







Mongodb
配置Mongodb
Windows端启动Mongdb服务
配置环境变量
电脑-→属性-→环境变量-→Path中添加MongoDb安装路径一直到bin
例
启动服务并进行相关配置;
mongod.exe --bind_ip 127.0.0.1 --logpath D:\MongoDB\dblog\mongodb.log --logappend --dbpath D:\MongoDB\db --port 27017 --service
- bind_ip:绑定服务 IP,绑定127.0.0.1,则只能本机访问,不指定默认本地所有 IP ;
- logpath :配置日志存放的位置;
- logappend :日志使用追加的方式;
- dbpath :配置数据存放的位置;
- port :配置端口号,27017是默认端口;
- service :以服务方式启动,即后台启动。
可以使用不同的端口、日志文件和数据存放位置启动多个
Linx端启动Mongodb服务
- 创建数据存放
cd /data#进入data路径
mkdir mydb#创建mydb文件夹 - 同理创建日志文件夹存放日志文件
mkdir /logs#创建并进入logs文件夹
cd /logs
mkdir mymongo#创建存放日志文件夹 - 配置文件(在
/etc下创建配置文件)
/etc/mymongod/mongod.confport=27020 dbpath=/data/mydb logpath=/logs/mymongo/mongod.log logappend=true fork=true - 配置文件启动命令
mongod -f /etc/mymongod/mongod.conf
启动Mongo客户端
- 启动命令
mongo --port 27020 - 关闭mongodb服务
use admin db.shutdownServer() - 退出客户端
exit ps -ef | grep mongo#查看进程
数据库基本操作
pgrep mongo -l#查看是否启动服务mongo#连接本地数据库use 数据库名#创建数据库(有则切换,无则创建)show dbs#查看数据库
刚创建的数据库还在内存中,没有持久化到磁盘中
查看可通过dbdb.库名.insert({_id:1,name:"王小明"})#插入数据db.dropDatabase()#删除数据库(删除必须先进入)db.集合名.insert([{},{}])#添加一个集合 一条数据用{},多条数据用[]db.集合名.find()#查询集合- db.集合名.find().pretty() #使查询更为整齐
db.createCollection("test", { capped : true, autoIndexId : true, size : 512000, max : 1000 } )- 条件查询
db.stu1.find({"name":"李小红"}).pretty()#等于db.stu1.find({"age":{$lt:18}}).pretty()#小于db.stu1.find({"age":{$lte:18}}).pretty()#小于等于db.stu1.find({"age":{$gt:18}}).pretty()#大于db.stu1.find({"age":{$gte:18}}).pretty()#大于等于db.stu1.find({"age":{$ne:18}}).pretty()#等于- 在mongdb里and条件与or只需将键值对用
,分割 db.集合名.find({$and:["userid":"1005","nickname":"罗密欧"]}).pretty()#and查询db.集合名.find({$or:["userid":"1002","userid":"1003"]}).pretty()#or查询db.集合名.find({<key>:null}).pretty()# 查询字段为null的文档db.集合名.find({<key>:/正则表达式/}).pretty()#正则查询db.集合名.find({<key>:{<key1>:<value1>,<key2>,<value2>}}).pretty()#嵌套查询(精确)db.集合名.find({<key>.<key1>:<value1>}.pretty())#嵌套查询(点查询)
db.集合名.find({<key>:{$in:[<key>:<value>]}}).pretty()包含操作符db.集合名.find({<key>:{$nin:[<key>:<value>]}}).pretty()不包含操作符db.集合名.drop()#删除集合db.集合名.insert(文档)#插入文档- (update()用于修改关键键值,save()修改整条数据)
db.集合名.update({旧文档},{$set:{新文档}})#更新文档db.集合名.save({})#指定_id则更新,否则则插入db.集合名.remove({'age':20})#删除age=20的数据db.集合名.remove({})#删除全部数据(集合本身不会删除,集合为空)
MongoDB文档的高级查询
向数据库导入数据和从数据库导出数据
数据导入工具:mongoimport;
MongoDB自带的数据导入工具,需在未连接客户端时使用
需要启动Mongo服务
- 导入数据
mongoimport -d Testdb1 -c score --type csv --headerline --ignoreBlanks --file test.csv
-d Testdb1: 指定将数据导入到 Testdb1 数据库;-c score:将数据导入到集合 score ,如果这个集合之前不存在,会自动创建一个(如果省略 --collection 这个参数,那么会自动新建一个以 CSV 文件名为名的集合);--headerline:这个参数很重要,加上这个参数后创建完成后的内容会以 CSV 文件第一行的内容为字段名(导入json文件不需要这个参数);--ignoreBlanks:这个参数可以忽略掉 CSV 文件中的空缺值(导入json文件不需要这个参数);--file 1.csv:这里就是 CSV 文件的路径了,需要使用绝对路径。
数据导出工具:mongoexport;
-
导出数据
1.导出json格式mongoexport -d Testdb1 -c score -o /file.json --type json-o /file.json:输出的文件路径/(根目录下)和文件名;--type json:输出的格式,默认为 json。
2.出 csv 格式的文件:
mongoexport -d Testdb1 -c score -o /file.json --type csv -f "_id,name,age,sex,major"-f:当输出格式为 csv 时,需要指定输出的字段名。
聚合操作
聚合管道操作:aggregate[({},{}…)] 用于聚合查询所有文档的方法,数组中的每个文档表示一种管道方法!
- $group操作符
db.集合名.aggregate([{$group:{<key1>:"$<key2>"}}]).pretty()#分组将以key2为键的文档分组成为一个新的文档,新文档的键位key1
- $limit操作符
db.集合名.aggregate({$limit:整型数字}).pretty()#显示集合中前整形数字条文档
- $match操作符
db.集合名.aggregate([{$match:{<key>:<value>}}]).pretty()#将集合中键key中值为value的文档查询出来
- $sort操作符
db.集合名.aggregate([{$sort:{<key>:-1或1}}]).pretty()#排序查询,1为 升序,-1为降序
- $project操作符
db.集合名.aggregate([{$project:{<key>:<value>}}]).pretty()#以key:value的显示规则显示该集合
db.集合名.aggregate({$project:{course:1,authoe:1,tags:1,num:'$learning_num'}})
0为不显示,非0为显示 上式把learning_num重命名为num
- $skip操作符
db.集合名.aggregate({$skip:整型数字}).pretty()#查询第整型数字后的文档
$skip与$limit可以组合使用
db.educoder.aggregate([{$skip:1},{$limit:2}])显示第2-3条文档
- $sum表达式
{<key3>:{$sum:$<key3>}}#求和
- $avg表达式
{<key3>:{$avg:$<key3>}}#求平均值
- $min表达式
{<key3>:{$min:$<key3>}}#求最小值
- $max表达式
{<key3>:{$max:$<key3>}}#求最大值
- $push表达式
db.集合名.aggregate([{管道操作符:{<key1>:"$<key2>",{<key3>:$push:$<key3>}}}])#字段key3到key3键里
- $first表达式
db.集合名.aggregate([{管道操作符:{<key1>:"$<key2>",{<key3>:$first:$<key3>}}}])#显示分组的第一个文档
- $last表达式
db.集合名.aggregate([{管道操作符:{<key1>:"$<key2>",{<key3>:$last:$<key3>}}}])#显示分组的最后一个文档
- $not表达式
db.集合名.find({age:{$not:{$gte:20}}})#条件取反 ,查询不满足条件的文档
- $unwind表达式
db.集合名.aggregate({$unwind:'$tags'})#拆分查询 将$tags字段分为多条,每条包含数组里的一个值
- $addToSet 表达式
在结果文档中插入值到一个数组中,但不创建副本
db.haicoder.aggregate([
{
'$group': {'_id': '$id', 'score': {'$addToSet': '$score'}}
}
]);
游标
游标是不是查询结果,而是查询的返回资源,或者接口,通过这个接口,可以逐条读取。就像fopen打开文件,,得到一个资源一样,通过资源,可以一行一行的读文件。
使用循环插入数据
首先插入10000条数据到集合 items,因为 mongodb 底层是 javascript 引擎,所以我们可以使用 js 的语法来插入数据:
for(var i=0;i<10000;i++)db.items.insert({_id:i,text:"Hello MongoDB"+i})
声明游标
定义一个变量来保存这个游标,find 的查询结果(_id<=5)赋值给了游标 cursor 变量,代码如下:
var cursor=db.items.find({_id:{$lte:5}})
打印游标中的数据信息
四种方法打印
printjson(cursor.next())打印下一条数据(读取完最后一条数据后,再使用会报错)- 使用 js 的 while 语法来循环打印
var currsor=db.items.find({_id:{$lte:5}})
while(curror.hasNext()){
printjson(curror.next(););
}
查看时只显示20条数据
全部查看需设置DBQuery.shellBatchSize = 1000
3. 使用 for 循环打印
for(var currsor=db.items.find({_id:{$lte:5}});cursor.hasNext();){
printjson(curror.next(););
}
- 使用 forEach 打印
var currsor=db.items.find({_id:{$lte:5}})
cursor.forEach(function(obj){
printjson(curror.next(););
})
游标的使用场景
假设每页有10行,我们查询第701页,可以配合 skip() 和 limit() 来实现
var cursor=db.items.find().skip(7000).limit(10);
cursor.forEach(function(obj){
printjson(curror.next(););
})
只取出其中一个
var cursor=db.items.find().skip(7000).limit(10);
printjson(curror.toArray()[3]);
索引基本操作
-
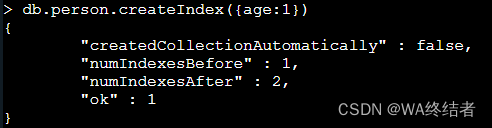
创建索引(单字段索引)
db.person.createIndex({key:1})- key:要创建索引的建;
- 如果为1,则为按照升序创建,-1为降序创建
-
查询索引
查询集合索引
db.person.getIndexes()
查询系统全部索引
db.system.indexes.find() -
删除索引
- 通过指定索引名称删除该索引:
db.person.dropIndex("areIdx") - 通过指定集合删除集合中的全部索引:
db.person.dropIndexes()
注意:默认索引_id无法被删除
- 通过指定索引名称删除该索引:
常见索引的创建
- 创建复合索引
与单字段索引的方法类似,选取多个键一同作为索引,中间以逗号隔开:
db.person.createindex({age:1,name:1})
- 创建多Key索引
当索引的字段为数组时,创建出的索引为多key索引,多key索引回为数组的每个元素建立一条索引,
比如person集合加入一个habit字段(数组)用于描述兴趣爱好
{name : '王小明', age : 19, habbit: ['football', 'runnning']}
需要查询有相同爱好的人可以利用habbit字段的多key索引
db.person.createIndex( {habbit: 1} ) // 升序创建多key索引
db.person.find({habbit: 'football'}) //查找喜欢足球的人
- 创建哈希索引
创建命令如下:
db.person.createIndex({_id:'hashed'})
- 创建文本索引
假设有文章集合collection:
{
title: 'enjoy the mongodb articles on educoder', //文章标题
tags: [ //标签
'mongodb',
'educoder'
]
}
则创建文本索引命令如下:
db.collection.createIndex({title:'text'})
-
创建全文索引的字段必须为string格式
-
每个集合只支持一个文本索引
也可以创建多个字段text
db.collection.createIndex(
{
title:'text',
tags:'text'
}
)
利用title的索引搜索含有educoder.net的文章
db.collection.find({$text:{$search:'educoder.net'}})
- search后的关键词可以有多个,关键词之间的分隔符可以是多种字符,例如空格、下划线、逗号、加号等,但不能是
-和\,因为这两个符号会有其他用途。搜索的多个关键字是 or 的关系,除非你的关键字包含-; - 匹配时不是完整的单词匹配,相似的词也可以匹配到;
删除文本索引:
-
通过命令获取索引名:
db.collection.getIndexes() -
删除索引:
db.collection.dropIndex('title_text')
有趣的地理索引
-
GeoJson数据
不是所有的文档都可以创建地理位置索引,只有拥有特定格式的文档菜可以创建
如果使用的2dsphere索引,则应该插入GeoJson数据
GeoJson格式:
{ type: 'GeoJSON type' , coordinates: 'coordinates' }-
type: 指类型,可以是Point、LineString、Polygon等;
-
coordinates:指的是一个坐标数组
-
插入数据
-
db.locations.insert({_id:1,name:'长沙站',location:{type:'Point',coordinates:[113.018987,28.201215]}}) db.locations.insert({_id:2,name:'湖南师范大学',location:{type:'Point',coordinates:[112.946045,28.170968]}}) db.locations.insert({_id:3,name:'中南大学',location:{type:'Point',coordinates:[112.932175,28.178291]}}) 4. `db.locations.insert({_id:4,name:'湖南女子学院',location:{type:'Point',coordinates:[113.014675,28.121163]}}) 5. `db.locations.insert({_id:5,name:"湖南农业大学",location:{type:'Point',coordinates:[113.090852,28.187461]}})
-
-
创建地理位置索引
db.locations.createIndex({location:'2dsphere'})- 2d :平面坐标索引,适用于基于平面的坐标计算,也支持球面距离计算,不过官方推荐使用 2dsphere 索引;
- 2dsphere :几何球体索引,适用于球面几何运算;
- 默认情况下,地理位置索引会假设值的范围是从−180到180(根据经纬度设置)。
-
地理位置索引的使用
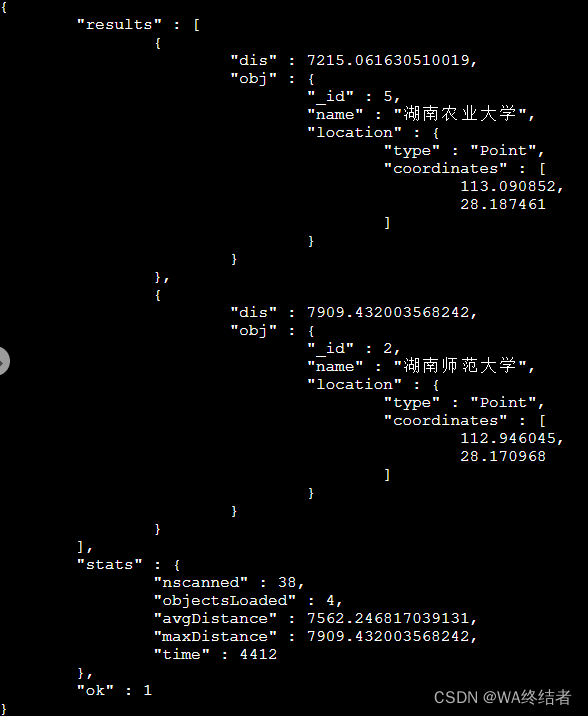
查询命令:
db.runCommand({ geoNear:'locations', near:{type:'Point',coordinates:[113.018987,28.201215]}, spherical:true, minDistance:1000, maxDistance:8000 })- geoNear :我们要查询的集合名称;
- near :就是基于那个点进行搜索,这里是我们的搜索点“长沙站”;
- spherical :是个布尔值,如果为 true,表示将计算实际的物理距离,比如两点之间有多少 km,若为 false,则会基于点的单位进行计算 ;
- minDistance :搜索的最小距离,这里的单位是米 ;
- maxDistance :搜索的最大距离。
数据库优化
MongoDB 查询优化原则
查询优化原则
-
在查询条件、排序条件、统计条件的字段上选择创建索引,可以显著提高查询效率;
-
用 $or 时把匹配最多结果的条件放在最前面,用 $and 时把匹配最少结果的条件放在最前面;
-
使用 limit() 限定返回结果集的大小,减少数据库服务器的资源消耗,以及网络传输的数据量;
-
尽量少用 i n ,而是分解成一个一个的单一查询。尤其是在分片上, in,而是分解成一个一个的单一查询。尤其是在分片上, in,而是分解成一个一个的单一查询。尤其是在分片上,in 会让你的查询去每一个分片上查一次,如果实在要用的话,先在每个分片上建索引;
-
尽量不用模糊匹配查询,用其它精确匹配查询代替,比如 i n 、 in 、 in、nin;
-
查询量大、并发大的情况,通过前端加缓存解决;
-
能不用安全模式的操作就不用安全模式,这样客户端没必要等待数据库返回查询结果以及处理异常,快了一个数量级;
-
MongoDB 的智能查询优化,判断粒度为 query 条件,而 skip 和 limit 都不在其判断之中,当分页查询最后几页时,先用 order 反向排序;
-
尽量减少跨分片查询,balance 均衡次数少;
-
只查询要使用的字段,而不查询所有字段;
-
更新字段的值时,使用 $inc 比 update 效率高;
$inc操作符用于将字段的值增加到指定的数量或将字段增加给定的值。类似于自增自减操作-
此运算符接受正值和负值。
-
如果给定的字段不存在,则此运算符将创建字段并设置该字段的值。
-
如果将此运算符与空值字段一起使用,则此运算符将生成错误。
-
它是单个文档中的原子操作。
// 将quantity减2,metrics.orders内嵌文档字段加1 db.products.update( { sku: "abc123" }, { $inc: { quantity: -2, "metrics.orders": 1 } } )
-
-
apped collections 比普通 collections 的读写效率高;
-
server-side processing 类似于 SQL 查询的存储过程,可以减少网络通讯的开销;
-
必要时使用 hint() 强制使用某个索引查询;
hint() 来强迫 MongoDB 使用一个特定的索引
db_name.table_name.find({query}).hint({"index_name":1}); -
如果有自己的主键列,则使用自己的主键列作为 id,这样可以节约空间,也不需要创建额外的索引;
-
使用 explain ,根据 exlpain plan 进行优化;
-
范围查询的时候尽量用 i n 、 in、 in、nin 代替;
-
查看数据库查询日志,具体分析的效率低的操作;
-
mongodb 有一个数据库优化工具 database profiler,能够检测数据库操作的性能。可以发现 query 或者 write 操作中执行效率低的,从而针对这些操作进行优化;
-
尽量把更多的操作放在客户端,当然这就是 mongodb 设计的理念之一。
MongoDB 的 Profiling 工具
Profiling 工具
Profiling 是 Mongo 自带的一种分析工具来检测并追踪影响性能的慢查询。
慢查询日志一般作为优化步骤里的第一步
优化步骤:
- 用慢查询日志(system.profile)找到超过50ms 的语句;
- 然后再通过 .explain() 解析影响行数,分析为什么超过50ms;
- 决定是不是需要添加索引。
Profiling 级别说明:
- 0:关闭,不收集任何数据;
- 1:收集慢查询数据,默认是100毫秒;
- 2:收集所有数据。
全局开启 Profiling
启用 Profiling 工具
方法一:
-
mongod 启动时加上以下参数
mongod --profile=1 --slowms=50
方法二:
-
在配置文件里添加两行
profile = 1 slowms = 50
mongo shell 中启动配置
-
查看状态
db.getProfilingStatus() -
查看级别
db.getProfilingLevel() -
设置级别
db.setProfilingLevel(1) //设置级别为1 -
设置级别和时间
db.getProfilingLevel(1,50) //设置级别为1,时间为50ms注意:
- 配置操作在 test 集合下面的话,只对该集合里的操作有效,要是需要对整个实例有效,则需要在所有的集合下设置或则在开启的时候开启参数;
- 每次设置之后返回给你的结果是修改之前的状态(包括级别、时间参数)。
关闭 Profiling 工具
只需要将收集慢查询数据的时间设置为0就可以关闭
db.setProfilingLevel(0)
慢查询分析
-
首先,在 test 数据库启用 Profiling 工具:
use test db.setProfilingLevel(1,50) # 设置级别为1,时间为50ms,意味着只有超过50ms的操作才会记录到慢查询日志中 -
然后在 test 数据库的 items 集合中循环插入100万条数据:
for(var i=0;i<1000000;i++)db.items.insert({_id:i,text:"Hello MongoDB"+i}) -
返回所有结果:
db.system.profile.find().pretty() -
结果显示为:
{ "op" : "insert", #操作类型,有insert、query、update、remove、getmore、command "ns" : "test.items", #操作的集合 "command" : { "insert" : "items", "ordered" : true, "$db" : "test" }, "ninserted" : 1, "keysInserted" : 1, "numYield": 0, #该操作为了使其他操作完成而放弃的次数。通常来说,当他们需要访问还没有完全读入内存中的数据时,操作将放弃。这使得在MongoDB为了放弃操作进行数据读取的同时,还有数据在内存中的其他操作可以完成 "locks": { #锁信息,R:全局读锁;W:全局写锁;r:特定数据库的读锁;w:特定数据库的写锁 "Global" : { "acquireCount" : { "r" : NumberLong(1), "w" : NumberLong(1) } }, "Database" : { "acquireCount" : { "w" : NumberLong(1) } }, "Collection" : { "acquireCount" : { "w" : NumberLong(1) } } }, "responseLength" : 45, #返回字节长度,如果这个数字很大,考虑值返回所需字段 "protocol" : "op_msg", "millis" : 60, #消耗的时间(毫秒) "ts" : ISODate("2018-12-07T08:19:11.997Z"), #该命令在何时执行 "client" : "127.0.0.1", #链接ip或则主机 "appName" : "MongoDB Shell", "allUsers" : [ ], "user" : "" }
profile 部分字段解释:
- op :操作类型;
- ns :被查的集合;
- commond :命令的内容;
- docsExamined :扫描文档数;
- nreturned :返回记录数;
- millis :耗时时间,单位毫秒;
- ts :命令执行时间;
- responseLength :返回内容长度。
常用的慢日志查询命令
-
返回最近的10条记录:
db.system.profile.find().limit(10).sort({ ts : -1 }).pretty() -
返回所有的操作,除 command 类型的:
db.system.profile.find( { op: { $ne : 'command'} }).pretty() -
返回特定集合:
db.system.profile.find( { ns : 'test.items' } ).pretty() -
返回大于5毫秒慢的操作:
db.system.profile.find({ millis : { $gt : 5 } } ).pretty() -
从一个特定的时间范围内返回信息:
db.system.profile.find( { ts : { $gt : new ISODate("2018-12-09T08:00:00Z"), $lt : new ISODate("2018-12-10T03:40:00Z") } } ).pretty() -
特定时间,限制用户,按照消耗时间排序:
db.system.profile.find( { ts : { $gt : new ISODate("2018-12-09T08:00:00Z") , $lt : new ISODate("2018-12-10T03:40:00Z") } }, { user : 0 } ).sort( { millis : -1 } ).pretty() -
查看最新的 Profile 记录:
db.system.profile.find().sort({$natural:-1}).limit(1).pretty() -
显示5个最近的事件:
show profile
Python 访问MongoDB
python连接MongoDB写入数据
pip工具
pip 是一个通用的 Python 包管理工具,提供了对 Python 包的查找、下载、安装、卸载的功能。
pymongo是MongoDB的一种接口
一般采用pip安装
也可以使用easy_install、源码等安装
安装命令:pip install pymongo
查看安装信息: pip show pymongo
测试PyMongo
-
导入pymongo库
import pymongo -
使用MongoClient对象创建与数据库服务器的连接
创建MongoClient实例后,就可以访问服务器中的任何数据。
// host域名 // port端口号 client=pymonogo.MongoClient(host='127.0.0.1',port=12717) // 连接具体的mongod服务器或副本集 client=MongoClient(host='10.90.9.102',port=12718) client=MongoClient(host='10.90.9.101:27018,10.90.9.102: 12718,10.90.9.103:27018') -
访问数据库
// 三种方法访问数据库 mydb = client["runoobdb"] //client是我们创建的实例 runobdb数据库可以看作client的属性 // 也可以用点的方式访问 db = client.myDB // 或者通过函数方法访问 db = client.get_database("myDB") // list_collection_names()函数可以返回该数据库集合列表 //判断是db否含有test3集合,如果有则删除 if("test3" in db.list_collection_names()): db.drop_collection("test3")如果不存在数据库,则系统会自动创建数据库
==在 MongoDB 中,数据库只有在内容插入后才会创建!==可以理解为当python中创建数据库后只有插入数据(创建集合并插入文档)后,mongodb才会根据内容创建数据库 -
集合操作
(1).插入文档
需要先获取集合,并使用集合的insert_one()方法或insert_many()方法插入文档
// 插入内容可以先保存在变量里
mydict = { "name": "RUNOOB", "alexa": "10000", "url": "https://www.runoob.com" }
x = mycol.insert_one(mydict) // 插入单条文档
//insert_many()插入多条文档
mylist = [
{ "name": "Taobao", "alexa": "100", "url": "https://www.taobao.com" },
{ "name": "QQ", "alexa": "101", "url": "https://www.qq.com" },
{ "name": "Facebook", "alexa": "10", "url": "https://www.facebook.com" },
{ "name": "知乎", "alexa": "103", "url": "https://www.zhihu.com" },
{ "name": "Github", "alexa": "109", "url": "https://www.github.com" }
]
x = mycol.insert_many(mylist) //该方法返回一个insertmanyresult对象,该对象具有一个属性inserted_ids,用于保存插入文档的ID
-
查询操作
==find()==方法来查询指定字段的数据,将要返回的字段对应值设置为 1。
MongoDB数据库安全
创建管理员用户
管理员用户:负责创建和管理其他用户的用户
切换到
admin数据库(admin数据库是一个具有特殊权限的数据库,用户需要访问它以便执行某些管理命令);
use admin
创建管理员用户:
db.createUser({user:"abc",pwd:"123",roles:[{role:"root",db:"admin"}]})
- user: 创建的管理员用户名
- pwd:管理员用户的密码
- roles:权限与数据库
验证管理员创建成功
db.auth("abc","123")
查看用户
show users 只能查看当前库下用户
db.system.users.find().pretty() 全局查看所有用户(要在admin下使用)
使用管理员用户查看普通用户itcastUser的信息
db.getUser("itcastUser")
使用管理员用户查看普通用户itcastUser的权限
db.getUsser(“itcastUser”,{showPrivileges:true})
启用身份验证
身份验证默认为禁用,启动MongoDB数据库服务器服务mongo时使用参数==--auth==来启动身份验证(身份验证前必须保证自己至少拥有一个管理员用户)
如果在admin数据库中没有用户,mongod启动时添加了–auth参数,需要先杀死进程,然后重启服务进程
ps -ef | grep mongodkill 服务进程号mongod 参数: --noauth
-
关闭现在有的数据库服务
use admin db.shutdownServer() -
重新启动mongod服务
mongod --auth --port 27017 --dbpath /data/db --logpath /tmp/mongodb.log --fork- auth: 开启身份验证
- dbpath:指定数据存放路径
- logpath:指定日志文件输出路径
- fork:后台运行
管理员登陆数据库
-
在命令行连接数据库(必须use admin)
mongo -uabc -p123 admin- -u 后面接用户名
- -p 后面接密码
-
受限情况下验证身份
use admin db.auth("abc","123") -
删除管理员用户
db.system.users.remove({user:"abc"}) // user为需要删除的管理员用户
按需求创建普通用户
| 权限 | 说明 |
|---|---|
Read | 允许用户读取指定数据库 |
readWrite | 允许用户读写指定数据库 |
dbAdmin | 允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile |
userAdmin | 允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户 |
clusterAdmin | 只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限。 |
readAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的读权限 |
readWriteAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的读写权限 |
userAdminAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的userAdmin权限 |
dbAdminAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限。 |
root | 只在admin数据库中可用。超级账号,超级权限 |
创建普通用户
-
创建用户
//用户user1,密码:user,拥有数据库test的读写权限 ue test db.createUser({user:"user1",pwd:"user1",roles:[{role:"readWrite",db:"test"}]}) // readWrite读写权限 //user2,密码:user2,对数据库test2有读写权限,对数据库test有只读权限。 use test2 db.createUser({user:"user2",pwd:"user2",roles:[{role:"readWrite",db:"test2"},{role:"read",db:"test"}]}) //read 只读权限 -
删除普通用户
use test2 db.dropUser("user2") //在当前数据库使用 //使用管理员用户删除普通用户中的readAnyDatabse db.revokeRolesFromUser("user2",[{role:"readAnyDatabase",db:"admin"}]) -
修改用户信息
// 使用管理员用户将普通用户itcastUser角色修改为readAnyDatabase db.updateUser("itcastUser",{roles:[{role:"read",db:"admin"},{role:"readAnyDatabase",db:"admin"}]}) //使用管理员用户itcastAdmin为普通用户itcastUser添加readWrite角色 db.grantRolesToUser("itcastUser",[{role:"readWrite",db:"admin"}]) //修改用户密码 //需要具有userAdmin或userAdminAnyDatabase或root的用户才能执行 db.changeUserPassword("itcastUser","itcastuser") db.updateUser("itcastUser",{"pwd":"itcastuser"})
数据库限制访问
限制 IP 访问,需要重启数据库服务 mongod 时,启用相应的功能
-
关闭服务(先用默认方法启动数据库:mongo )
use admin //进入admin数据库 db.shutdownServer() //关闭服务 exit //退出数据库 -
启动服务(只有本机 IP 可以连接数据库):
mongod --dbpath /data/db --logpath /tmp/mongodb.log --bind_ip 127.0.0.1 --fork- binf_ip :限制连接的网络接口,可以设置多个,以逗号隔开。
限制端口访问
当按照以上方法启动 mongod 时,默认情况下他会等待所有在端口27017上的入站连接,可以用 -port 修改该设置。也需要重新启动 mongod 服务,方法同上。
-
关闭服务(先用默认方法启动数据库:mongo ):
use admin //进入admin数据库 db.shutdownServer() //关闭服务 exit //退出数据库 -
启动服务(只有本机 IP 可以连接数据库,且限制只能端口20000连接):
mongod -port 20000 --dbpath /data/db --logpath /tmp/mongodb.log --bind_ip 127.0.0.1 --fork -
连接数据库:
mongo 127.0.0.1:20000设置了端口后如果不加端口连接会被拒绝访问
MongoDB 复制集 & 分片
MongoDB 架构
复制集
- 备份数据 数据库的数据只有一份的话是极不安全的,一旦数据所在的电脑坏掉,我们的数据就彻底丢失了,所以要有一个备份数据的机制。
- 故障自动转移 部署了复制集,当主节点挂了后,集群会自动投票再从节点中选举出一个新的主节点,继续提供服务。而且这一切都是自动完成的,对运维人员和开发人员是透明的。当然,发生故障了还是得人工及时处理,不要过度依赖复制集,万一都挂了,那就连喘息的时间都没有了。
- 在某些特定的场景下提高读性能 默认情况下,读和写都只能在主节点上进行。 下面是 MongoDB 的客户端支持5种复制集读选项:
- primary :默认模式,所有的读操作都在复制集的主节点进行的;
- primaryPreferred :在大多数情况时,读操作在主节点上进行,但是如果主节点不可用了,读操作就会转移到从节点上执行;
- secondary :所有的读操作都在复制集的从节点上执行;
- secondaryPreferred :在大多数情况下,读操作都是在从节点上进行的,但是当从节点不可用了,读操作会转移到主节点上进行;
- nearest :读操作会在复制集中网络延时最小的节点上进行,与节点类型无关。
复制集结构,如图1所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gLvseBkA-1666614051831)(https://data.educoder.net/api/attachments/208438)]
副本集成员状态
| 状态码 | 状态名称 | 状态介绍 |
|---|---|---|
| 0 | STARTUP | 成员刚启动时处于此状态 |
| 1 | PRIMARY | 成员处于主节点的状态 |
| 2 | SECONDARY | 成员处于副节点的状态 |
| 3 | RECOVERING | 成员正在执行启动自检,数据回滚或同步过程结束时也会短暂处于次状态 |
| 5 | STARTUP2 | 成员处于初始化同步过程 |
| 6 | UNKNOWN | 成员处于未知状态 |
查看副本集成员状态
rs.status()
查看MongoDB运行状态
ps -ef | grep mongodb
分片
分片(sharding)是指将数据库拆分,使其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。通过一个名为 mongos 的路由进程进行操作,mongos 知道数据和片的对应关系(通过配置服务器)。
什么时候使用分片:
- 机器的磁盘不够用了,使用分片解决磁盘空间的问题;
- 单个 mongod 已经不能满足写数据的性能要求,通过分片让写压力分散到各个分片上面,使用分片服务器自身的资源;
- 想把大量数据放到内存里提高性能,通过分片使用分片服务器自身的资源。
分片结构,如图2所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m3Biy1qD-1666614051831)(https://data.educoder.net/api/attachments/209067)]
- Shard :用于存储实际的数据块,实际生产环境中一个 shard server 角色可由几台机器组个一个 replica set 承担,防止主机单点故障;
- Config Server :mongod 实例,存储了整个 ClusterMetadata,其中包括 chunk 信息;
- Query Routers :前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
MongoDB 复制集搭建
配置文件设置
因为我们要启动三个 mongodb 服务,所以要准备三个数据存放位置,三个日志文件,三个配置文件。
-
数据存放位置;
在 /data 路径下创建文件夹 db1、db2 和 db3 来存放三个服务的数据。
-
日志文件;
在 /logs 路径下创建文件夹 mongo 存放日志文件 mongod1.log、mongod2.log 和 mongod3.log(文件不用创建,到时候会自动生成,但路径即文件夹必须提前创建好)。
-
配置文件。
在 /etc/mongod 路径下新建三个配置文件,使用配置文件启动 mongod 服务(在之前的实训中我们都是用命令启动的)。
mongodx.conf 内容如下: x(对应1、2、3)
port=2700x #配置端口号
dbpath=/data/dbx #配置数据存放的位置
logpath=/logs/mongo/mongodx.log #配置日志存放的位置
logappend=true #日志使用追加的方式
fork=true #设置在后台运行
replSet=YOURMONGO #配置复制集名称,该名称要在所有的服务器一致
配置文件启动命令
mongod -f /etc/mongod/mongodx.conf
配置主从节点
三个端口的服务全部启动成功后,需要进入其中一个进行配置节点。 设置27019为 arbiter 节点。
-
进入端口号为27018的进行配置,连接数据库:mongo --port 27018;
-
选择数据库 admin;
-
输入配置要求如下:
config = { _id:"YOURMONGO", members:[ {_id:0,host:'127.0.0.1:27018'}, {_id:1,host:'127.0.0.1:27019',arbiterOnly:true}, {_id:2,host:'127.0.0.1:27020'}, ] }
使用 rs.initiate(config)进行初始化:
rs.initiate(config)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vvB6yA76-1666614051833)(https://data.educoder.net/api/attachments/209380)]
此为主节点
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SoJ3lPDQ-1666614051833)(https://data.educoder.net/api/attachments/209378)]
此为主从节点
-
使用rs.status() 查看状态。
-
验证复制集同步
在主数据库插入数据,然后去从数据库查看数据是否一致。
连接主数据库:mongo --port 27018;
use testdb.person.insert({name:'王小明',age:20})
连接从数据库:mongo --port 27020;
从库查询数据需要设置 slaveOk 为 true;
use test
rs.slaveOk(true)
db.person.find()
切换 Primary 节点到指定的节点
在实际应用中,如果想指定某服务器或端口作为主节点,而不是随机选举一个主节点,可以通过以下方法改变 Primary 节点:
-
先进入主节点中进行操作:
mongo --port 27018 -
查看目前的节点状态:
rs.conf() #查看配置rs.status() #查看状态其中 priority : 是优先级,默认为 1,优先级 0 为被动节点,不能成为活跃节点。优先级不为 0 则按照由大到小选出活跃节点。
因为默认的都是1,所以只需要把给定的服务器的 priority 加到最大即可。让27020成为主节点,操作如下: 现进入目前的主节点进行操作如下:
cfg=rs.conf()cfg.members[2].priority=2 #修改priority,members[2]即对应27020端口rs.reconfig(cfg) #重新加载配置文件,强制了副本集进行一次选举,优先级高的成为Primary。在这之间整个集群的所有节点都是secondaryrs.status()
这样,给定的服务器或端口就成为了主节点。
移除服务器nosql02中的隐藏节点
rs.remove(“nosql102:27017”)
MongoDB 分片集搭建
配置文件设置
-
同复制集一样,我们要准备目录存放我们的数据和日志:
mkdir -p /data/shard1/dbmkdir -p /logs/shard1/logmkdir -p /data/shard2/dbmkdir -p /logs/shard2/logmkdir -p /data/shard3/dbmkdir -p /logs/shard3/logmkdir -p /data/config/dbmkdir -p /logs/config/logmkdir -p /logs/mongs/log -
配置文件 (新建在 /etc/mongo 目录下);
mongod1.conf 内容如下:
dbpath=/data/shard1/dblogpath=/logs/shard1/log/mongodb.logport=10001shardsvr=truefork=truemongod2.conf 内容如下:
dbpath=/data/shard2/dblogpath=/logs/shard2/log/mongodb.logport=10002shardsvr=truefork=truemongod3.conf 内容如下:
dbpath=/data/shard3/dblogpath=/logs/shard3/log/mongodb.logport=10003shardsvr=truefork=true其中 shardsvr 是用来开启分片的。
-
从配置文件启动 mongod 服务:
mongod -f /etc/mongo/mongod1.confmongod -f /etc/mongo/mongod2.confmongod -f /etc/mongo/mongod3.conf
config 节点
-
配置启动节点服务:
mongod --dbpath /data/config/db --logpath /logs/config/log/mongodb.log --port 10004 --configsvr --replSet cs --fork -
连接 route 节点:
mongo localhost:10004 -
输入以下命令:
use admincfg = { _id:'cs', configsvr:true, members:[ {_id:0,host:'localhost:10004'} ]}rs.initiate(cfg)运行效果如图1所示,说明设置成功:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-28HTGMQa-1666614051834)(https://data.educoder.net/api/attachments/209178)] 图 1
route 节点
-
配置启动节点服务:
mongos --configdb cs/localhost:10004 --logpath /logs/mongs/log/mongodb.log --port 10005 --fork -
连接上 route 节点:
mongo localhost:10005 -
添加分片:
sh.addShard('localhost:10001')sh.addShard('localhost:10002')sh.addShard('localhost:10003') -
查看集群的状态:分片摘要信息、数据库摘要信息、集合摘要信息等;
sh.status()运行效果如图 2 所示,说明设置成功:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mzLNVT64-1666614051834)(https://data.educoder.net/api/attachments/209185)] 图 2
分片验证
-
连接 route 节点:mongo localhost:10005;
数据量太小可能导致分片失败,这是因为 chunksize 默认的大小是 64MB( chunkSize 来制定块的大小,单位是 MB ),使用以下代码把 chunksize 改为 1MB 后,插入数据,便可以分片成功。
use configdb.settings.save( { _id:"chunksize", value: 1 } ) -
对集合使用的数据库启用分片:
sh.enableSharding("test") -
添加索引:
db.user.ensureIndex({ "uid" : 1}) -
分片:
sh.shardCollection("test.user",{"uid" : 1}) -
插入10万条数据(大概需要40s 左右):
use testfor(i=0;i<100000;i++){db.user.insert({uid:i,username:'test-'+i})} -
再次运行 sh.status() 会多出内容,显示分片的情况。
-
去各个节点查看数据分布情况:
以下分别是在端口10001、10002和10003查询的文档条数,加起来正好10万条。
数据备份和恢复
数据备份
mongodump备份工具
参数
| 参数 | 参数说明 |
|---|---|
| -h | 指明数据库宿主机的IP |
| -u | 指明数据库的用户名 |
| -p | 指明数据库的密码 |
| -d | 指明数据库的名字 |
| -c | 指明collection的名字 |
| -o | 指明到要导出的文件名 |
| -q | 指明导出数据的过滤条件 |
| –authenticationDatabase | 验证数据的名称 |
| –gzip | 备份时压缩 |
| –oplog | use oplog for taking a point-in-time snapshot |
使用mongodump备份数据
备份操作无需进入客户端
-
全库备份
mongodump -h 127.0.0.1:27300 -uroot -proot --authenticationDatabase admin -o /home/mongod #备份本地27300端口中root用户的所有数据库到/home/mongod目录下 -
单个数据备份
mongodump -h 127.0.0.1:27300 -uroot -proot --authenticationDatabase admin -d test -o /home/mongod/test #备份本地27300端口中root用户的test数据库到/home/mongod/test目录下
-
集合备份
mongodump -h 127.0.0.1:27300 -uroot -proot --authenticationDatabase admin -d test -c haha -o /home/mongod/test/haha#备份27300端口中root用户的test数据库的haha集合到/home/mongod/test/haha目录下 -
压缩备份库
mongodump -h 127.0.0.1:27300 -uroot -proot --authenticationDatabase admin -d test -o /home/mongod/test1 --gzip#压缩备份本地27300端口中root用户的test数据库到/home/mongod/test1目录下 -
压缩备份集合
mongodump -h 127.0.0.1:27300 -uroot -proot --authenticationDatabase admin -d test -c haha -o /home/mongod/test1/haha --gzip#压缩备份27300端口中root用户的test数据库的haha集合到/home/mongod/test1/haha目录下
数据恢复
mongorestore 恢复工具
| 参数 | 参数说明 |
|---|---|
| -h | 指明数据库宿主机的IP |
| -u | 指明数据库的用户名 |
| -p | 指明数据库的密码 |
| -d | 指明数据库的名字 |
| -c | 指明collection的名字 |
| -o | 指明到要导出的文件名 |
| -q | 指明导出数据的过滤条件 |
| –authenticationDatabase | 验证数据的名称 |
| –gzip | 备份时压缩 |
| –oplog | use oplog for taking a point-in-time snapshot |
| –drop | 恢复的时候把之前的集合drop掉 |
使用 mongorestore 恢复数据
-
全库备份中恢复单库(基于之前的全库备份)
mongorestore -h 127.0.0.1:27017 -uroot -proot --authenticationDatabase admin -d test --drop /home/mongod#从/home/mongod目录下恢复全部数据库的数据到本地27300端口中root用户中(基于第一关的备份,下同) -
恢复 test 库
mongorestore -h 127.0.0.1:27017 -uroot -proot --authenticationDatabase admin -d test /home/mongod/test#从/home/mongod/test目录下恢复名为test的单个数据库的数据到本地27300端口中root用户中的test数据库 -
恢复 test 库下的 haha 集合
mongorestore -h 127.0.0.1:27017 -uroot -proot --authenticationDatabase admin -d test -c haha /home/mongod/test/haha/haha.bson#从/home/mongod/test/haha目录下恢复集合的数据到本地27300端口中root用户的test数据库的haha集合中 -
–drop 参数实践恢复
# 恢复单库mongorestore -h 127.0.0.1:27017 -uroot -proot --authenticationDatabase admin -d test --drop /home/mongod/test# 恢复单表mongorestore -h 127.0.0.1:27017 -uroot -proot --authenticationDatabase admin -d test -c vast --drop /home/mongod/test/haha/haha.bson



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











