







单点Redis的问题:
1.Redis是内存存储, 服务重启 可能会丢失数据。
2.单节点Redis并发能力虽然不错,但也 无法满足如618这样的高并发场景。
3.如果Redis 宕机,则服务不可用,需要一种自动的故障恢复手段。
4.Redis基于内存, 单节点能存储的数据量难以满足海量数据需求。
解决:
1.数据丢失问题: 实现数据持久化,将数据写入磁盘
2.并发能力问题: 搭建主从集群,实现读写分离
3.故障恢复问题: 利用Redis哨兵,实现健康检测和自动恢复
4.存储能力问题: 搭建分片集群,利用插槽机制实现动态扩容
1.RDB持久化
RDB全称Redis Database Backup file( Redis数据备份文件),也被叫做 Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
快照文件称为RDB文件,默认保存在当前运行目录。
1.如何启动RDB:直接redis-cli -> save

注意:由Redis主进程来完成,但Redis是单线程的,RDB是将数据写到磁盘,磁盘的IO比较慢,如果数据量又很大就要耗时很久,在此期间,无法处理其他的请求,只适合停机时使用。(不推荐)
2.bgsave

运行那一刻就返回结果,在后台异步执行保存操作。主进程不受影响,可以正常处理请求。
3.主动停机时会自动进行一次RDB,在运行目录生成dump.rdb文件。
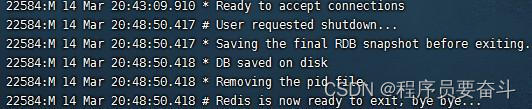
./redis-cli -a 密码 shutdown:如果redis是后台启动可以这样关闭。
如果要查看Redis输出日志需要在redis.conf中找到logfile "",后面填写路径(绝对路径),loglevel是日志等级默认notice,有debug,verbose,notice,warning.
问题1:
redis会在自己正常停机时保存,但如果redis是宕机的就不会保存了。
解决:
每隔一段时间,数据就备份一次。
4.Redis内部有触发RDB的机制,可以在redis.conf文件中找到

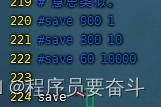
存入一个值后在日志中就可以看到这样一个日志

实现了每隔一段时间保存一次。RDB的时间不能设置过长(没有持久化,在这段时间宕机的话数据会丢失),也不能过短(频率过高,来不及处理),一般就默认。所以还要有其他持久化方案来弥补RDB方案。
5.RDB的其他配置



RDB如何实现异步持久化
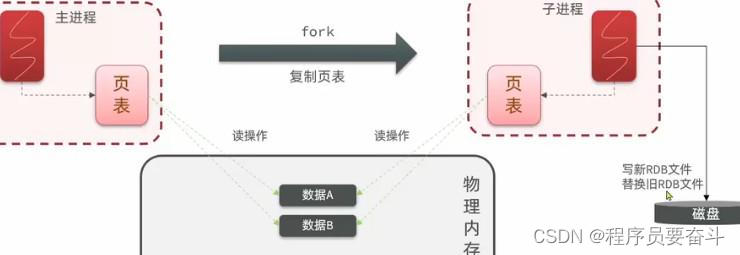
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件。
问题2:
主进程的子进程是异步执行的,但fork是主进程执行的会堵塞其他请求
解决:尽量缩短fork的时间
fork底层实现
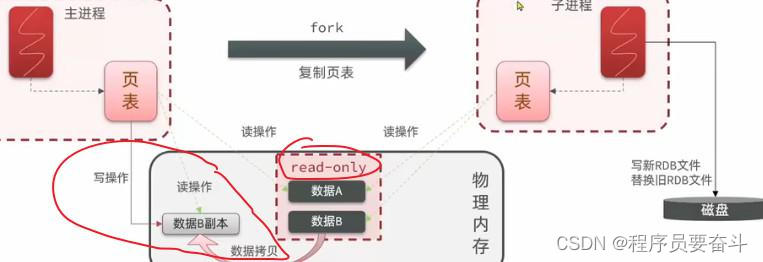
在Linux系统中所有的进程度无法直接操作物理内存,而是操作系统给每个进程分配虚拟内存,主进程只能操作虚拟内存,而操作系统会维护一个虚拟内存与物理内存之间的映射关系表,这个表称之为页表。所以主进程操作于虚拟内存,而虚拟内存基于页表的映射关系到物理内存真正的存储位置。这样就能实现对物理内存数据的读写。
执行fork时,会去创建一个子进程,拷贝主进程的页表,也就是把映射关系拷贝给子进程。而子进程有了和主进程一样的映射关系,当子线程在操作自己的虚拟内存时,由于映射关系和主进程一样,所以可以映射到相同的物理内存区域,这样就实现了子进程和主进程内存空间的共享。
这样就无需拷贝内存中的数据,直接实现内存共享,这个速度就会变得非常快,堵塞的时间就尽可能缩短了,而后子进程就可以读取自己的数据了,而后写入磁盘的文件中去。这样异步持久化就实现了。
问题3:
子进程在写数据到磁盘中的时候,主进程是可以接收请求修改内存中的数据的,这样可能会出现脏数据。
解决:
fork采用的是copy-on-write技术:
1.当主进程执行读操作时,访问共享内存;
2.当主进程执行写操作时,则会拷贝一份数据,执行写操作;
fork会将主进程和子进程共享的数据标记成read-only(只读模式),如果主进程要写的话就需要先将数据拷贝出来再执行写操作。如果执行了拷贝,主进程以后读也要到拷贝出来的地方读。
问题4:
在极端情况下可能会发生子进程写得比较慢,耗时比较久,而在写的过程中,不断有新的请求来修改共享数据,导致所有的数据都修改了,那么这种情况下所有数据都要拷贝一份新的导致内存翻倍。
解决:
一般情况下Redis都要预留一些内存空间,防止在做RDB时有内存溢出问题。
RDB总结
1.RDB方式bgsave的基本流程
1.fork主进程得到一个子进程,共享内存空间
2.子进程读取内存数据并写入新的RDB文件
3.用新RDB文件替换旧的RDB文件
2.RDB的执行时间
默认是服务停止时。(save)
满足配置文件中save条件时(bgsave)
3.RDB的缺点
RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
fork子进程,压缩,写出RDB文件都比较耗时
2.AOF持久化
AOF全称为Append Only File( 追加文件)。Redis处理的每一个写命令都会记录在AOF文件, 可以看做是命令日志文件。
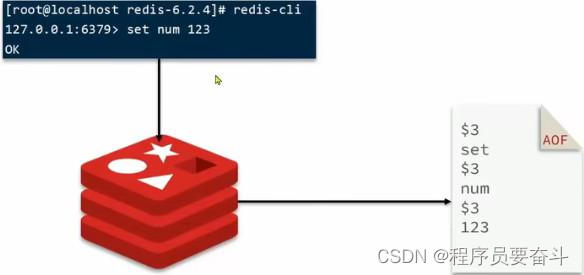
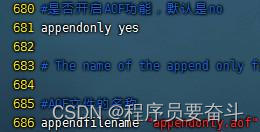
注意:AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF
注意:AOF的命令记录的频率也可以通过redis.conf来配置
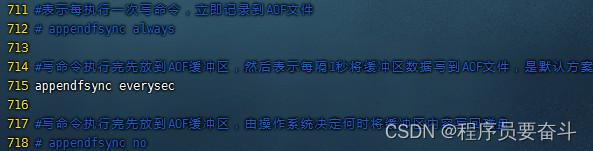
appendfsync always: 主进程立即将接收到的命令写到内存再记录AOF文件。
appendfsync everysec:将接收到的命令写到内存,再放到缓冲区,每隔一秒将缓冲区的内容写到AOF文件, 不是主进程往磁盘里写,性能得到了提高(内存方式的读写)
配置项 | 刷盘时机 | 优点 | 缺点 |
Always | 同步刷盘 | 可靠性高,几乎不丢失数据 | 性能影响大 |
everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
更改配置后重启
1.输入写命令后会生成AOF文件

2.关闭redis时会有AOF数据的再次检查
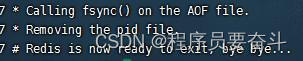
3.重启后数据会从AOF文件做一次加载

这样就实现了持久化和故障恢复
问题5:
RDB记录的是文件的值,而AOF记录的是操作,如果对同一个值做多次修改操作,RDB记录的只是最后的值,而AOF会记录每次的值,这样的话会导致AOF文件比RDB文件大很多。并且前面的操作都是多余的。
解决:
因为是记录命令,AOF文件会比RDB文件大得多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到同样的效果。

注意:
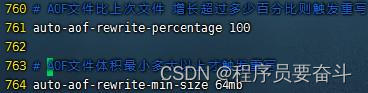
Redis也会在触发阈值时自动去重写AOF文件。阈值可以在redis.conf中配置
3.RDB和AOF的区别
RDB和AOF各自有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
RDB | AOF | |
持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
宕机恢复速度 | 很快 | 慢 |
数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源,但AOF重写时会占用大量CPU和内存资源 |
使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









