







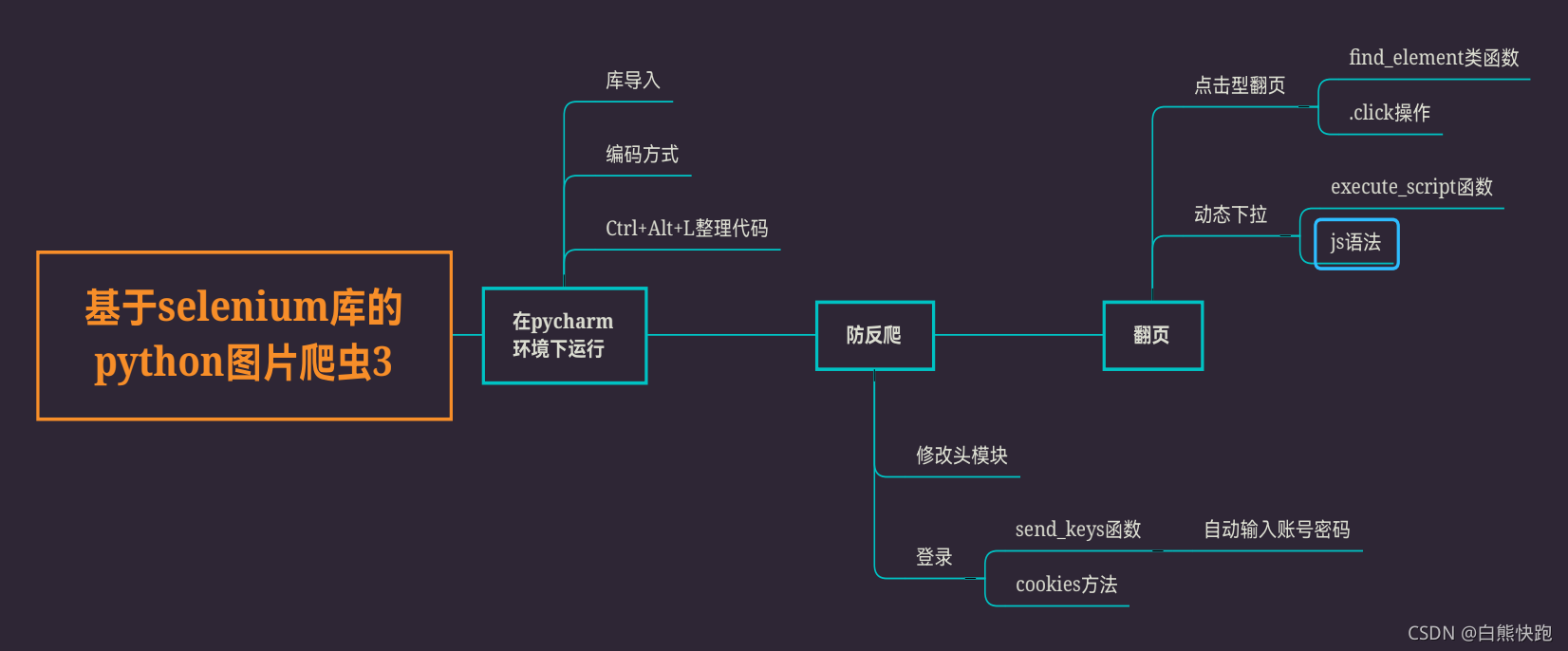
 本篇博客介绍了如何在PyCharm中配置和运行Selenium爬虫,包括设置项目、导入库、调整编码方式和使用快捷键。在防反爬方面,讲解了去除浏览器监测和模拟登录的方法。对于翻页操作,详细阐述了点击翻页和动态下拉加载的实现。此外,还强调了适时添加延迟的重要性。最后,提供了一些实用的Selenium代码示例,帮助读者更好地掌握Python爬虫技巧。
本篇博客介绍了如何在PyCharm中配置和运行Selenium爬虫,包括设置项目、导入库、调整编码方式和使用快捷键。在防反爬方面,讲解了去除浏览器监测和模拟登录的方法。对于翻页操作,详细阐述了点击翻页和动态下拉加载的实现。此外,还强调了适时添加延迟的重要性。最后,提供了一些实用的Selenium代码示例,帮助读者更好地掌握Python爬虫技巧。
目录
更新了!更新了!
我是白熊快跑,想必听完了前两章的你,已经十分了解python爬虫的基本思路,已经编出一个.py文件了。

那么今天,也就是在这个selenium系列的终章,我们就来说说如何在pycharm环境下运行你的爬虫程序,以及在此基础上在加以一点润色,离按下shift+F10就能轻轻松松自动爬到大量图片的目标就不远了!!
在IDLE调试好我们的程序后,直接Ctrl+C再Ctrl+V到pycharm中是欠妥的,在运行前还需要一点小准备。
一、pycharm小准备
在我们准备之前,你还需要新建一个项目(如果已有就不用了)
然后在该项目下创建python文件

现在你就可以把代码复制进入新开页面了!
接下来开始小准备
01库导入
前面章节我们说了在命令行窗口用pip语句下载python库,但是这个安好的库只能在命令行窗口和python的IDLE运行,而不能直接在pycharm运行
所以我们需要 File-->Settings-->Project xxx(你的项目名字,反正就是 Version Control 下面那个)-->Project Interpreter-->点击“小+号”
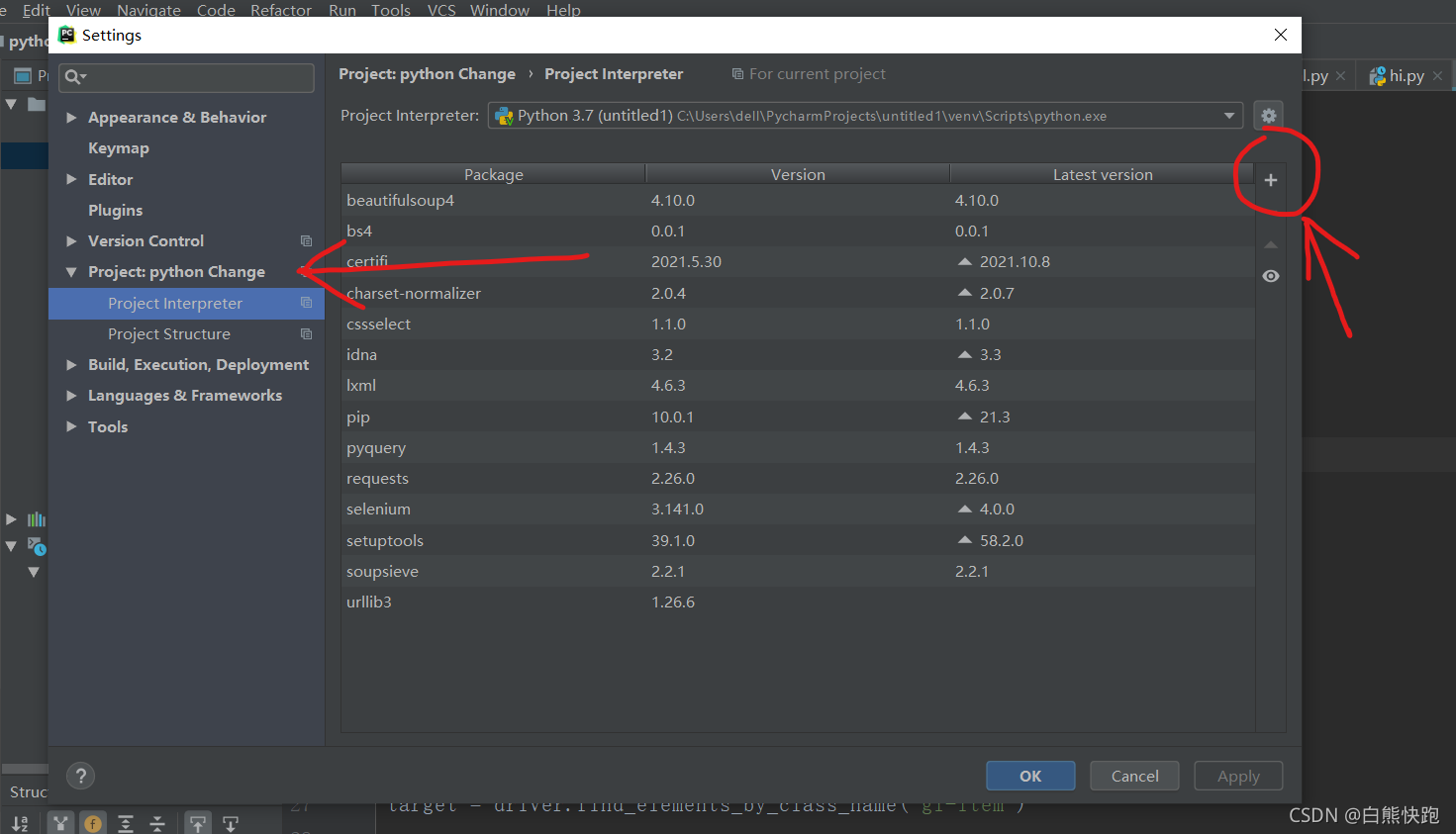
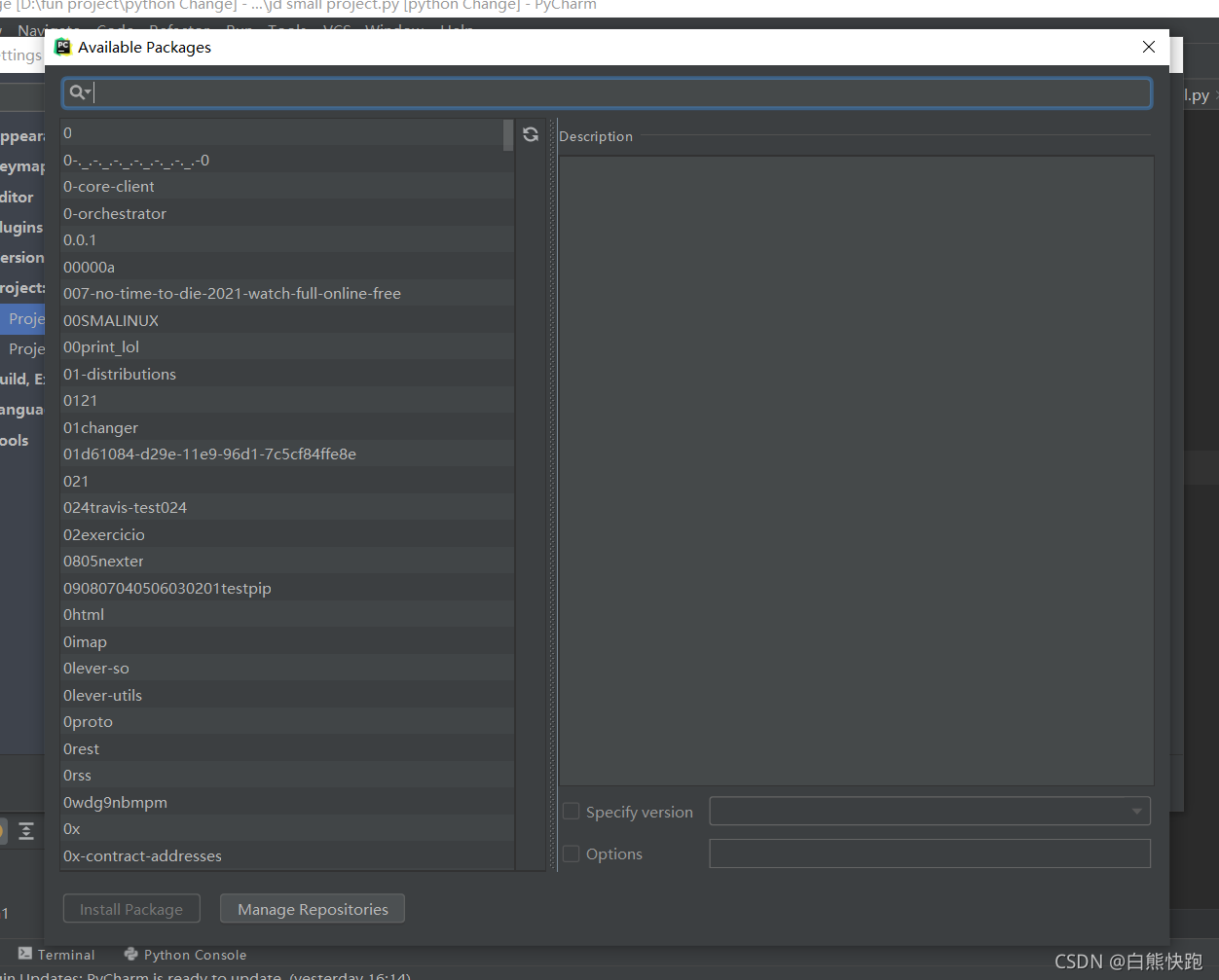
最后在弹出界面最上方的搜索框搜索需要的库,再点击左下角的 Install Package 就OK啦!(右侧多选框均不必勾选)
02编码方式
在python文件第一行写如下语句:
# -*- coding:UTF-8 -*-这指的是一种广泛编码方式,拥有对应的推荐程序格式和解析文本方式
总之,听说添加了这条语句的代码都会变幸运
03快捷键
关于pychram还有一些很方便的快捷键,比如常用的有
- Ctrl+Alt+L :可以自动整理程序格式!!!(比如给你自动加空格)
- Alt+1 :把左侧文件栏收起(再按则放出)
- shift+F10 :运行Run上一次运行的程序
最后还有一点注意
import time
time.sleep(2)适时加入延迟!
适时加入延迟!
适时加入延迟!
先前我们在IDLE编程时是一句句输入,相当于自带了延迟
但是在pycharm的爬虫过程中,如果进入一个新界面不加入延迟,网站就来不及完成加载,导致selenium库找不到元素,就会报错!!
二、防反爬
在 requests 库中,我们get网站时可以通过修改 headers 和 proxies 来修改头和ip,达到如入无人之境的防反爬效果(后面可能会写一写这个)
而在selenium库中,程序模拟浏览器访问网站,通常困扰我们的不是headers被人拦截,而是需要登录,当然,还有头顶那行小字(对于咱们小项目,ip不换也影响不大)
01去掉浏览器监测
先说怎么去掉头顶小字
其实就博主经验而言,小字不去除也影响不大
但是还是去掉比较好
from selenium.webdriver import Chrome # 谷歌浏览器
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)像这样创建 driver ,小字应该就被去掉了
02登录操作
这里分享两种登录方法
1.直接自动输入法
机智的小伙伴应该已经想过,既然selenium库能模拟浏览器,那么能不能模拟键盘鼠标操作呢
确实是可以的,在selenium库中可以对获取到的网络元素做click或者send_keys
下面还是以花瓣网为例

这里我们先试试找到登录健,然后点击它
button = driver.find_element_by_xpath('//*[@class="login bounce btn rbtn"]')
button.click()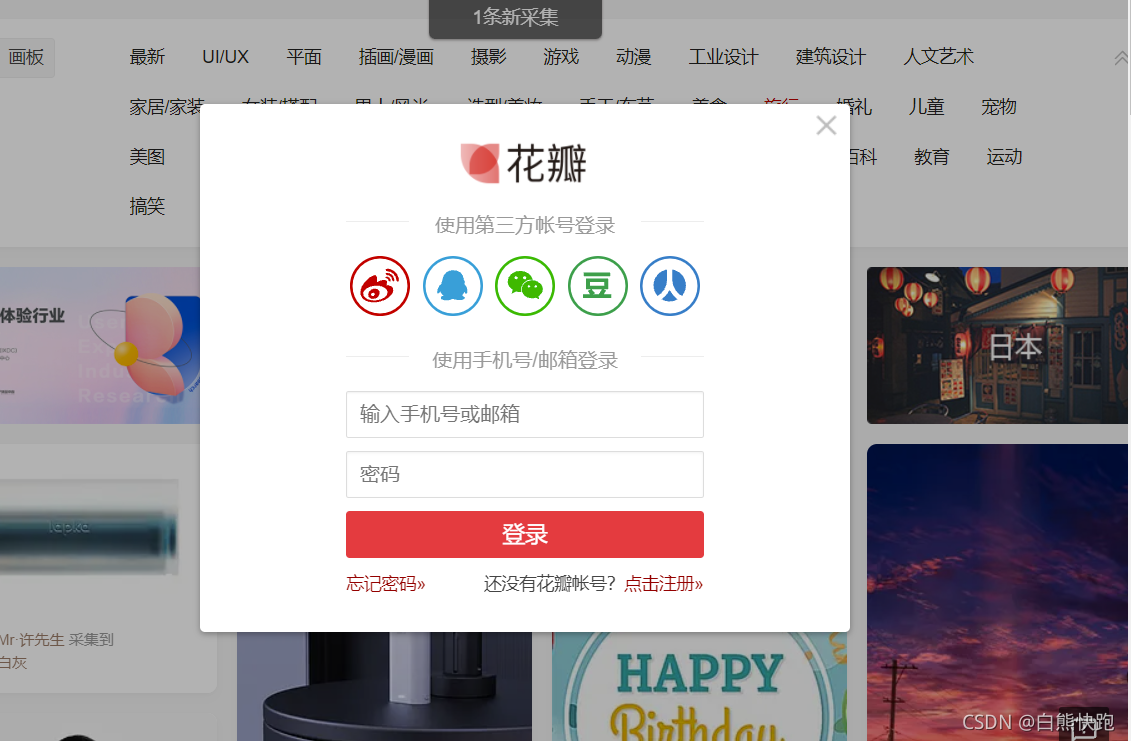
后面的操作思路是一样的,下面是完整的登录过程
from selenium.webdriver.common.keys import Keys
driver.find_element_by_xpath('//*[@class="login bounce btn rbtn"]').click() # 点击登录
button1 = driver.find_element_by_xpath('//*[@class="login"]//*[@class="mail-login"]/input[2]')
button1.send_keys('1372593xxxx') # 输入你的账号
button2 = driver.find_element_by_xpath('//*[@class="login"]//*[@class="mail-login"]/input[3]')
button2.send_keys('xxxxxx') # 输入你的密码
driver.find_element_by_xpath('//*[@class="login"]//*[@class="btn btn18 rbtn"]').send_keys(Keys.RETURN) # 按回车,登录成功
成功登录!
注意:
- 这种方法仅适用于登录简单的网页,复杂网页含验证码不推荐
- 需要在程序前import一个Keys,是用来按回车的
- 记得前面先把driver定义好!
2.cookies方法
有了解一点requests库爬虫的小伙伴可能知道在修改headers防反爬时,有一个东西叫cookies
这个东西简单来说,就是一个表示用户登录与否状态的参数
在网站中我们也可以查看(先不要直接复制!)


selenium库很棒的提供了可操作cookies的函数:
- driver.get_cookies() :以列表格式读取网站上的cookies
- driver.add_cookie() :向网站以单个元素添加到网站上
- driver.delete_all_cookies() :把当前网站上的现有所有cookies删除
于是我们可以进入网站,获取它的cookies保存成文件;然后删掉所有cookies,再读取我们创建的cookies文件添加到网站中
import json # 一个自带的库
with open('C:/Users/dell/Desktop/cookies.txt','w') as f: # 这是博主的文件路径
f.write(json.dumps(driver.get_cookies())) # 获取cookies
driver.delete_all_cookies() # 删掉网站现有cookies
with open('C:/Users/dell/Desktop/cookies.txt','r') as f:
cookies_list = json.load(f)
for cookie in cookies_list:
if 'expiry' in cookie:
del cookie['expiry']
driver.add_cookie(cookie) # 添加cookies注意:
- 需要先import一个python自带库json解析cookies
- 听说cookies元素(类型是字典)里面不能含有expiry这个值,所以把它删掉
- 先找一个文件夹创建一个cookies.txt,然后把该路径复制过来,注意了,注意了,把所有反斜杠改为斜杠!!!
三、翻页
01点击翻页
在selenium库里自动翻页比较简单,像前面登录那样 找元素-->点击元素 就可以了
在此之前你还需要一个拉到底部的操作
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')注意:括号内第二个参数就表示当前网页的高度
02动态下拉
上面那个拉到底部的操作非常神奇啊,但现在不是所有网站都有底的(比如某宝)
这时就需要我们慢慢地向下拉动网页
博主的思路是设定一个时间段让它下拉,到时间就停(还是花瓣网)
bottom = driver.find_element_by_id('page') # 覆盖整个网页那个元素
t0 = time.time()
height = 300 # 初次下拉值
dr_time = 40 # 想要爬取的时间
while Elem.height <= bottom.size['height']:
driver.execute_script('window.scrollTo(0, %d)' % height)
time.sleep(2)
Elem.height = Elem.height + 1000
t1 = time.time()
if (t1 - t0) > dr_time:
break注意:
- 代码中的bottom参数是覆盖整个网页的一个网络元素,目的是找到网页的高度,可以通过F12点击左上角小箭头,再将鼠标放在网页上寻找(找到后单击)

如图,找到覆盖面积最大的元素就是了 - size() 函数对网络元素使用,返回的是一个字典(这里取了它的 Height )
到本章为止,我们就要向基于selenium库的python图片爬虫画上一个完满的句号啦(但是python爬虫之路还远远没有结束!)后续大概会更新关于requests库制作ip池的内容,还请小伙伴们请多多点赞和关注,你的每一点鼓励或指正都对我很重要!!!
完整的爬取花瓣网图片代码我会放在下一章,然后还会附上一个爬取jd商品信息的案例。喜欢的朋友请追更~我们下期见啦!
(往期内容可在专栏查看~)

















 4409
4409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









