






一、开窗函数的概念
窗口函数是一种在 SQL 中用于处理查询结果集的强大工具,它可以对结果集的一部分进行计算,而不是对整个结果集进行聚合。它与聚合函数(如 SUM、AVG、COUNT 等)的区别在于,聚合函数将多行数据聚合成一个结果,而窗口函数为每一行计算一个结果,并且保留原始的行结构。开窗函数可以避免了在使用GROUP BY时,必须返回聚合列的情况,开窗函数可以同时返回基础列和聚合列,更加简洁,逻辑上更清晰。
SQL中规定,在查询使用分组时,任何没有出现在group by 子句中的属性如果出现在select或者having子句中,它只能作为聚集函数的参数,否则查询是错误的。例如:
/*错误查询*/
select dept_name, ID, avg(salary)
from instructor
group by dept_nameID属性没有出现在group by中,但它出现在了select子句中,这样的查询是错误的,它只能像salary属性一样作为聚集函数(avg)的参数出现。这也是传统group by使用时复杂头疼的地方,所以我们介绍窗口函数,窗口函数不存在这类限制。
二、语法结构
窗口函数的一般语法结构如下:
<窗口函数> OVER (
[PARTITION BY <列名>]
[ORDER BY <列名> [ASC | DESC]]
[ROWS | RANGE <窗口范围说明>]
)<窗口函数>:可以是聚合函数(如 SUM、AVG、COUNT、MIN、MAX 等),也可以是专用的窗口函数(如 RANK、DENSE_RANK、ROW_NUMBER、NTILE 等)。PARTITION BY <列名>:将结果集按照指定的列进行分区,类似于 GROUP BY 的作用,但不同的是,分区不会将结果集压缩,而是为每个分区单独计算窗口函数。ORDER BY <列名> [ASC | DESC]:在每个分区内,按照指定的列对行进行排序,为窗口函数的计算提供有序的数据序列。ROWS | RANGE <窗口范围说明>:指定窗口的范围,用于确定参与计算的行集。ROWS:基于行的范围,例如ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING表示当前行的前一行、当前行和后一行参与计算。RANGE:基于值的范围,例如RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW表示从分区开始到当前行(包括当前行)的所有行,并且对于RANGE,是基于ORDER BY列的值范围,而不是行号。
三、常用的窗口函数类型
1.聚合类窗口函数:
SUM():计算窗口内的总和。AVG():计算窗口内的平均值。COUNT():计算窗口内的行数。MIN():找出窗口内的最小值。MAX():找出窗口内的最大值。
例如,用SUM作为窗口函数:
select employee_id, department_id,
sum(salary) over (partition by department_id order by salary) as cumulative_salary
from employees上述sum语句中,计算了在每个部门内部,按照薪资升序排列的累计工资,它会计算从部门内第一个员工到当前员工的工资总和。
2. 排序类窗口函数:
ROW_NUMBER():为每一行分配一个唯一的、连续的数字,从 1 开始,按照ORDER BY的顺序。RANK():为每一行分配一个排名,相同的值会得到相同的排名,排名会跳跃(如 1, 2, 2, 4)。DENSE_RANK():为每一行分配一个排名,相同的值会得到相同的排名,但排名是连续的(如 1, 2, 2, 3)。NTILE(n):将结果集划分为 n 个桶,并为每一行分配一个桶编号,从 1 到 n。
这是一个使用dense_rank()函数的例题——“分数排名”
表: Scores
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | score | decimal | +-------------+---------+ id 是该表的主键(有不同值的列)。 该表的每一行都包含了一场比赛的分数。Score 是一个有两位小数点的浮点值。
编写一个解决方案来查询分数的排名。排名按以下规则计算:
- 分数应按从高到低排列。
- 如果两个分数相等,那么两个分数的排名应该相同。
- 在排名相同的分数后,排名数应该是下一个连续的整数。换句话说,排名之间不应该有空缺的数字。
按 score 降序返回结果表。
查询结果格式如下所示。
示例 1:
输入: Scores 表: +----+-------+ | id | score | +----+-------+ | 1 | 3.50 | | 2 | 3.65 | | 3 | 4.00 | | 4 | 3.85 | | 5 | 4.00 | | 6 | 3.65 | +----+-------+ 输出: +-------+------+ | score | rank | +-------+------+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 2 | | 3.65 | 3 | | 3.65 | 3 | | 3.50 | 4 | +-------+------+
针对这个题,我们只需要使用dense_rank()就可以完成。partition by部分为空默认以整个表为一个分组。
代码如下:
SELECT
S.score,
DENSE_RANK() OVER (ORDER BY S.score DESC) AS 'rank'
FROM
Scores S;输入:
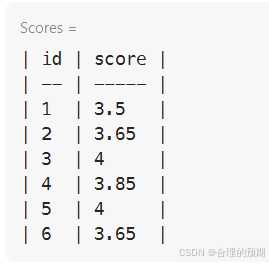
输出:
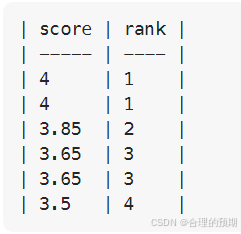
3.分析类窗口函数:
LAG(<列名>, <偏移量>, <默认值>):返回当前行之前第 n 行的值,如果不存在则返回default值。LEAD(<列名>, <偏移量>, <默认值>):返回当前行之后第 n 行的值,如果不存在则返回defalut值。FIRST_VALUE(<列名>):返回窗口内第一行的值。LAST_VALUE(<列名>):返回窗口内最后一行的值。
例如,lag()函数:
SELECT
employee_id,
department_id,
salary,
LAG(salary, 1, 0) OVER (PARTITION BY department_id ORDER BY salary) AS previous_salary
FROM
employees;此语句将返回每个部门内,当前员工前一位员工的工资,如果没有前一位员工,则返回 0。
四、窗口函数的应用场景。
1.计算累计值和平均移动值:
可以使用SUM()和AVG()来计算累计值和平均移动值,在一些时间序列的题上可以用到。
2.排名和排序:
rank(),dense_rank(),row_number(),这个是我自己做题用的最多的窗口函数,在很多要查询分类,排序的的案例中很有用。
3.前后数据比较:
lvg(),lead(),可以比较两个相邻段的数据,包括当前数据和前后数据。

















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









