






wlt嵌入式课程
C语言学习
第八章
8-9 内部函数与外部函数
extern定义函数为外部函数,随时可以调用,一般省略extern为直接定义为外部函数
static定义函数为内部函数,使用时只能在该内部函数所在文件中被调用,别的文件无法直接调用,可间接调用,即在该内部函数所在文件中定义外部函数调用该内部函数,然后在其他文件中调用这个调用了内部函数的外部函数,即可实现调用不在同一文件下的内部函数。
优点:
同一个工程下的不同文件可使用内部函数定义多个同名文件,使用时函数互不影响
8-10 内联函数
函数被调用时,内部实际操作比较复杂,首先是栈指针指向函数,然后栈指针往下走,走到需要调用另一个函数,再跳到另一个栈指针,再接着往下走,当一个函数大量被调用时,同时也带来了大量的指针操作,浪费很多时间。
在这时候使用内联函数,省去大量函数入栈出栈的操作,执行速度比一般函数快。内联函数实际使用时,就是讲所需要调用的函数内容直接复制到调用函数的位置,进行编译,正常函数是直接跳到所调用的函数里执行这个函数,然后执行完再退出这个函数,然后正常执行主函数下边的内容。
内联函数一般要求尽量短小,效率才会高,太长的内联函数,编译器可能会当做一般函数处理。
优点
提高函数调用的效率
8-12 开发自己的库函数
首先当需要给别人开发某些功能,但又不想让别人知道源码,这时候就需要把源码以库文件的形式发送给别人。
静态链接库
静态链接库就是使用时直接把库内部的程序直接拷贝到使用的位置,占用内存比较大。
动态链接库不进行拷贝,使用时才进行入栈出栈操作,动态库的后缀名为.dll
9-1 数组的基本概念
输入函数scanf(),当输入控制符里用逗号隔开,那么在控制台中输入的时候也要用逗号隔开,如果控制符没有隔开,那么输入时可以使用tab,也可以使用空格进行隔开
数组的输入输出都是要用循环进行依次输入输出
数组特殊初始化方式,特殊初始化方式,也叫指定初始化,C99新增的初始化方式,比如指定数组的某一位进行赋值,例如:
int a[10] = {[0] = 1,[9] = 2}
定义了一个a数组,然后仅给a数组的第0位和第9位赋值
数组的大小:
定义int 数组,数组中每个元素占内存为int 所占大小,整个数组所占内存为每搁元素所占内存的总和。
数组名字与数组地址
当数组名用作sizeof()或&的操作数时,sizeof返回的是整个数组的字符长度,&取地址取得也是整个数组的地址,例如:
char a[10];
printf("%d %d\n",a,&a[0]);
printf("%d %d\n",a+1,&a[1]);
a 是代表整个a数组的地址
&a[0] 同样是代表整个数组的地址
a+1加的是地址指向下一个元素,具体十六进制地址变化多少取决于该元素的大小。
&a[1]是a[1]这个元素的地址
数组的地址和数组首个元素的地址是相等的,但是意义不一样,当地址进行加一操作时,数组的地址加一变化的长度是整个数组的长度,而数组首个元素的地址进行加一操作,地址变化的长度是一个元素的长度。
数组名代表的是首个元素a[0]的地址也就是&a[0],而不是数组的首地址&a
数组名a+1表示下一个数组元素的地址,而&a+1是指向下一个数组的地址
9-2 二维数组
二维数组其实是特殊的一维数组,因为二维数组内部存储的是一维数据
int a[2][3] = {{1,2},{4,5,6}}
这种定义方式,最终的效果是这个二维数组的第一行是1 2 0,第二行是 4 5 6
在从键盘获取数组数值的时候
for(i = 0,i < 2,i++)
for(j = 0,j < 3,j++)
scanf("%d",a[i]+j)
a[i]+j这种获取方式,是地址的形式,和&a[i][j]作用一样
如果使用a[i]+j这种方式,特别要注意不能再a[i]前边加&,如果是首地址加一,那就是直接跳到了下一个行
在二维数组中a[0]代表这一行数组的首地址,然后+j是从首地址往后加一,也就是一点点取到了下一个地址
三维数组可以理解为用一维数组存放二维数组
字符数组与字符串
字符数组就是存放字符的数组
char str[20] = {'h','e','l','l',o'};
printf("%c",str[1]) //单独打印这个这个字符数组中下标为1的元素
for(i = 0;i < 20;i++)
printf("%c",str[i]) //按照循环依次打印整个字符数组
printf("%s",str) //输出控制符是%s为按照字符串格式输出,输出str整字符串
puts(str) //直接输出整个字符串
定义二维字符数组
char str[][5] = {{'h','e','l','l','o'},{'w','o','r','l','d'}} //定义时可以省略一维的下标,但二维下标不能省略
char str[10] = {104,101,108,108,111} //以ASCII值来定义
字符串和字符不同,字符串结尾都有\0作为结束符,且这个结束符占一字节的内存
字符串处理函数
#include<string.h> //常用的字符串处理函数
char str[100];
gets(str);
printf("%d %d",sizeof(str),strlen(str)); //输出第一个是100,第二个是10 因为定义的内存空间是100 ,strlen是计算实际字符串长度的函数
char str1[5] = {"json"};
char str2[5] = {"zhan"};
printf("%s",strcpy(str1,str2)); //此时的打印输出结果就是zhan,strcpy(a,b)是字符串拷贝函数,就是把b中的字符覆盖掉a的字符
printf("%s",strncpy(str1,str2,2)); //strncpy(a,b,c)按字节拷贝函数,就是strncpy比strcpy多了一个n,然后c是数值,就是拷贝的字节数,如果拷贝的字节数小于a中字节数,那么只会从a中的第一个字符开始覆盖
char str1[5] = {"json"};
char str2[5] = {"zhan"};
printf("%s",strcat(str1,str2)); //此时的打印输出结果就是jsonzhan,strcat(a,b)是字符串连接函数,就是把b中的字符连接到a的字符,放到a中字符的后边
printf("%s",strncat(str1,str2,2)); //strncat(a,b,c)按字节连接函数,就是strncat比strcat多了一个n,然后c是数值,就是连接的字节数
注意字符输入时候的gets和scanf的区别gets只有遇到回车键才会结束获取字符,而scanf遇到空格就会结束
数组作为函数参数
数组元素作为函数参数
数组名作为函数参数:
代表的是数组的首地址,传给函数的是地址,或者叫常量指针
注意:
数组名作为函数参数是,其实传递的是一个地址指针,形参和实参的类型必须一致。
形参和实参数组的长度可以不相同,关于数组的长度可以通过另外的参数传递进来
多维数组作为函数的参数时,在函数定义时对形参数组可以指定每一维的长度,但是可以省去第一维的长度。
二维数组作为函数参数
使用static修饰数组参数
9-3 变长数组
int len = 10;
int array[len]; //数组的下标是变量,成为变长数组
变长数组的存储和作用域
变长数组采用动态存储
在函数体或代码块内声明
不能使用static或extern修饰
作用域:从声明处到代码块结束
下次执行这个代码会重新创建一个新的数组
10-1 指针的基本概念
int a;
a = 30;
int *p = &a; //定义一个指针p,把a这个变量的地址传给指针p
取址&运算符和取值*运算符
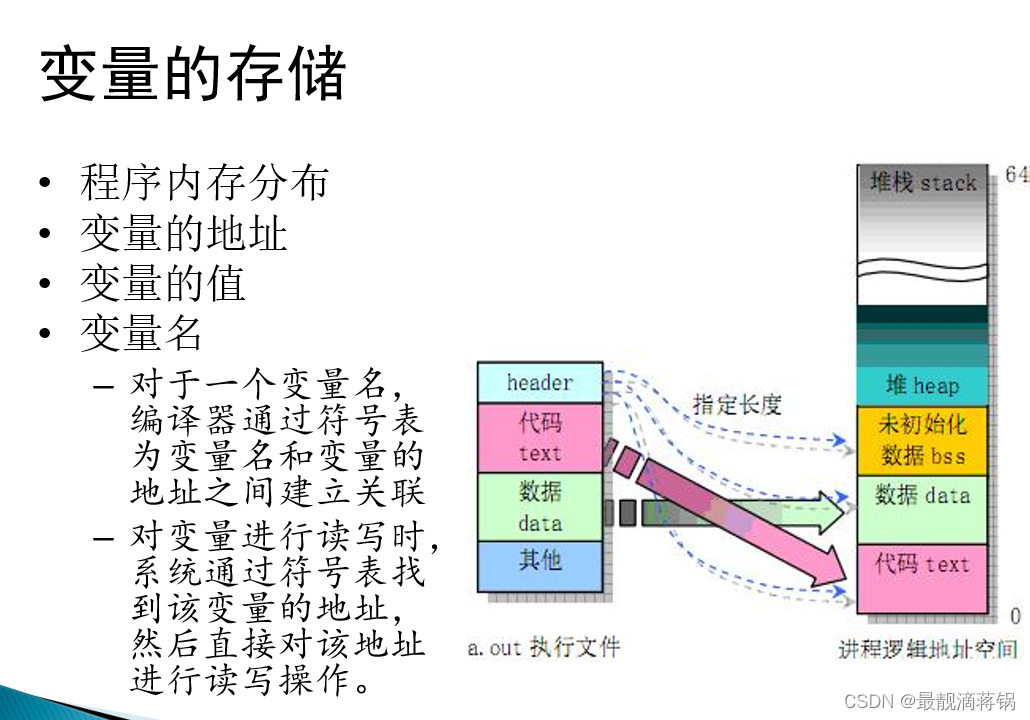
一个可执行文件.exe,代码段和数据段是分开的,定义一个变量,相当于定义一个数据,而printf语句相当于是一个指令,就被编译器认为是代码,程序中有代码和数据,当整个程序编译的时候,编译器会自己分,把每一个语句分为代码和数据,然后把数据和代码分别放在数据段和代码段,然后链接在一起,再把库文件加一些头子,生成可执行文件,可执行文件放在硬盘里,然后我们执行的时候,他把可执行文件放在内存中,从内存中执行,在内存中和实际的可执行文件结构还是有区别得,然后代码段基本没区别,读取的时候直接从硬盘考到内存中,数据段,不同的变量,有不同的存储方式和不同的作用域,存储空间分为动态区和静态区全局变量属于静态存储区,在内存中只要程序不退出就一直存在,静态存储区也分为两种,一种是已经赋值过的全局变量,和没有赋值的全局变量,这两种全局变量在内存中的存储也是不同的,初始化和未初始化,未初始化的放在未初始化的bss区,没有生成标志符,初始化过得放在数据data区。未初始化的变量存储:比如说定义了10个每个4字节的全局变量,然后头文件会指定一段bss区,给这些未初始化的变量分配空间,指定长度。
动态存储区:堆栈。
局部变量,存放动态存储区,只有当程序运行时,才会给这些变量分配内存,分配到堆栈之中。
int main{
prinrf("%x",__func__); //打印所在函数的地址也就是主函数的入口地址,也就是代码段的底端
}
理解:
在linux操作系统下静态存储区是从下往上存储,代码段,数据段都是从下往上存储,也就是实际反映到地址上是新地址比旧地址增加,动态存储区,从栈顶压入,然后一次向下存储,所以进入动态存储区的地址新地址比旧地址依次减小,在动态存储区和静态存储区有一部分未分配的存储区,当动态存储区占满以后仍需动态存储,就把这部分未定义的存储区,当做动态存储区,使用结束后自动释放,当静态存储区占满以后也是如此。
linux操作系统内存入口地址:
stack: bf82ceb8
heap: 9743008
…
bss : 8049980
data : 8049900
code: 80486b0
符号表
从汇编语言的角度来看,当一个变量名生成的时候,编译器会生成一个表格,这个表格的内容为该变量的数据,例如该变量的数值,地址,等,编译器用过查找符号表为变量名和变量的地址之间建立关联
对变量进行读写时,系统通过符号表找到该变量的地址,然后直接对改地址进行读写操作。
指针变量
10-2 指向变量的指针
int i = 10;
int *p = &i; //定义一个指针变量的一种方法
int *p;
p = &i; //定义一个指针变量的另一种方法
printf("%x %x",&i,p);
printf("%x %x",&i+1,p+1);//&i+sizeof(int),地址加一其实是加的一个变量长度
printf("%d %d %d",sizeof(i),sizeof(&i),sizeof(p),sizeof(*p));
//当程序在64位计算机上结果是4 8 8 4
//当程序在32位计算机上结果是4 4 4 4 ,主要原因是不同的编译器,给变量分配的内存不同
未初始化的全局变量放在bss段
未初始化的局部变量编译器会在内存中随即给这个变量附一个值,然后存放在动态存储区。
10-3指向数组的指针
数组与指针的关系
1 数组与指针的联系
- 数组名可以看做是一个常量指针
- 数组作为参数时,会退化为一个指针
2 数组与指针的区别
- 数组是一种数据结构,而指针是一种整型变量
- 保存的值不同:指针保存数据的地址,数组保存数据
- 访问值的方式不同:指针通过*(取值运算符)间接访问,数组通过下标直接访问或通过*(取值运算符)间接访问
3 数组名与指针
- 数组名的内涵在于其指代实体是一种数据结构:sizeof/&
- 数组名的外延在于其可以转换为指向其指代实体的指针,而且是一个指针常量
- 指向数组或者数据类型的指针则是一个整型变量,其存放的是这个数组或者数据变量的地址,而数组名没有单独的空间存放.
10-3指向数组的指针
int a[10] = {1,2,3,4,5,6,7,8,9,0};
int *p = a[0];
///
for(int i=0;i<10;i++)
printf("%d",a[i]);
///
for(int i=0;i<10;i++)
printf("%d",p[i]);
///
for(int i=0;i<10;i++)
printf("%d",*(a+i));
///
for(int i=0;i<10;i++)
printf("%d",*(p+i));
///
这四种打印数组的方法结果都是相同的,原理就是把数组的首元素的首地址传给指针p指针p指向昂的地址就是a数组的首地址,然后由于数组在内存中的存放是按照从首元素依次排列得到,然后指针依次向下遍历也是按照顺序遍历。
注意
引用数组元素时,有两种方式一种是通过引用数组下标来引用数组元素(方式一、二),另一种是通过指针的方式(方式三、四)
当采用数组下标去数组元素的时候,具体的取元素过程是:
- a[i],第一步首先a数组的首地址,然后通过计算偏移值i*sizeof(int/char…)得到偏移值(地址)
- 第二步对改地址进行取值操作
当采用地址遍历后取值的方法,取数组元素的过程是:
- 直接根据地址,进行取值
以上两种,明显直接对地址操作,效率会更高
数组指针作为函数的参数
数组名作为函数的参数会退化为一个常量指针
a与&a的区别
a: 指向数组元素的指针
&a:指向整个数组的指针
int a[10] = {1,2,3,4,5,6,7,8,9,0};
int *p1 = a; //p1代表a数组的首地址
int (*p2)[10] = a; //(这里a也可以用&a但是可能会有警告)这个时候的p2和&a意义相同都是代表整个数组
printf("%d %d",p1,p1+1);
printf("%d %d",p2,p2+1);
printf("%d %d",a,a+1);
printf("%d %d",&a,&a+1); //首地址加1是加的一个元素的宽度,真个数组的地址加一加的是整个数组宽度
10-4指向二维数组的指针
指向二维数组的指针与地址的关系
指向二维数组元素的指针与地址的关系
int a[2][3]={{1,2,3},{4,5,6}};
int i,j;
int (*p)[3] = a; //指向数组的指针
for(i=0;i<2;i++)
for(j=0;j<3;j++)
printf("%d ",p[i][j]);//a[i][j] //可以理解
for(i=0;i<2;i++)
for(j=0;j<3;j++)
printf("%d ",*(a[i]+j));//*(p[i]+j) //~~这是一种按照地址的方法取数组元素,首先是所有数组元素都在内存中依次排列,所以地址也是依次排列的,当要取a[1][2]时 先是指针从[0][0]从0走到1,然后走3格,因为虽然时二维数组但还是可以按照一维数组来理解相当于一行前三个数是这个数组的第一行,后三个数是这个数组的第二行,然后走三格....好像说错了,~~ 应该是先看 a[i]这一个地址,首先是如果要找a[1][2]这个元素,先定位到a[1]的地址,也就是定位到第1行,然后地址加j,找a[1][2]的话就是加2,然后指针往右走2,就是了。
for(i=0;i<2;i++)
for(j=0;j<3;j++)
printf("%d ",*(*(p+i)+j));//*(*(p+i)+j)
int *pa = &a[0][0];
for(i=0;i<2;i++)
for(j=0;j<3;j++)
printf("%d ",*((pa+i*3)+j));
注意:
指向一维数组的指针,定义方式:
int a[3] ={1,2,3};
int *p = a;
一维数组的a[1]是指第1个元素 2
指向二维数组的指针,定义方式:
int a[2][3] = {1,2,3,4,5,6};
int (*p)[3] = a;
然后地址法取值a[1]这个存放的第一行元素的地址,然后a+1是从二位数组首元素的首地址也就是a[1]的地址那么*(a+1)代表a[1]的地址,然后然后对这个行地址进行偏移操作,就是取列地址,(a+1)+1这加一就是寻到了a[1][1]的地址了,然后※((a+1)+1)也就是给(a+1)+1这个地址再取值就得到了这个位置的数组元素
10-5指针数组
指针数组
存放指针的数组
数组指针
指向数组的指针
//定义指针数组
char *p[3]={
"hello",
"2022",
"Jiang",
}
int i;
for(i=0;i<5;i++)
printf("%d\n",p[3]); //打印这个指针数组的内容
printf("%d\n",sizeof(p)); //打印这个指针数组的大小
编译器给指针数组分配的大小是按照指针的大小分配内存,其中指针指向的内容的大小并不是存放在指针数组的内存中,而是被编译器放到了其他地方,所以打印sizeof§的结果是4*3是12,4是一个指针变量的大小,3是三个指针变量,这是整个指针变量的大小
10-6指向字符串的指针
- 字符串指针的定义、初始化与使用
- 字符串指针作为函数的参数
- 字符串指针变量与字符数组的区别
在栈中分配单元,
char *str = "hello world";
//在这里定义的字符指针首先str这个指针指向字符串“hello world”然后直接使用str代表字符串的首地址, 这个字符指针自己的地址编译器在的栈中存储,对这个str字符指针的地址进行取址操作得到的是“hello world”的地址
10-7指向指针的指针
指针指向的数据类型还是指针,就叫指向指针的指针,简称二级指针
int i = 8;
int *p = &i;
int **pp = &p;
printf("%x %x",p,pp);
printf("%x %x",p,&i);//这俩是一样的
printf("%x %x",pp,&p);//这俩是一样的的
printf("%d %d %d",*p,i,**pp);//这仨是一样的,取得都是数值
10-8 指向函数的指针
定义一个变量还是函数都会生成一个符号表,符号表里是这个变量或者这个函数的各种数据,函数入口地址啥的
- 指向函数的指针的定义、初始化、使用
int fun(){
putchar("hello fun!");
} //定义一个函数
int (*p)();// 定义一个指向函数的指针
p = fun; //把函数的地址给这个指针,也可以 p = &fun;
p(); //调用这个函数
(*p)(); //调用这个函数
(**p)();//同样调用这个函数
- 指向函数的指针作为函数的参数
int main(){
int a = 5,b = 6;
calc(a,b,&add); //主函数使用时计算器函数参数有计算时所需要的的数值和要进行哪个计算的函数的地址
calc(a,b,&sub);
}
int add(int a,int b){ //正常定义加法函数
return (a+b);
}
int sub(int a,int b){ //正常定义减法函数
int c = 0;
if (a>b)
c = a-b;
else if(b>a)
c = b-a;
else
c = 0;
return c;
}
void calc(int a,int b,int (*fp)(int x,int y)){
int result = 0;
result = fp(a,b);
printf("result:%d\n",result);
}//定义一个计算器函数,这个函数通过函数指针调用加减法函数
10-9 指针函数
函数返回值是指针的函数,就是叫指针函数
函数返回值是字符的函数,就叫字符函数
函数的类型根据这个函数的返回值类型来确定的
char *month[]={ //month存放在静态存储区
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"
};
char *month_check(int i);//函数声明
int * my_add(int a,int b);//函数声明
int main()
{
char *p;
p = month_check(1);
printf("%s\n",p);
int *q;
q = my_add(2,6);//这一行调用函数,结果确实是正确的但是实际的地址已经释放了
my_add(20,60);
my_add(40,60);//这两行调用会重写这个q的值
printf("%d\n",*q);
return 0;
}
char *month_check(int i)
{
return month[i-1];
}
int * my_add(int a,int b)
{
int c;
int *p = &c;
c = a + b;
return p; //这里返回的是c的地址但是由于c是一个局部变量,函数结束后这个局部变量的地址会被释放,导致虽然所在地址的值暂时没有被改写,但是实际地址已经不是c了
}
指针函数返回的指针主要指针指向的是静态的全局变量地址,而不能是局部变量,局部变量会被改写
10-10 const关键字修饰指针
- const 修饰变量
const修饰变量以后这个变量成为一个常量,常量无法再次修改
const int a = 8; //此时a被const锈蚀以后变成常量,a就是8是这个常量而不是给a赋值8
a = 9; //这句话相当于 8 = 9,当然就不对了
- const 修饰指针
- 变成指向常量的指针
指向常量的指针不能修改指针所指的数值,但是可以修改地址
- 变成指向常量的指针
int a = 9;
int b = 8;
const int *p = &a; //const 放到int前后都可以,此时这个指针是一个指向常量的指针
p = &b;//这一句可以执行,
*p = 8;//这一句不行,不能修改常量
- 常指针
不可以修改地址,但可以修改地址所指向的值
int a =9;
int b =8;
int * const q = &a;//此时定义的这个指针q经过const修饰以后变成常指针,
q = &b;//这一句有错误,不能修改常指针的地址
*q = 8;//这一句没问题,可以修改常指针所指向的数值
- 指向常量的常指针
既不可以修改地址,也不可以修改数值
int a = 8;
int b = 9;
const int *const q = &a;
q = &b;//不能这样修改
*q = 9;//也是不能这样修改
- 扩展到数组
int a[10];
a[0] = 1; // 正常的数组给第0位赋值
int const b[10];
b[0] = 9; //const修饰以后不能给数组元素赋值
10-11指针数足作为main函数参数
-
入口函数main的两种标准定义方式
-
指针数组作为函数的参数
-
实现一个简单的计算器
10-12 restrict关键字修饰指针
同一块地址可能被多个指针指向,然后可以指向这一块地址的指针可以被restrict修饰,某个地址的指针被修饰过后,这块地址只能由这一个被修饰的指针所使用的,使用别的指针修改这一块地址的内容是不可以de,该被修饰的指针是访问指针指向数据对象的唯一方式。
- 优点
帮助编译器更好的优化代码
提醒用户要使用满足restrict要求的参数
11-1结构体的基本概念
数据类型分为基本数据类型和构造数据类型
基本数据类型 :int、float、char…
构造数据类型:由几种基本数据类型组成的数据类型
- 定义结构体
struct person //关键字struct,person是结构体名
{
char name[10]; //结构体包含char int数据类型
int age;
char sex;
}p1,p2;//定义两个person结构体的类型,定义类型不分配内存,但是定义p1,p2才会给p1 p2 分配内存
struct person p3,p4;
struct student //定义一个结构体student,如果其他地方再也不会用这个结构体了,那么
{
struct person p; //student结构,包含一个person结构体,还有uint,float
unsigned int stu_num;
float score;
}stu1,stu2 = {{"kate",22,'F'},12330,99};//stu1,stu2都是student结构体,然后stu2赋值操作,初始化
struct student stu1; //第二种初始化方法,如果没有使用第一种初始化方法,又单独拉出来初始化,就像定义数组的时候要么定义的时候一次性初始化,要么就是一个一个的初始化
struct stduent stu1;//上边已经在结构体末尾stu1,stu2,这里可以不用这一句再重复定义了
strcpy(stu1.p.name,"Jiang");
stu1.p.age = 20;
stu1.p.sex = 'M';
stu1.stu_num = 2333;
stu1.score = 80;
struct person *pt;
AMBA总线协议,cpu与片上外设连接协议,一个裸cpu想要给各类外部设备连接实现功能,Ram公司生产的cpu都需要AMBA总线协议。
AMBA总线协议有一个内存对齐的说明,就是说结构体在实际内存分配的过程中是需要字节之间对齐的,因为在数据读取的时候是尽可能的一次总线周期就把所有数据全部拉起来,不然后如果内存么有对齐,两次总线周期,这会大大降低cpu的读取效率。
内存对齐
- 字、双字和四字在内存中没有强制必须对齐
- 访问未对齐的数据访问需要两次总线周期
- 编译默认将结构体中的成员数据内存对齐
结构体的存储
- 结构体只要保证成员变量在内存中的存放顺序,但不能保证所占内存的大小
减少结构体存储空间的浪费
- 重组数据成员:边界要求最严格的先出现
理解
在结构体存储的时候遵循AMBA总线协议,内存对齐,就是四字节一位以上述程序中结构体为例:第一个结构体成员为一个十字节的字符数组占了是个字节,但是下一个成员是一个整型需要四个字节,如果挨着上一个字符数组的后边存储,就会导致四个取一次的话,整型数据的前两个就会跟着字符数组的后两个一起,这样导致一次取不到整型变量,然后就有了内存对齐的说法,也就是存放完第一个字符数组以后,空两格,到第13个字节,再接着存储整型成员,这样的话,就是一次总线周期就能把数据取完,接下来也是整型成员之后的五个字节的字符数组成员,接下是第十八个字节开始,还不是4的倍数,就必须再空两格,直接从第20个字节开始存储,然后存储五个字节以后,整个结构体变量存储完毕,总共占据25个字节,但是共存储了一个十字节的字符数组一个整型变量,一个五字节的字符数组,一共是19个字节的内容,所以说,结构体变量所占的字节并不一定是所有结构体成员的字节总和。然后这个方法缺点也很明显,就是浪费了很多内存,所以尽量减小内存浪费的方法就是尽量把成员中比较边缘界定严格的放到前边,可变的数组之类的,放到后边。
- 64位机器指针是8个字节
- 32位机器指针是4个字节
11-2 结构体数组
数组元素是整型变量,成为整型数组,
数组元素存放的是一维数组成为二维数组,数组元素存放的是 二维数组,称为三维数组…
数组元素是结构体,称为结构体数组
-定义时初始化
可部分赋初值
内部大括号可以省略
数组长度可以省略
struct person{
char name[10];
char sex;
int age;
}p1,p2;
struct student {
struct person p;
int num;
int score;
};
struct stu1 [10];
stu1[0].num = 1001;
stu1[0].score = 99;
stu1[0].p.age = 21;
struct stu2 [10] = {
{{"Jiang",'M',18},1001,100},
{{"Zhang",'F',18},1002,99},
{{"Wei",'F',18},1003,98},
{{"Xia",'F',18},1004,97},
};
for(int i = 4;i<5;i++)
scanf("%c %c %x %d %d",student[4].p.name,student[4].p.sex,stduent[4].p.age,stduent[4].num,student[4].score);
stu2[5] = stu2[4];
for(int i = 0;i<7)
printf("姓名:%c 性别 %c 年龄:%d岁 学号:%d 成绩 %d");
- 数组元素之前可以整体赋值
- 输入输出操作只能对数组元素的成员操作
结构体数组作为函数参数
结构体数组作为变量传参数,传递的不是地址,整而是个结构体的整体,和数组传参不同
11-3指向结构体的指针
一个指针指向整型变量叫整型指针,指向数组叫数组指针,指向结构体就叫结构体指针
- 结构体指针的定义、初始化、使用
- 指向结构体数组的指针
- 结构体指针作为函数的参数
- 结构体数组指针作为函数参数
- 使用结构体指针构建动态数据结构—链表
struct student stu = {{"Jiang",20,'M'},1000,100};
struct student *p = &stu; //定义一个结构体指针,stu本身可以直接相互赋值,比如:stu1 = stu2,但是在定义结构体指针的时候必须使用取址符号&,才能把结构体的地址传给指针p,定义结构体指针。
//三种访问方式
printf("%c %d %c %d %d",stu.p.name,stu.p.age,stu.p.sex,stu.num,stu.score);
printf("%c %d %c %d %d",(*p).p.name,(*p).p.age,(*p).p.sex,(*p).num,(*p).score);
printf("%c %d %c %d %d",p->p.name,p->p.age,p->p.sex,p->num,p->score);
结构体指针的优点,就是穿参的时候如果直接传递结构体变量,结构体变量很大,传递的时候很慢,使用结构体指针的时候,只需要传递一个四字节的指针,效率会高很多,在栈中分配的内存也会小。
指向结构体数组的指针
//第一种取值方式
for(int i = 0; i<5;i++)
printf("%c %d %c %d %d",(*(p+i)).p.name,(*(p+i)).p.age,(*(p+i)).p.sex,(*(p+i)).num,(*(p+i)).score); //(*(p+i))这个p是指向结构体数组的指针,然后p+i是地址如果直接取值的话是需要用间接取值符号->,可以对p+i进行取值运算*(p+i),但是由于后边的成员运算符'.'的优先级高于取值运算符'*'所以,要给*(p+i)再套一个括号,不然的话就会先进行成员运算符的操作,就相当于p+i然后取成员,这样由于p+i是地址,就回到第一句,取成员就需要用间接取成员运算符->
//第二种取值方式
for(int i = 0; i<5;i++)
printf("%c %d %c %d %d",p[i].p.name,p[i].p.age,p[i].p.sex,p[i].num,p[i].score); //使用p[i]取值的时候由于p[i]是一个数组下标,代表的是数值,然后取成员用'.'
//第三种取值方式
for(int i = 0; i<5;i++)
printf("%c %d %c %d %d",(p+i)->p.name,(p+i)->.p.age,(p+i)->p.sex,(p+i)->num,(p+i)->.score);
//和第一种有些类似
结构体指针构建链表
用结构体构建链表就是一个头一个尾巴,通过各个内存之间的指针指向而连接在一起,每个结构体都有一个尾指针指向下一个结构体,最后一个结构体的指针是空指针。
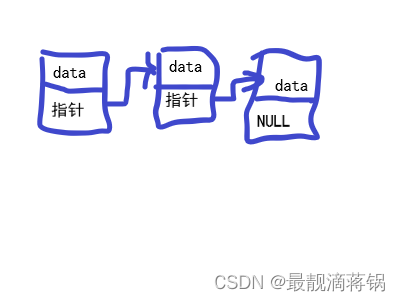
int main(){
struct node{
int data;
strbcu node * next; //定义一个结构体的时候定义一个指针变量,最好命名为next,这样能一眼看出来是用于链表的指针
}node1,node2; //定义两个node类型的结构体
node1.data = 10;//单独给结构体的成员赋值
node1.next = &node2;//另外给结构体内部的指针赋地址
node2.data = 20;//给第二个结构体的成员赋值
node2.next = NULL;//第二个结构体内部的指针设置为空指针
printf("%d %d\n",node1.data,node2.data);//正常取值的时候直接取成员符号取值
printf("%d %d\n",node1.data,node1.next->data);
//使用链表取值,通过node1的结构体指针指向第二个结构体的成员,node1.next->data,node1是结构体名,指向next是使用'.',然后next指针里存放的时候node2的地址所以在指向node2中data的成员的时候是使用间接去成员符号'->'。
}
11-4 结构体函数
返回值类型是结构体变量的函数,叫结构体函数
strcut student {
char name;
char sex;
int age;
int num;
}; //先定义一个结构体类型
int main(){
struct student stu;//然后定义一个结构体变量
stu = struct_create(); //通过结构体创建函数,创建一个结构体传给stu
printf("%c %c %d %d",stu.name,stu.sex,stu.age,stu.num);//打印结构体
}
struct student struct_create(void);
{
struct student stu;//定义结构体
puts ("input a student info:");
scanf("%c %c %d %d",&stu.name,&stu.sex,&stu.age,&stu.num);
return stu; //结构体函数传递结构体是传递的数值,虽然函数执行完,这个stu的内存已经被释放,但是数值还是在的,而且同一类型结构体之间可以直接相互赋值
}
11-5 共用体
共用体也是一种构造类数据
共用体是里边东西共用同一个内存单元,共用体的长度是有共用体里边最长的成员变量所决定,每个时刻只能使用一个成员变量
- 共用体的定义、初始化、使用
- 共用体的存储和大小
- 共用体数组
共用体的关键字 union
union student {
int age;
char sex;
int num;
float score;
int *p;
}stu1;
union student stu2;
stu1.age = 0x11223344;
printf("%x\n",stu1.age); //这个可以正常打印,结果是0x11223344
printf("%x\n",stu1.sex);//这个时候访问sex其实还是访问的age赋的值,由于sex是一个char类型的,是一个字节,然后智能访问age的低字节的内容也就是44,
stu2.sex = 'M';
printf("%c\n",stu2.sex);//结果是M
printf("%x\n",stu2.age);//结果是M的ASCII码 48的十六进制30
通过指针访问共用体的成员,相同共用体可以构成共用体的数组,首先是共用体的类型,长度
然后通过下标引用访问共用体成员进行赋值,然后通过循环,下标引用共用体成员打印共用体数组
注意
- 共用体变量中的值是最后一次存放的成员的值
- 共用体变量的地址和各成员地址相同
- 共用体不能作为函数参数和返回值
- 共用体和结构体可以相互嵌套
结构体可以用共用体当作成员变量,共用体也可以用结构体当做成员
11-6 枚举
- 枚举数据类型
- 枚举的定义、初始化、引用
enum week{
sunday = 1,//给第一个赋值为1,下边的变量依次加一赋值,如果不给第一个赋值,那么会默认为0,下边依次加一赋值,也可以赋值为负值,
minday,
tuesday,
wensday = 10,//如果这种从中间赋值,那么下边的这些值就从这个值之后一次加一,也就是说thusday是11,friday是12
thusday,
friday,
saturday,
}a;//一个变量的取值是有限的,我们把它定义为枚举类型,比如一周只有七天,周一到周日,一个
enum week a,b,c;
a = sunday;
b = monday;
c = thusday;
printf("%d %d %d %d",a,b,c,friday);
注意
枚举是常量,不能作为左值被重新赋值
枚举类型不是字符或者字符串,使用时不能加单引号或双引号
枚举可以用在关系表达式中
枚举从0开始自动赋值
枚举变量的取值范围要在枚举类型定义的范围内
11-7使用typedef定义类型名
typedef unsigned int uint;//使用typedef把unsigned int 起了一个新的名字 uint,把c语言中已经有的数据类型,定义成新的类型名称
//然后可以用这个新的类型名称定义变量
uint i;//此时这个i就是一个unsigned int类型的变量
typedef struct
{
char name[20];
int age;
}student;
student stu = {"Jiang",20};//这个struct结构体类型被typedef修饰以后起了个别名student,然后用这个结构体类型定义结构体的时候前边不需要再加struct
用typedef定义别的类型
typedef int intarray_10[10];//定义一个十字节的数组
typedef int(*myfunc)(int a,int b);
int func(int a,int b);
myfunc p;
p = func;
int func(int a,int b)
{
return (a+b);
}
11-8 结构体成员为柔性数组
允许在一个结构里定义一个零长度的数组,而且不占用结构体的数组,然后使用的时候需要去栈里分配内存。c99新增加的标准
typedef struct{
int i;
int array[0];
}isoc_urb;
printf("%d\n",sizeof(is0c_urb));
isoc_urb *p = (isoc_urb*)malloc(sizeof(iisoc_urb)+100*sizeof(int));
p->array[0] = 100;
p->array[1] = 200;
printf("%d %d",p->array[0],p->array[1]);
malloc在栈里申请内存
柔性数组的使用:比如摄像头的图像分辨率,有很多种720p,1080p,大小都不相同,使用零长数组,定义的时候不需要分配内存,然后使用的时候如果是大图像,那就用malloc分配大内存,传输小图像就用malloc分配小内存,定义的时候不占用空间,属于动态分配空间,
11-9 复合字面量
所谓字面量就是固定数值表示
- 基本数据类型字面量:100、12.34,“hello”
复合字面量
- 构造数据类型:数组字面量、结构体字面量
优点
- 使得函数构造数据类型参数传递可以不再定义一个变量,直接使用复合字面量,省去赋值操作,使得参数传递更加简洁
struct student stu = {"Jiang",20};
(struct student){"Jiang",20};//相当于强制转换这一堆数据,把这一堆数据强制转换成一个student结构体类型,在这之前定义好了student这个结构体类型
12-1 预处理的概念
程序的生成过程首先编译,就是把程序编译成汇编语言,接着使用汇编器,蒋汇编语言转换为二进制目标代码,然后在进行链接,生成可执行文件。其实还有一个过程就是预处理过程例如宏替换,头文件展开等。
-预处理的生成过程
预处理 编译 汇编 链接 可执行文件
- 预处理过程
处理程序中以#开头的预处理命令
执行#include命令,蒋使用该文件包含的内容头文件内容替换该命令
执行#define命令,将程序中使用过的#define定义的宏,替换为具体的数字
执行条件编译及其他预处理命令 - 预处理1过后,生成的文件还是c源文件
文件包含
#include
宏定义
#define #undef //undef取消宏定义
条件编译
#if #else #endif
#ifdef #ifndef
其他命令
重置行号和文件名: #line
产生错误信息:#error
修改编译器设置:#pragma
12-2宏定义
用一些标识符作为宏名来代替一些符号或常量的命令
在预处理阶段,预处理器会将程序中所有出现的宏名用宏定义中的字符串替换,这个过程称为宏替换或宏展开
#define STR "hello world"
#define STR "hello world \
Great wall"//如果宏定义的字符串较长以行写不完,那就使用'\'续节符
- 带参数的宏定义
- 形式参数和实际参数
在宏定义总的参数为形式参数
在宏调用中的参数称为实际参数
展开时,不仅要宏展开,还要用实际参数替换形参 - 定义格式
#define 宏名 字符串
#和##操作符使用
#undef的使用
#define INT(n) a##n
int INT(1); //此时调用的宏定义,把1赋值给n##n表示1,所以定义的是一个整型变量a1
a1 = 10;
#undef INT//把这个宏定义取消,取消以后就无法在使用了
注意
需要注意的地方当字符串为较复杂的表达式时记得加括号,防止因优先级而带来的运算错误
一般使用大写字母来表示宏名,可以放在头文件中,宏定义也可以嵌套
使用宏定义时不要吝啬加括号,除非你考虑到了所有可能出现错误的情况
使用圆括号扩至每个参数,保证每个参数都在定义表达式中能正确分组
宏定义的作用域:定义开始到文件结尾或#undef处
宏定义要单独占一个逻辑行,若定义字符串太长,可以使用\换行续接
12-3一些预定义的宏名
编译器会预定义一些常用的宏
DATE:当前源程序的创建日期
FILE:当前源程序的文件名称(包括盘符和路径)
LINE:当前被编译代码的行号
STDC:返回编译器是否为c标准编译器
TIME:当前源程序的创建时间
func:预定义标识符,不是宏定义,使用gcc预定义编译会发现__func__不会被展开
12-4 文件包含
在一些大项目,需要多人协作编程,有上百个c文件和源文件,每个人负责一部分模块,当别人需要使用你所写的模块,这就需要你把你写的模块封装成一个头文件,这样别人使用你的模块,只需要包含你的头文件就行了
- 头文件包含命令
#include - 使用头文件的好处
1、避免函数原型的重复声明,(声明的作用,告诉编译器这个函数是什么类型,这个函数可能在下边定义,也可能是在某个文件中定义了)利于程序模块化设计
2、避免了宏定义的多次重复声明
3、不会明显增加程序的大小:头文件的内容是编译器需要的信息,而不是加到最终代码里的具体语句
3、头文件搜索路径
标准路径和项目工程的当前路径(绝对路径) - 使用头文件需要注意的地方
1、头文件的编译过程是不占用可执行文件的内存得的
2、头文件可以在任何地方使用#include引入
仅仅做文本替换操作,不一定放在文件开头
3、避免多次包含同一头文件可采用条件编译的方法来避免。如下:
#ifdef __MAFUNC__
#define __MAFUNC__
......//一些函数的声明 宏定义 常量定义 不可以定义全局变量
#endif //这种头文件的结构可避免多次包含同一头文件
12-5条件编译
- 为什么要条件编译
提高程序的适用性,减少目标代码的体积
使用条件编译制作程序的不同客服版本
使程序移植更加方便
常见的条件编译命令
#if #else #endif //else是最后一个else
#if #elif #endif //elif是elseif可以有好几个
#ifdef #ifndef //如果定义了这个宏,就编译这样一块,如果没有定义这个宏就编译第二块
#if defined #if !defined
#if !defined FOR_A_COMPANY && defined REALAESE
int add(int a, int b)
{
printf("For A company\n");
return (a+b);
}
#else
int add(int a, int b)
{
printf("For B company\n");
return (a+b);
}
#endif
#if 0
int sub(int a,int b)
{
printf("if\n");
return (a-b);
}
#elif 0
int sub(int a,int b)
{
printf("elif\n");
return (a-b);
}
#else
int sub(int a,int b)
{
printf("else\n");
return (a-b);
}
#endif
12-6其他预处理命令
重置行号和文件名:#line
产生错误编译信息:#error
修改编译器设置:#pragma
操作符_Pragma(C99)
#line 1000 "hello"//重置了行号为1000,文件吗叫hello
#pragma message ("打印错误信息")//
- 结构体对齐#pragma
- 对齐模数
跟处理器相关,强制内存对齐
可以提升读取数据的速度 - 结构体内成员按各自对齐模数对齐
- 结构体按结构体模数对齐
- 对齐模数大小的确定
结构体成员对齐模数是#pragma指定值(或默认值)和该成员所占空间长度的较小值
结构体对齐模数是#pragma指定值(或默认值)和结构体最大成员数据类型长度的较小值
- 对齐模数
结构体的大小是对齐模数的整数倍
#pragma pack(8)
_Pragma("pack(8)")//这一个和上一行一个意思,但是这个不是宏定义
struct student{
char sex;
double score;
int age;
int num;
};
print ("%d\n",sizeof(struct student)); //被#pragma pack(8)修饰以后,打印结构体的长度只会是8的倍数
13-1动态内存管理
- 在C语言中程序分为代码区和数据段,内存中也分为动态内存和静态内存
- 静态内存分布
- 堆式存储分布
- 栈式内存分布
栈从高往低存储,当程序需要给形参分配内存时就从栈中分配内存,函数调用结束后,内存分配就结束了,指针回到栈顶。栈指针sp,后进先出。
堆,由低地址往高地址延伸,允许程序自己申请内存使用,比如需要自己申请一个内存,在程序中起初你不知道实际内存需要多少,然后需要的时候再申请,比如摄像头有不同的分辨率,但是你起初不知道分辨率是多少,需要的缓冲区是多少,只能等用到的时候实时分配,(malloc)先进后出。
栈的内存分配和释放由系统进行分配和释放效率高速度快,堆的内存分配和释放都有操作者管理,有时候会忘记释放,会生成碎片,速度慢。
每个系统的堆和栈的大小都是系统定义好的。 - 动态内存中分为堆和栈
动态内存管理就是堆
](https://i-blog.csdnimg.cn/blog_migrate/df670fbbbf5f26637f56efba5d409ab7.png)
13-2动态内存申请函数
- 内存分配函数 malloc
malloc申请成功以后,返回这段内存的地址,如果申请失败就是返回0,
char *p;
p = (char*)malloc(100);申请一个100字节的内存,把地址给p
if(!p){
printf("malloc failed!\n");
return -1;
}
struct (p,)
- 内存分配函数calloc
struct student{
int num ;
int age;
float score;
};
struct sudent *p;
p = (struct student*)calloc(10,sizeof(struct student));//申请了10个student结构体内存大小的内存
- 调整已分配的内存函数realloc
当malloc或calloc申请的内存不够用的时候,使用realloc再重新申请更大的内存
p = realloc(p,200*100000);//还是相同的地址,只是内存扩展到了200*10000
- 内存释放函数free
13-3内存泄漏和野指针
使用动态内存常见的错误
内存未分配成功而直接使用
内存分配成功,尚未初始化而直接使用
内存分配成功且已初始化,但操作越过了内存的边界
使用完毕后忘记释放内存,造成内存泄露
防止内存泄漏:使用malloc申请的内存使用结束后及时释放,注意保存malloc函数返回的指针。防止内存越界,可能会破坏其他动态内存的信息,造成free失败,对于多人开发,要坚持谁申请谁释放,每次申请后要检查是否成功然后再使用,分配空间时,可以多申请一点,函数错误退出时,不要忘记其他已经分配额空间
野指针
什么是野指针:
int *p,*q,*r;
*r = 100;//此时指针r没有初始化就被赋值,就叫做野指针,
//可以先定义空指针
int *r = NULL;
*r = 100;//这样可以使用
14-1 文件的基本概念
流的概念
-
输入输出流
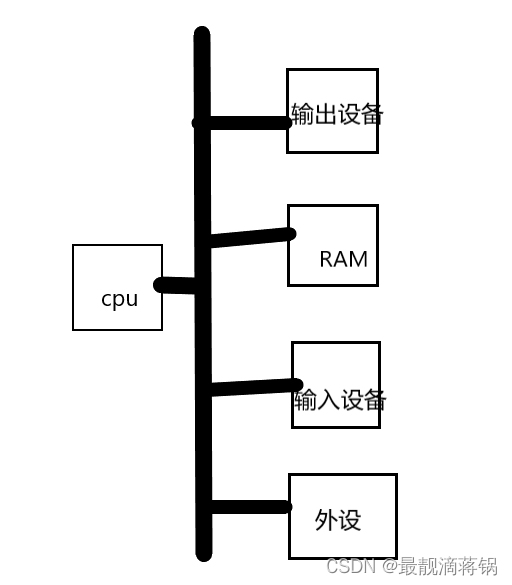
在一个标准的逻辑设备,cpu通过总线挂载各类设备,在cpu与其他设备交互的时候需要一个通信协议,就是总线协议,通过总线协议各个设备之间传输的字节,称为流,字节流
-
流与缓冲
-
标准输入输出
标准输入流(设备):stdin:与键盘相连
标准输出流(设备):stdout:与显示器相连
printf("input a,b");
fprintf(stdout,"input a,b");//这两行意思一样都是标准输出到控制台
键盘输入的数据都放在缓冲区,scanf首先读取缓冲区的内容,如果缓冲区数据多了,下一个scanf直接读取在它之前的缓冲区的数据,就不需要在输入数据了,可以使用fflush(stdin);这一句清空缓冲区,括号里的参数是缓冲区的位置上,stdin就是说是在标准控制台的缓冲区。
标准错误流(设备):stderr:与显示器设备相连
什么是文件
- 文件是一组相关数据的有序集合
标准输入输出流也叫文件, - 数据集的名称叫文件名
- 文件一般存储在磁盘等外部介质上,使用时读取到内存
- 文件的分类
- 用户角度:普通文件和设备文件
在linux系统下把设备都看成文件,可以直接打开和读写 - 编码方式:文本文件和二进制文件
- 用户角度:普通文件和设备文件
- 文件缓冲区
文件并不是打开就直接打开了,是先进缓冲区,然后才打开,然后你在缓冲区读写,读写结束后保存文件才会把文件写在内存中然后才在缓冲区释放。
文件指针
指向一个文件的指针变量称为文件指针
通过该指针可以对文件进行各种操作
int main(){
FILE*fp; //定义文件指针
fp = fopen("test.c","wt");
fclose(fp);
fp = fopen("test.bin","wb");
fclose(fp);
}
14-2文件的打开与关闭
文本文件的打开与关闭
FILE *p;
fp = fopen("test.txt","r");
二进制文件的打开与关闭
常见的文件打开方式
只读:r (以r打开的文件必须已经存在) ,如果文件不存在,只读的方式打开会报错。
只写:w(以w打开的文件不存在时会自动创建),再次打开会覆盖原文件的内容
读和写方式:+ 比如wb+就是写打开还能读的二进制文件
追加:a 不会覆盖源文件的内容
文本文件:t(默认打开方式,可省略不写)比如:wt是写文本文件
二进制文件:b 创建二进制文件
文件路径
FILE *p;
fp = fopen("test.txt","r");//这里的open编译器会在文件所在文件夹的内找test.txt
fp = fp = fopen("G:\\c-lesson\\chap14\\14-2\\code\\test.c","rt"); //想表示字符'\'必须使用两个斜杠'\\'转义字符
//如果fopen打开失败了,会给文件指针fp赋值NULL
14-3 文件的读写操作
字符读写函数:fgetc()/fputc()
字符串读写函数:fgets()/fputs()
数据块读写函数:fread()/fwrite()
格式化读写函数:fscanf()/fprintf()
struct student *sp = (struct student*)malloc(2*sizeof(struct student));//首先在堆内用malloc申请一块两个struct student大小的内存,指针为sp
fread(sp,sizeof(struct student),2,fp);//然后使用fread读两块struct student大小的放到sp这个buffer(缓冲区)中
printf("姓名\t成绩\t分数\n");
for(int i = 0;i<2;i++)
printf("%s\t%d\t%f\n",sp[i].name..........);
fclose(fp);//关闭文件
free(sp);//释放sp指针指向的内存
sp = NULL;//给sp指针直向一个NULL空指针,防止野指针
fread fwrite一般用于二进制文件操作
fprintf(FILE stream,const charformat);
函数说明,fprintf()会根据参数format字符串来转换并格式化数据,然后将结果输出到参数stream指定的文件中,直到出现字符串结束(‘\0’)为止
fprintf(fp,"%s\t%d\t%f\n",sp[i].name.........);
14-4文件状态检测函数
feof()函数
检测文件指针是否已经到达文件末尾
返回0:文件指针到达文件末尾
文件结束标志:EOF
FILE *fp;//定义一个文件指针
if((fp = fopen("feof.txt","rt")) == NULL) //
{
printf("fopen failed!\n");
return -1;
}
while(!feod(fp)){
putchar(fgetc(fp));//取一个字符打印一下
}
putchar('\n');
fclose(fp);
ferror()函数
检测文件的操作状态是否出错
文件操作出错返回真,否则返回0
clearerr()函数
文件错误标志非0时,所有的文件操作均无效
在ferror函数检测出错后,清除文件操作错误标志,然后可以接着对文件进行操作
FILE *fp;
if((fp =fopen("ferror.bin","wb")) ==NULL)
{
printf("fopen failed!\n");
return -1; //检测内存申请是否成功
}
fwrite(&stu,sizeof(struct student),2,fp);//写操作
if(ferror(fp)!=0) //检测文件操作是否出错,出错就打印然后清除标志位
{
printf("write failed!\n");
clearerr(fp);
return -1;
}
fclose(fp);//关闭文件
14-5文件随机读写
操作文件首先打开文件,文件指针指向开头,写完之后关闭,在重新打开读写,再指向文件开头。对文件操作以后,文件指针是会变动的,如果没有关闭文件,再读的话,是从指针处开始读的
- 文件定位函数:fseek()
fseek(文件指针,偏移量,起始位置)
起始位置:0-文件开头,1-当前位置 2-文件末尾
fseek(fp,0,0);//文件指针为fp,偏移量为0,起始位置为0
fseek(fp,8*sizeof(int),SEEK_SET);//文件指针为fp,偏移量为8个int型字节大小,起始位置SEEK_SET(文件头)
fseek(fp,0,SEEK_END);//通过这个方法计算文件的长度
- 获取当前位置函数:ftell()
ftell(文件指针)
返回值当前文件指针距离文件头部的偏移 - 重置文件位置指针:rewind()
rewind(文件指针)
并清除文件错误标志
rewind(fp);//把文件指针重置到开头

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









