







目录
redis学习🥳
一、string类型基本介绍
string 类型是 Redis 最基础的数据类型,关于字符串需要特别注意:
1)首先 Redis 中所有的键的类型都是字符串类型,而且其他几种数据结构也都是在字符串类似基础上
构建的,例如列表和集合的元素类型是字符串类型,所以字符串类型能为其他 4 种数据结构的学习奠
定基础。
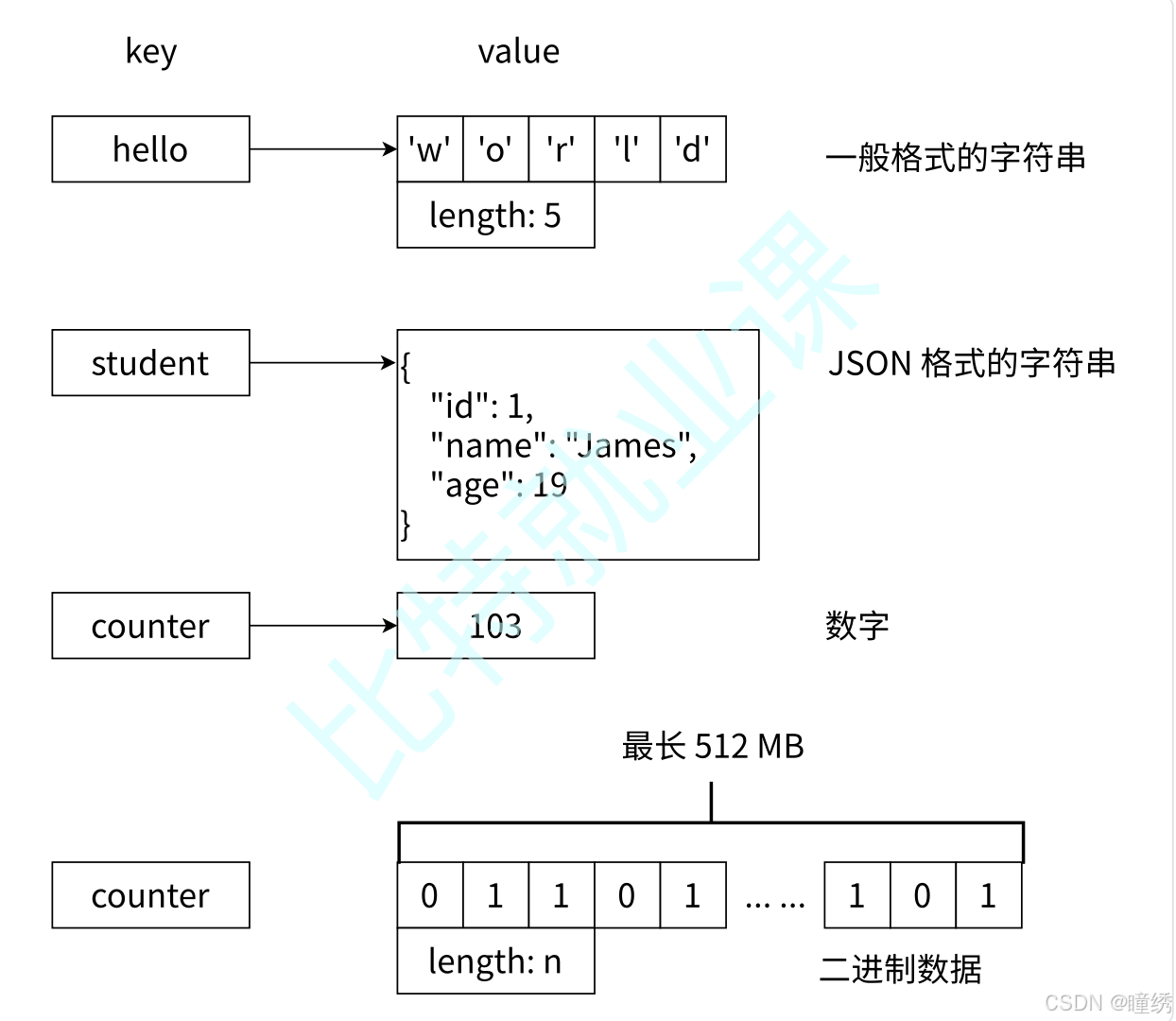
2)其次,如图 2-7所示,字符串类型的值实际可以是字符串,包含一般格式的字符串或者类似
JSON、XML 格式的字符串;数字,可以是整型或者浮点型;甚至是二进制流数据,例如图片、音
频、视频等。不过一个字符串的最大值不能超过 512 MB。
由于 Redis 内部存储字符串完全是按照二进制流的形式保存的,所以 Redis 是不处理字符集编码
问题的,客户端传入的命令中使用的是什么字符集编码,就存储什么字符集编码。
图 2-7 字符串数据类型
二、常见命令
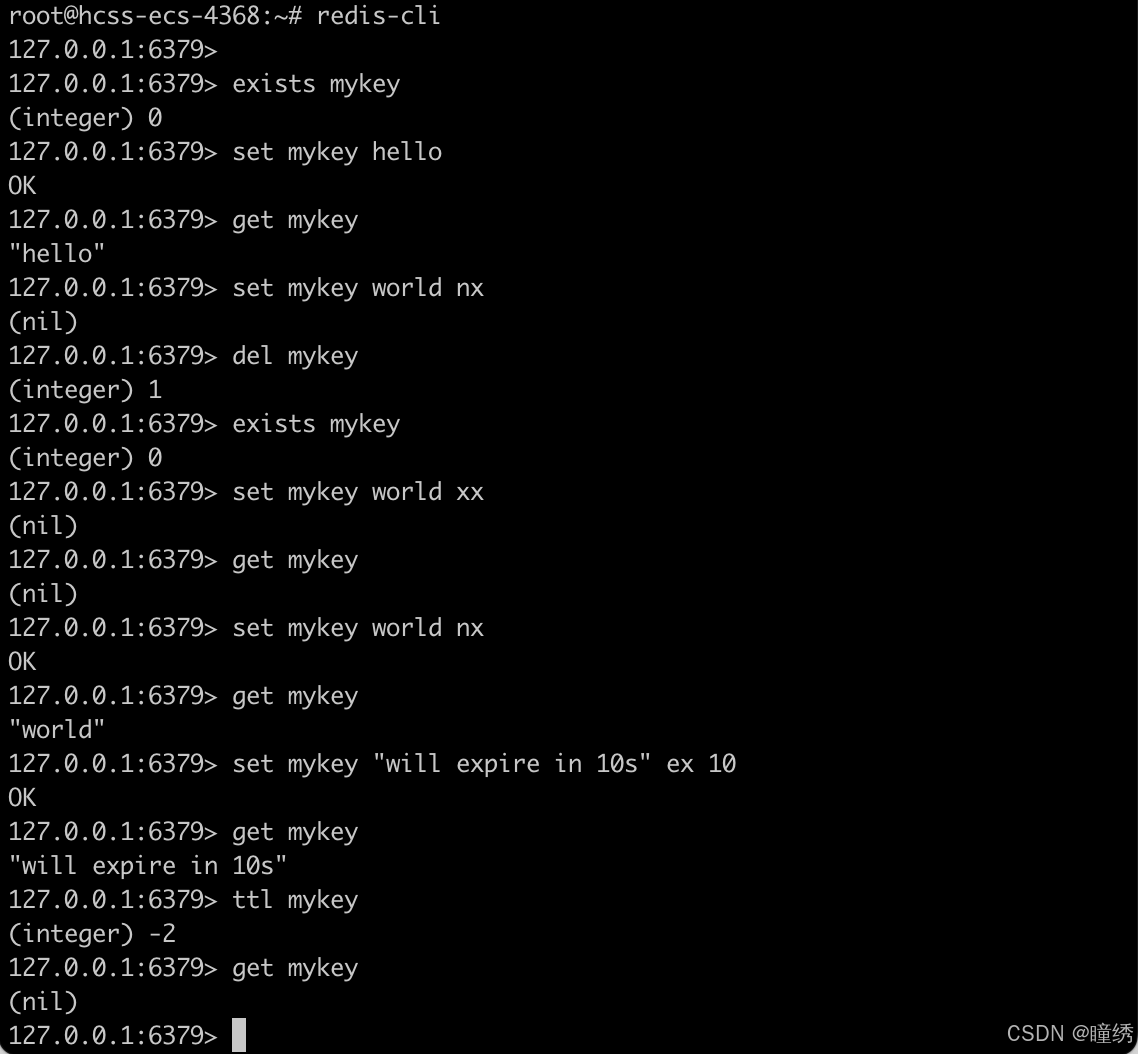
2.1 SET
将 string 类型的 value 设置到 key 中。如果 key 之前存在,则覆盖,无论原来的数据类型是什么。之前关于此 key 的 TTL 也全部失效。
语法:
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]命令有效版本:1.0.0 之后
时间复杂度:O(1)
选项:
SET 命令支持多种选项来影响它的行为:
• EX seconds ⸺ 使用秒作为单位设置 key 的过期时间。
• PX milliseconds ⸺ 使用毫秒作为单位设置 key 的过期时间。
• NX ⸺ 只在 key 不存在时才进行设置,即如果 key 之前已经存在,设置不执行。
• XX ⸺ 只在 key 存在时才进行设置,即如果 key 之前不存在,设置不执行。
注意:由于带选项的 SET 命令可以被 SETNX 、SETEX 、PSETEX 命令代替,所以之后的版本中,
Redis 可能进行合并。
返回值:
• 如果设置成功,返回 OK。
• 如果由于 SET 指定了 NX 或者 XX 但条件不满足,SET 不会执行,并返回 (nil)。
示例:
2.2 GET
获取 key 对应的 value。如果 key 不存在,返回 nil。如果 value 的数据类型不是 string,会报错。
语法:
GET key命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:当 key 存在时,返回 key 对应的 value;当 key 不存在,返回 nil 。
示例:

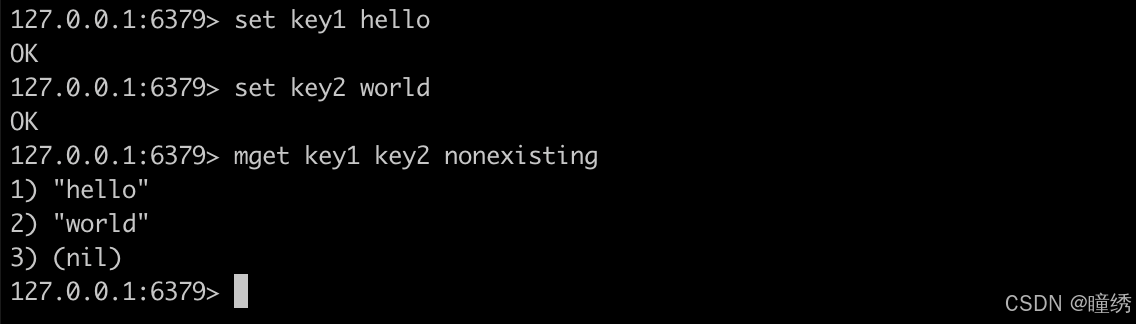
2.3 MGET
一次性获取多个 key 的值。如果对应的 key 不存在或者对应的数据类型不是 string,返回 nil。
语法:
MGET key [key ...]命令有效版本:1.0.0 之后
时间复杂度:O(N) N 是 key 数量
返回值:对应 value 的列表
示例:
2.4 MSET
一次性设置多个 key 的值。
语法:
MSET key value [key value ...]命令有效版本:1.0.1 之后
时间复杂度:O(N) N 是 key 数量
返回值:永远是 OK
示例:
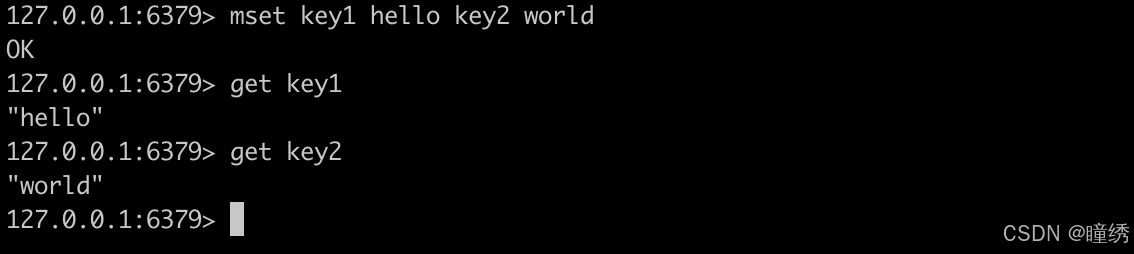
图 2-8 多次 get vs 单次 mget
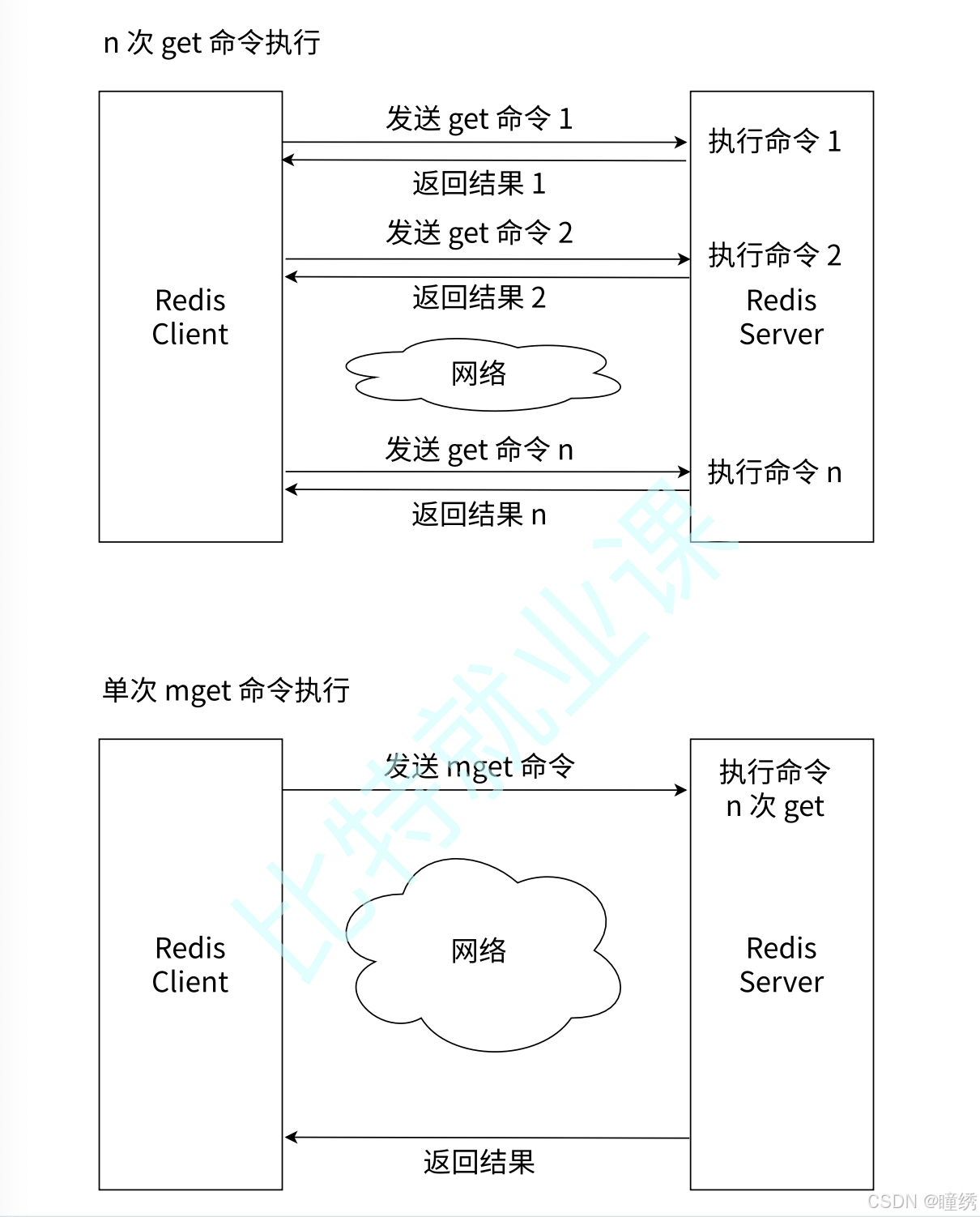
如图 2-8 所示,使用 mget / mset 由于可以有效地减少了网络时间,所以性能相较更高。假设网络耗
时 1 毫秒,命令执行时间耗时 0.1 毫秒,则执行时间如表 2-2 所示。
| 操作 | 时间 |
|---|---|
| 1000 次 get | 1000 x 1 + 1000 x 0.1 = 1100 毫秒 |
| 1 次 mget 1000 个键 | 1 x 1 + 1000 x 0.1 = 101 毫秒 |
学会使用批量操作,可以有效提高业务处理效率,但是要注意,每次批量操作所发送的键的数量也不
是无节制的,否则可能造成单一命令执行时间过长,导致 Redis 阻塞。
2.5 SETNX
设置 key-value 但只允许在 key 之前不存在的情况下。
语法:
SETNX key value命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:1 表示设置成功。0 表示没有设置。
示例:
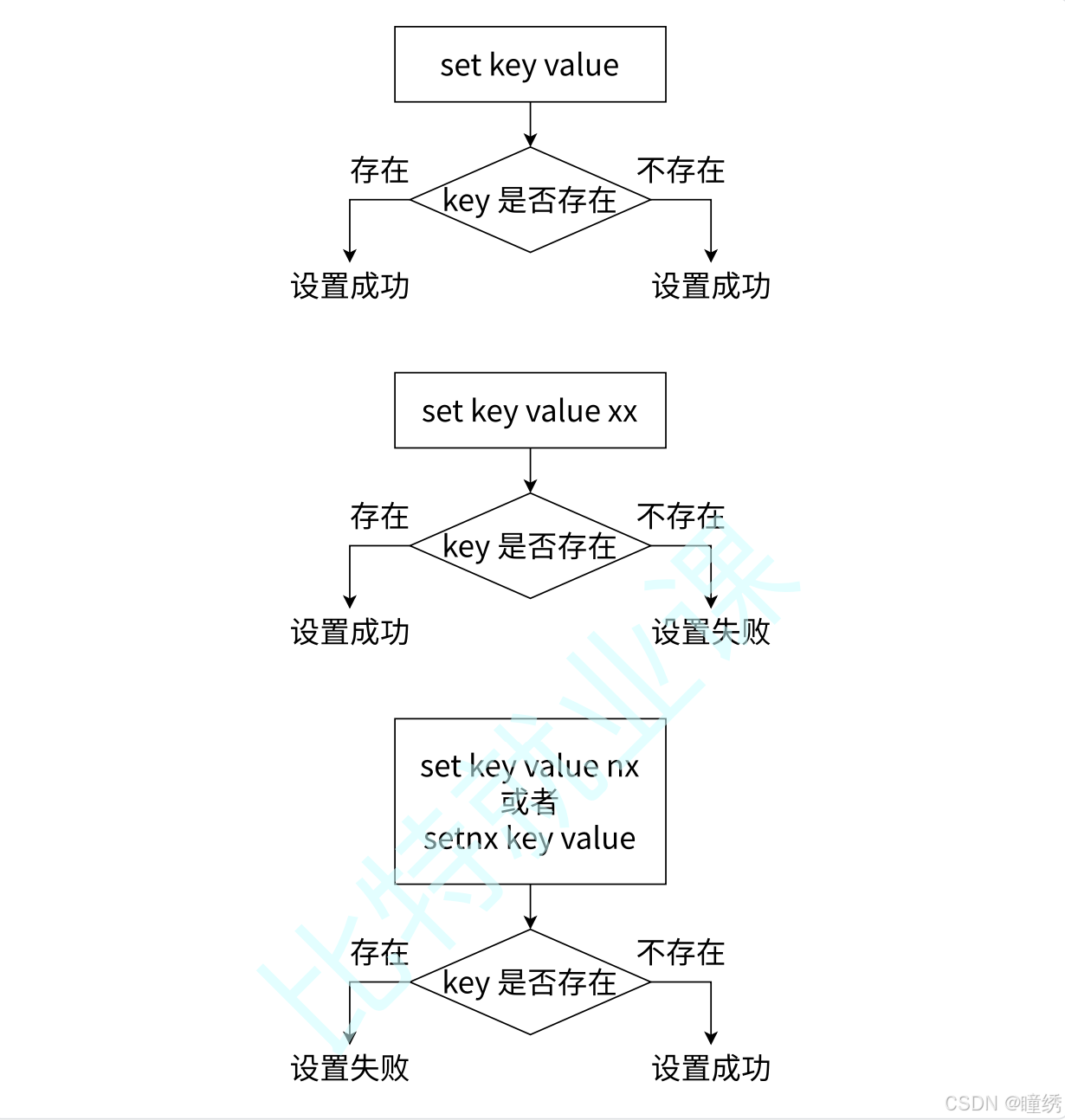
SET、SET NX 和 SET XX 的执行流程如图 2-9 所示。
图 2-9 SET、SET NX、SET XX 执行流程
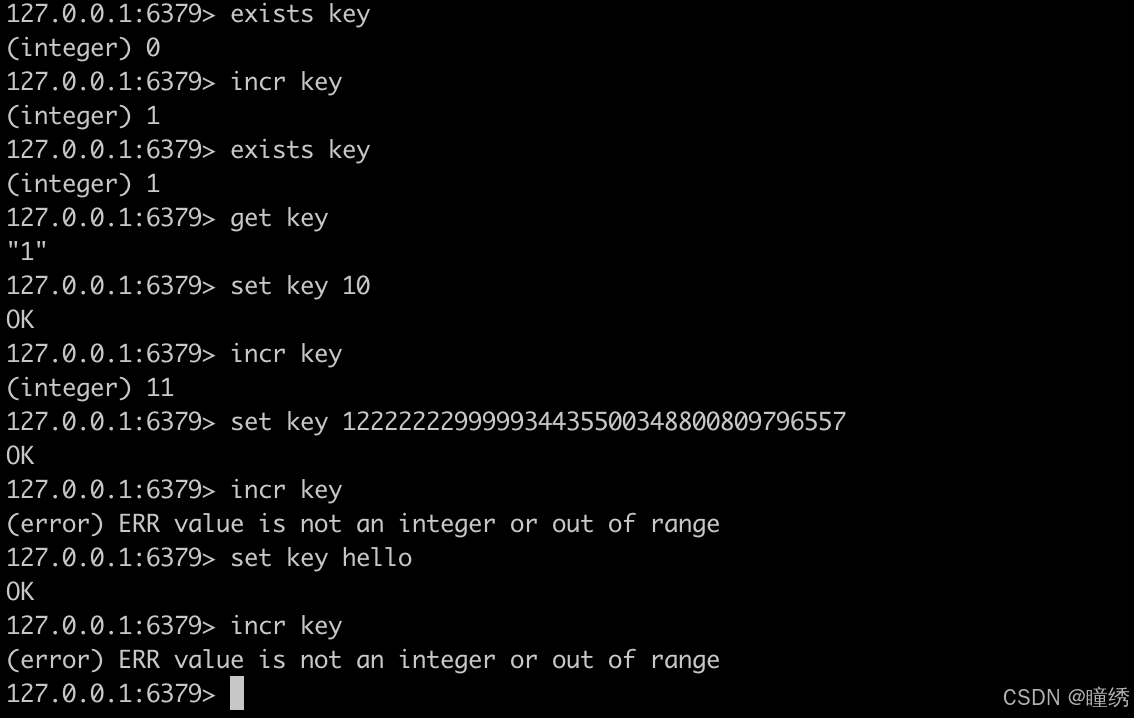
2.6 INCR
将 key 对应的 string 表示的数字加一。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型,则报错。
语法:
INCR key命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:integer 类型的加完后的数值。
示例:
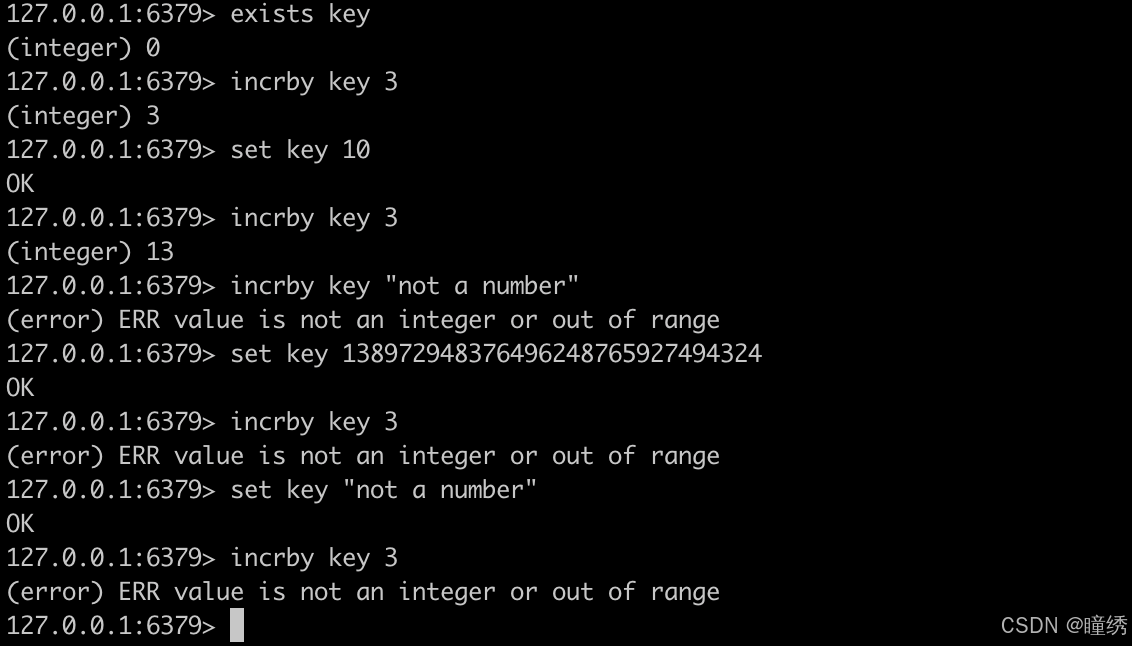
2.6 INCRBY
将 key 对应的 string 表示的数字加上对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了64 位有符号整型,则报错。
语法:
INCRBY key decrement命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:integer 类型的加完后的数值。
示例:
2.7 DECR
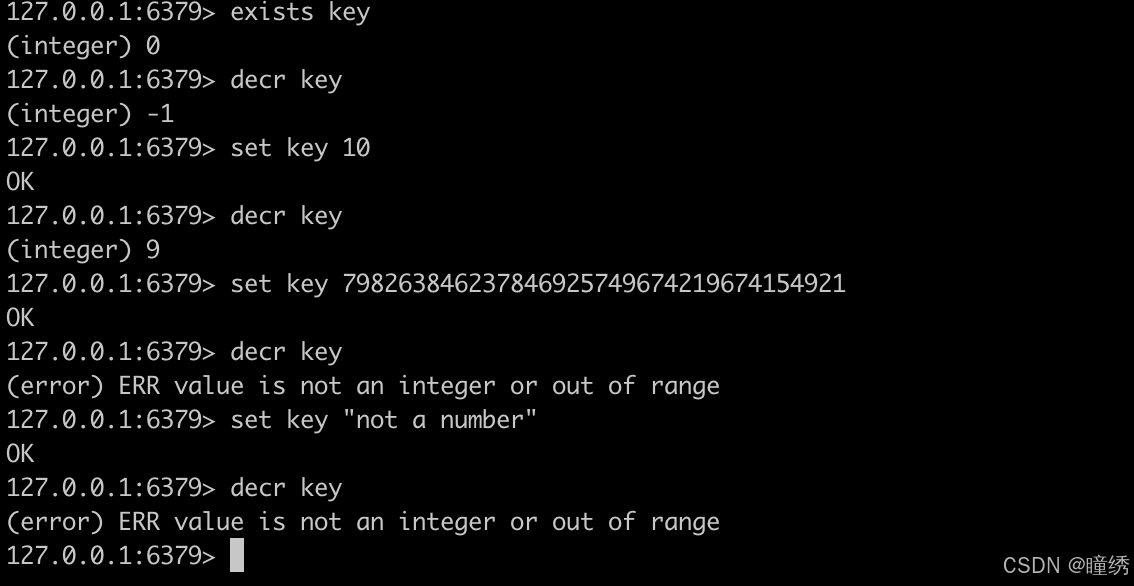
将 key 对应的 string 表示的数字减一。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型,则报错。
语法:
DECR key命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:integer 类型的减完后的数值
示例:
2.8 DECYBY
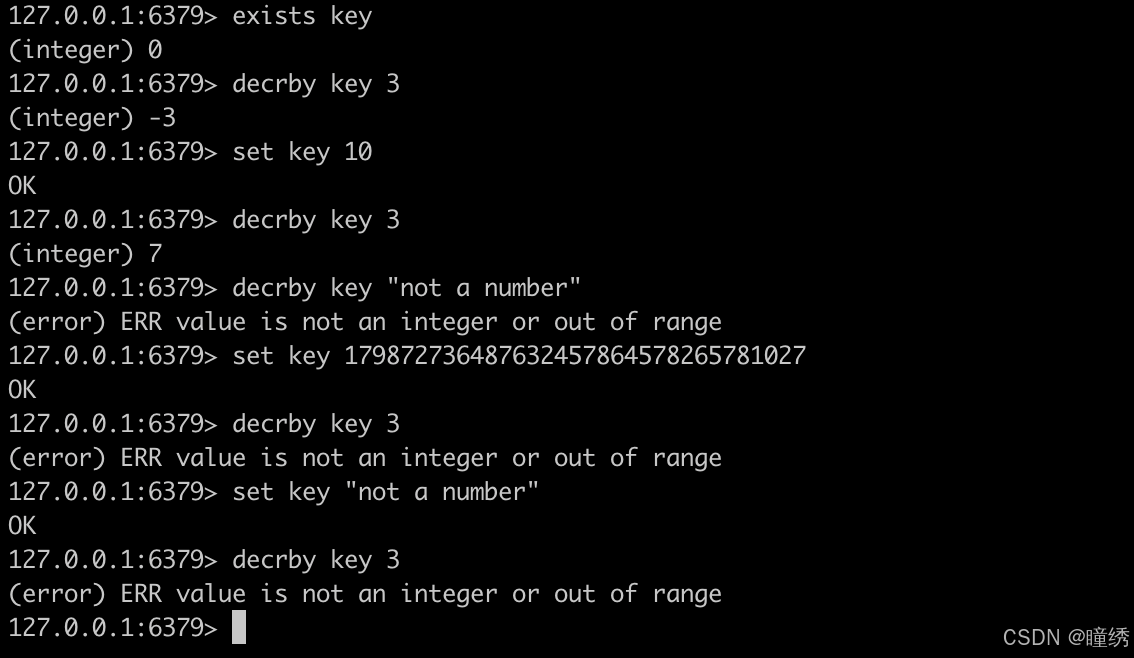
将 key 对应的 string 表示的数字减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了64 位有符号整型,则报错。
语法:
DECRBY key decrement命令有效版本:1.0.0 之后
时间复杂度:O(1)
返回值:integer 类型的减完后的数值。
示例:
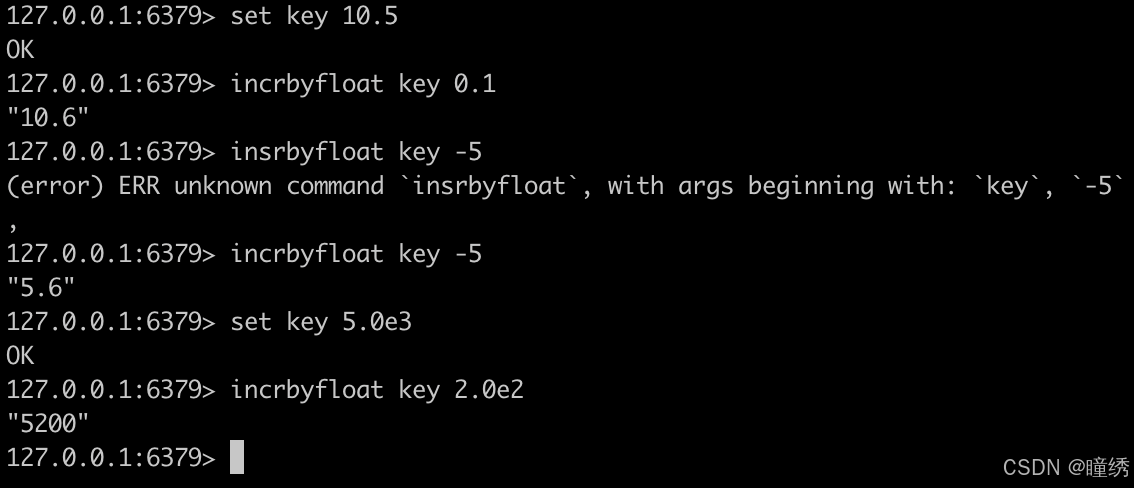
2.9 INCRBYFLOAT
将 key 对应的 string 表示的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的不是 string,或者不是一个浮点数,则报错。允许采用科学计数法表示浮点数。
语法:
INCRBYFLOAT key increment命令有效版本:2.6.0 之后
时间复杂度:O(1)
返回值:加/减完后的数值。
示例:
很多存储系统和编程语言内部使用 CAS 机制实现计数功能,会有一定的 CPU 开销,但在 Redis 中完
全不存在这个问题,因为 Redis 是单线程架构,任何命令到了 Redis 服务端都要顺序执行。
2.10 APPEND
如果 key 已经存在并且是一个 string,命令会将 value 追加到原有 string 的后边。如果 key 不存在,则效果等同于 SET 命令。
语法:
APPEND KEY VALUE命令有效版本:2.0.0 之后
时间复杂度:O(1). 追加的字符串一般长度较短,可以视为 O(1)
返回值:追加完成之后 string 的长度。
示例:
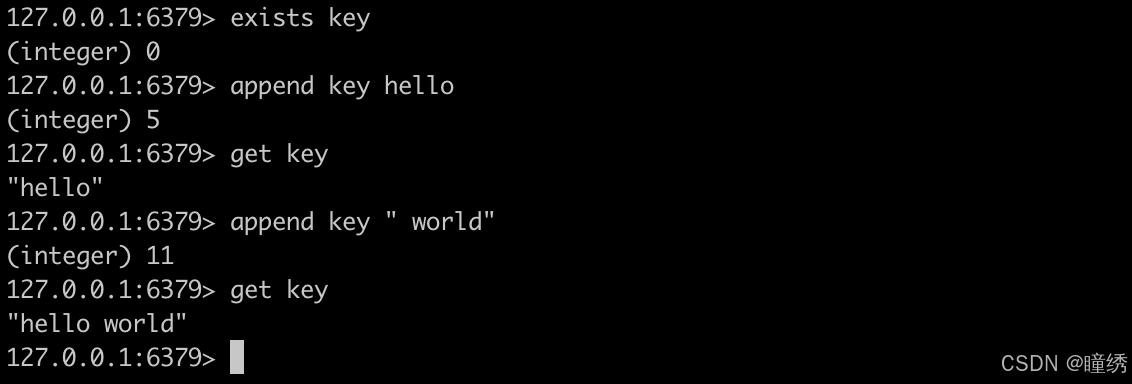
2.11 GETRANGE
返回 key 对应的 string 的子串,由 start 和 end 确定(左闭右闭)。可以使用负数表示倒数。-1 代表倒数第一个字符,-2 代表倒数第二个,其他的与此类似。超过范围的偏移量会根据 string 的长度调整成正确的值。
语法:
GETRANGE key start end命令有效版本:2.4.0 之后
时间复杂度:O(N). N 为 [start, end] 区间的长度,由于 string 通常比较短,可以视为是 O(1)
返回值:string 类型的子串
示例:
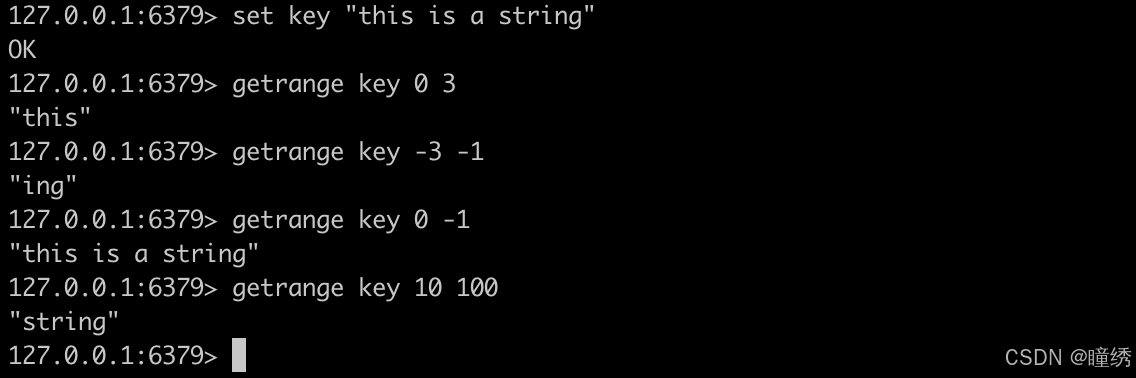
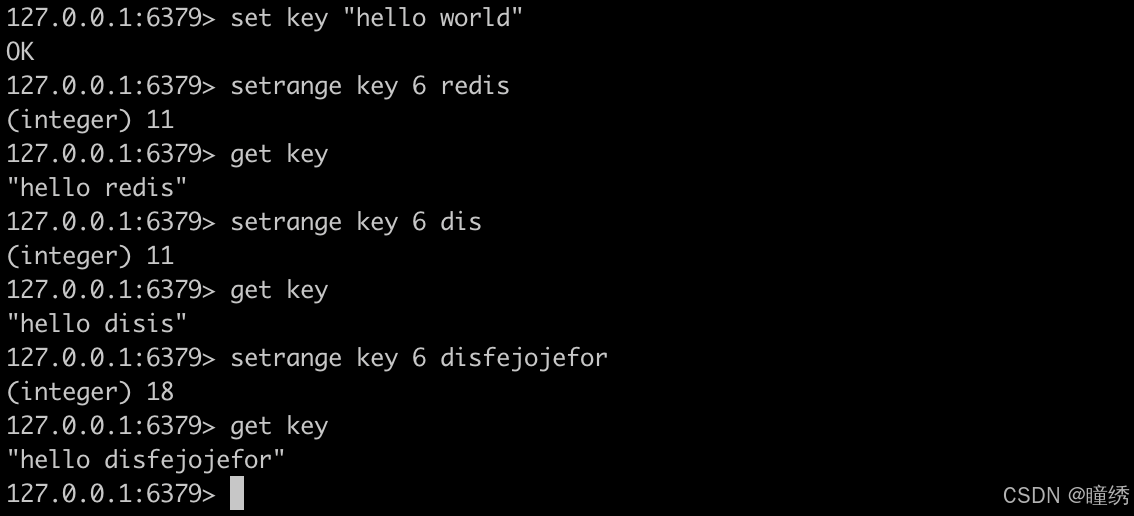
2.12 SETRANGE
覆盖字符串的一部分,从指定的偏移开始。
语法:
SETRANGE key offset value命令有效版本:2.2.0 之后
时间复杂度:O(N), N 为 value 的长度,由于一般给的 value 比较短,通常视为 O(1)
返回值:替换后的 string 的长度。
示例:
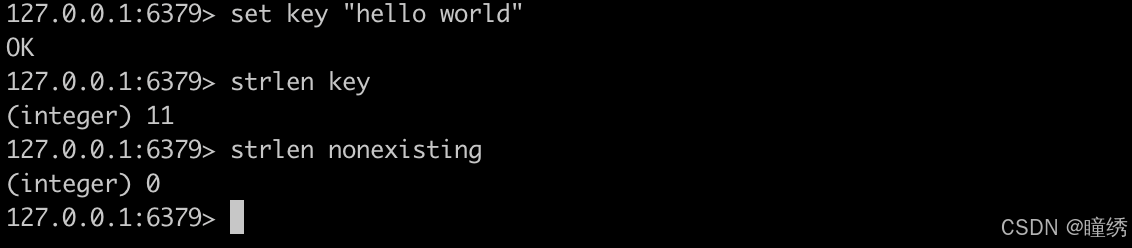
2.13 STRLEN
获取 key 对应的 string 的长度。当 key 存放的类似不是 string 时,报错。
语法:
STRLEN key命令有效版本:2.2.0 之后
时间复杂度:O(1)
返回值:string 的长度。或者当 key 不存在时,返回 0。
示例:
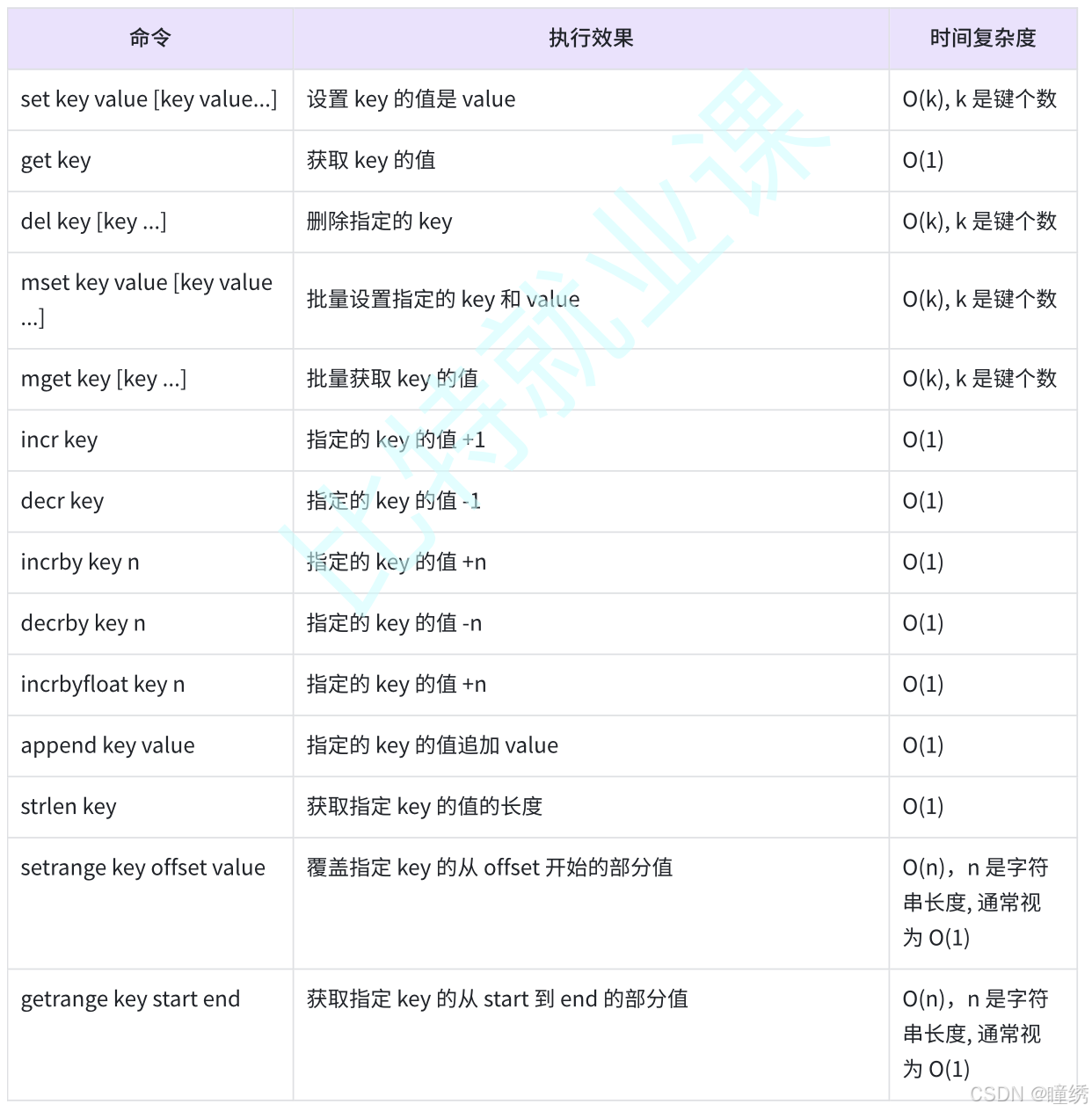
2.14 命令小结
表 2-3 是字符串类型命令的效果、时间复杂度,开发人员可以参考此表,结合自身业务需求和数据大
小选择合适的命令。
表 2-3 字符串类型命令小结
三、内部编码
字符串类型的内部编码有 3 种:
- int:8 个字节的长整型;
- embstr:小于等于 39 个字节的字符串;
- raw:大于 39 个字节的字符串;
Redis 会根据当前值的类型和长度动态决定使用哪种内部编码实现。
整型类型示例如下:

短字符串示例如下:

长字符串示例如下:

四、string 的典型应用场景
4.1 缓存(Cache)功能
图 2-10 是比较典型的缓存使用场景,其中 Redis 作为缓冲层,MySQL 作为存储层,绝大部分请求的
数据都是从 Redis 中获取。由于 Redis 具有支撑高并发的特性,所以缓存通常能起到加速读写和降低
后端压力的作用。
图 2-10 Redis + MySQL 组成的缓存存储架构
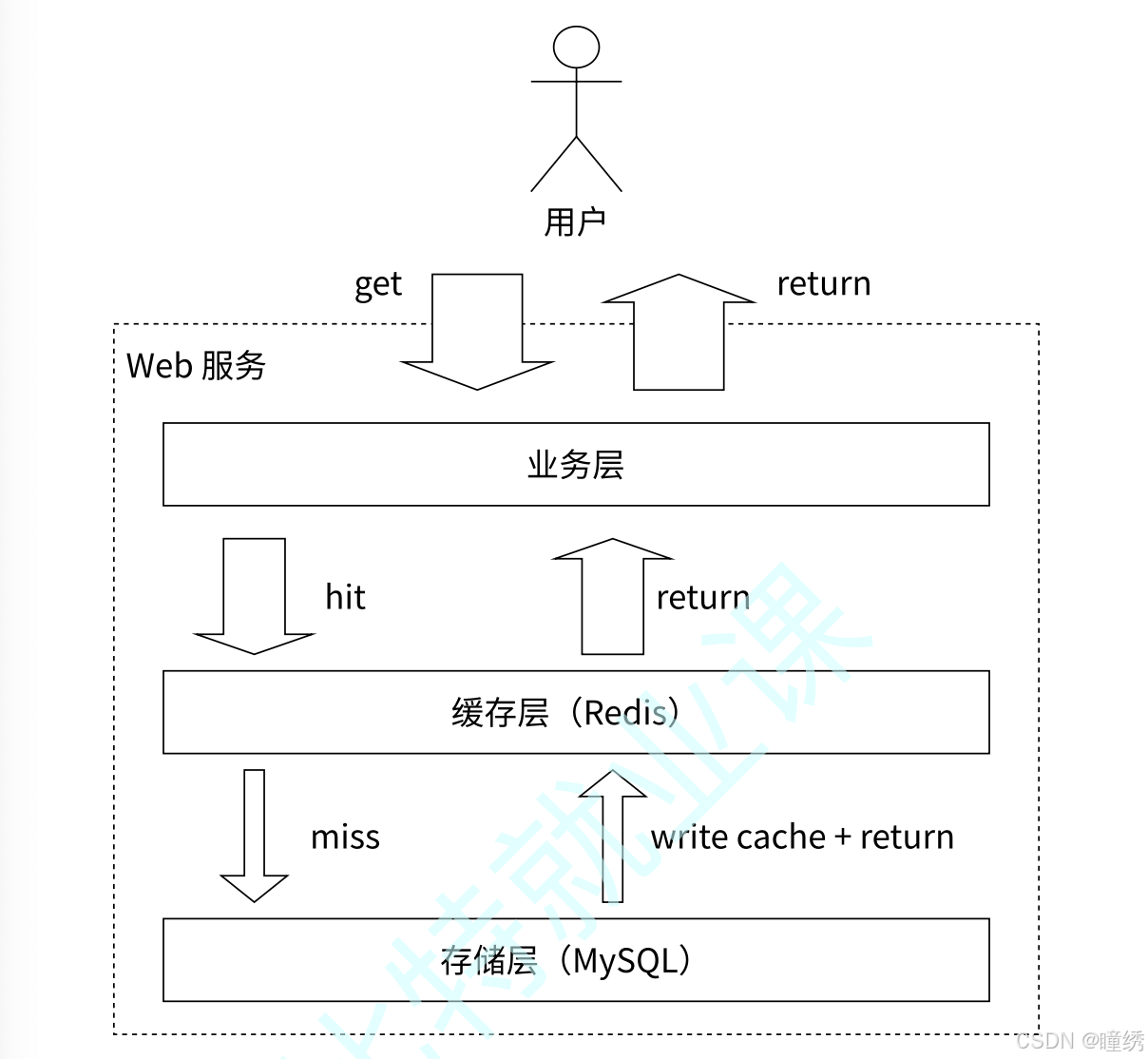
下面的伪代码模拟了图 2-10 的业务数据访问过程:
1)假设业务是根据用户 uid 获取用户信息
UserInfo getUserInfo(long uid) {
...
}2)首先从 Redis 获取用户信息,我们假设用户信息保存在 "user:info:<uid>" 对应的键中:
// 根据 uid 得到 Redis 的键
String key = "user:info:" + uid;
// 尝试从 Redis 中获取对应的值
String value = Redis 执行命令:get key;
// 如果缓存命中(hit)
if (value != null) {
// 假设我们的用户信息按照 JSON 格式存储
UserInfo userInfo = JSON 反序列化(value);
return userInfo;
}3)如果没有从 Redis 中得到用户信息,及缓存 miss,则进一步从 MySQL 中获取对应的信息,随后
写入缓存并返回:
// 如果缓存未命中(miss)
if (value == null) {
// 从数据库中,根据 uid 获取用户信息
UserInfo userInfo = MySQL 执行 SQL:select * from user_info where uid = <uid>
// 如果表中没有 uid 对应的用户信息
if (userInfo == null) {
响应 404
return null;
}
// 将用户信息序列化成 JSON 格式
String value = JSON 序列化(userInfo);
// 写入缓存,为了防止数据腐烂(rot),设置过期时间为 1 小时(3600 秒)
Redis 执行命令:set key value ex 3600
// 返回用户信息
return userInfo;
}通过增加缓存功能,在理想情况下,每个用户信息,一个小时期间只会有一次 MySQL 查询,极大地提
升了查询效率,也降低了 MySQL 的访问数。
与 MySQL 等关系型数据库不同的是,Redis 没有表、字段这种命名空间,而且也没有对键名
有强制要求(除了不能使用一些特殊字符)。但设计合理的键名,有利于防止键冲突和项目
的可维护性,比较推荐的方式是使用 "业务名:对象名:唯一标识:属性" 作为键名。例如
MySQL 的数据库名为 vs,用户表名为 user_info,那么对应的键可以使用
"vs:user_info:6379"、"vs:user_info:6379:name" 来表示,如果当前 Redis 只会被一个业务使用,可以省略业务名 "vs:"。如果键名过程,则可以使用团队内部都认同的缩写替代,例如
"user:6379:friends:messages:5217" 可以被"u:6379:fr:m:5217" 代替。毕竟键名过长,还是会导致 Redis 的性能明显下降的。
4.2 计数(Counter)功能
许多应用都会使用 Redis 作为计数的基础工具,它可以实现快速计数、查询缓存的功能,同时数据可
以异步处理或者落地到其他数据源。如图 2-11 所示,例如视频网站的视频播放次数可以使用 Redis 来
完成:用户每播放一次视频,相应的视频播放数就会自增 1。
图 2-11 记录视频播放次数
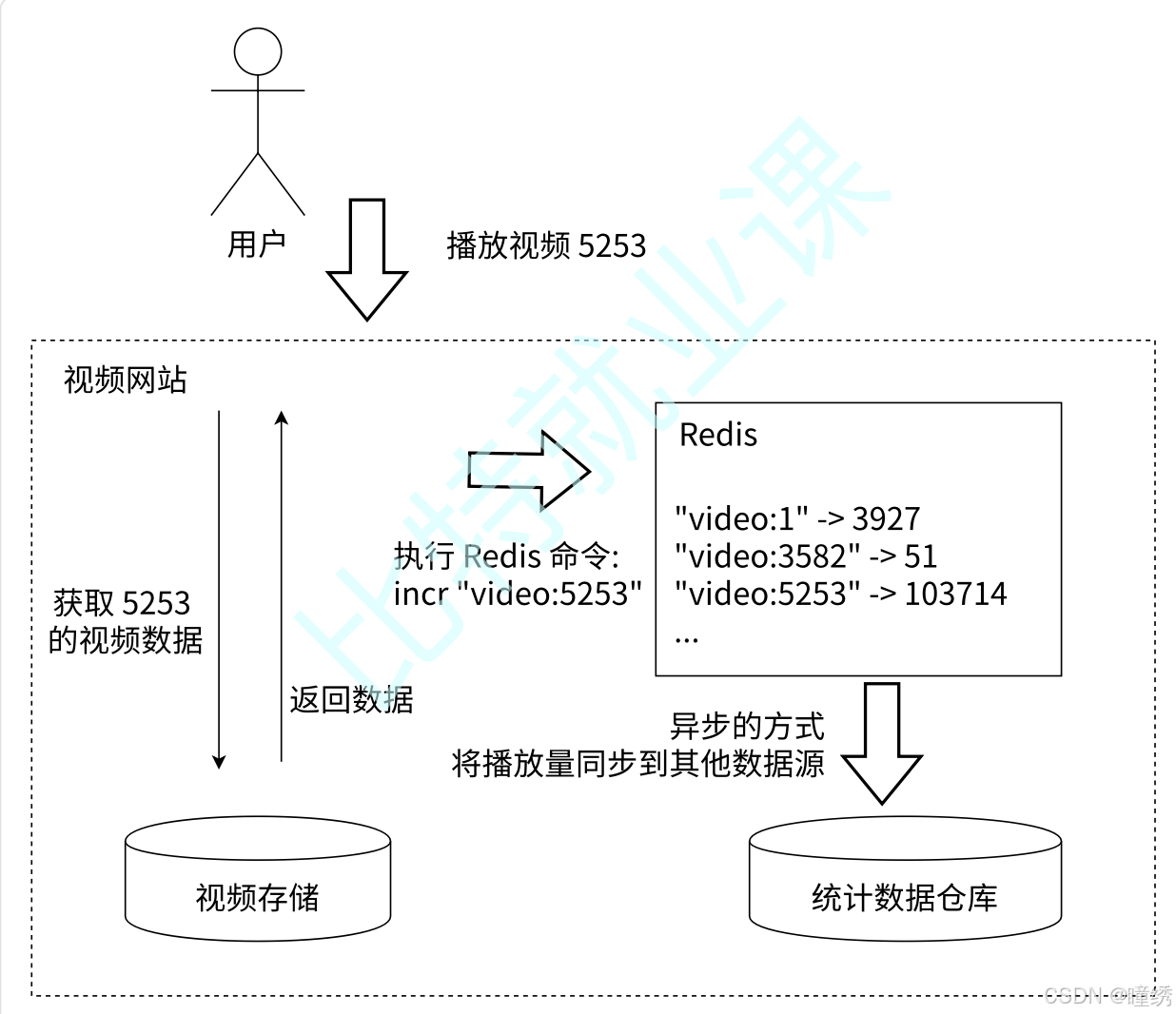
// 在 Redis 中统计某视频的播放次数
long incrVideoCounter(long vid) {
key = "video:" + vid;
long count = Redis 执行命令:incr key
return counter;
}实际中要开发一个成熟、稳定的真实计数系统,要面临的挑战远不止如此简单:防作弊、照不同维度计数、避免单点问题、数据持久化到底层数据源等。按
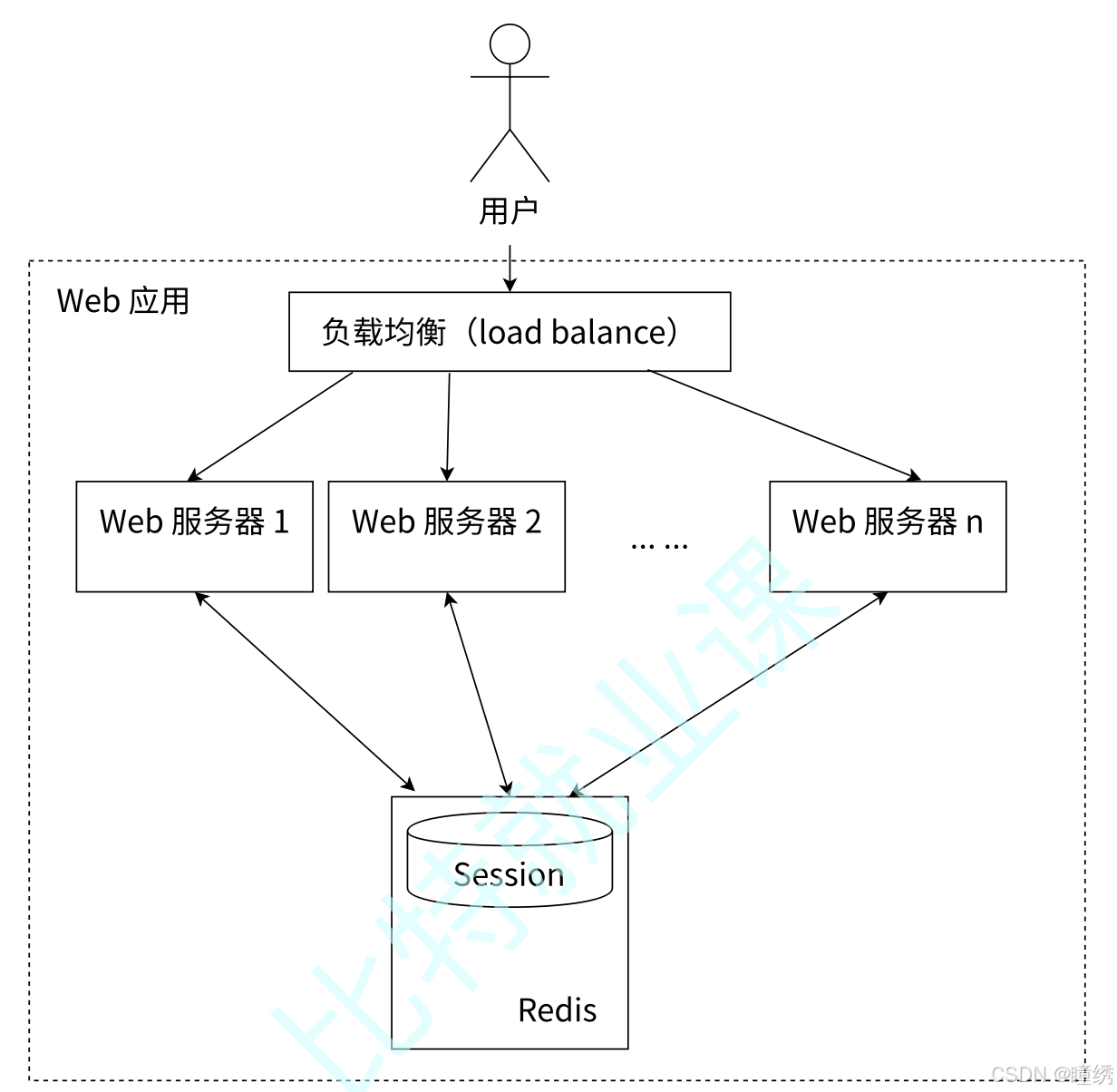
4.3 共享会话(Session)
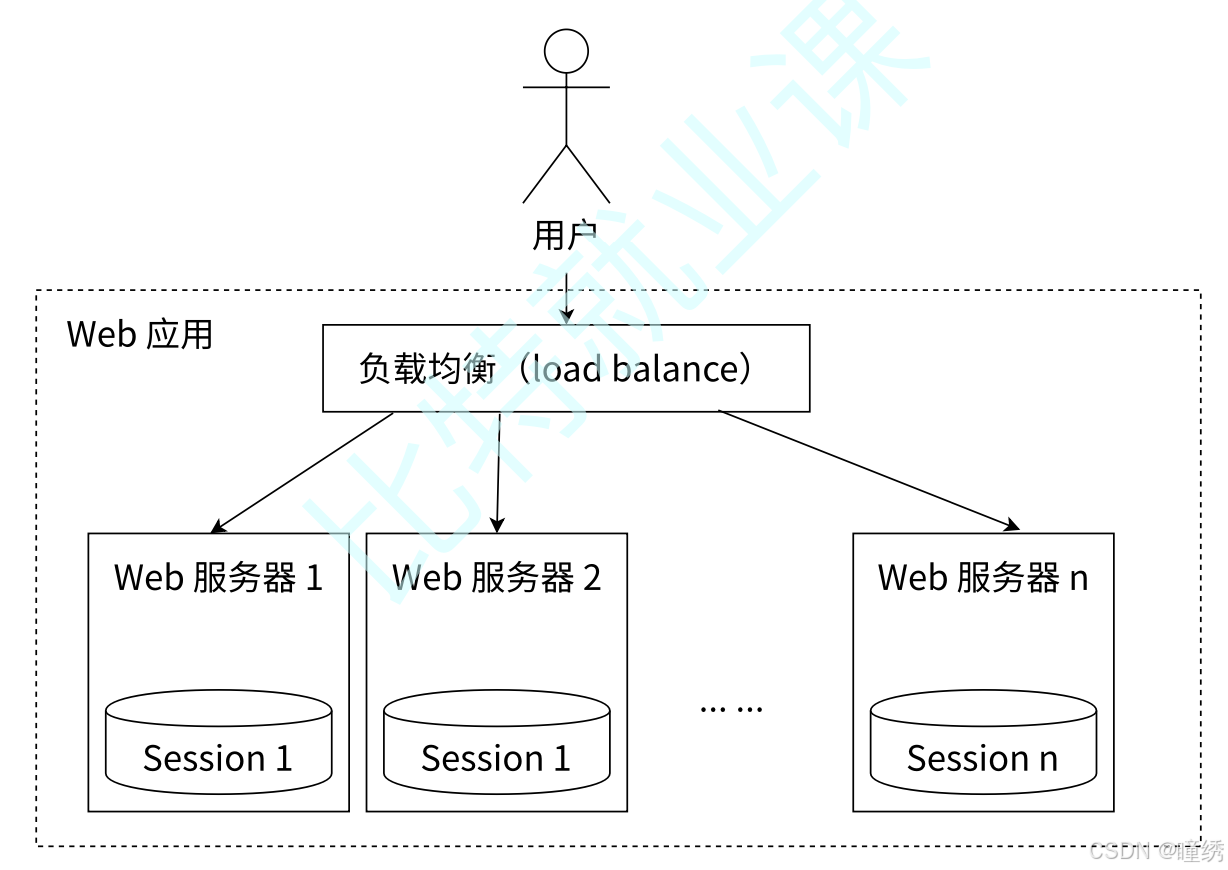
如图 2-12 所示,一个分布式 Web 服务将用户的 Session 信息(例如用户登录信息)保存在各自的服
务器中,但这样会造成一个问题:出于负载均衡的考虑,分布式服务会将用户的访问请求均衡到不同
的服务器上,并且通常无法保证用户每次请求都会被均衡到同一台服务器上,这样当用户刷新一次访
问是可能会发现需要重新登录,这个问题是用户无法容忍的。
图 2-12 Session 分散存储
为了解决这个问题,可以使用 Redis 将用户的 Session 信息进行集中管理,如图 2-13 所示,在这种
模式下,只要保证 Redis 是高可用和可扩展性的,无论用户被均衡到哪台 Web 服务器上,都集中从
Redis 中查询、更新 Session 信息。
图 2-13 Redis 集中管理 Session
2.4 手机验证码
很多应用出于安全考虑,会在每次进行登录时,让用户输入手机号并且配合给手机发送验证码,然后
让用户再次输入收到的验证码并进行验证,从而确定是否是用户本人。为了短信接口不会频繁访问,
会限制用户每分钟获取验证码的频率,例如一分钟不能超过 5 次,如图 2-14 所示。
图 2-14 短信验证码

此功能可以用以下伪代码说明基本实现思路:
String 发送验证码(phoneNumber) {
key = "shortMsg:limit:" + phoneNumber;
// 设置过期时间为 1 分钟(60 秒)
// 使用 NX,只在不存在 key 时才能设置成功
bool r = Redis 执行命令:set key 1 ex 60 nx
if (r == false) {
// 说明之前设置过该手机的验证码了
long c = Redis 执行命令:incr key
if (c > 5) {
// 说明超过了一分钟 5 次的限制了
// 限制发送
return null;
}
}
// 说明要么之前没有设置过手机的验证码;要么次数没有超过 5 次
String validationCode = 生成随机的 6 位数的验证码();
validationKey = "validation:" + phoneNumber;
// 验证码 5 分钟(300 秒)内有效
Redis 执行命令:set validationKey validationCode // 返回验证码,
随后通过手机短信发送给用户
return validationCode ;
}
// 验证用户输入的验证码是否正确
bool 验证验证码(phoneNumber, validationCode) {
validationKey = "validation:" + phoneNumber;
ex 300;
String value = Redis 执行命令:get validationKey;
if (value == null) {
// 说明没有这个手机的验证码记录,
验证失败
return false;
}
if (value == validationCode) {
return true;
} else {
return false;
}
}以上介绍了使用 Redis 的字符串数据类型可以使用的几个场景,但其适用场景远不止于此,开发人员
可以结合字符串类型的特点以及提供的命令,充分发挥自己的想象力,在自己的业务中去找到合适的
场景去使用 Redis 的字符串类型。
五、翻译翻译什么是业务?
业务其实就是一个公司 / 一个产品,是如何解决一个 / 一系列问题的,解决问题的过程就可以称为是
“业务”;
不同的公司,不同的产品,有不同的业务,不同的业务就需要不同的技术作为支撑,业务是非常重要
的,很多时候,优化技术解决不了的问题,可以通过优化业务来解决;
实际开发过程中,必须要结合实际业务场景,做一些技术上的调整,比如12306 卖火车票的例子:
12306 这个网站背后的技术积累,可以说全国甚至全世界,独一档,这个网站支撑的业务是极其恐怖
的——春运,在这个时候抢火车票 需要支撑超高的并发量,在最开始 12306 上线的时候,体验非常
差,虽然当时引入了非常多的技术,提高网站的访问速度和可用性,但是在放票的时候,整体的压力
还是很大,还是很容易出问题,通过一些常规技术手段,优化效果并不明显,但是有人提出方案: 分时
段放票,8:00 放一批(几个车次)10:00 再放——批业务上的优化12:0014:00),本来是一次放所有票现
在是分 5次,每次放五分之一,这样就相当于把瞬间的压力降低到原来的 五分之一了,全国那么多车
次,分 100 次放票,也很容易能做到。
注意⚠️:
操作 linux 的时候,千万注意,不要乱按 ctrl +s
ctrl +s在 xshell 中的作用是"冻结当前画面
ctrl +q 解除冻结~~
在启动 redis 客户端的时候,加上一个 --raw 这样的选项就可以使 redis 客户端能够自动的把二进制数据尝试翻译
redis学习打卡🥳


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











