






Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python 由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年。
像 Perl 语言一样, Python 源代码同样遵循 GPL(GNU General Public License) 协议。
发展历史
Python 是由 Guido van Rossum 在八十年代末和九十年代初,在荷兰国家数学和计算机科学研究所设计出来的。
Python 本身也是由诸多其他语言发展而来的,这包括 ABC、Modula-3、C、C++、Algol-68、SmallTalk、Unix shell 和其他的脚本语言等等。
像 Perl 语言一样,Python 源代码同样遵循 GPL(GNU General Public License)协议。
现在 Python 是由一个核心开发团队在维护,Guido van Rossum 仍然占据着至关重要的作用,指导其进展。
Python环境搭建
Python下载
Python最新源码,二进制文档,新闻资讯等可以在Python的官网查看到:
Python官网:https://www.python.org/
你可以在以下链接中下载 Python 的文档,你可以下载 HTML、PDF 和 PostScript 等格式的文档。
Python文档下载地址:https://www.python.org/doc/
集成开发环境(IDE): PyCharm
PyCharm 是由 JetBrains 打造的一款 Python IDE,支持 macOS、 Windows、 Linux 系统。
PyCharm 功能 : 调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制……
PyCharm 下载地址 : https://www.jetbrains.com/pycharm/download/
PyCharm 安装地址:http://www.runoob.com/w3cnote/pycharm-windows-install.html
python 学习笔记
1.变量赋值及命名规则
name1="solo"
name2=name1
print(name1,name2)
name1 = "hehe"
print(name1,name2)
此代码中name1的值为hehe,name2的值为solo
2.Python 条件语句
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
可以通过下图来简单了解条件语句的执行过程:
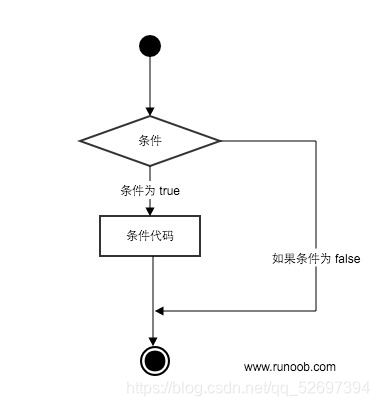
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false。
Python 编程中 if 语句用于控制程序的执行,基本形式为:
if 判断条件:
执行语句……
else:
执行语句……
if 语句的判断条件可以用>(大于)、<(小于)、==(等于)、>=(大于等于)、<=(小于等于)来表示其关系。
当判断条件为多个值时,可以使用以下形式:
if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4……
3.循环语句(while、for、嵌套循环)
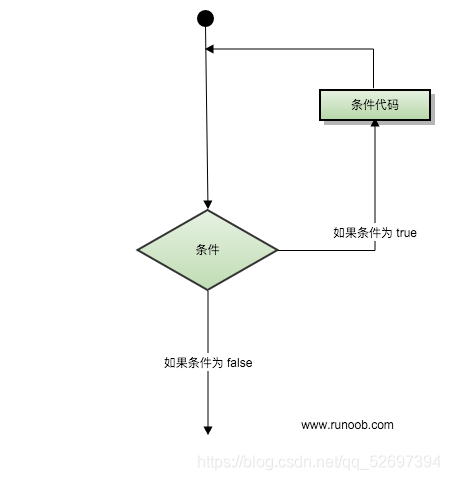
| 循环类型 | 描述 |
|---|---|
| while 循环 | 在给定的判断条件为 true 时执行循环体,否则退出循环体。 |
| for 循环 | 重复执行语句 |
| 嵌套循环 | 你可以在while循环体中嵌套for循环 |
循环控制语句
循环控制语句可以更改语句执行的顺序。
Python支持以下循环控制语句:
| 控制语句 | 描述 |
|---|---|
| break 语句 | 在语句块执行过程中终止循环,并且跳出整个循环 |
| continue 语句 | 在语句块执行过程中终止当前循环,跳出该次循环,执行下一次循环。 |
| pass 语句 | pass是空语句,是为了保持程序结构的完整性。 |
################## while语句 ######################
# A = 66
# count = 0 # 设置初始值count=0
#
# while count < 3 :
#
# B = int(input("请输入0-100的数字:"))
#
# if B == A:
# print ("恭喜你猜对了!")
# break
# elif B > A :
# print ("猜大了")
# else:
# print ("猜小了")
# count += 1
# else:
# print ("你猜的次数太多了!")
################## for语句 ######################
A = 66
i=1
for i in range(3):# while判断count是否小于3,如果小于3则:
print("i=",i)
B = int(input("请输入0-100的数字:"))
if B == A:
print ("恭喜你猜对了!")
break
elif B > A :
print ("猜小了")
else:
print ("猜大了")
i+=1
else:
print ("你猜的次数太多了!")
################## 循环嵌套######################
i = 2
while(i < 100):
j = 2
while(j <= (i/j)):
if not(i%j): break
j = j + 1
if (j > i/j) : print i, " 是素数"
i = i + 1
print "Good bye!"
4.运算符与表达式
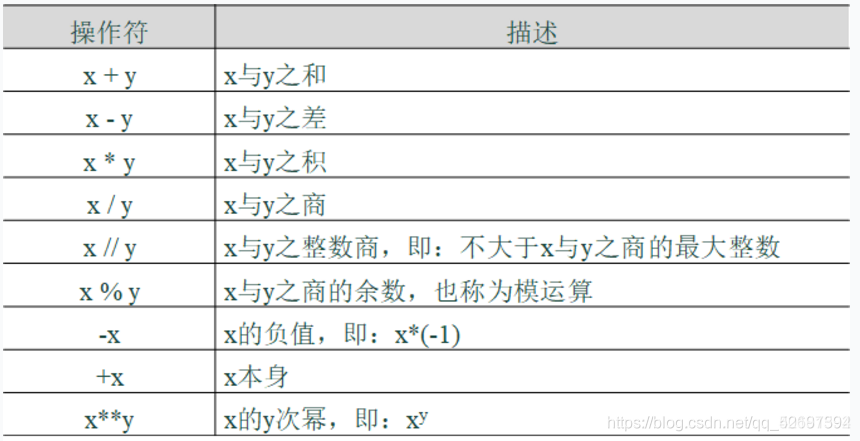
print("2/3=",2/3)
print("3//2=",3//2)
print("2**3=",2**3)
print("3.0//3.0=",3.0//2.0)
print(2>=3)
print(3>=2)
print(2!=2)
print(10 and 25)
print(0 or 20)
print(not 10)
输出结果
print("2/3=",2/3)
print("3//2=",3//2)
print("2**3=",2**3)
print("3.0//3.0=",3.0//2.0)
print(2>=3)
print(3>=2)
print(2!=2)
print(10 and 25)
print(0 or 20)
print(not 10)
5.Python函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
语法
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]
默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
其中,def 和 return 为关键字。
注意: 函数缩进后面的语句被称为是语句块,缩进是为了表名语句的逻辑与从属关系。缩进这个问题不能忽视,否则会导致代码无法成功运行,这里需要特别注意。
函数调用
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
如下实例调用了printme()函数:
# 定义函数
def printme( str ):
"打印任何传入的字符串"
print str
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")
以上实例输出结果:
我要调用用户自定义函数!
再次调用同一函数
return 语句
return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值,下例便告诉你怎么做:
实例
# 可写函数说明
def sum( arg1, arg2 ):
# 返回2个参数的和."
total = arg1 + arg2
print "函数内 : ", total
return total
# 调用sum函数
total = sum( 10, 20 )
以上实例输出结果:
函数内 : 30
6.Python 模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
例子
下例是个简单的模块 support.py:
support.py 模块:
def print_func( par ):
print "Hello : ", par
return
import 语句
模块的引入
模块定义好后,我们可以使用 import 语句来引入模块,语法如下:
import module1[, module2[,... moduleN]]
比如要引用模块 math,就可以在文件最开始的地方用 import math 来引入。在调用 math 模块中的函数时,必须这样引用:
模块名.函数名
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support.py,需要把命令放在脚本的顶端:
test.py 文件代码:
# 导入模块
import support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob")
以上实例输出结果:
Hello : Runoob
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
from…import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块 fib 的 fibonacci 函数,使用如下语句:
from fib import fibonacci
这个声明不会把整个 fib 模块导入到当前的命名空间中,它只会将 fib 里的 fibonacci 单个引入到执行这个声明的模块的全局符号表。
from…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
例如我们想一次性引入 math 模块中所有的东西,语句如下:
from math import *
搜索路径
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
1、当前目录
2、如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
3、如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
5.类的理解
类的介绍
类的定义:
class CocaCola:
formula = ['caffeine','sugar','water','soda']
使用 class 来定义一个类,就如同创建函数时使用的 def 定义一个函数一样简单。如上你可以看到定义了名为 CocaCola 的类,接着在缩进的地方有一个装载着列表的变量的 formula,这个在类里面定义的变量就是类的变量,而类的变量有一个专有的术语,我们称之为类的属性。
类的属性:
- 类变量
- 方法
①类的实例化:
coke_for_me = CocaCola()
coke_for_you = CocaCola()
②类变量属性的引用:CocaCola.formula、coke_for_me.formula
类方法的使用:
class CocaCola:
formula = ['caffeine','sugar','water','soda']
def drink(self):
print('Energy!')
coke = CocaCola()
coke.drink()
结果:
Energy!
self
我想很多人会有关注到这个奇怪的地方——似乎没有派上任何用场的self参数。我们来说明下原理,其实很简单,我们修改下上面的代码:
class CocaCola:
formula = ['caffeine','sugar','water','soda']
def drink(coke): # 把self改为coke
print('Energy!')
coke = CocaCola()
coke.drink()
结果:
Energy!
这个参数其实就是被创建的实例本身。也就是将一个个对象作为参数放入函数括号内,再进一步说,一旦一个类被实例化,那么我们其实可以使用和与我们使用函数相似的方式:
coke = CocaCola
coke.drink() == CocaCola.drink(coke) #左右两边的写法完全一致
被实例化的对象会被编译器默默地传入后面方法的括号中,作为第一个参数。上面两个方法是一样的,但我们更多地会写成前面那种形式。其实self这个参数名称是可以随意修改的(编译器并不会因此而报错)。
和函数一样,类的方法也能有属于自己的参数,如下:
class CocaCola:
formula = ['caffeine','sugar','water','soda']
def drink(self,how_much):
if how_much == 'a sip':
print('Cool~')
elif how_much == 'whole bottle’:
print('Headache!')
ice_coke = CocaCola()
ice_coke.drink('a sip')
结果:
Cool~
魔术方法
Python 的类中存在一些方法,被称为「魔术方法」,_init_()就是其中之一。
class CocaCola():
formula = ['caffeine','sugar','water','soda']
def __init__(self):
self.local_logo = '可口可乐'
def drink(self):
print('Energy!')
coke = CocaCola()
print(coke.local_logo)
作用:在创建实例之前,它做了很多事情。说直白点,意味着即使你在创建实例的时候不去引用 init_() 方法,其中的语句也会先被自动的执行。这给类的使用提供了极大的灵活性。
class CocaCola:
formula = ['caffeine','sugar','water','soda']
def __init__(self,logo_name):
self.local_logo = logo_name
def drink(self):
print('Energy!')
coke = CocaCola('ݢݗݢԔ')
coke.local_logo
>>> 可口可乐
类的继承
如下代码:
class CaffeineFree(CocaCola):
caffeine = 0
ingredients = [
'High Fructose Corn Syrup',
'Carbonated Water',
'Phosphoric Acid',
'Natural Flavors',
'Caramel Color',
]
coke_a = CaffeineFree('Cocacola-FREE')
coke_a.drink()
表示 CaffeineFree 继承了 CocaCola 类。
类中的变量和方法可以被子类继承,但如需有特殊的改动也可以进行覆盖。
Q1:类属性如果被重新赋值,是否会影响到类属性的引用?
class TestA():
attr = 1
obj_a = TestA()
TestA.attr = 24
print(obj_a.attr)
>>> 结果:24
A1:会影响。
Q2:实例属性如果被重新赋值,是否会影响到类属性的引用?
class TestA:
attr = 1
obj_a = TestA()
obj_b = TestA()
obj_a.attr = 42
print(obj_b.attr)
>>> 结果:1
A2:不会影响。
Q3:类属性实例属性具有相同的名称,那么.后面引用的将会是什么?
class TestA():
attr =1
def __init__(self):
self.attr = 24
obj_a = TestA()
print(obj_a.attr)
>>> 结果:24
A3:类属性赋值后的值。
总结:如图所示,Python 中属性的引用机制是自外而内的,当你创建了一个实例之后,准备开始引用属性,这时候编译器会先搜索该实例是否拥有该属性,如果有,则引用;如果没有,将搜索这个实例所属的类是否有这个属性,如果有,则引用,没有那就只能报错了。

















 4472
4472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









