






目录
摘要
U-Net是基于FCN的原理进行改进,以适应小样本的分割任务。U-Net的核心结构由对称的编码器-解码器组成。编码器通过卷积和池化操作逐步提取图像的抽象特征并降低分辨率,从而捕捉全局语义信息;解码器通过上采样和卷积操作逐步恢复分辨率,并结合编码器提供的低层特征图重建目标的细节信息,从而实现精确分割。U型结构和跳跃连接的设计有效解决了深层网络中的细节丢失问题。U-Net通过数据增强技术,能够在有限的标注数据上进行高效训练。该网络模型结构简单且高效,能够在保证分割精度的同时减少计算量。
Abstract
U-Net is an improvement based on the principles of FCN to adapt to segmentation tasks with limited samples. The core structure of U-Net consists of a symmetric encoder-decoder architecture. The encoder gradually extracts abstract features from the image and reduces resolution through convolution and pooling operations to capture global semantic information. The decoder restores the resolution step by step through upsampling and convolution operations and reconstructs the details of the target by combining low-level feature maps from the encoder, thereby achieving precise segmentation. The U-shaped structure and skip connections effectively solve the problem of detail loss in deep networks. U-Net employs data augmentation techniques to efficiently train on limited labeled data. The network is simple and efficient, reducing computational load while maintaining segmentation accuracy.
U-Net
论文链接:[1505.04597] U-Net: Convolutional Networks for Biomedical Image Segmentation
网络结构
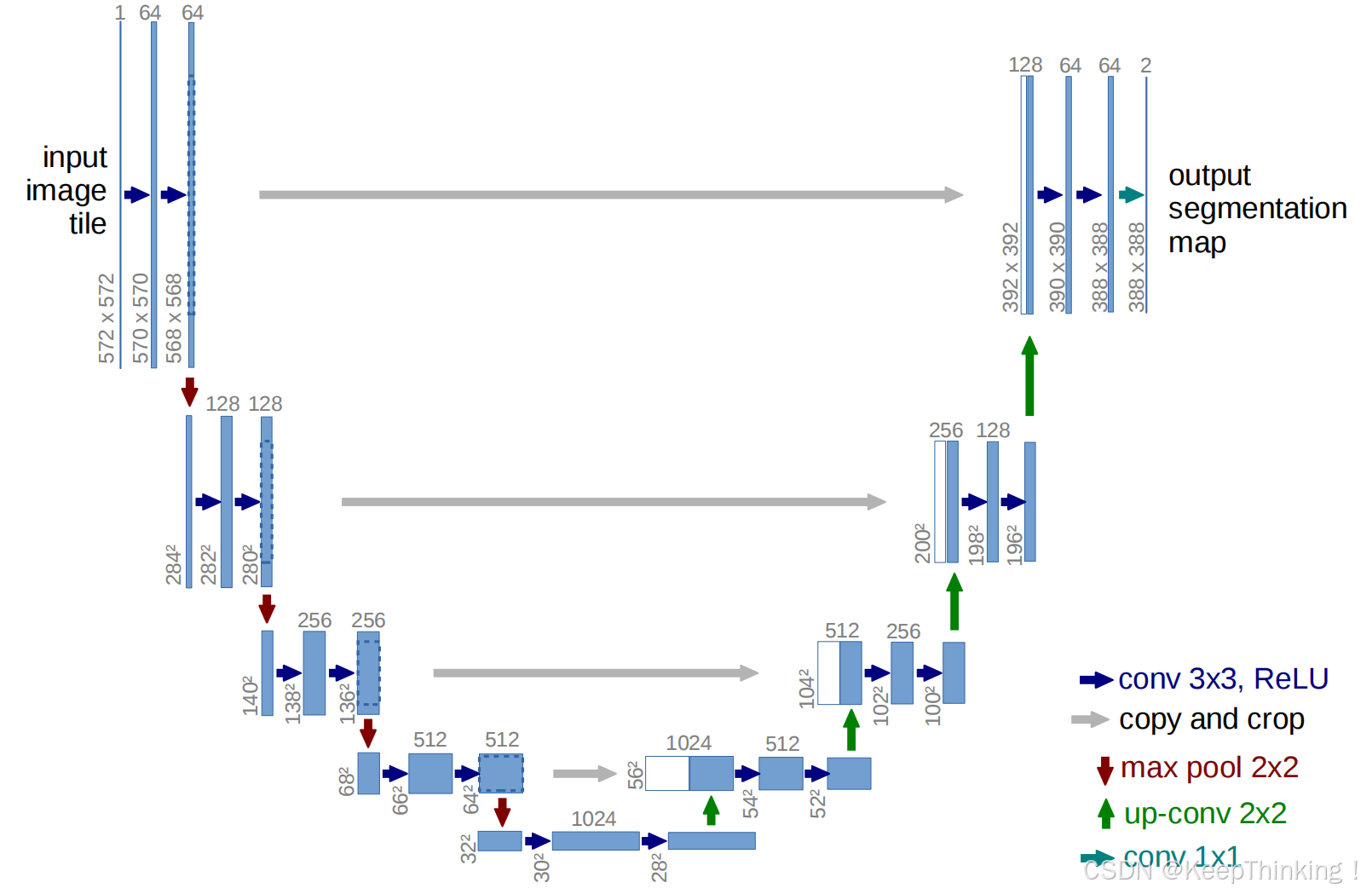
U-Net网络形状像“U”,故被称为U-Net。
在学习网络模型之前,我们先了解一下上图右下角各个箭头代表的操作。
- conv 3x3,ReLu:卷积层,其中卷积核大小是 3x3 ,然后经过ReLu激活;
- copy and crop:复制和裁剪。对于输出的特征图像尺寸,需要进行复制并进行中心剪裁,方便和后面上采样生成的特征图像尺寸进行拼接;
- max pool 2x2:最大池化层,卷积核为 2x2 ;
- up-conv 2x2:反卷积,用于上采样,卷积核为 2x2 。本文中使用的是ConvTranspose2d()函数进行该操作;
- conv 1x1:卷积层,卷积核大小是1x1。
编码器
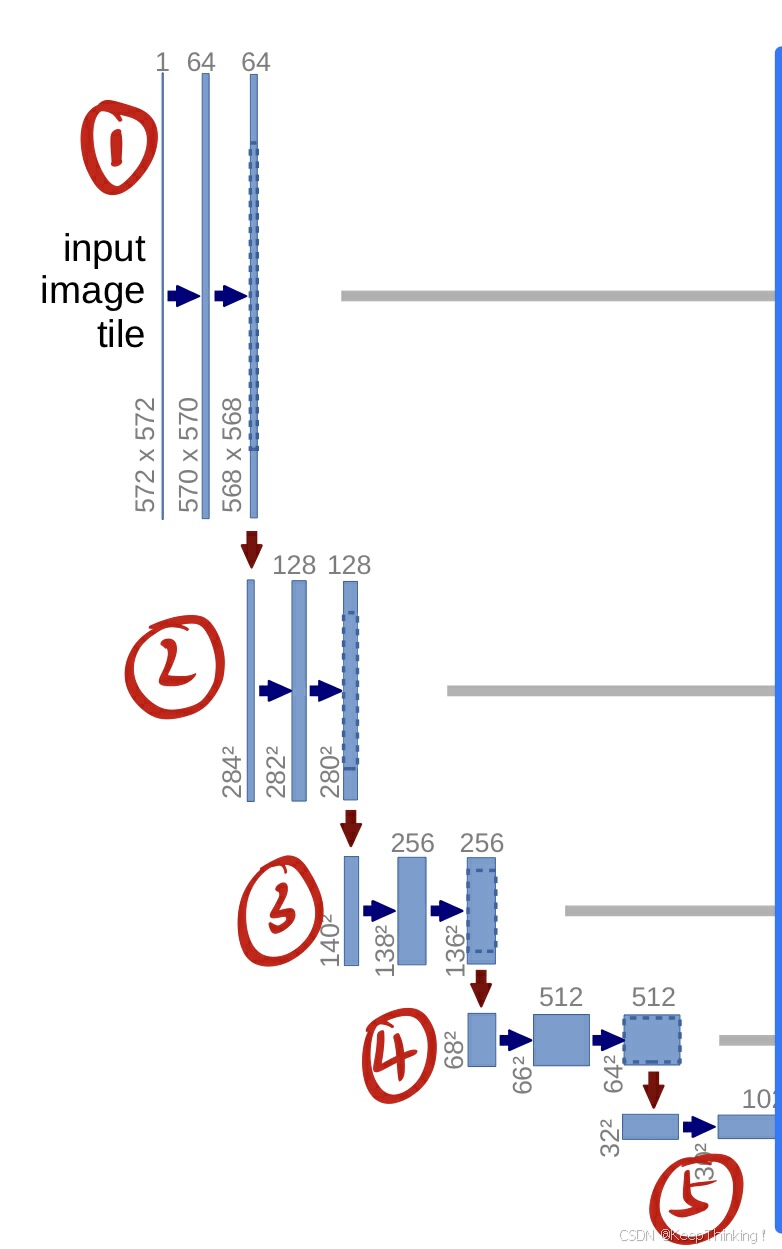
U-Net网络的左半部分为编码器,如上图所示。编码器通过卷积和池化操作逐步提取图像的抽象特征并降低分辨率,从而捕捉全局语义信息。
- 第一部分
由U-Net网络架构图可以看出输入图像是 1x572x572 的大小,其中的1代表的是通道数,输出通道是64,并且通过 3x3 的卷积操作,并且由图片中的尺寸变成570x570,因此可以得出相关的参数值in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0,整个图片的蓝色箭头的卷积操作都是这样,因此 kernel_size=3, stride=1, padding=0 可以固定了。只需要更改输入和输出通道数的大小即可。
数据维度变化:1x572x572 --> 64x570x570 --> 64x568x568
# 由572*572*1变成了570*570*64
self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu1_1 = nn.ReLU(inplace=True)
# 由570*570*64变成了568*568*64
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0)
self.relu1_2 = nn.ReLU(inplace=True)红色箭头处最大池化的卷积核和步长都设置为 2 ,使得输出特征图像大小减半,通道数不变。
数据维度变化:64x568x568 --> 64x284x284
# 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2) - 第二部分
进行的操作与第一部分相同,只是参数传递的大小不同。
数据维度变化:64x284x284 --> 128x282x282 --> 128x280x280
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128
self.relu2_2 = nn.ReLU(inplace=True)
最大池化设置相同,其数据维度变化:128x280x280 --> 128x140x140
# 采用最大池化进行下采样 280*280*128->140*140*128
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2) 重复上述步骤进行到第五部分即可,左半部分编码器整体代码如下:
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0) # 由572*572*1变成了570*570*64
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 由570*570*64变成了568*568*64
self.relu1_2 = nn.ReLU(inplace=True)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128
self.relu2_2 = nn.ReLU(inplace=True)
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 280*280*128->140*140*128
self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0) # 140*140*128->138*138*256
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 138*138*256->136*136*256
self.relu3_2 = nn.ReLU(inplace=True)
self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 136*136*256->68*68*256
self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0) # 68*68*256->66*66*512
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 66*66*512->64*64*512
self.relu4_2 = nn.ReLU(inplace=True)
self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 64*64*512->32*32*512
self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0) # 32*32*512->30*30*1024
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=0) # 30*30*1024->28*28*1024
self.relu5_2 = nn.ReLU(inplace=True)因为U-Net涉及到 copy and crop,在前向传播时如果全部步骤都当作 x,那么就无法复制和裁剪了,因为每次都是对最终结果进行复制,而不是中间步骤进行复制。需要在在最大池化之前,有个新变量保存输出的特征图像,方便后续进行复制和裁剪。
前向传播代码如下:
def forward(self, x):
x1 = self.conv1_1(x)
x1 = self.relu1_1(x1)
x2 = self.conv1_2(x1)
x2 = self.relu1_2(x2) # 这个后续需要使用
down1 = self.maxpool_1(x2)
x3 = self.conv2_1(down1)
x3 = self.relu2_1(x3)
x4 = self.conv2_2(x3)
x4 = self.relu2_2(x4) # 这个后续需要使用
down2 = self.maxpool_2(x4)
x5 = self.conv3_1(down2)
x5 = self.relu3_1(x5)
x6 = self.conv3_2(x5)
x6 = self.relu3_2(x6) # 这个后续需要使用
down3 = self.maxpool_3(x6)
x7 = self.conv4_1(down3)
x7 = self.relu4_1(x7)
x8 = self.conv4_2(x7)
x8 = self.relu4_2(x8) # 这个后续需要使用
down4 = self.maxpool_4(x8)
x9 = self.conv5_1(down4)
x9 = self.relu5_1(x9)
x10 = self.conv5_2(x9)
x10 = self.relu5_2(x10)跳跃连接
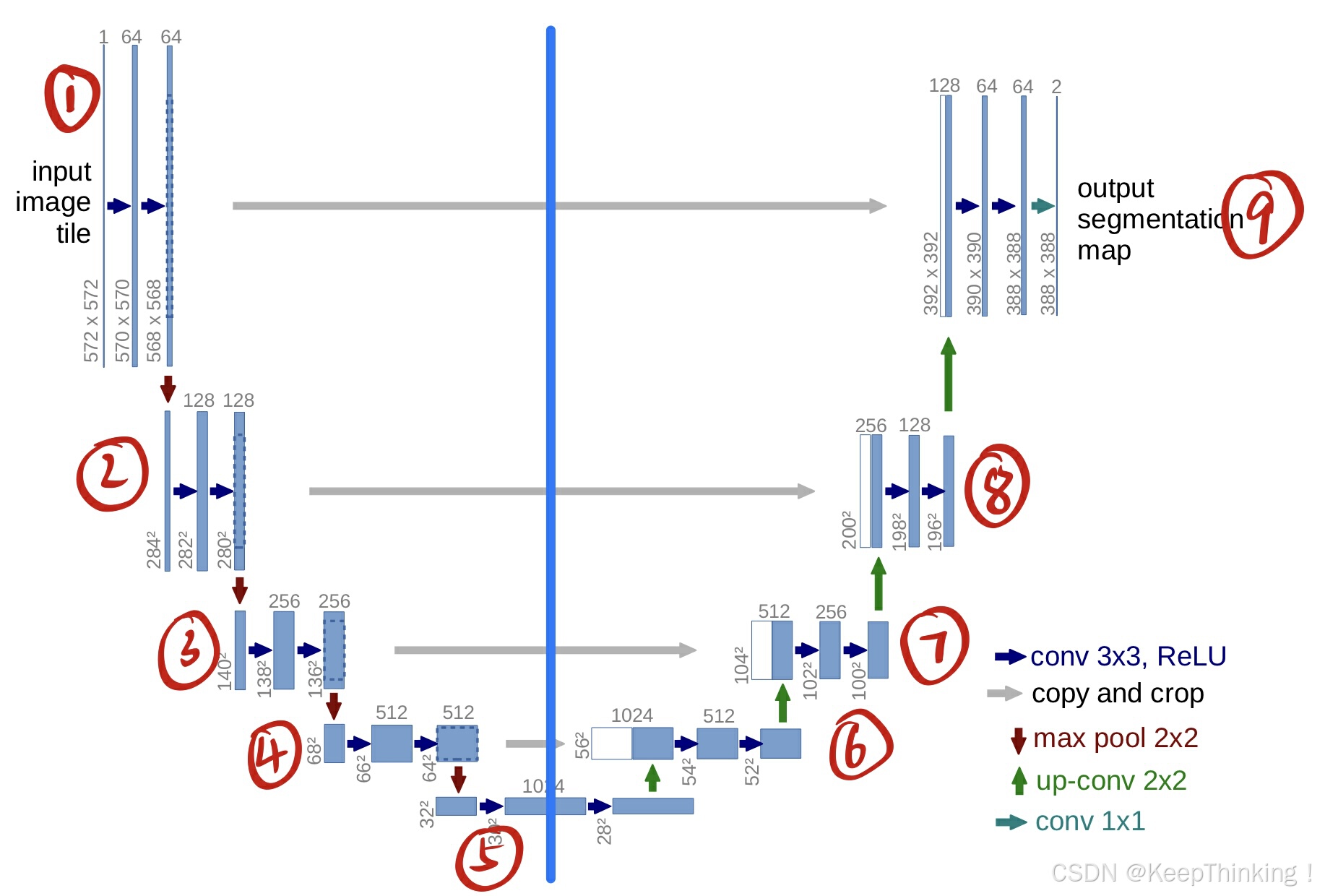
U-Net中的跳跃连接是网络架构的核心创新,将编码器中的低层特征图与解码器中的对应层进行连接,也就是上图灰色箭头copy and crop部分(1连9、2连8等)。跳跃连接将编码器中提取的高分辨率、细节丰富的低层特征传递到解码器中,从而在上采样过程中更好地恢复图像的空间分辨率。
编码器通过卷积和池化操作逐步降低特征图的空间分辨率,同时提取高级语义信息。然而,这一过程会导致图像的细节信息丢失。为了解决这一问题,跳跃连接将编码器中的特征图像复制,并根据解码器中上采样特征图的尺寸进行裁剪,以确保两者在空间维度上一致。裁剪后的特征图与解码器中的上采样特征图在通道维度上进行拼接,通常使用 torch.cat 函数实现。拼接后的特征图会经过一系列卷积操作,进一步提取和融合特征,从而实现低层细节信息与高层语义信息的结合。
例如 4 --> 6 进行的第一次上采样,以及拼接操作:
# 第一次上采样,以及Copy and crop up1 = self.up_conv_1(x10) # 得到56*56*512 # 需要对x8进行裁剪,从中心往外裁剪 crop1 = self.crop_tensor(x8, up1) # 拼接操作 up_1 = torch.cat([crop1, up1], dim=1)
跳跃连接的主要作用:保留细节信息、增强分割精度、解决信息丢失问题。
解码器
最下面第5部分是 1024x28x28 的特征图像,经过绿色箭头up-conv 2x2 上采样,得到 512x56x56的特征图像,尺寸扩大一倍,通道数减半。在第4部分和第6部分横向连接的灰色箭头左边的特征图像是 512x64x64 ,然后对其进行复制并中心裁剪,最后得到 512x56x56 的特征图像。将该特征图像和上采样得到的图像进行通道上的拼接,最后得到 1024x56x56 的特征图像。重复上述步骤,就能够得到和原图大小相同的分割图像。
解码器代码如下所示:
self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0) # 56*56*1024->54*54*512
self.relu6_1 = nn.ReLU(inplace=True)
self.conv6_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 54*54*512->52*52*512
self.relu6_2 = nn.ReLU(inplace=True)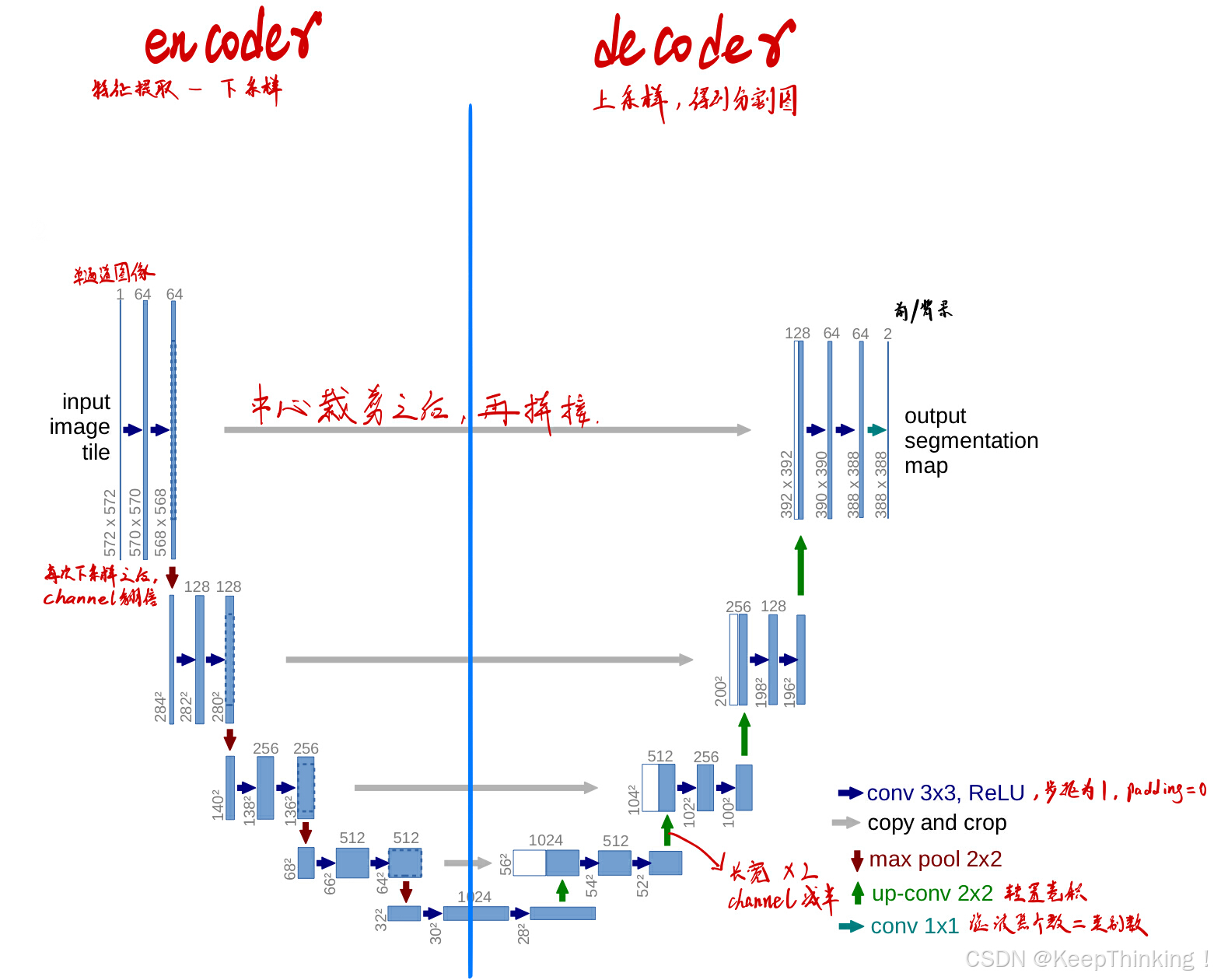
U-Net网络结构整体代码如下所示:
import torch
import torch.nn as nn
from torch.nn import functional as F
# 基本卷积块
class Conv(nn.Module):
def __init__(self, C_in, C_out):
super(Conv, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(C_in, C_out, 3, 1, 1),
nn.BatchNorm2d(C_out),
# 防止过拟合
nn.Dropout(0.3),
nn.LeakyReLU(),
nn.Conv2d(C_out, C_out, 3, 1, 1),
nn.BatchNorm2d(C_out),
# 防止过拟合
nn.Dropout(0.4),
nn.LeakyReLU(),
)
def forward(self, x):
return self.layer(x)
# 下采样模块
class DownSampling(nn.Module):
def __init__(self, C):
super(DownSampling, self).__init__()
self.Down = nn.Sequential(
# 使用卷积进行2倍的下采样,通道数不变
nn.Conv2d(C, C, 3, 2, 1),
nn.LeakyReLU()
)
def forward(self, x):
return self.Down(x)
# 上采样模块
class UpSampling(nn.Module):
def __init__(self, C):
super(UpSampling, self).__init__()
# 特征图大小扩大2倍,通道数减半
self.Up = nn.Conv2d(C, C // 2, 1, 1)
def forward(self, x, r):
# 使用邻近插值进行下采样
up = F.interpolate(x, scale_factor=2, mode="nearest")
x = self.Up(up)
# 拼接,当前上采样的,和之前下采样过程中的
return torch.cat((x, r), 1)
# 主干网络
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
# 4次下采样
self.C1 = Conv(3, 64)
self.D1 = DownSampling(64)
self.C2 = Conv(64, 128)
self.D2 = DownSampling(128)
self.C3 = Conv(128, 256)
self.D3 = DownSampling(256)
self.C4 = Conv(256, 512)
self.D4 = DownSampling(512)
self.C5 = Conv(512, 1024)
# 4次上采样
self.U1 = UpSampling(1024)
self.C6 = Conv(1024, 512)
self.U2 = UpSampling(512)
self.C7 = Conv(512, 256)
self.U3 = UpSampling(256)
self.C8 = Conv(256, 128)
self.U4 = UpSampling(128)
self.C9 = Conv(128, 64)
self.Th = torch.nn.Sigmoid()
self.pred = torch.nn.Conv2d(64, 3, 3, 1, 1)
def forward(self, x):
# 下采样部分
R1 = self.C1(x)
R2 = self.C2(self.D1(R1))
R3 = self.C3(self.D2(R2))
R4 = self.C4(self.D3(R3))
Y1 = self.C5(self.D4(R4))
# 上采样部分
# 上采样的时候需要拼接起来
O1 = self.C6(self.U1(Y1, R4))
O2 = self.C7(self.U2(O1, R3))
O3 = self.C8(self.U3(O2, R2))
O4 = self.C9(self.U4(O3, R1))
# 输出预测,这里大小跟输入是一致的
# 可以把下采样时的中间抠出来再进行拼接,这样修改后输出就会更小
return self.Th(self.pred(O4))
if __name__ == '__main__':
a = torch.randn(2, 3, 256, 256)
net = UNet()
print(net(a).shape)训练
U-Net损失函数:softmax激活函数 + 带权重的交叉熵损失函数 + 权重计算函数
- softmax激活函数将每个像素点的输入特征与权重做非线性叠加。每个像素点经过softmax的处理后产生的输出值个数等于标签里的类别数,并得到每个像素点中每个类的置信度。
- 交叉熵损失函数用来衡量两个概率分布差异的测量函数。U-Net使用的是带边界权重的交叉熵损失函数:
x:经softmax处理后的输出值;
I:Ω → {1, . . . , K},是每个像素的真实标签;
:点x在对应的label给出的那个类别的输出的激活值;
w : Ω → R 是在训练过程中添加给每个像素的权重。
- 权重计算函数
模型训练代码如下:
from torch import optim
import torch.nn as nn
import torch
def train_net(net, device, data_path, epochs=40, batch_size=1, lr=0.00001):
# 加载训练集
isbi_dataset = ISBI_Loader(data_path)
train_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,
batch_size=batch_size,
shuffle=True)
# 定义RMSprop算法
optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9) # 常用的优化器
# 定义Loss算法
criterion = nn.BCEWithLogitsLoss() # 就是一个将sigmoid函数和BCELOSS函数结合的一种loss函数
# best_loss统计,初始化为正无穷
best_loss = float('inf')
# 训练epochs次
for epoch in range(epochs):
# 训练模式
net.train() # 打开训练模式
i = 1
# 按照batch_size开始训练
for image, label in train_loader:
i = i + 1
optimizer.zero_grad()
# 将数据拷贝到device中
image = image.to(device=device, dtype=torch.float32)
label = label.to(device=device, dtype=torch.float32)
# 使用网络参数,输出预测结果
pred = net(image)
# 计算loss
loss = criterion(pred, label)
if i==30 :
print('Loss/train', loss.item())
# 保存loss值最小的网络参数
if loss < best_loss:
best_loss = loss
torch.save(net.state_dict(), 'best_model.pth')
# 更新参数
loss.backward() # 反向传播
optimizer.step()
if __name__ == "__main__":
# 选择设备,有cuda用cuda,没有就用cpu
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载网络,图片单通道1,分类为1。
net = UNet(1,1)
# 将网络拷贝到deivce中
net.to(device=device)
# 指定训练集地址,开始训练
data_path = "../input/unet-train/lesson-2/data/train"
train_net(net, device, data_path)训练过程:
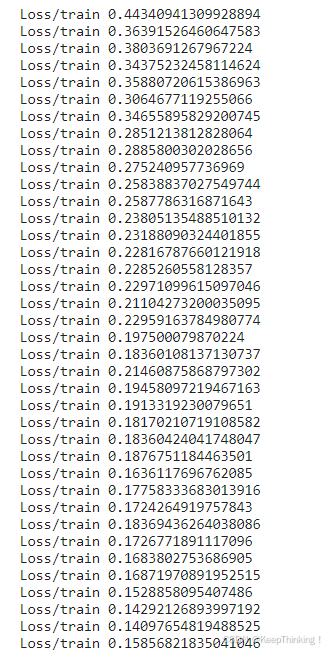
模型预测代码如下所示:
import glob
import numpy as np
import torch
import os
import cv2
if __name__ == "__main__":
# 选择设备,有cuda用cuda,没有就用cpu
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载网络,图片单通道,分类为1。
net = UNet(1, 1)
# 将网络拷贝到deivce中
net.to(device=device)
# 加载模型参数
net.load_state_dict(torch.load('./best_model.pth', map_location=device))
# 测试模式
net.eval()
# 读取所有图片路径
tests_path = glob.glob('../input/unet-train/lesson-2/data/test/*.png')
print(tests_path)
# 遍历素有图片
for test_path in tests_path:
# 保存结果地址
save_res_path = test_path.split('/')[6] + '_res.png'
print(save_res_path)
# 读取图片
img = cv2.imread(test_path)
# 转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# 转为batch为1,通道为1,大小为512*512的数组
img = img.reshape(1, 1, img.shape[0], img.shape[1])
# 转为tensor
img_tensor = torch.from_numpy(img)
# 将tensor拷贝到device中,只用cpu就是拷贝到cpu中,用cuda就是拷贝到cuda中。
img_tensor = img_tensor.to(device=device, dtype=torch.float32)
# 预测
pred = net(img_tensor)
# 提取结果
pred = np.array(pred.data.cpu()[0])[0]
# 处理结果
pred[pred >= 0.5] = 255
pred[pred < 0.5] = 0
# 保存图片
cv2.imwrite(save_res_path, pred)效果展示:
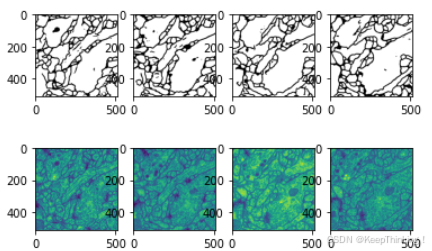
总结
U-Net自提出以来,在医学图像分割和其他视觉任务中取得了显著成就,尤其是在处理小样本数据时表现出色,成为图像分割领域的经典模型。U-Net对称的编码器-解码器结构和跳跃连接设计有效解决了细节丢失问题,还为后续分割模型提供了重要借鉴。目前,在很多领域都有U-Net的身影,例如扩散生成模型等,这些都是很好的研究方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









