




 本文提出基于协方差矩阵的函数测量特征分布,设计可微损失函数训练网络学习共享信息,用自监督学习策略引导多模态任务关注私有信息。介绍了文本、音频、视觉特征提取及模态融合等方法,构建深度模态共享信息学习模块,在多模态情感分析基准数据集实验,结果优于现有方法。
本文提出基于协方差矩阵的函数测量特征分布,设计可微损失函数训练网络学习共享信息,用自监督学习策略引导多模态任务关注私有信息。介绍了文本、音频、视觉特征提取及模态融合等方法,构建深度模态共享信息学习模块,在多模态情感分析基准数据集实验,结果优于现有方法。
1. 文章贡献
- 提出了一个基于协方差矩阵的函数作为二阶统计量来测量特征在对齐和拉伸模式之间的分布。
- 我们设计了一个可微损失函数来训练网络学习模态之间的共享信息。
- 使用自监督学习策略生成模块来引导多模态任务专注于模态特定的私有信息。
- 在三个多模态情感分析的基准数据集上进行了全面的实验,以验证我们设计的模块的可行性。我们的方法优于目前最先进的方法。
其中1、3参考拼接的论文
A domain generalization network combing invariance and specificity towards real-time intelligent fault diagnosis
Learning modality-specific representations with self-supervised multi-task learning for multimodal
sentiment analysis
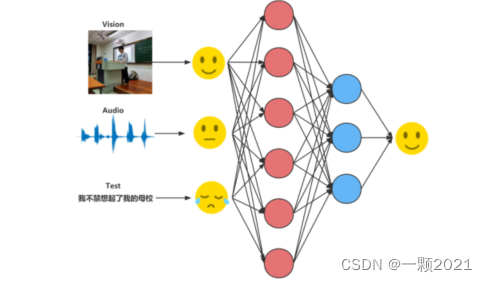
2.相关工作
A. MSA
B. BERT
C. LSTM
D. ULGM
E. Domain generalization
F. Multi-Task learning
3. 方法
A.文本特征提取——Bert
B.音频特征提取——预训练工具包+sLSTM
C.视觉特征提取——视觉初始特征提取工具包+sLSTM
D.模态融合——将三个特征拼接成一个序列之后投射到相同的低维空间中。
E.预测分析——由一个线形层完成分类或回归任务
F.特征投影&融合与ULGM模块
ULGM模块根据从单模态特殊到多模态类中心的相对距离计算偏移量(单模态表示到正中心和负中心的相对距离)。使用基于动量的更新策略将新生成的单峰标签与历史生成的单峰标签组合在一起。该策略有助于自监督生成的单峰标签在子任务训练过程中逐渐稳定下来。
参考Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis这篇文章,不再详细介绍。
G. 深度模态共享信息学习模块
深度模态共享信息学习模块是在深度学习系统中从多个模态中提取共享信息的有效工具。该模块可以提取任意两种指定模式之间的共享信息,例如音频和视觉数据。
对于音频模态,使用Featurea;对于视觉模态Featurev。由于每次训练都是基于特定的一批数据,所以这里设置音频模态F特征和F特征的个数分别为Na和Nv(因为是同一批数据,所以Na = Nv)。每个Featurea特征和Featurev特征被投影到d维空间中。
音频和视频模态的单批矩阵。
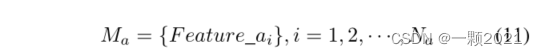
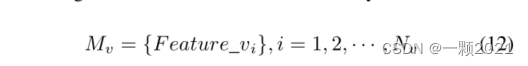
分别构造音频模态和视觉模态的协方差矩阵。使用基于协方差矩阵的函数来反映模态之间共享的信息内容。
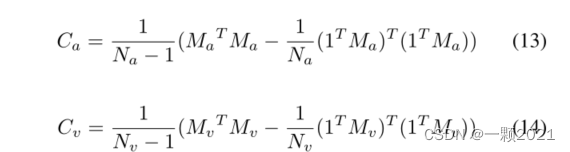
构建损失函数,促进多模态情感分析模型关注和学习模态之间的共享信息。
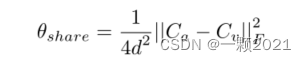
计算梯度。已知θshare是一个可微函数,可以在网络中反向传播。
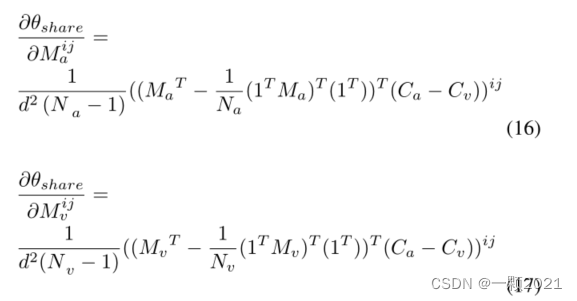
该模块的思想是通过模态间的二阶统计量来匹配模态间的分布。
整个模块的任务是最小化函数。
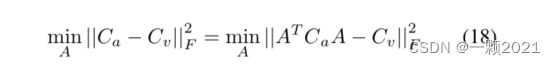
H.整体优化目标函数
总体优化目标函数分为三类,即多模态任务、单模态任务和模态深度特征对齐任务。


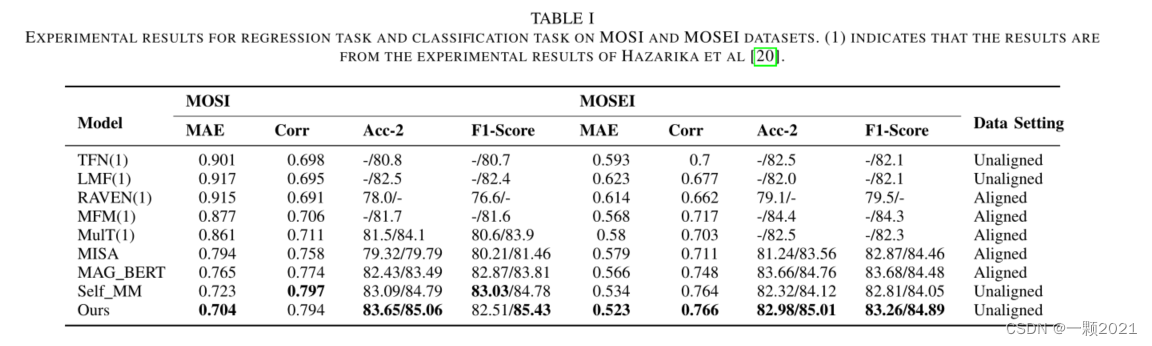
4.实验


















 1508
1508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











