







逻辑回归
概述
当一看到“回归”这两个字,可能会认为逻辑回归是一种解决回归问题的算法,然而逻辑回归是通过回归的思想来解决二分类问题的算法。(不是回归,是二分类算法;机器学习算法一般都是先选择逻辑回归再用复杂的)。
逻辑回归是将样本特征和样本所属类别的概率联系在一起,假设现在已经训练好了一个逻辑回归的模型为 f(x) ,模型的输出是样本 x 的标签是 1 的概率,则该模型可以表示
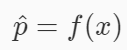
若得到了样本 x 属于标签 1 的概率后,很自然的就能想到当
0.5 时 x 属于标签 1 ,否则属于标签 0 。由于概率是 0 到 1 的实数,所以逻辑回归若只需要计算出样本所属标签的概率就是一种回归算法,若需要计算出样本所属标签,则就是一种二分类算法。
sigmod函数
sigmod函数公式为
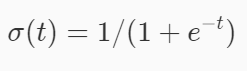
先来用代码绘制一下它的图像吧
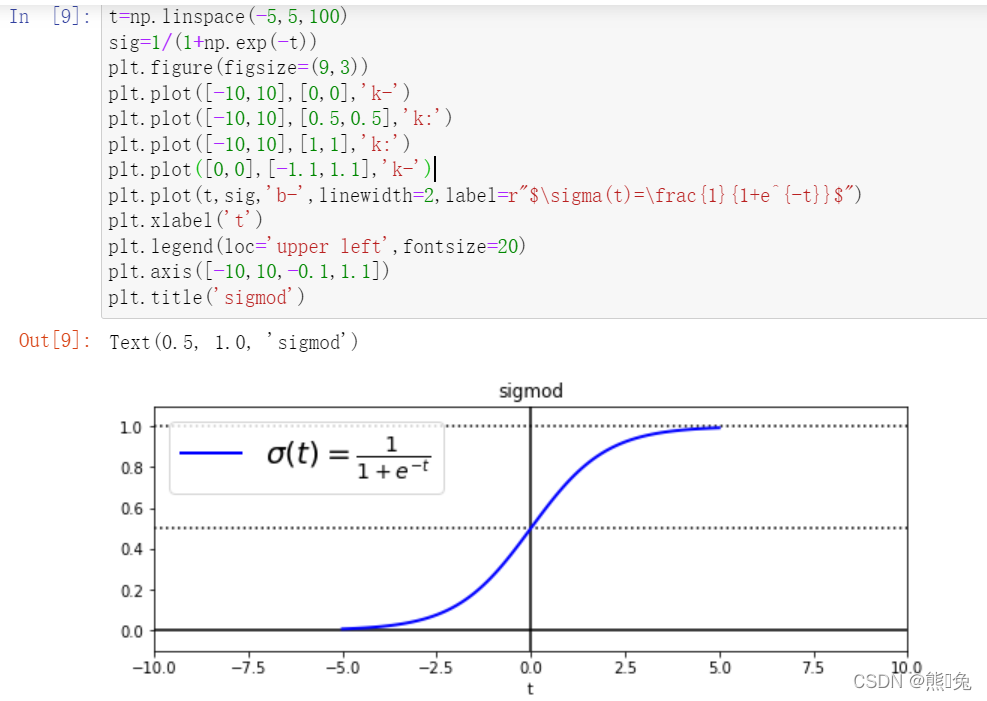
从sigmoid函数的图像可以看出当 t 趋近于 −∞ 时函数值趋近于 0 ,当 t 趋近于 +∞ 时函数值趋近于 1 。可见sigmoid函数的值域是 (0,1) ,满足我们要将 (−∞,+∞) 的实数转换成 (0,1) 的概率值的需求。因此逻辑回归在预测时可以看成
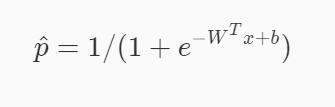
代码实现sigmod函数:
import numpy as np
def sigmoid(t):
return 1 / (1 + np.exp(-t))
梯度下降
梯度:
前面文章有提到说进行参数的更新,优化算法,机器算法中便是利用梯度下降的思想来进行算法模型优化的。机器学习的套路就是用户交给机器一堆数据,然后告诉它什么样的学习方式是对的(目标函数),让它朝着这个方式去做。
梯度:梯度的本意是一个向量,由函数对每个参数的偏导组成,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向变化最快,变化率最大。
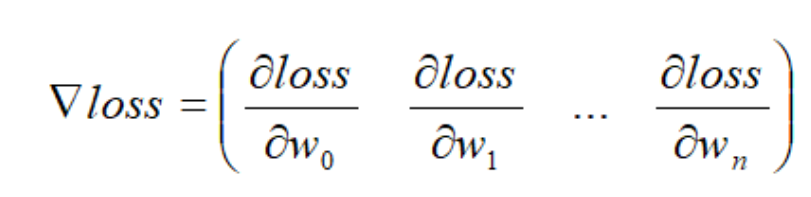
梯度下降:
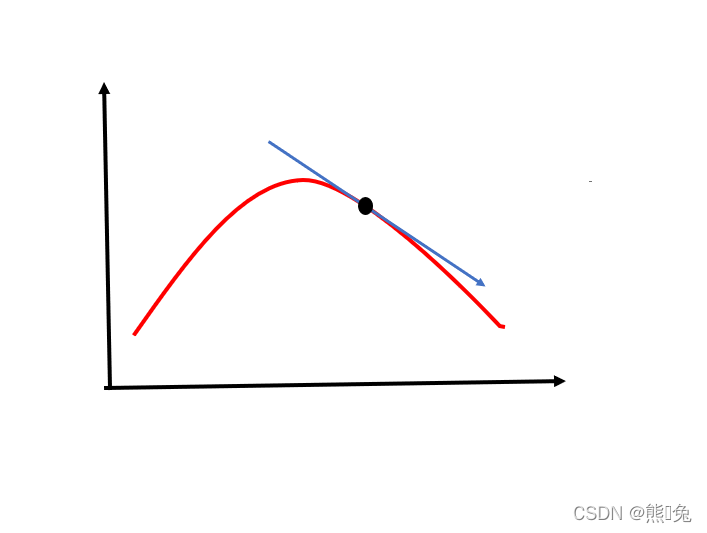
梯度下降是一种非常通用的优化算法,能够为大范围的问题找到最优解。梯度下降的中心思想就是迭代地调整参数从而使损失函数最小化。通过测量参数向量 θ 相关的损失函数的局部梯度,并不断沿着降低梯度的方向调整,直到梯度降为 0 ,达到最小值。
梯度下降的目标函数:这表示的是在 θj 的反方向上走一步。因为梯度下降是函数对 θ求导,求取的方向是向上的,现在我们需要的是向下的
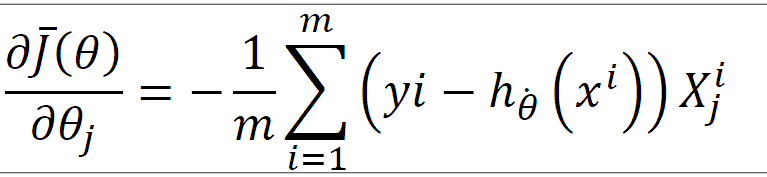
因此梯度的更新中间是加法,因为加上一个负号,即在 θj的方向上走一步。
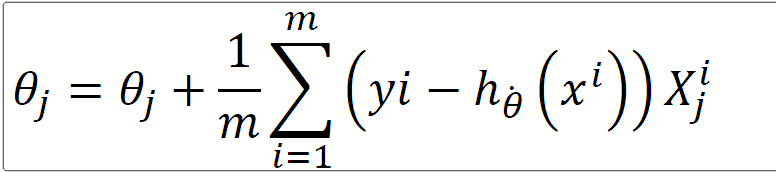
机器学习中有三种梯度下降的方式:
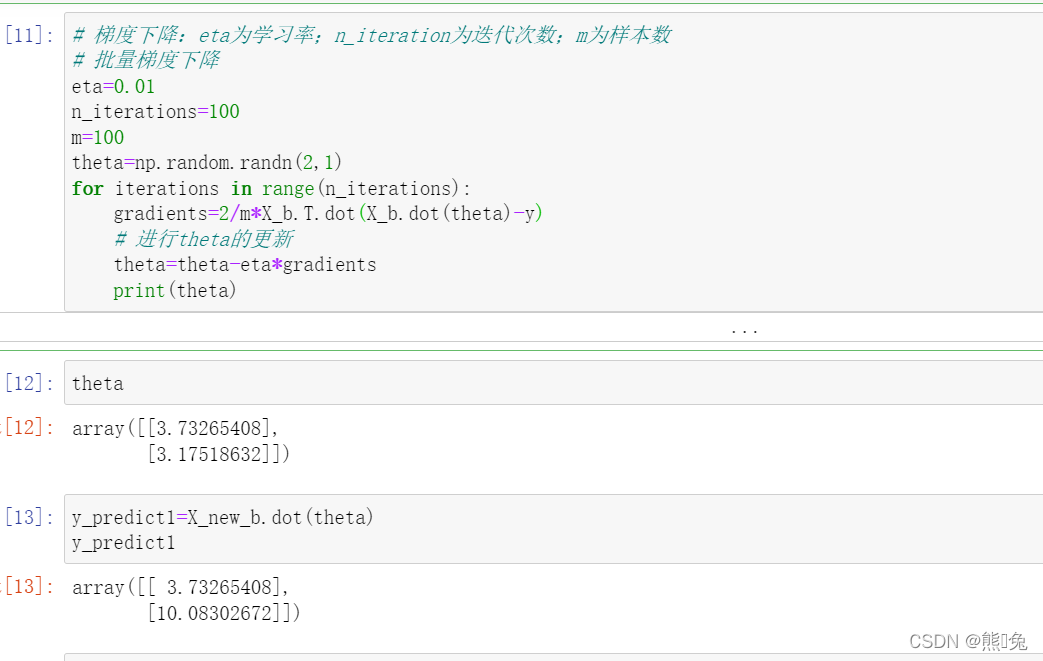
① 批量梯度下降:即是上面所显示在公式:
代码实现
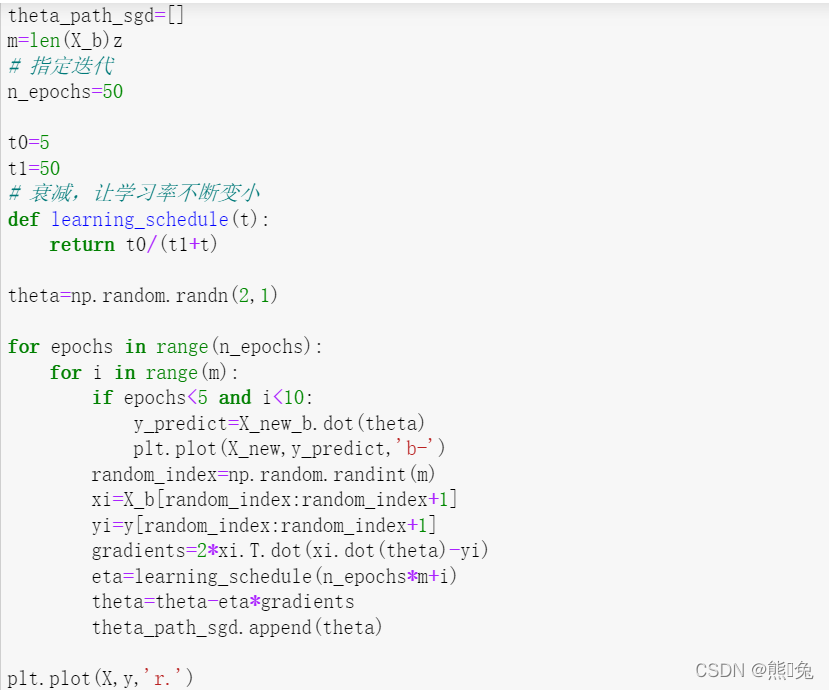
② 随机梯度下降:每一次找一个样本
代码实现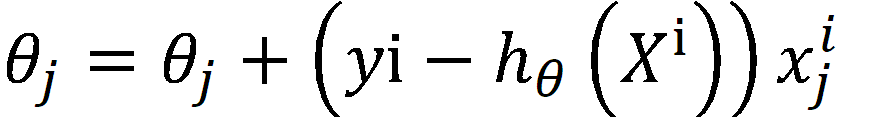
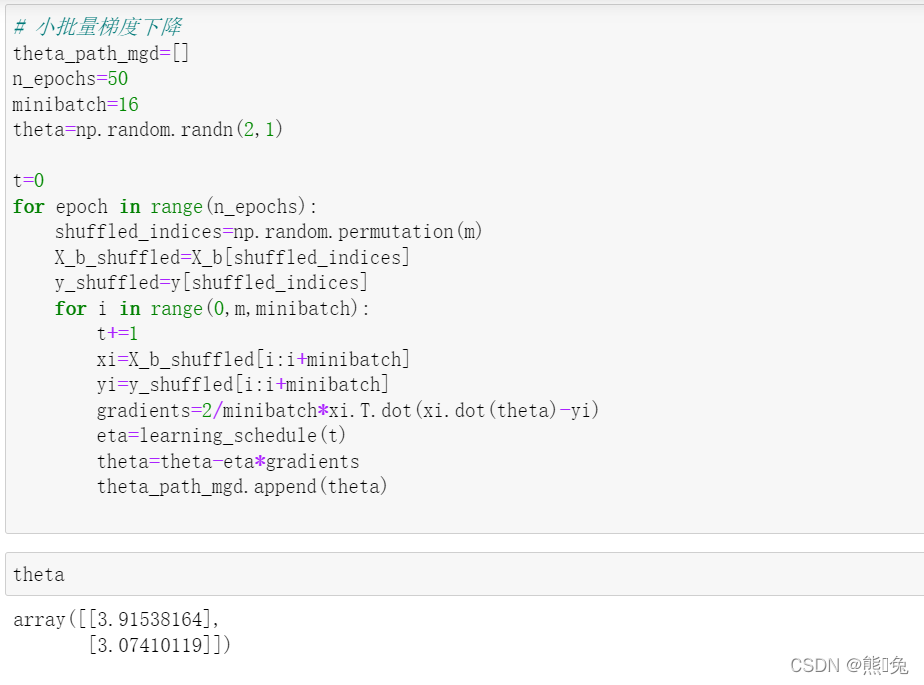
③ 小批量梯度下降: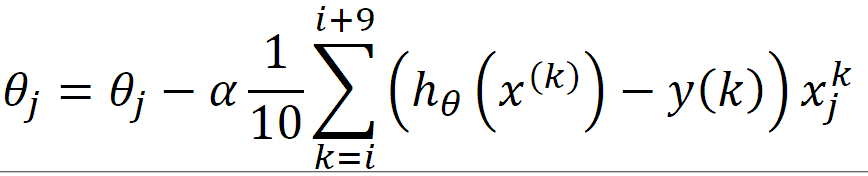
@表示学习率(步长),是 0 到 1 之间的值,是个超参数,需自己定义
代码实现
算法原理
在传统机器学习中,损失函数通常为凸函数,假设此时只有一个参数,则损失函数对参数的梯度即损失函数对参数的导数。如果刚开始参数初始在最优解的左边,很明显,这个时候损失函数对参数的导数是小于 0 的,而学习率是一个 0 到 1 之间的数,此时按照公式更新参数,初始的参数减去一个小于 0 的数是变大,也就是在坐标轴上往右走,即朝着最优解的方向走。同样的,如果参数初始在最优解的右边,此时按照公式更新,参数将会朝左走,即最优解的方向。所以,不管刚开始参数初始在何位置,按着梯度下降公式不断更新,参数都会朝着最优解的方向走。
算法流程
1、随机初始参数;
2、确定学习率;
3、求出损失函数对参数梯度;
4、按照公式更新参数;
5、重复 3 、 4 直到满足终止条件(如:损失函数或参数更新变化值小于某个阈值,或者训练次数达到设定阈值)。
import numpy as np
import warnings
warnings.filterwarnings("ignore")
def gradient_descent(initial_theta,eta=0.05,n_iters=1000,epslion=1e-8):
'''
梯度下降
:param initial_theta: 参数初始值,类型为float
:param eta: 学习率,类型为float
:param n_iters: 训练轮数,类型为int
:param epslion: 容忍误差范围,类型为float
:return: 训练后得到的参数
'''
theta = initial_theta
i_iter = 0
# 一直训练
while i_iter < n_iters:
# 实现损失函数
gradient = 2*(theta-3)
last_theta = theta
# 进行参数的更新
theta = theta - eta*gradient
# 若判断其误差程度是否小于所能容忍的误差度
if(abs(theta-last_theta)<epslion):
break
i_iter +=1
return theta
训练逻辑回归模型
通常,我们先将数据输入到模型,从而得到一个预测值,再将预测值与真实值结合,得到一个损失函数,最后用梯度下降的方法来优化损失函数,从而不断的更新模型的参数 θ ,最后得到一个能够正确对特征和标签进行分类的模型。
我们知道要使用梯度下降算法首先要知道损失函数对参数的梯度,即损失函数对每个参数的偏导(上面公式有涉及)

import numpy as np
import warnings
warnings.filterwarnings("ignore")
def sigmoid(x):
'''
sigmoid函数
:param x: 转换前的输入
:return: 转换后的概率
'''
return 1/(1+np.exp(-x))
def fit(x,y,eta=1e-3,n_iters=10000):
'''
训练逻辑回归模型
:param x: 训练集特征数据,类型为ndarray
:param y: 训练集标签,类型为ndarray
:param eta: 学习率,类型为float
:param n_iters: 训练轮数,类型为int
:return: 模型参数,类型为ndarray
'''
theta = np.zeros(x.shape[1])
i_iter = 0
while i_iter < n_iters:
gradient = (sigmoid(x.dot(theta))-y).dot(x)
theta = theta -eta*gradient
i_iter += 1
return theta
LogisticRegression()
LogisticRegression可以实现多分类。LogisticRegression的构造函数中有三个常用的参数可以设置:
solver:{‘newton-cg’ , ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, 分别为几种优化算法。默认为liblinear;
C:正则化系数的倒数,默认为 1.0 ,越小代表正则化越强;
max_iter:最大训练轮数,默认为 100 。
和sklearn中其他分类器一样,LogisticRegression类中的fit函数用于训练模型,实例化,fit函数有两个向量输入:
X:大小为 [样本数量,特征数量] 的ndarray,存放训练样本;
Y:值为整型,大小为 [样本数量] 的ndarray,存放训练样本的分类标签。
LogisticRegression类中的predict函数用于预测,返回预测标签,predict函数有一个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放预测样本。
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
def digit_predict(train_image, train_label, test_image):
'''
实现功能:训练模型并输出预测结果
:param train_sample: 包含多条训练样本的样本集,类型为ndarray,shape为[-1, 8, 8]
:param train_label: 包含多条训练样本标签的标签集,类型为ndarray
:param test_sample: 包含多条测试样本的测试集,类型为ndarry
:return: test_sample对应的预测标签
'''
# 训练集变形
flat_train_image = train_image.reshape((-1, 64))
# 训练集标准化
minmax=MinMaxScaler()
flat_train_image =minmax.fit_transform(flat_train_image)
# 测试集变形
flat_test_image = test_image.reshape((-1, 64))
# 测试集标准化
minmax=MinMaxScaler()
flat_test_image =minmax.fit_transform(flat_test_image)
# 训练--预测
rf = LogisticRegression(C=4.0)
rf.fit(flat_train_image, train_label)
return rf.predict(flat_test_image)

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









