







 本文详细介绍了使用粒子群算法(PSO)解决背包问题的过程,包括实验目的、任务、各种优化策略(如线性递减、非线性递减、自适应、随机和压缩因子法的惯性权重,以及非对称学习因子)的分析和伪代码。此外,还讨论了深度优先搜索、01规划和动态规划作为替代解决方案,并提供了实验总结,强调了算法的全局搜索与局部搜索平衡的重要性。
本文详细介绍了使用粒子群算法(PSO)解决背包问题的过程,包括实验目的、任务、各种优化策略(如线性递减、非线性递减、自适应、随机和压缩因子法的惯性权重,以及非对称学习因子)的分析和伪代码。此外,还讨论了深度优先搜索、01规划和动态规划作为替代解决方案,并提供了实验总结,强调了算法的全局搜索与局部搜索平衡的重要性。
文章目录
一、实验目的
1、掌握粒子群算法的基本思想及原理;
2、熟练运用Matlab或Python实现粒子群算法。
二、实验任务
以Matlab或Python为编程工具,利用粒子群算法求解例6.4背包问题。
三、实验过程(备注:包括问题分析、伪代码、程序代码和仿真结果)
1995年,美国学者Kennedy和Eberhart共同提出了粒子群算法,其基本思想源于对鸟类群体行为进行建模与仿真的研究结果的启发。
| 名称 | 含义 |
|---|---|
| 粒子 | 优化问题的候选解 |
| 位置 | 候选解所在的位置 |
| 速度 | 候选解移动的速度 |
| 适应度 | 评价粒子优劣的值,一般设置为目标函数值 |
| 个体最佳位置 | 单个粒子迄今为止找到的最佳位置 |
| 群体最佳位置 | 所有粒子迄今为止找到的最佳位置 |
它的核心思想是利用群体中的个体对信息的共享使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得问题的可行解。
粒子群算法的核心公式,
r
1
r_1
r1和
r
2
r_2
r2是[0,1]上的随机数:
υ
i
d
=
ω
υ
i
d
−
1
+
c
1
r
1
(
p
b
e
s
t
i
d
−
x
i
d
)
+
c
2
r
2
(
g
b
e
s
t
d
−
x
i
d
)
\upsilon _{i}^{d}=\omega \upsilon _{i}^{d-1}+c_1r_1\left( pbest_{i}^{d}-x_{i}^{d} \right) +c_2r_2\left( gbest^d-x_{i}^{d} \right)
υid=ωυid−1+c1r1(pbestid−xid)+c2r2(gbestd−xid)
x
i
d
+
1
=
x
i
d
+
v
i
d
x_{i}^{d+1}=x_{i}^{d}+v_{i}^{d}
xid+1=xid+vid
| 符号 | 含义 |
|---|---|
| n n n | 粒子个数 |
| c 1 c_1 c1 | 粒子的个体加速因子 |
| c 2 c_2 c2 | 粒子的社会加速因子 |
| ω \omega ω | 速度的惯性权重 |
| υ i d \upsilon _{i}^{d} υid | 第d次迭代时,第i个粒子的速度 |
| x i d x_{i}^{d} xid | 第d次迭代时,第i个粒子所在的位置 |
| f ( x ) f\left(x\right) f(x) | 在位置x时的适应度值 |
| p b e s t i d pbest_{i}^{d} pbestid | 到第d次迭代为止,第i个粒子经过的最好的位置 |
| g b e s t d gbest^d gbestd | 到第d次迭代为止,所有粒子经过的最好的位置 |
3.1 问题分析
有N件物品和一个容量为V的背包。第件物品的体积是 c i c_i ci ,价值是 w i w_i wi 。求解将哪些物品放入背包可使物品的体积总和不超过背包的容量,且价值总和最大。假设物品数量为10,背包的容量为300。每件物品的体积为[95,75,23,73,50,22,6,57,89,98],价值为[89,59,19,43,100,72,44,16,7,64]。
离散粒子群算法:基本的粒子群算法是在连续域中搜索函数极值的有力工具。继基本粒子群算法之后,Kennedy和Eberhart又提出了一种离散二进制版的粒子群算法。在此离散粒子群方法中,将离散问题空间映射到连续粒子运动空间,并适当修改粒子群算法来求解,在计算上仍保留经典粒子群算法速度-位置更新运算规则。粒子在状态空间的取值和变化只限于0和1两个值,而速度的每一维
ν
i
j
\nu_{ij}
νij代表位置每一位
x
i
j
x_{ij}
xij取值为1的可能性。因此,在连续粒子群中的
ν
i
j
\nu_{ij}
νij更新公式依然保持不变,但是
p
b
e
s
t
i
d
pbest_{i}^{d}
pbestid和
g
b
e
s
t
d
gbest^d
gbestd只在[0,1]内取值。其位置更新等式表示如下:
x
i
j
=
{
1
r
a
n
d
<
1
/
[
1
+
exp
(
−
v
i
j
)
]
0
其他
x_{ij}=\begin{cases} 1& rand<1/\left[ 1+\exp \left( -v_{ij} \right) \right]\\ 0& \text{其他}\\\end{cases}
xij={10rand<1/[1+exp(−vij)]其他式中,
r
a
n
d
rand
rand是从[0,1]中产生的随机数
3.1.1 线性递减惯性权重
惯性权重 ω \omega ω体现的是粒子继承先前的速度的能力,一个较大的惯性权重有利于全局搜索,而一个较小的权重则更利于局部搜索。为了更好地平衡算法的全局搜索以及局部搜索能力,可以使用线性递减惯性权重LDIW(Linear Decreasing Inertia Weight),公式如下: ω d = ω s t a r t − ( ω s t a r t − ω e n d ) × d K \omega ^d=\omega _{start}-\left( \omega _{start}-\omega _{end} \right) \times \frac{d}{K} ωd=ωstart−(ωstart−ωend)×Kd其中 d d d是当前迭代的次数, K K K是迭代总次数, ω s t a r t \omega_{start} ωstart一般取0.9, ω e n d \omega_{end} ωend一般取0.4,与原来的相比,现在惯性权重与迭代次数有关。
3.1.2 非线性递减惯性权重
ω d = ω s t a r t − ( ω s t a r t − ω e n d ) × ( d K ) 2 \omega ^d=\omega _{start}-\left( \omega _{start}-\omega _{end} \right) \times \left( \frac{d}{K} \right) ^2 ωd=ωstart−(ωstart−ωend)×(Kd)2 ω d = ω s t a r t − ( ω s t a r t − ω e n d ) × [ 2 d K − ( d K ) 2 ] \omega ^d=\omega _{start}-\left( \omega _{start}-\omega _{end} \right) \times \left[ \frac{2d}{K}-\left( \frac{d}{K} \right) ^2 \right] ωd=ωstart−(ωstart−ωend)×[K2d−(Kd)2]
3.1.3 自适应惯性权重
ω
i
d
=
{
ω
min
+
(
w
max
−
ω
min
)
f
max
d
−
f
(
x
i
d
)
f
max
d
−
f
a
v
e
r
a
g
e
d
f
(
x
i
d
)
⩾
f
a
v
e
r
a
g
e
d
ω
max
f
(
x
i
d
)
<
f
a
v
e
r
a
g
e
d
\omega _{i}^{d}=\begin{cases} \omega _{\min}+\left( w_{\max}-\omega _{\min} \right) \frac{f_{\max}^{d}-f\left( x_{i}^{d} \right)}{f_{\max}^{d}-f_{average}^{d}}& f\left( x_{i}^{d} \right) \geqslant f_{average}^{d}\\ \omega _{\max}& f\left( x_{i}^{d} \right) <f_{average}^{d}\\\end{cases}
ωid=⎩
⎨
⎧ωmin+(wmax−ωmin)fmaxd−faveragedfmaxd−f(xid)ωmaxf(xid)⩾faveragedf(xid)<faveraged其中:
(1)
ω
min
\omega _{\min}
ωmin和
ω
max
\omega _{\max}
ωmax是预先给定的最小和最大惯性系数,一般取0.4和0.9
(2)
f
a
v
e
r
a
g
e
d
=
∑
i
=
1
n
f
(
x
i
d
)
/
n
f_{average}^{d}=\sum_{i=1}^n{f\left( x_{i}^{d} \right)}/n
faveraged=∑i=1nf(xid)/n,即第
d
d
d次迭代时所有粒子的平均适应度
(3)
f
max
d
=
max
{
f
(
x
1
d
)
,
.
.
.
,
f
(
x
n
d
)
}
f_{\max}^{d}=\max \left\{ f\left( x_{1}^{d} \right) ,...,f\left( x_{n}^{d} \right) \right\}
fmaxd=max{f(x1d),...,f(xnd)},即第
d
d
d次迭代所有粒子的最大适应度
3.1.4 随机惯性权重
使用随机的惯性权重可以避免在迭代前期局部搜索能力的不足,也可以避免在迭代后期全局搜索能力的不足。 ω = ω min + ( ω max − ω min ) × r a n d ( ) + σ × r a n d n ( ) \omega =\omega _{\min}+\left( \omega _{\max}-\omega _{\min} \right) \times rand\left( \right) +\sigma \times randn\left( \right) ω=ωmin+(ωmax−ωmin)×rand()+σ×randn() r a n d ( ) rand\left(\right) rand()为[0,1]均匀分布随机数, r a n d n ( ) randn\left( \right) randn()为正态分布的随机数, σ \sigma σ用来度量随机变量权重 ω \omega ω预期数学期望之间的偏离程度,一般取0.2~0.5之间的一个数,该项是为了控制取值中的权重误差,使权重 ω \omega ω有利于向期望方向进化,这样做的依据是正常情况下实验误差服从正态分布。
3.1.5 压缩因子法
个体学习因子
c
1
c_1
c1和社会学习因子
c
2
c_2
c2决定了粒子本身经验信息和其他粒子的经验信息对粒子运行轨迹的影响,其反映了粒子群之间的信息交流。设置
c
1
c_1
c1较大的值,会使粒子过多地在自身的局部范围内搜索,而较大的
c
2
c_2
c2的值,则又会促使粒子过早收敛到局部最优值。
为了有效地控制粒子的飞行速度,使算法达到全局搜索与局部搜索两者间的有效平衡,可采用压缩因子,这种调整方法通过合适选择参数,可以确保PSO算法的收敛性,并可取消对速度的边界限制。压缩因子法中应用较多的个体学习因子
c
1
c_1
c1和社会学习因子
c
2
c_2
c2均取2.05,用符号可以表示为:收缩因子
Φ
=
2
∣
2
−
C
−
C
2
−
4
C
∣
\varPhi =\frac{2}{|2-C-\sqrt{C^2-4C}|}
Φ=∣2−C−C2−4C∣2,其中
C
=
c
1
+
c
2
=
4.1
C=c_1+c_2=4.1
C=c1+c2=4.1,惯性权重
ω
=
0.9
\omega =0.9
ω=0.9,速度更新公式改为:
υ
i
d
=
Φ
×
[
ω
υ
i
d
−
1
+
c
1
r
1
(
p
b
e
s
t
i
d
−
x
i
d
)
+
c
2
r
2
(
g
b
e
s
t
d
−
x
i
d
)
]
\upsilon _{i}^{d}=\varPhi \times \left[ \omega \upsilon _{i}^{d-1}+c_1r_1\left( pbest_{i}^{d}-x_{i}^{d} \right) +c_2r_2\left( gbest^d-x_{i}^{d} \right) \right]
υid=Φ×[ωυid−1+c1r1(pbestid−xid)+c2r2(gbestd−xid)]
3.1.6 非对称学习因子
在经典PSO算法中,由于在寻优后期粒子缺乏多样性,易过早收敛于局部极值,因此通过调节学习因子,在搜索初期使粒子进行大范围搜索,以期获得具有更好多样性的高质量粒子,尽可能摆脱局部极值的干扰。
学习因子 c 1 c_1 c1和 c 2 c_2 c2决定粒子个体经验信息和其他粒子经验信息对寻优轨迹的影响,反映了粒子之间的信息交换。设置较大的 c 1 c_1 c1值,会使粒子过多的在局部搜索;反之,较大的 c 2 c_2 c2值会使粒子过早收敛到局部最优值。因此,在算法搜索初期采用较大的 c 1 c_1 c1值和较小的 c 2 c_2 c2值,使粒子尽量发散到搜索空间即强调“个体独立意识”,而较少受到种群内其他粒子即“社会意识部分”的影响,以增加群内粒子的多样性。随着迭代次数的增加,使 c 1 c_1 c1线性递减, c 2 c_2 c2线性递增,从面加强了粒子向全局最优点的收敛能力。 c 1 = c 1 max − ( c 1 max − c 1 min ) × d K c_1=c_{1\max}-\left( c_{1\max}-c_{1\min} \right) \times \frac{d}{K} c1=c1max−(c1max−c1min)×Kd c 2 = c 2 min + ( c 2 max − c 2 min ) × d K c_2=c_{2\min}+\left( c_{2\max}-c_{2\min} \right) \times \frac{d}{K} c2=c2min+(c2max−c2min)×Kd c 1 max c_{1\max} c1max通常取2.5, c 1 min c_{1\min} c1min通常取0.5, c 2 min c_{2\min} c2min通常取1.0, c 2 max c_{2\max} c2max通常取2.25。
3.2 伪代码

3.3 代码程序
clear; clc
Volume = [95,75,23,73,50,22,6,57,89,98]; % 物体体积
V = 300; % 背包体积
Value = [89,59,19,43,100,72,44,16,7,64]; % 物品价值
afa = 2; % 惩罚函数系数
M = 10; % 物品数量
gbest = zeros(50,6);
for x = 1 : 50
N = 50; % 种群数量
D = M; % 粒子维度
T = 50; % 最大迭代次数
Vmax = 10; % 速度最大值
Vmin = -10; % 速度最小值
% 1.2.3.4.惯性权重
Wmax = 0.9; % 惯性权重最大值
Wmin = 0.4; % 惯性权重最小值
w = (Wmax + Wmin) / 2; % 5.6.惯性权重
c1 = 1.5; % 个体学习因子
c2 = 1.5; % 社会学习因子
c15 = 2.05;c25 = 2.05; % 5.压缩学习因子
c1max = 2.5; c1min = 0.5; % 6.非对称学习因子
c2min = 1.0; c2max = 2.25;
% 初始化粒子
x1 = randi([0,1], N, D);v1 = rand(N, D) * (Vmax-Vmin) + Vmin;
x2 = randi([0,1], N, D);v2 = rand(N, D) * (Vmax-Vmin) + Vmin;
x3 = randi([0,1], N, D);v3 = rand(N, D) * (Vmax-Vmin) + Vmin;
x4 = randi([0,1], N, D);v4 = rand(N, D) * (Vmax-Vmin) + Vmin;
x5 = randi([0,1], N, D);v5 = rand(N, D) * (Vmax-Vmin) + Vmin;
x6 = randi([0,1], N, D);v6 = rand(N, D) * (Vmax-Vmin) + Vmin;
% 初始化个体最优位置和最优值
p1=x1; p2=x2; p3=x3; p4=x4; p5=x5; p6=x6; % 最优位置
pbest1 = ones(N, 1); pbest2 = ones(N, 1); % 最优值
pbest3 = ones(N, 1); pbest4 = ones(N, 1); % 最优值
pbest5 = ones(N, 1); pbest6 = ones(N, 1); % 最优值
for i = 1 : N
pbest1(i) = func4(x1(i,:), Volume, Value, V, afa);
pbest2(i) = func4(x2(i,:), Volume, Value, V, afa);
pbest3(i) = func4(x3(i,:), Volume, Value, V, afa);
pbest4(i) = func4(x4(i,:), Volume, Value, V, afa);
pbest5(i) = func4(x5(i,:), Volume, Value, V, afa);
pbest6(i) = func4(x6(i,:), Volume, Value, V, afa);
end
% 初始化全局最优位置和最优值
g1 = ones(1,D); g2 = ones(1,D);g3 = ones(1,D); % 全局最优位置
g4 = ones(1,D); g5 = ones(1,D); g6 = ones(1,D); % 全局最优位置
gbest1 = 0; gbest2 = 0; gbest3 = 0; % 最优值
gbest4 = 0; gbest5 = 0; gbest6 = 0; % 最优值
for i = 1 : N
if pbest1(i) > gbest1
g1 = p1(i,:);gbest1 = pbest1(i);
end
if pbest2(i) > gbest2
g2 = p2(i,:);gbest2 = pbest2(i);
end
if pbest3(i) > gbest3
g3 = p3(i,:);gbest3 = pbest3(i);
end
if pbest4(i) > gbest4
g4 = p4(i,:);gbest4 = pbest4(i);
end
if pbest5(i) > gbest5
g5 = p5(i,:);gbest5 = pbest5(i);
end
if pbest6(i) > gbest6
g6 = p6(i,:);gbest6 = pbest6(i);
end
end
gb1 = ones(1,T); gb2 = ones(1,T); % 存储每一代的最优值
gb3 = ones(1,T); gb4 = ones(1,T); % 存储每一代的最优值
gb5 = ones(1,T); gb6 = ones(1,T); % 存储每一代的最优值
%% 开始迭代
for i = 1 : T % 每一代
% 计算动态惯性权重值
w1 = Wmax - (Wmax-Wmin)* i / T; % 1.线性递减惯性权重
w2 = Wmax - (Wmax-Wmin)*(i/T)^2; % 2.非线性递减惯性权重
% w2 = Wmax - (Wmax-Wmin)* (2*i/T - (i/T)^2);
average = sum(pbest3) / N; % 种群平均值
% 4.随机惯性权重
w4 = Wmin + (Wmax-Wmin) * rand + 0.35 * randn;
% 5.压缩因子法
v = 2 / abs(2 - 4.1 - (4.1^2 - 4*4.1)^0.5);
% 6.非对称学习因子
c16 = c1max - (c1max-c1min) * i / T;
c26 = c2min + (c2max-c2min) * i / T;
for j = 1 : N % 每一个个体
if pbest3(j) < average % 3.自适应惯性权重
w3 = Wmax;
else
w3 = Wmin+(Wmax-Wmin)*(gbest3-pbest3(j))/(gbest3-average);
end
% 1.2.更新位置和速度
v1(j,:)=w1*v1(j,:)+c1*rand*(p1(j,:)-x1(j,:))+c2*rand*(g1-x1(j,:));
v2(j,:)=w2*v2(j,:)+c1*rand*(p2(j,:)-x2(j,:))+c2*rand*(g2-x2(j,:));
% 3.4.更新位置和速度
v3(j,:)=w3*v3(j,:)+c1*rand*(p3(j,:)-x3(j,:))+c2*rand*(g3-x3(j,:));
v4(j,:)=w4*v4(j,:)+c1*rand*(p4(j,:)-x4(j,:))+c2*rand*(g4-x4(j,:));
v5(j,:)=v*w*v5(j,:)+c15*rand*(p5(j,:)-x5(j,:))+c25*rand*(g5-x5(j,:));
v6(j,:)=w*v6(j,:)+c16*rand*(p6(j,:)-x6(j,:))+c26*rand*(g6-x6(j,:));
% 边界条件处理
for ii = 1 : D
if v1(j,ii) > Vmax || v1(j,ii) < Vmin
v1(j,ii) = rand * (Vmax-Vmin) + Vmin;
end
if v2(j,ii) > Vmax || v2(j,ii) < Vmin
v2(j,ii) = rand * (Vmax-Vmin) + Vmin;
end
if v3(j,ii) > Vmax || v3(j,ii) < Vmin
v3(j,ii) = rand * (Vmax-Vmin) + Vmin;
end
if v4(j,ii) > Vmax || v4(j,ii) < Vmin
v4(j,ii) = rand * (Vmax-Vmin) + Vmin;
end
if v5(j,ii) > Vmax || v5(j,ii) < Vmin
v5(j,ii) = rand * (Vmax-Vmin) + Vmin;
end
if v6(j,ii) > Vmax || v6(j,ii) < Vmin
v6(j,ii) = rand * (Vmax-Vmin) + Vmin;
end
end
% 位置
vx1 = 1 ./ (1 + exp(-v1(j,:))); vx2 = 1 ./ (1 + exp(-v2(j,:)));
vx3 = 1 ./ (1 + exp(-v3(j,:))); vx4 = 1 ./ (1 + exp(-v4(j,:)));
vx5 = 1 ./ (1 + exp(-v5(j,:))); vx6 = 1 ./ (1 + exp(-v6(j,:)));
for jj = 1 : D
if vx1(jj) > rand
x1(j,jj) = 1;
else
x1(j,jj) = 0;
end
if vx2(jj) > rand
x2(j,jj) = 1;
else
x2(j,jj) = 0;
end
if vx3(jj) > rand
x3(j,jj) = 1;
else
x3(jj) = 0;
end
if vx4(jj) > rand
x4(j,jj) = 1;
else
x4(j,jj) = 0;
end
if vx5(jj) > rand
x5(j,jj) = 1;
else
x5(j,jj) = 0;
end
if vx6(jj) > rand
x6(j,jj) = 1;
else
x6(j,jj) = 0;
end
end
% 1.更新个体最优位置和最优值
value1 = func4(x1(j,:),Volume,Value,Vmax,afa);
if value1 > pbest1(j)
p1(j,:) = x1(j,:); pbest1(j) = value1;
end
% 2.更新个体最优位置和最优值
value2 = func4(x2(j,:),Volume,Value,Vmax,afa);
if value2 > pbest2(j)
p2(j,:) = x2(j,:);pbest2(j) = value2;
end
% 3.更新个体最优位置和最优值
value3 = func4(x3(j,:),Volume,Value,Vmax,afa);
if value3 > pbest3(j)
p3(j,:) = x3(j,:);pbest3(j) = value3;
end
% 4.更新个体最优位置和最优值
value4 = func4(x4(j,:),Volume,Value,Vmax,afa);
if value4 > pbest4(j)
p4(j,:) = x4(j,:);pbest4(j) = value4;
end
% 5.更新个体最优位置和最优值
value5 = func4(x5(j,:),Volume,Value,Vmax,afa);
if value5 > pbest5(j)
p5(j,:) = x5(j,:);pbest5(j) = value5;
end
% 6.更新个体最优位置和最优值
value6 = func4(x6(j,:),Volume,Value,Vmax,afa);
if value6 > pbest6(j)
p6(j,:) = x6(j,:);pbest6(j) = value6;
end
% 更新全局最优位置和最优值
if pbest1(j) > gbest1
g1 = p1(j,:);gbest1 = pbest1(j);
end
if pbest2(j) > gbest2
g2 = p2(j,:);gbest2 = pbest2(j);
end
if pbest3(j) > gbest3
g3 = p3(j,:);gbest3 = pbest3(j);
end
if pbest4(j) > gbest4
g4 = p4(j,:);gbest4 = pbest4(j);
end
if pbest5(j) > gbest5
g5 = p5(j,:);gbest5 = pbest5(j);
end
if pbest6(j) > gbest6
g6 = p6(j,:);gbest6 = pbest6(j);
end
end
% 记录每一代的全局最优解
gb1(i) = gbest1;gb2(i) = gbest2;gb3(i) = gbest3;
gb4(i) = gbest4;gb5(i) = gbest5;gb6(i) = gbest6;
end
gbest(x,1) = gbest1;gbest(x,2) = gbest2;gbest(x,3) = gbest3;
gbest(x,4) = gbest4;gbest(x,5) = gbest5;gbest(x,6) = gbest6;
end
% 绘制结果
h = stackedplot(gbest);
h.DisplayLabels = {'线性递减','非线性递减','自适应','随机','压缩','非对称'};
h.LineWidth = 2;
h.XLabel = {'Generation'};
3.4 仿真结果
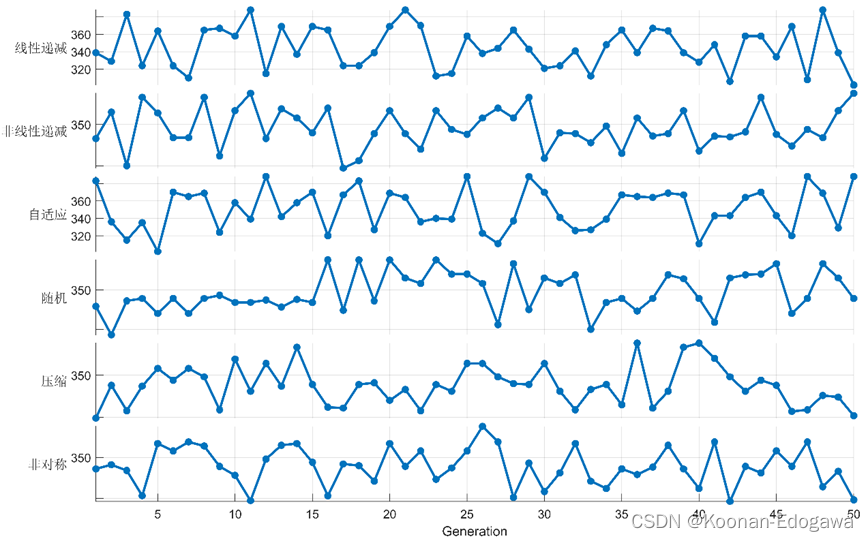
种群数量为50,迭代次数为50,六种方法重复50次,每次的最优如下图所示,并不是每次都可以取得到最大值。
四、实验总结(包括实验过程中出现的问题、新的理解、实验心得体会等)
4.1 问题
从粒子群算法来看,其更像是一种“特殊”的枚举算法,其通过独特的方式优化枚举过程,当种群数量和迭代次数很大时,结果越接近最优值。在本题中,迭代次数和种群数量不是很大时,最终结果并不是总能达到最大值,同时题目中只有10个物品,在不排除超重的情况取法有1024种,但整个种群总共有2500个样本,但仍然可能未取得极值,可见粒子群算法的局限性。
4.1.1 深度优先搜索
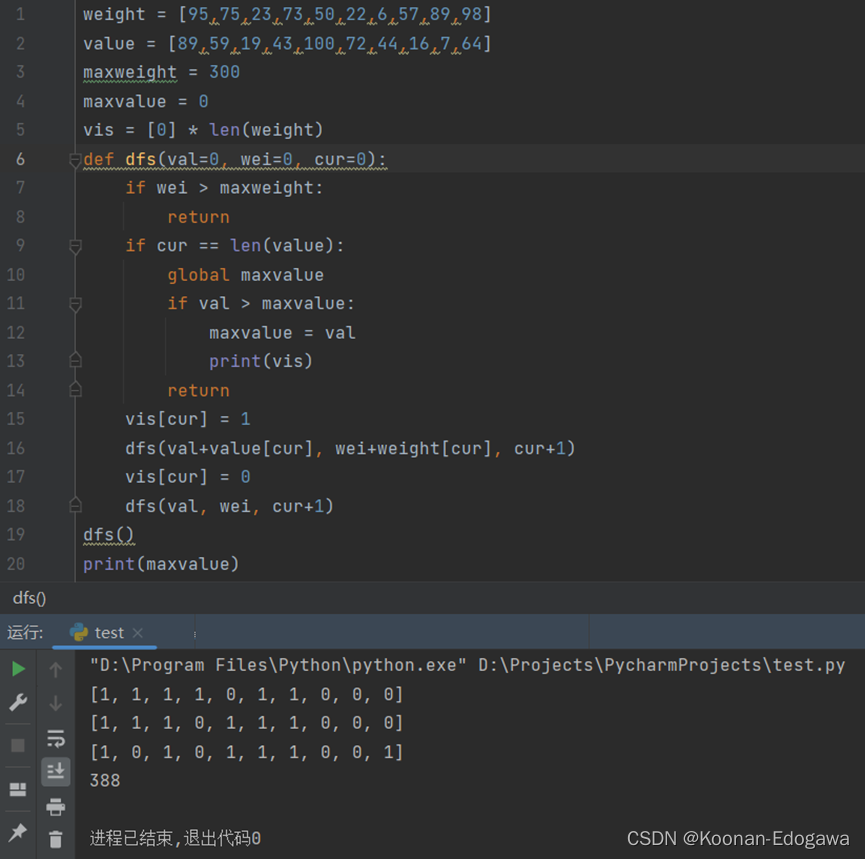
从题目来看,本题可以使用深度优先搜索算法求解,同时通过剪枝的操作,降低算法的时间复杂度,其求解过程如下图所示,最终收益为388,10件物品的选取情况为[1,0,1,0,1,1,1,0,0,1]。当时整体上看模型仍是O(2^n)的算法,当物品数量过大时,运算时间将十分漫长。
4.1.2 01规划
设物体的质量为 W = ( w 1 , w 2 , . . . , w n ) W=\left( w_1,w_2,...,w_n \right) W=(w1,w2,...,wn),物品的价值为 V = ( v 1 , v 2 , . . . , v n ) V=\left( v_1,v_2,...,v_n \right) V=(v1,v2,...,vn),背包最大重量为 W max W_{\max} Wmax,规划模型如下所示,可通过intlinprog函数求解。 max ∑ i = 1 n v i x i { ∑ i = 1 n w i x i ⩽ W max x i ∈ { 0 , 1 } i = 1 , . . . , n \max \sum_{i=1}^n{v_ix_i}\\\begin{cases} \sum_{i=1}^n{w_ix_i}\leqslant W_{\max}\\ x_i\in \left\{ 0,1 \right\} \,\,i=1,...,n\\\end{cases} maxi=1∑nvixi{∑i=1nwixi⩽Wmaxxi∈{0,1}i=1,...,n
4.1.3 动态规划
记dp[i][j]表示体积为j的背包,对于前i个物体能获得的最大收益,对第i个物体,不放时dp[i][j] = dp[i-1][j],放时dp[i][j] = dp[i-1][j-w[i]] + v[i],故状态转移方程为dp[i][j] = max(dp[i-1][j], dp[i-1][j-w[i]] + v[i])。为进一步优化空间复杂度,模型状态转移方程可以优化为dp[j] = max(dp[j], dp[j-w[i]] + v[i])。
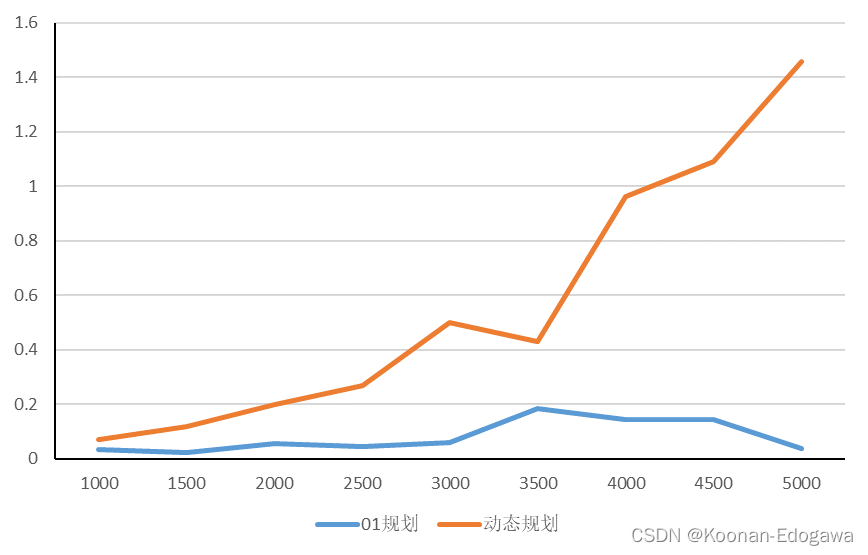
将01规划和动态规划算法在相同物品数量的情况下,以20次不同取值的所用时间平均值为观测值,绘制如下图形,结果显示,01规划的时间复杂度更低,这可能与其内部实现的有关。
time = zeros(9, 3);
for ii = 1 : 9
M = 500 + 500 * ii; % 物体数量
time(ii,1) = M;
intcon = 1 : M;
lb = zeros(M,1);
ub = ones(M,1);
time1 = zeros(20,2);
for jj = 1 : 20
weight = randi([1,100],1,M);
value = randi([1,100],1,M);
maxweight = round(sum(weight)*rand);
tic;
[x,fval] = intlinprog(-value,intcon,weight,maxweight,[],[],lb,ub);
t1 = toc;
time1(jj,1) = t1;
dp = zeros(maxweight,1);
tic
for i = 1 : M
for j = maxweight : -1 : weight(i)+1
dp(j) = max(dp(j), dp(j-weight(i)) + value(i));
end
end
t2 = toc;
time1(jj,2) = t2;
end
time(ii,2) = sum(time1(:,1))/20;
time(ii,3) = sum(time1(:,2))/20;
end
4.2 理解
粒子群算法被提出的灵感来源于鸟群觅食,鸟群觅食过程中,每只鸟沿着各个方向飞行去寻找食物,每只鸟儿都能记住到目前为止自己在飞行过程中最接近食物的位置,同时每只鸟儿之间也有信息共享,它们会比较到目前为止各自与食物之间的最近距离,从各自的最近距离中,选择并记忆整体的一个最近距离位置。由于每只鸟儿都是随机往各个方向飞行的,各自的最近距离位置与整体最近距离位置不断被更新,也即它们记忆中的最近位置越来越接近食物,当它们飞行到达的位置足够多之后,它们记忆的整体最近位置也就达到了食物的位置。总体上来看,粒子群算法也就是一种“特殊”的枚举算法,当种群数量足够多,种群迭代次数足够长时,往往能找到最优解,但二者不满足时,可能陷入局部极值。
4.3 心得体会
(1)粒子群算法是基于群智能理论的优化算法,通过群体中粒子间的合作与竞争产生的群体智能指导优化搜索。与其他算法相比,粒子群算法是一种高效的并行搜索算法。
(2)粒子群算法与遗传算法都是随机初始化种群,使用适应值来评价个体的优劣程度和进行一定的随机搜索。但粒子群算法根据自己的速度来决定搜索,没有遗传算法的交叉与变异。与进化算法相比,粒子群算法保留了基于种群的全局搜索策略,但是其采用的速度-位移模型操作简单,避免了复杂的遗传操作。
(3)由于每个粒子在算法结束时仍保持其个体极值,即粒子群算法除了可以找到问题的最优解外,还会得到若干较好的次优解,因此将粒子群算法用于调度和决策问题可以给出多种有意义的方案。
(4)粒子群算法特有的记忆使其可以动态地跟踪当前搜索情况并调整其搜索策略。另外,粒子群算法对种群的大小不敏感,即使种群数目下降时,性能下降也不是很大。


















 4344
4344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











