







听课(李宏毅老师的)笔记,方便梳理框架,以作复习之用。本节课主要讲了优化失败的原因,batch大小对训练的影响,使用Momentum方法来解决梯度下降时无法逃离critical point的现象
1. 优化失败的原因
主要有两个
- local minima
- saddle point
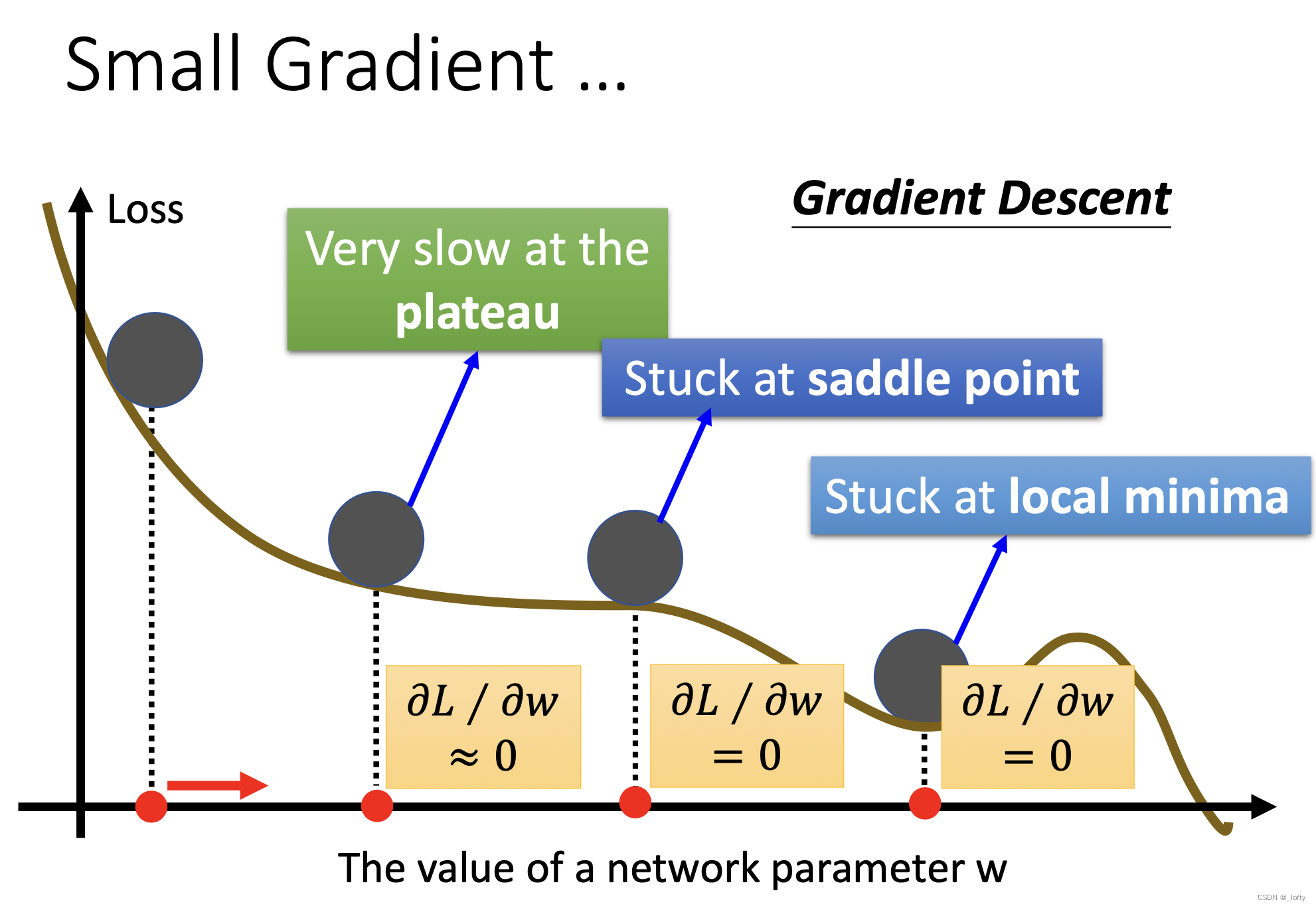
大家在学习时通常会忽略第二个,而直接说是因为遇到了local minima,实际上这是很不严谨的。应该统称为critical point,当gradient 为0时,不仅仅可能是local minima,还有可能是saddle point
theta’是一个critical point
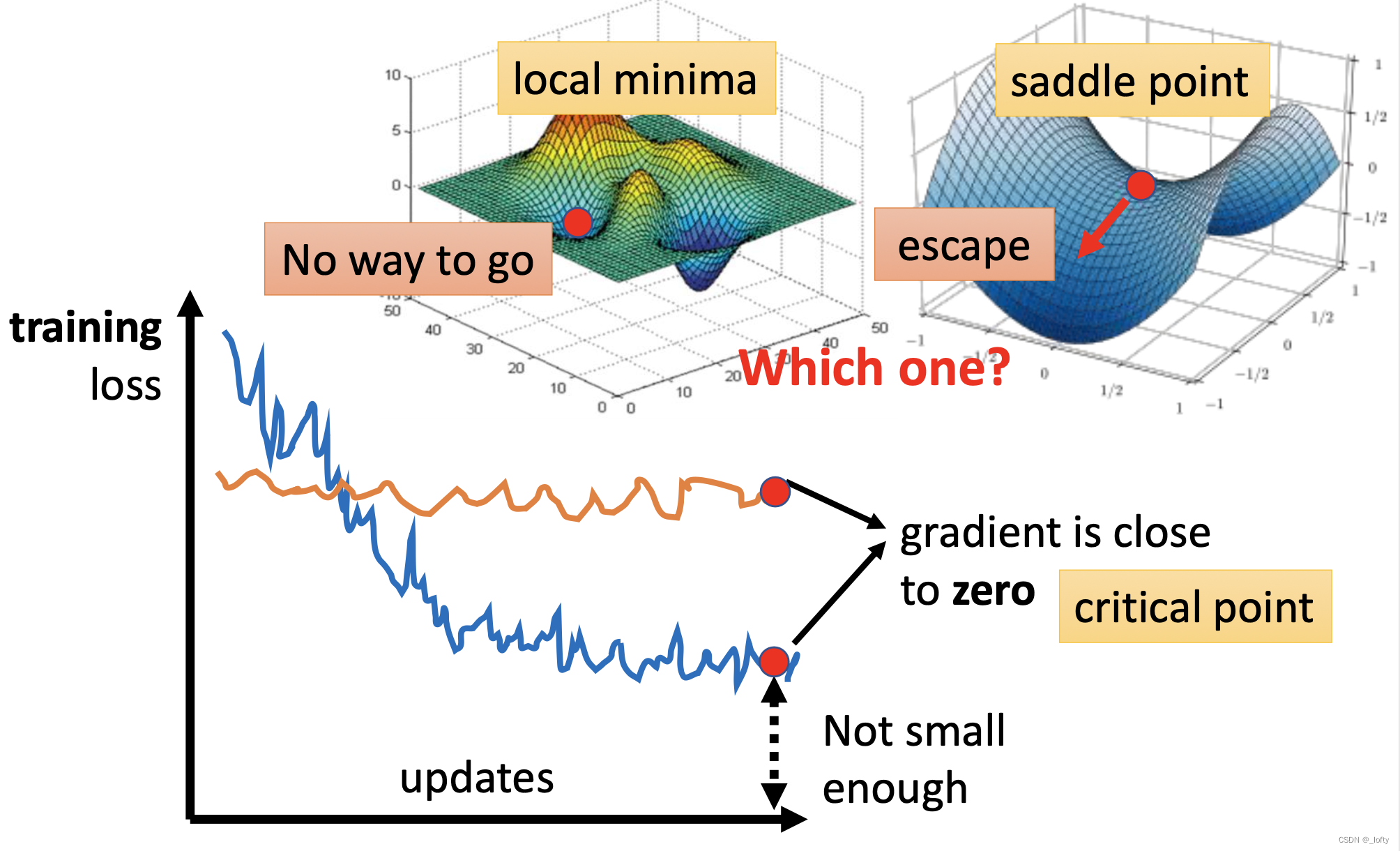
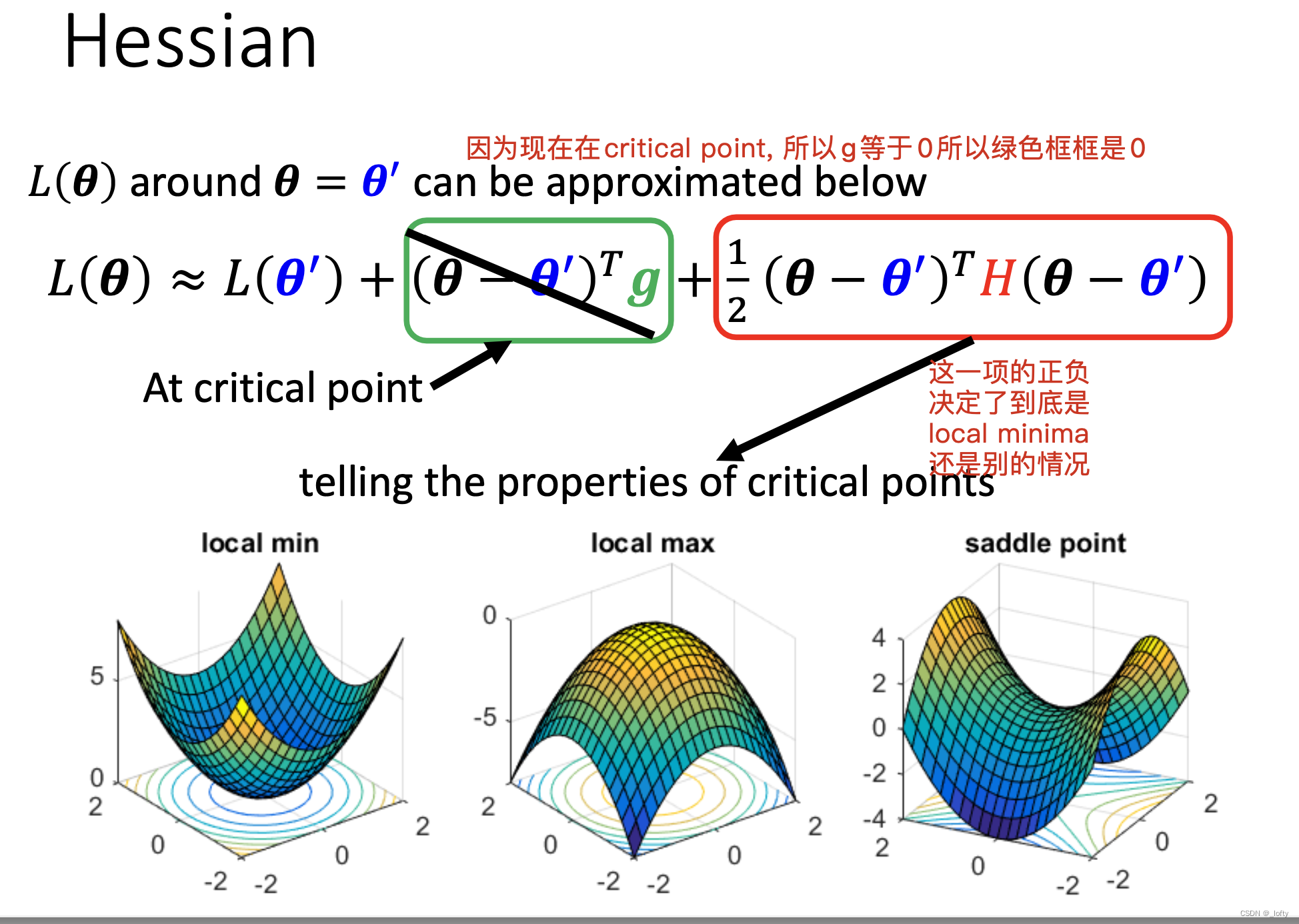
2. 如何分辨是local minima还是saddle point?
这部分涉及到数学的证明和推理,看不懂也没关系,反正在实际应用中也不用这个算……


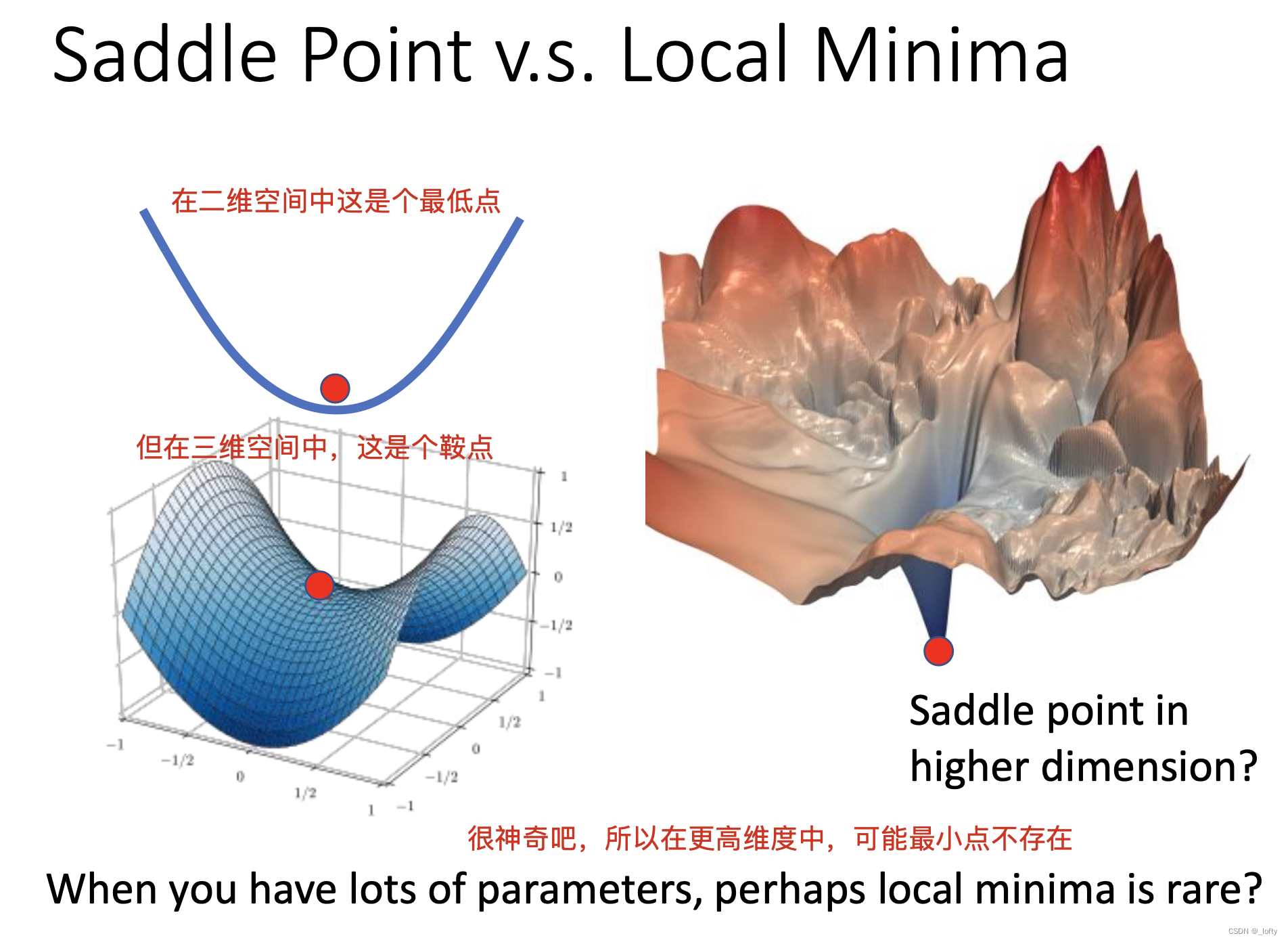
3. 看起来存在的local minima在更高维度不一定存在
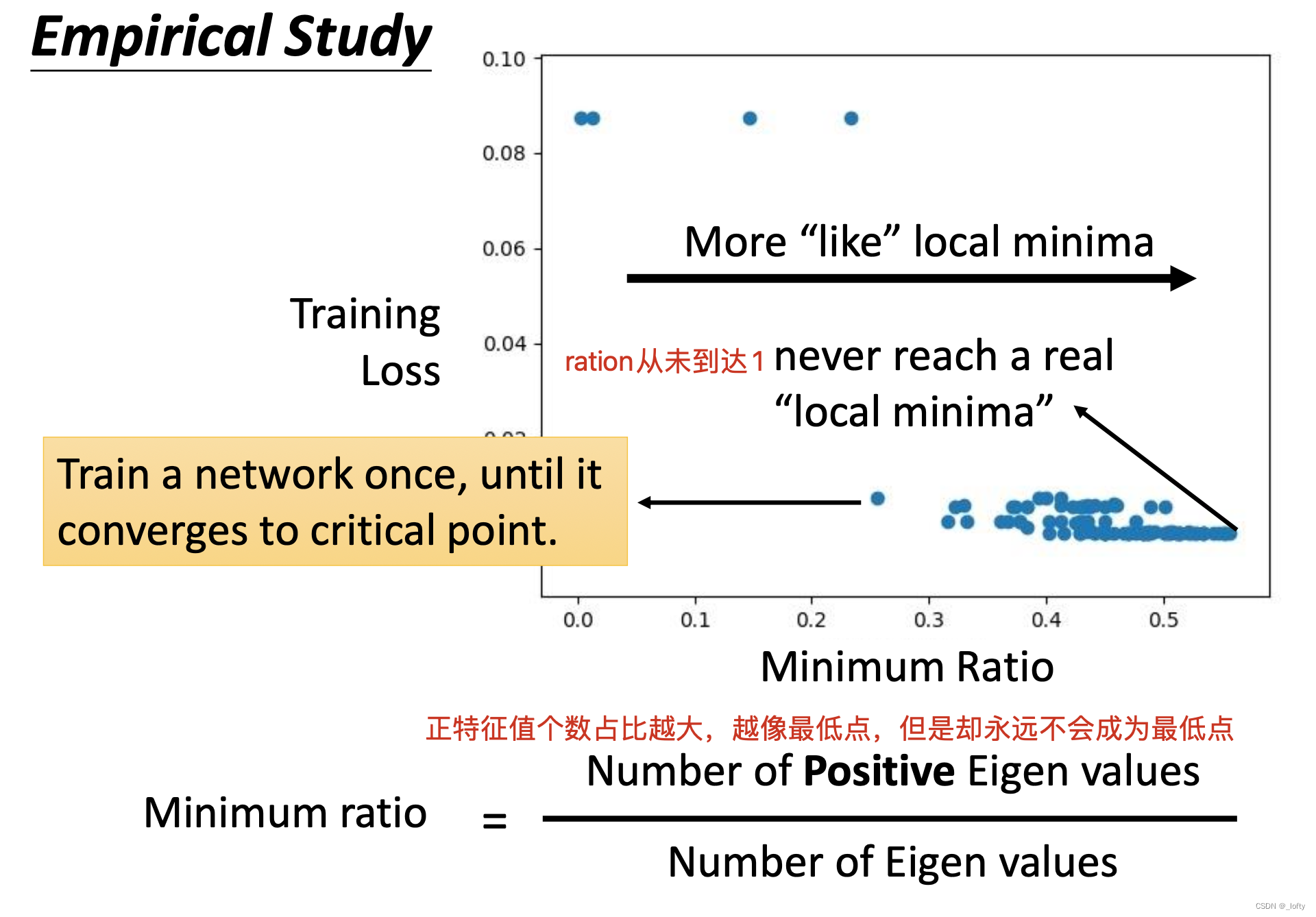
小结
4. Batch size对训练有影响吗?
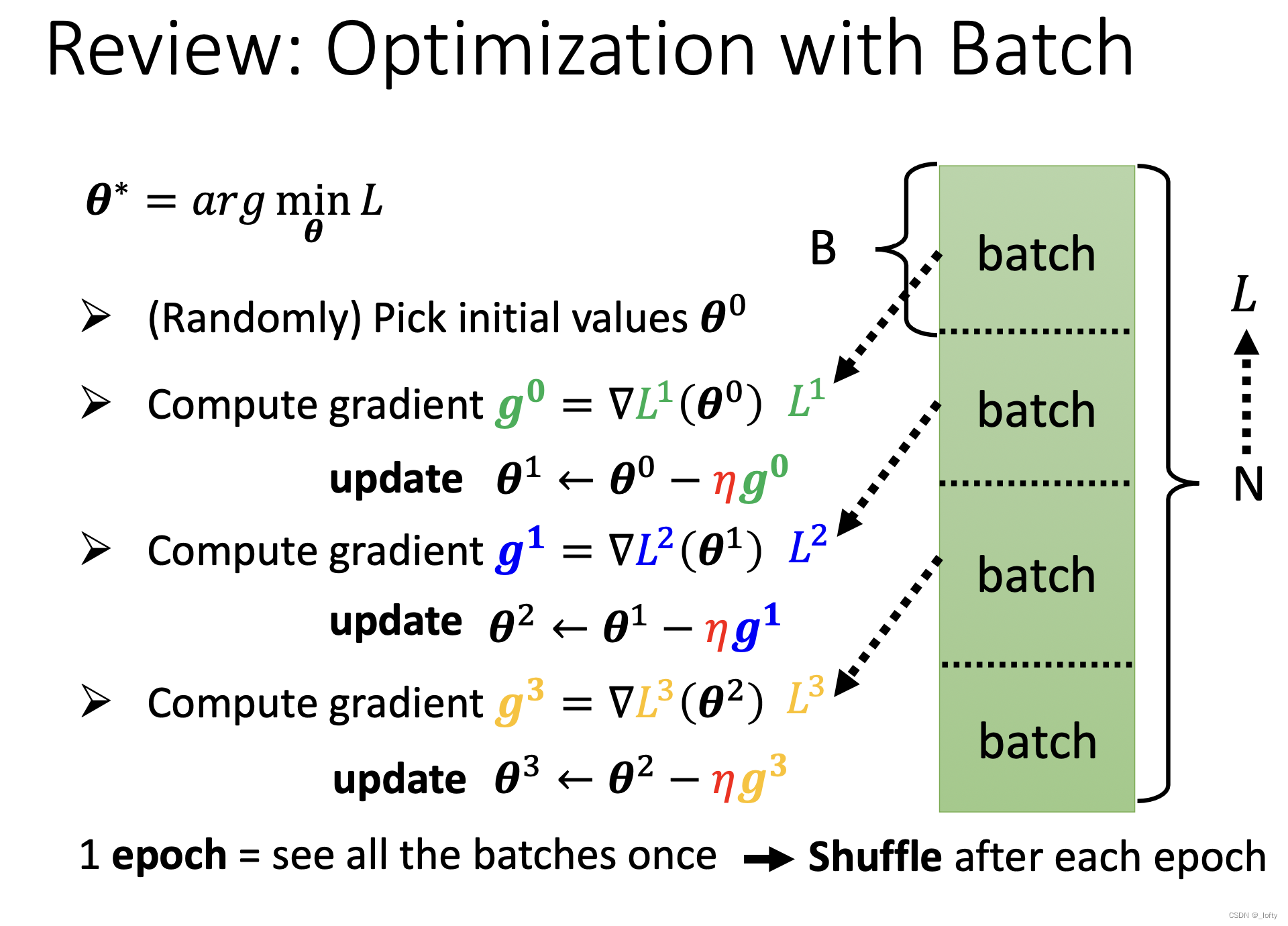
4.1 简单回顾
4.2 一个比较极端的例子

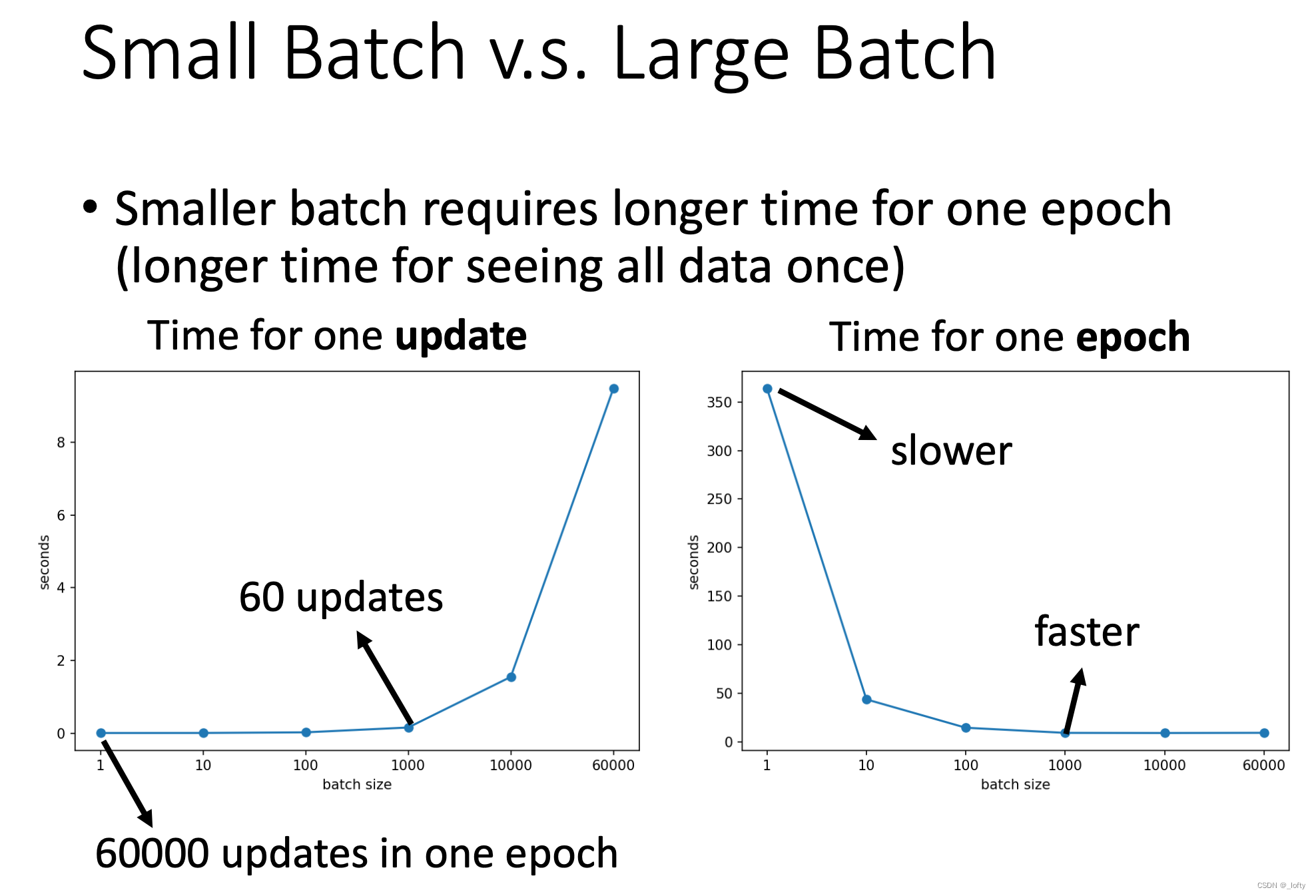
4.3 大batch速度占优势(但有一定限制)
只要batch size不是特别大,其实大batch在速度上还是占优势的。
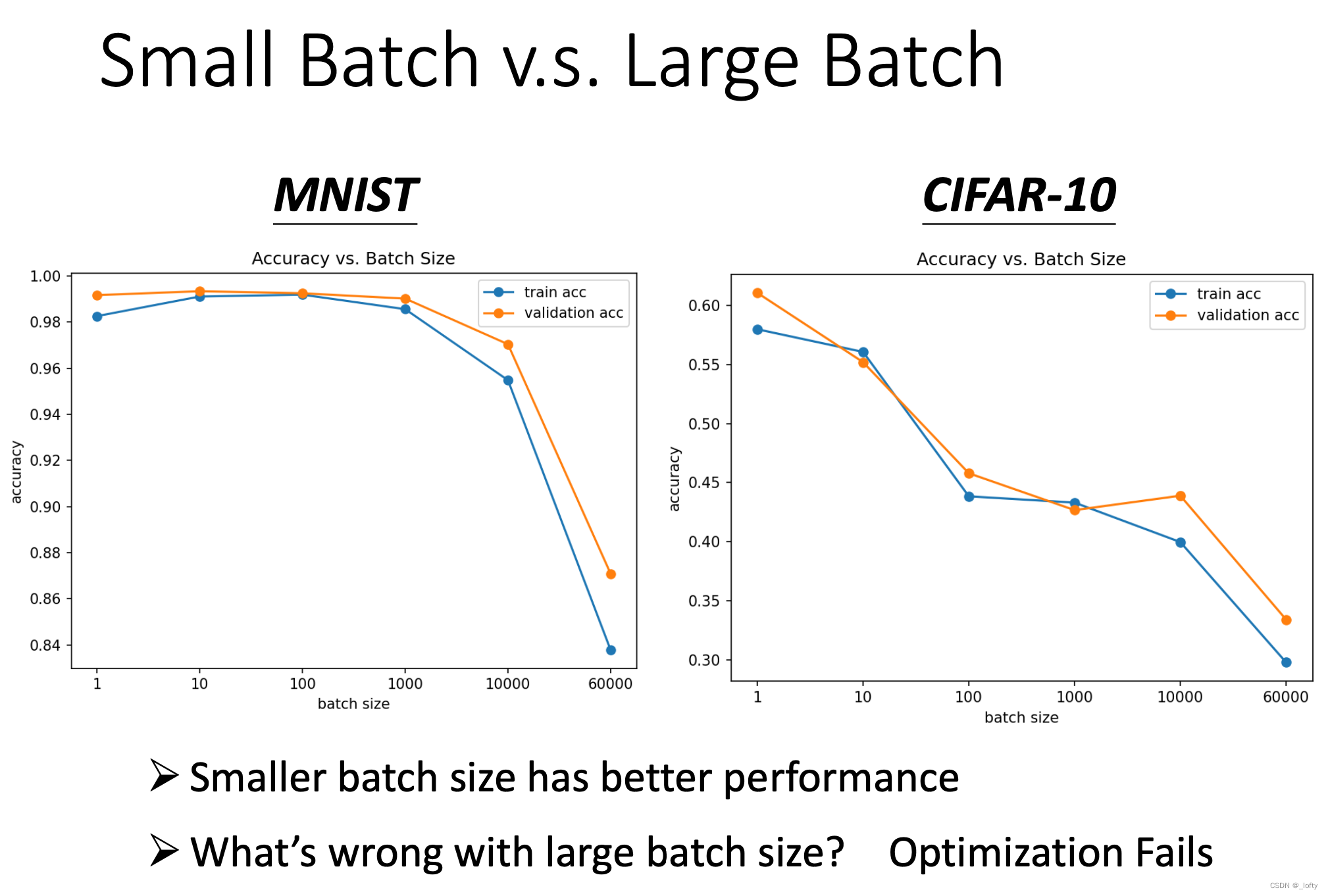
4.4 大batch并非十全十美

大batch可能会导致optimization fails
4.5 大batch导致optimization失败的原因
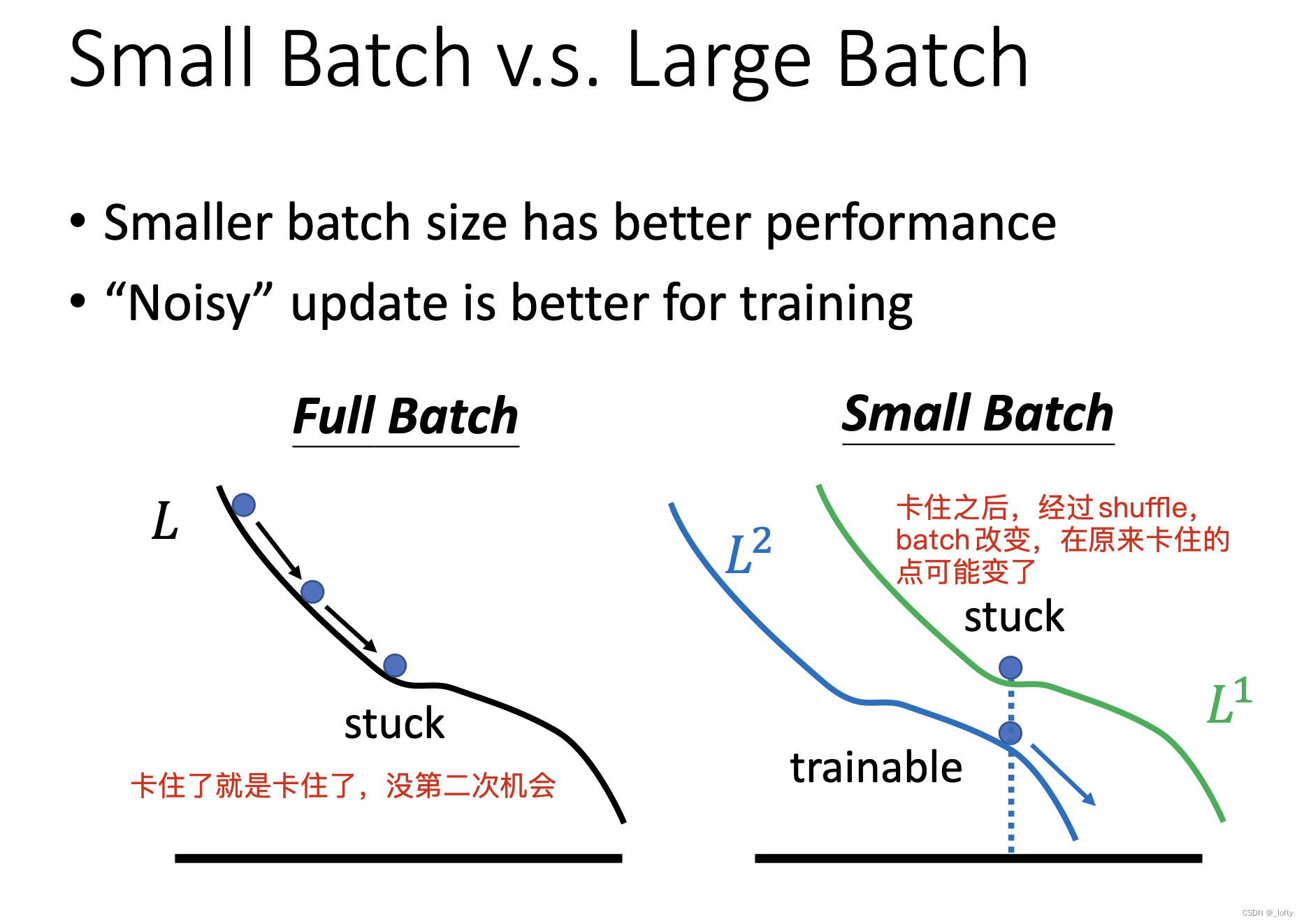
4.6 为什么小batch在测试集上表现更好?
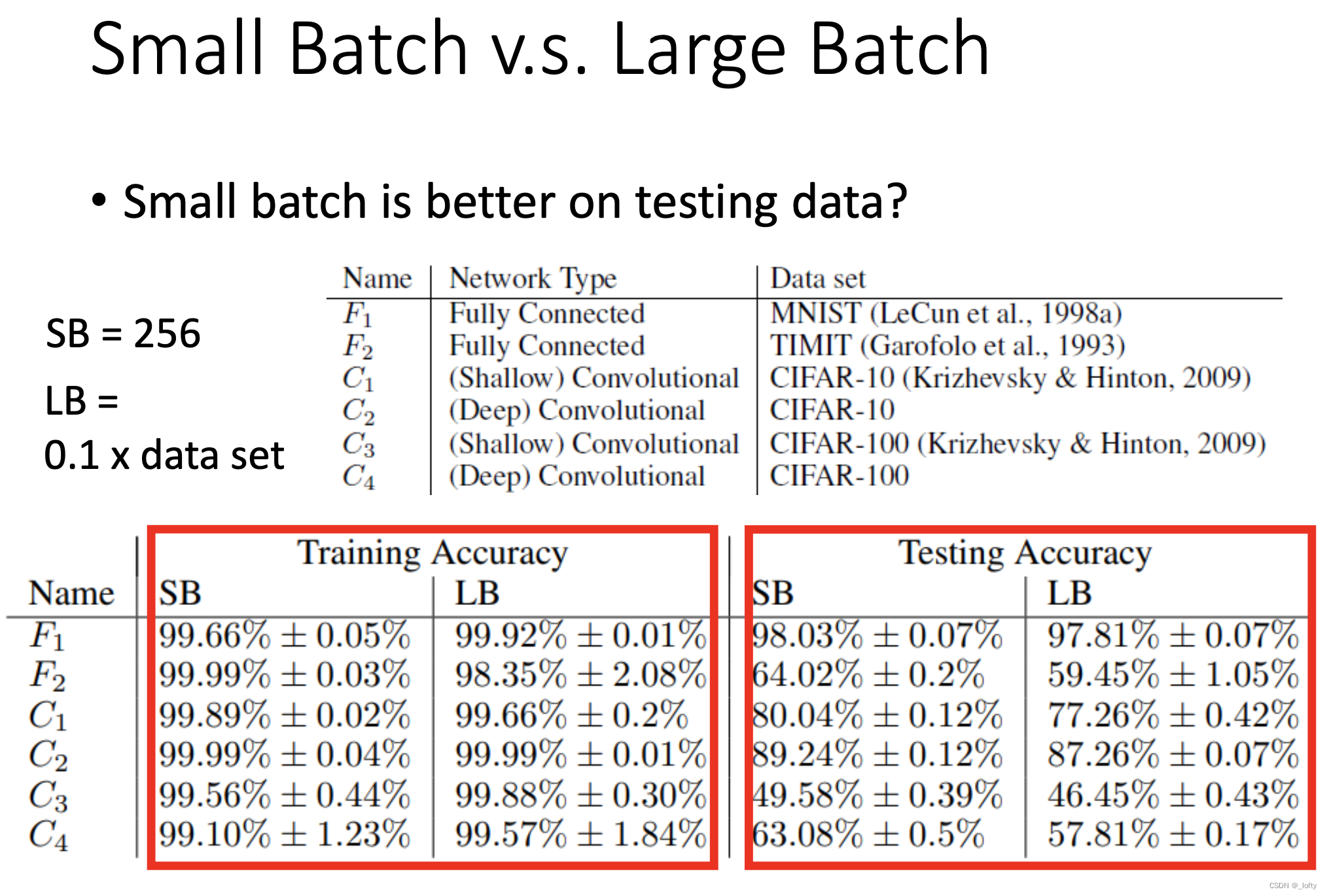
下面这张图我来解释一下。
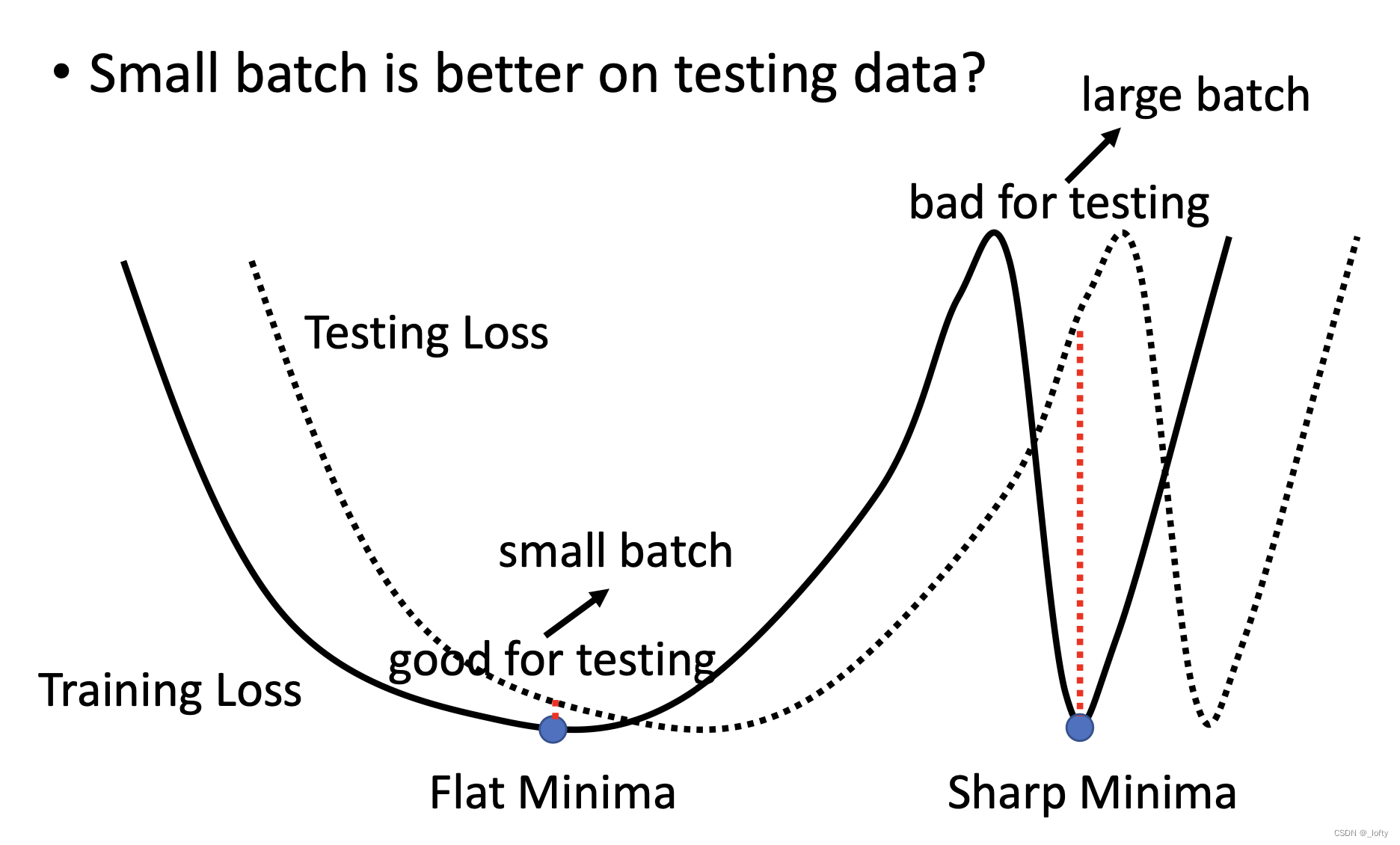
首先,为什么traning loss和testing loss可能不一样?
因为这可能是碰到了mismatch现象,测试集和训练集的数据分布就不太一样。导致两个loss函数不一样
其次,我们认为flat minima比sharp minima好。这是为什么呢,因为看两类minima在两条loss曲线的差别,很明显在sharp minima时得到的testing loss更大。
最后,为什么说small batch更容易走到flat minima?不知道,老师这么说的,说是小峡谷无法困住small batch,就可以跳出来到flat minima了
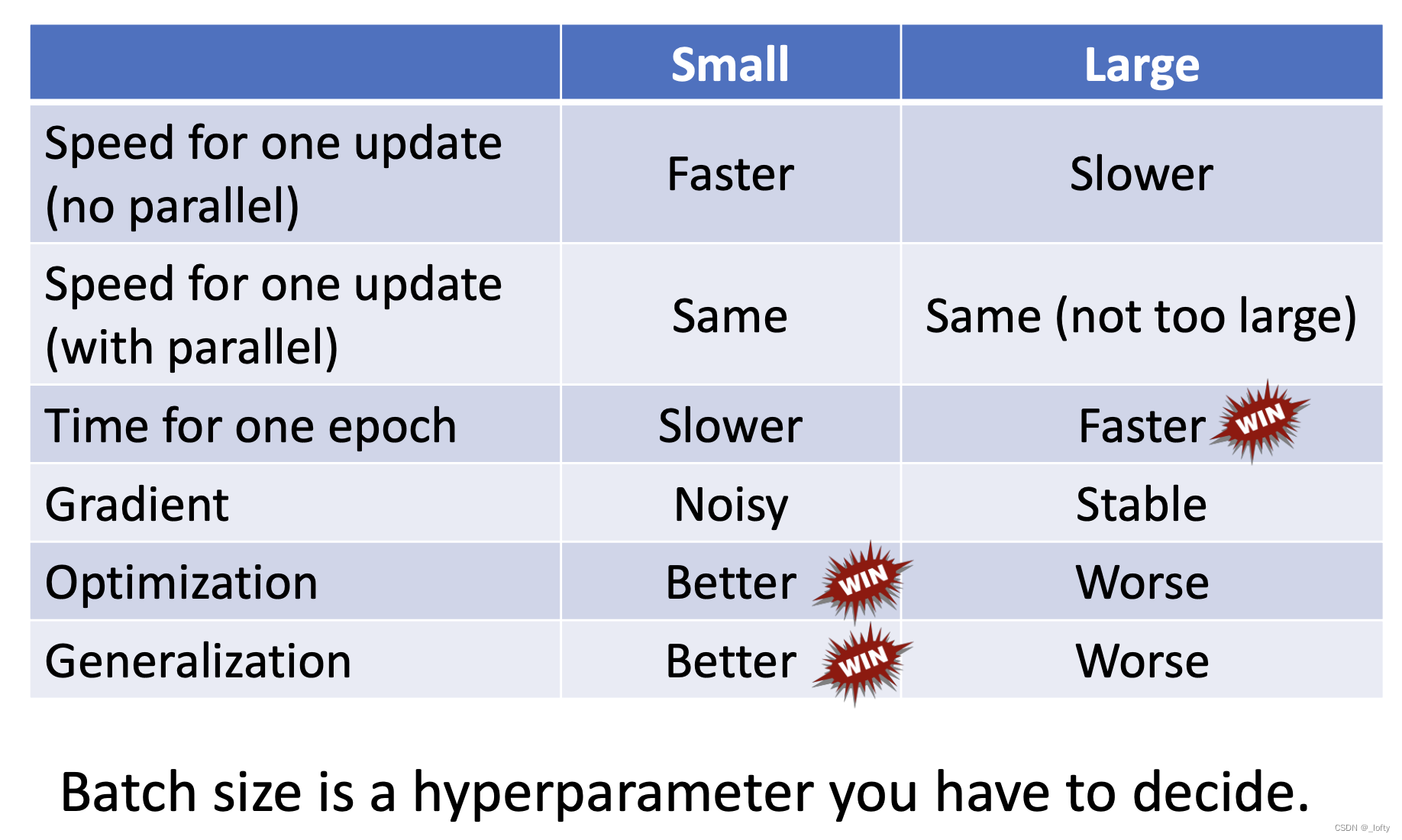
有没有什么办法两全其美一下,就是一种既要又要的追求!
5. Momentum
5.1 引入
考虑到物理世界中小球滚下坡时,带有一定的惯性,即使遇到最低点,也能滚出去
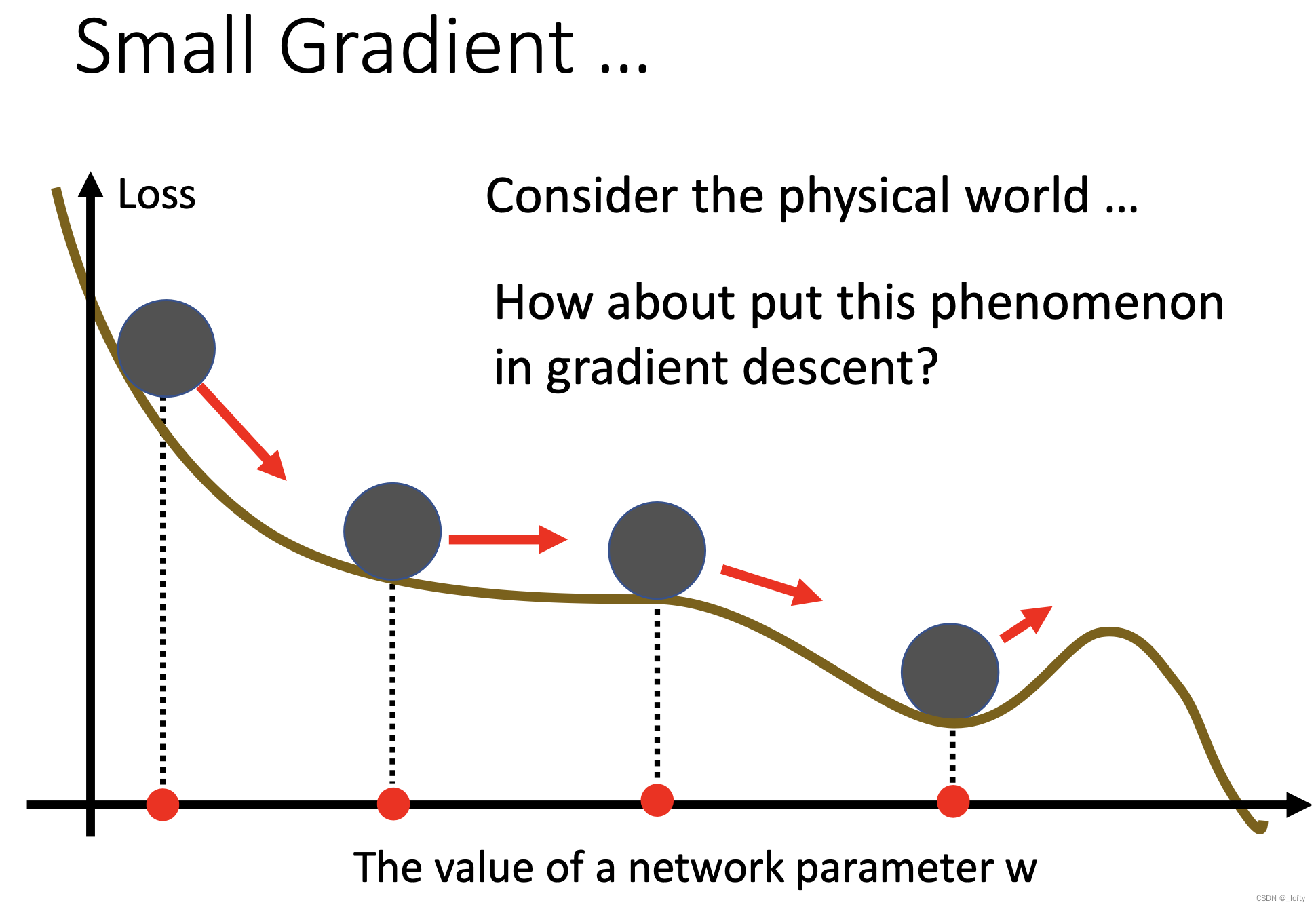
5.2 运动方向的合成
红色虚线和蓝色虚线(代表惯性)合成了蓝色实线,蓝色实线就是实际的运动的方向。
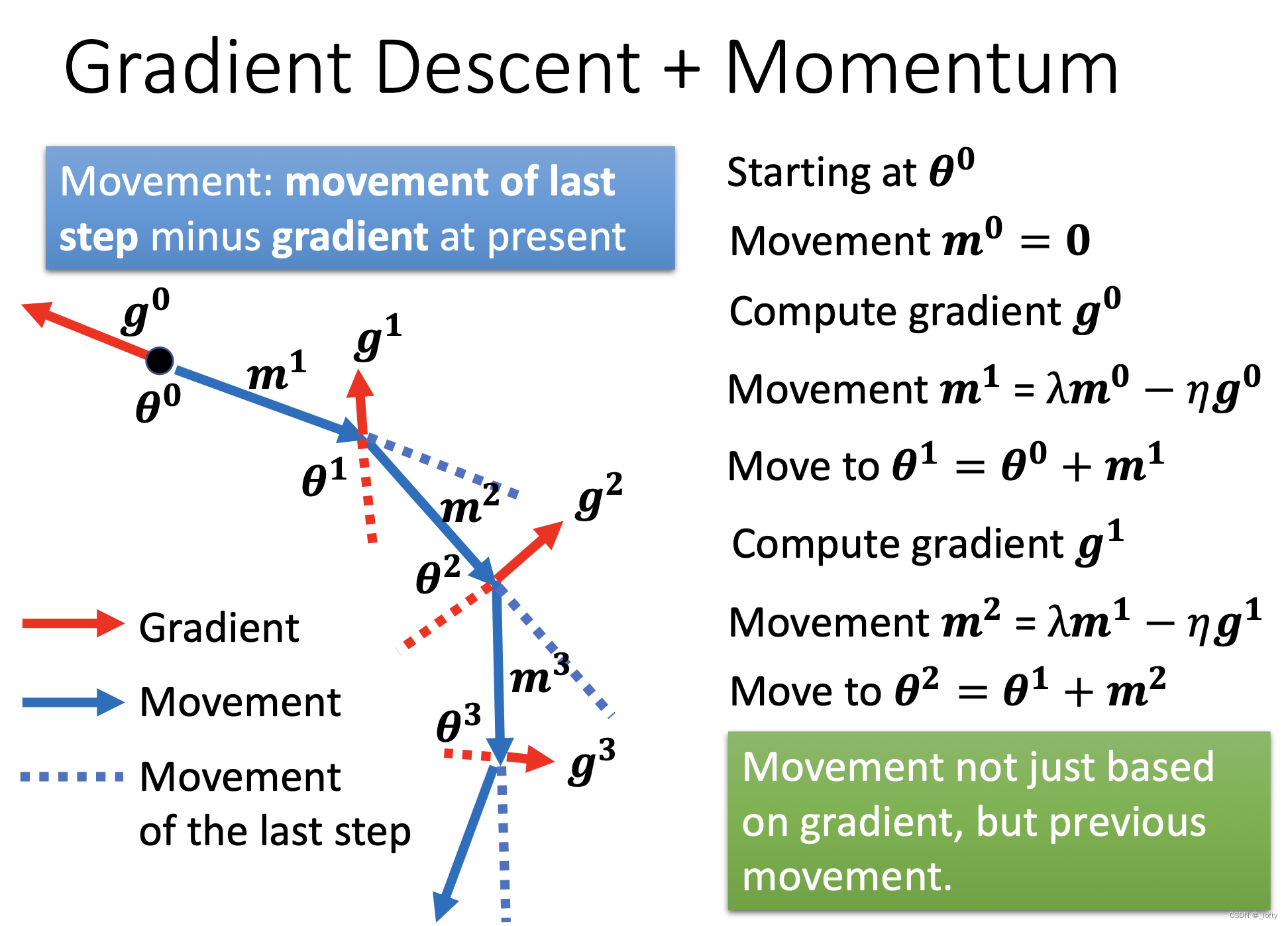
5.3 数学表达




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











