







 本文深入探讨了二叉搜索树的特性,包括其查找、插入和删除操作,并介绍了平衡二叉树的概念,强调了保持树平衡对于优化查找效率的重要性。通过实例展示了如何通过右旋和左旋调整平衡因子,确保树的平衡状态。此外,还讨论了不同插入顺序对树平均查找长度的影响,揭示了平衡二叉树在最佳情况下能达到的查找效率。
本文深入探讨了二叉搜索树的特性,包括其查找、插入和删除操作,并介绍了平衡二叉树的概念,强调了保持树平衡对于优化查找效率的重要性。通过实例展示了如何通过右旋和左旋调整平衡因子,确保树的平衡状态。此外,还讨论了不同插入顺序对树平均查找长度的影响,揭示了平衡二叉树在最佳情况下能达到的查找效率。
数据结构篇(四):
这次开始我们树的第二讲,让我们直接进入正题。
(一).二叉搜索树
一般来说我们都用二叉树解决动态查找(经常发生插入和删除)的问题(取决于它的高效率)。
那么,为什么二叉搜索树的效率会这么好呢?
因为我们将查找的数据实现实现了有效的排序,这样我们就形成了一个判定树,它的查找效率是树的高度。放在树上的动态性比较强,插入删除比在线性里面做容易。
其中,二叉搜索树,一棵二叉树,可以为空,如果不为空,满足以下性质:
1.非空左子树的所有键值小于其根结点的键值。
2.非空右子树的所有键值大于其根结点的键值。
3.左、右子树都是二叉搜索树。
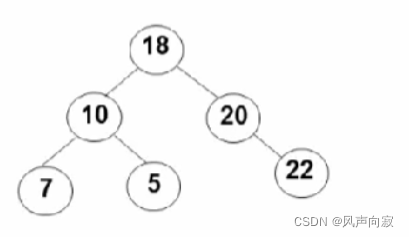
如图,让我们判断一下它是不是二叉搜索树。
因为,对10这个结点,5不满足右子树的键值大于根结点的键值。
二叉树的查找操作:
(1).从根节点开始,如果树为空,返回NULL
(2).若搜索树非空,则根结点关键字和X进行比较,并进行不同处理:
若X小于根结点键值,只需在左子树中继续搜索
如果X大于根结点的键值,在右子树中进行继续搜索
若两者比较结果是相等,搜索完成,返回指向此结点的指针
代码实现如下:
尾递归实现:
Position Find(ElementType X, BinTree BST)
{
if(!BST) return NULL; //如果树为空,返回空
if(X>BST->Data)
return Find(X,BST->Right); //右子树遍历查找
else(X<Bst->Data)
return Find(X,BST->Left); //左子树遍历查找
else
return BST; //查找失败
}
循环实现:
Position IterFind(ElementType X,BinTree BST)
{
while(BST) // 如果树非空
{
if(X>BST->Data)
BST = BST->Right; //右子树遍历查找
else if(x<BST->Data)
BST = BST->Left; //左子树遍历查找
else
return BST;
}
return NULL;
}
找到最小元素:
Position FindMin(BinTree BST)
{
if(!BST) return NULL;
else if(!BST->Left)
return BST;
else
return FindMin(BST->Left);
}
找到最大元素:
Position FindMax(BinTree BST)
{
if(BST)
while(BST->Right)
BST = BST->Right;
return BST;
}
插入元素:
BinTree Insert(ElementType X,BinTree BST)
{
if(!BST) //找到位置后创建结点
{
BST = malloc(sizeof(struct TreeNode));
BST->Data = X;
BST->Left = BST->Right = NULL;
}else
if(X<BST->Data) //遍历查找位置
BST->Left = Insert(X,BST->Left);
else if(X>BST->Data)
BST->Right = Insert(X,BST->Right);
return BST;
}
删除操作:
删除操作一般分三种。
(1)若删除节点为叶节点
直接删除,并再修改其父结点指针—置为NULL
如图,若我们想删除结点35:
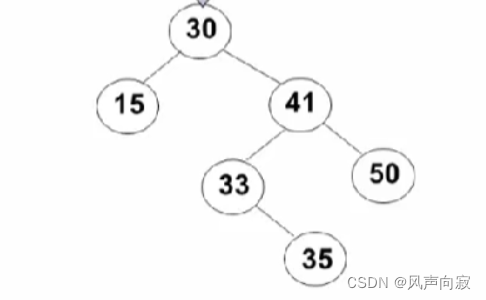
找到结点后直接删除就好,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6yjq5C1t-1639183486825)(C:\Users\Smile\AppData\Roaming\Typora\typora-user-images\image-20211210223613007.png)]](https://i-blog.csdnimg.cn/blog_migrate/d2b9fd507b9d7c4094779c3ecae2ccdc.png)
(2)删除结点带有一个子节点
如图,假设我们想删除33结点:
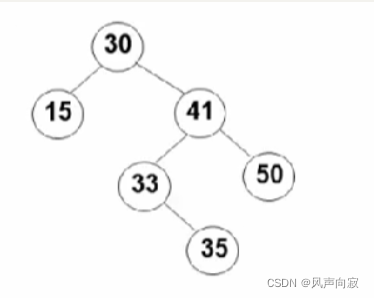
我们找到对应的结点,然后将其带的父节点41指向其子节点35,如图:
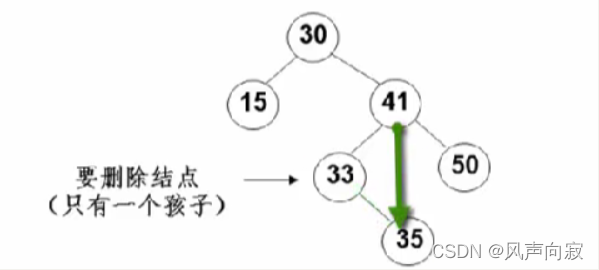
(3)删除结点有左、右两个子节点
我们一般采用另一结点替代被删除结点:右子树的最小元素或者左子树的最大元素,因为他们一定不是有两个子节点的节点。
代码实现:
BinTree Delete(ElementType X,BinTree BST)
{
Position Tmp;
if(!BST) printf("要删除的元素未找到"):
else if(X<BST->Data)
BST->Left = Delete(X,BST->Left); //左子树递归删除
else if(X>BST->Data)
BST->Right = Delete(X,BST->Right);//右子树递归删除
else //找到删除结点
if(BST->Left&&BST->Right) //如果被删除结点有两个子结点
{
Tmp = FindMin(BST->Right);
//找到右子树中最小的结点填补空缺结点
BST->Data = Tmp->Data;
BST->Right = Delete(BST->Data,BST->Right);//删除右子树最小的结点
}else //被删除结点只有一个结点或无孩子结点
{
Tmp = BST;
if(!BST->Left) //有右结点或无孩子结点
BST = BST->Right;
else if(!BST->Right);//有左结点或无孩子结点
BST->BST->Left;
free(Tmp); //将第三方变量空间释放
}
return BST;
}
操作总结以后就是:
1.先找到需要删除的对应的结点
2.判断该需要删除的结点有几个子节点
3.如果被删除结点有两个孩子结点,则删除该结点之前,要有一个第三方变量Tmp来获取右子树最小值或左子树最大值,来填补这个缺失的结点,并且将获取到的结点删除。
4.如果被删除结点只有一个结点或无孩子结点,则判断结点的类型,再用其子树代替它删除后的位置。
(二).平衡二叉树
首先,搜索树结点不同插入次序,将导致不同的深度和平均查找长度ASL。
结点插入次序不同时,查找所花费的平均查找次数也不同。
如下:
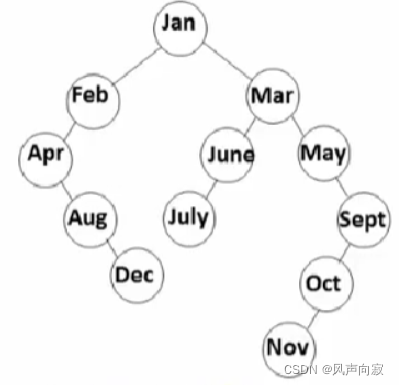
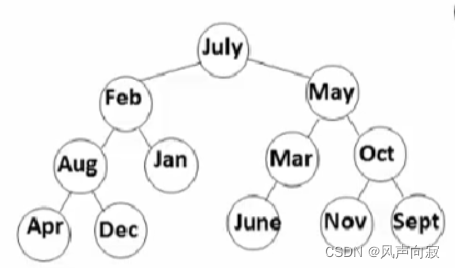
上述两幅图,就鲜明的跟我们体现出来了,不同次序导致树的长度不一样,但是,我们怎么知道平均的查找次数是不是一样呢?
其中,第一幅图中,树的平均查找长度ASL为: (1+2×2+3×3+4×3+5×2+6×1)/12 = 3.5
第一行每个结点比较一次,第二行每个结点比较两次,第三行每个结点比较三次,以此类推,就可以列出上式。
第二幅图中,树的平均查找长度ASL为:3.0(按上述方法计算)
可见,不同的次序,同样导致了查找次数的不同。
同时,相比第一第二张图的ASL,我们发现第二幅图的查找次数更少,效果更好,为什么呢?我们观察它的结构,发现它两边的子树分布的个数比较均匀,长度也相近,即比较平衡。这就引出了我们要讲的——平衡二叉树。
让我们先来了解下平衡因子(左右两个子树的高度差),通常如果不是空树的话,我们不希望它的值超过1。
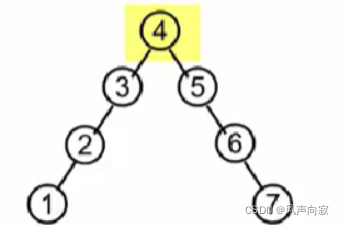
上图这种结构,大家猜猜是不是平衡二叉树。
答案是不是,因为你看3结点左边子树的高度为2,而右边为0,所以左右两边的高度查>1,所以不是平衡二叉树。
下图是不是平衡二叉树呢?
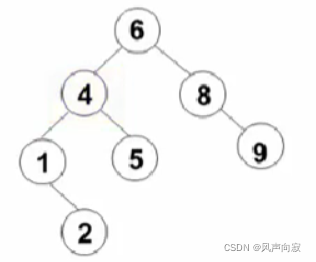
答案为是,因为它每个结点两边的子树高度差都不大于一,所以它为平衡二叉树。
那下图是不是呢:
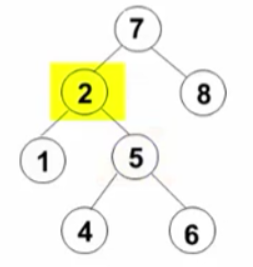
答案为不是,因为对7结点来说,左边的层数比右边多两层,所以它不是平衡二叉树。
平衡二叉树这么好用的话,那它的高度能达到log2n吗?
设nh高度为h的平衡二叉树的最少结点数。结点数最少时:
当高度h = 0时,

最少结点数为1;
当高度h = 1时,
我们有两种情况,一种是左右两边子树都有,一种是某边缺了一个结点。
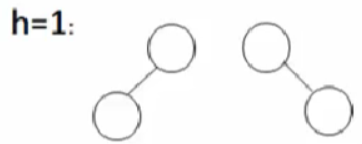
所以最少的结点数为2;
当高度h = 2时,
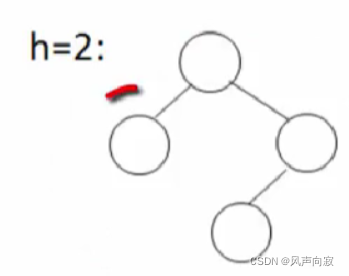
如图,此时为结点个数最少的情况,当最左边的结点删除后,那么剩下的树就不是平衡二叉树,当右子树的左结点删除后,则h就不是2了。
所以此时最少结点数为4;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k5v108Eh-1639183486833)(C:\Users\Smile\AppData\Roaming\Typora\typora-user-images\image-20211211005613919.png)]](https://i-blog.csdnimg.cn/blog_migrate/71a91cf97b50d7b79c1894fe46d275f3.png)
综上我们就可以得到这样的关系,
高度为h时的最少结点数 = 高度为h-1时最少结点数+高度为h-2时最少结点数+1。
(三)平衡二叉树的调整
如图:
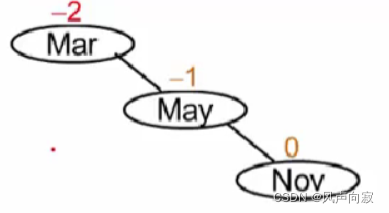
此时,上述结构不构成平衡二叉树,所以我们需要将其转换一下:
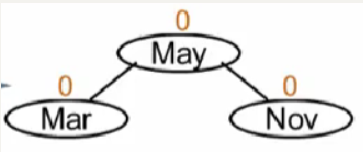
此时,转换的方法叫右旋。
平衡被破坏的发现者是Mar,导致不平衡的结点为“麻烦结点”Nov,因结点是Nov在发现者(Mar)的右子树的右子树上,所以叫RR 插入,需要RR旋转(右单旋)。
让我们看看下面的例子:
如图
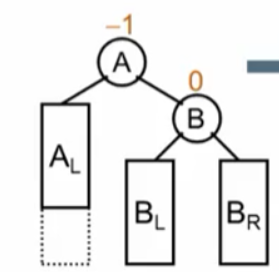
此时是一个平衡二叉树,我们现在加入一个结点:
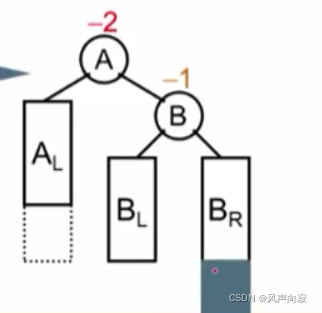
可以发现,此时平衡二叉树的结点被破坏了,这时我们发现,破坏平衡的结点是N在发现者(A)的右子树的右子树上,所以我们进行RR旋转。
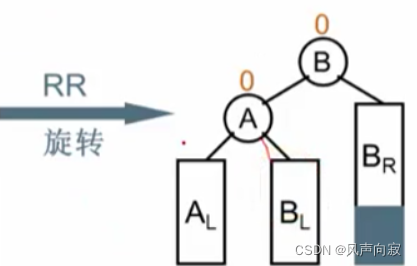
再举个LL旋转的例子:
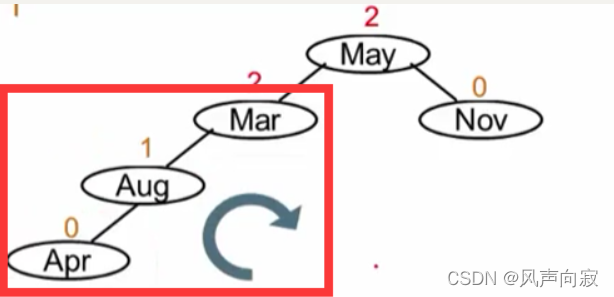
如图,被破坏者为Mar,破坏者为Apr,所以我们破坏者在被破坏者左子树的左子树上,所以进行LL旋转
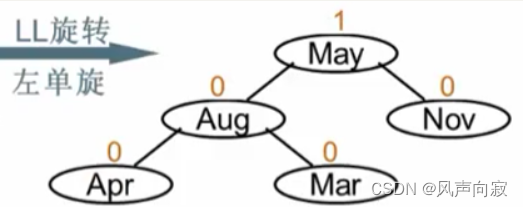
(注意,只需旋转被破坏者到破坏者那一段。)
具体操作如下:
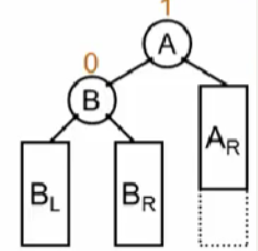
再入对应的破坏者:
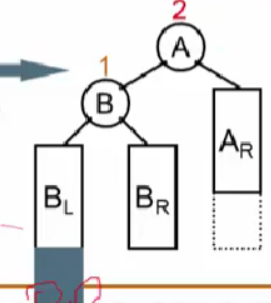
旋转:
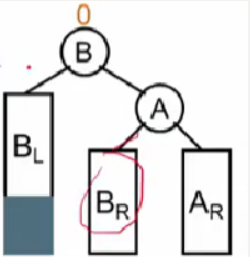
因为它是搜索树,必须满足左边小右边大,所以BR位置如上图。
再举个LR例子:
如图
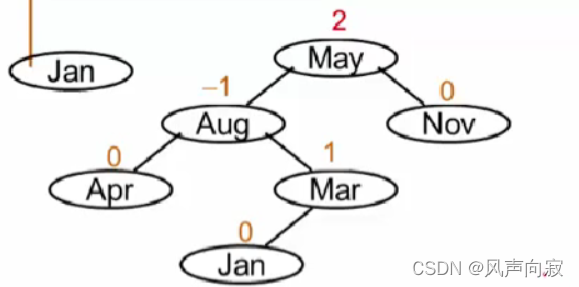
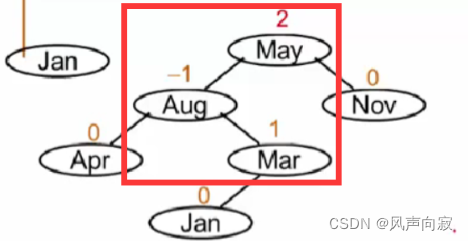
Jan插入后,树变得不平衡了,其中被破坏者为May,破坏者为Jan,此时破坏者在被破坏者的左子树的右子树上,所以进行LR旋转。
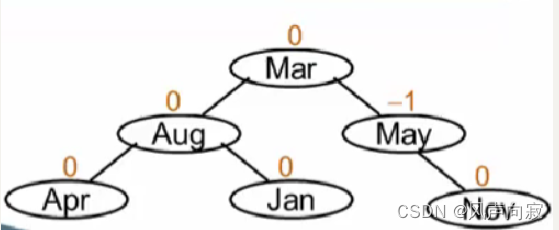
此时,为什么转换为这样呢?
因为Mar为三个结点的中心值,以他为根节点符合二叉树左小右大的规则。
操作如图:
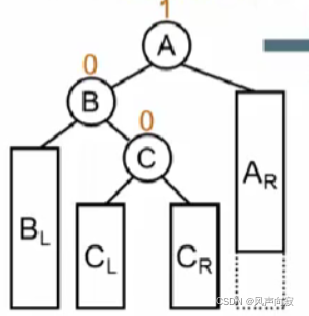
插入破坏结点:

进行LR旋转:
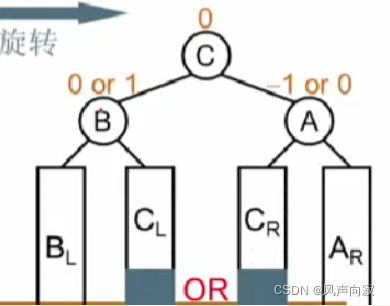
必须满足左边小右边大,所以以C为根节点,B在左,A在右。
真正的希望必须是现实的延伸,是一步步往前走的路,是不断为美好的下一步作准备的实现。
数据结构篇(五):_风声向寂的博客-优快云博客
(2条消息) 数据结构篇(三):_风声向寂的博客-优快云博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









