







目录
首先需要介绍两个概念:
磁盘
常见的有机械硬盘(HDD)和固态硬盘(SSD),也有一部分机器会使用NVME协议的固态硬盘,总的来说,磁盘的作用就是持久化存储数据。
- 机械磁盘的最小读写单位是扇区,一般大小为 512 字节
- 固态磁盘的最小读写单位是页,通常大小是 4KB、8KB 等
在 Linux 中,磁盘实际上是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
文件系统
文件系统是在磁盘之上的树状结构,主要用来管理文件。Linux常见的文件系统有ext4和xfs,这是目前使用最广泛的两种。
虚拟文件系统
为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
备注:
- lvm技术准确来说是一种磁盘管理技术,在其之上依然有文件系统。
- 无论机械磁盘,还是固态磁盘,相同磁盘的随机 I/O 都要比连续 I/O 慢很多。对固态磁盘来说,虽然它的随机性能比机械硬盘好很多,但同样存在“先擦除再写入”的限制。随机读写会导致大量的垃圾回收,所以相对应的,随机 I/O 的性能比起连续 I/O 来,也还是差了很多。
此外,连续 I/O 还可以通过预读的方式,来减少 I/O 请求的次数,这也是其性能优异的一个原因。很多性能优化的方案,也都会从这个角度出发,来优化 I/O 性能。
文件系统的工作原理
为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
索引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。比如说软链接文件,实际就是多了一个目录项,实际指向的inode还是原来的文件。
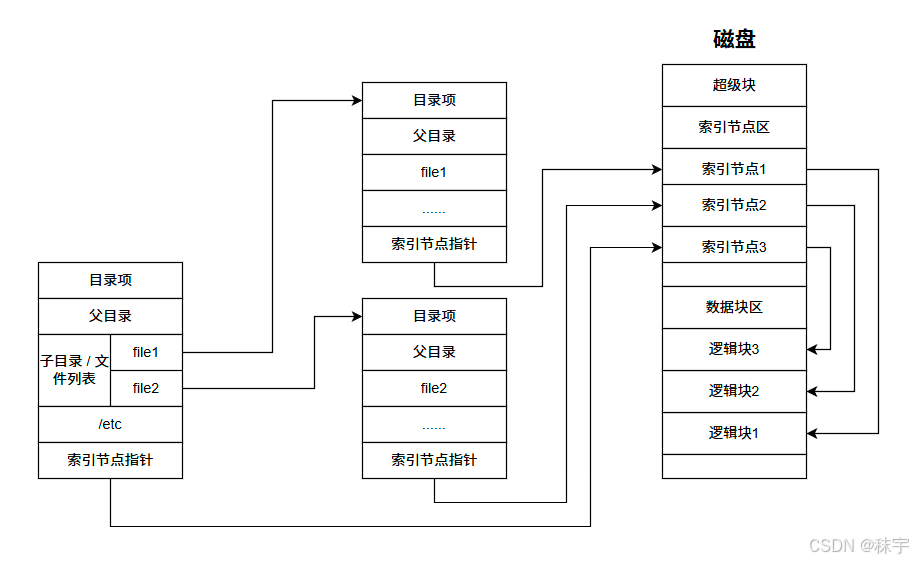
首先,目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据。为了协调慢速磁盘与快速 CPU 的性能差异,文件内容会缓存到页缓存 Cache 中,索引节点也会缓存到内存中,从而提升文件的访问速度。
其次,磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块(Superblock)、索引节点区和数据块区。其中:
- 超级块,存储整个文件系统的状态
- 索引节点区,用来存储索引节点
- 数据块区,则用来存储文件数据
文件系统 I/O
把文件系统挂载到挂载点后,就能通过挂载点,去访问它下面的文件了。VFS 提供了一组标准的文件访问接口。这些接口以系统调用的方式,提供给应用程序使用。
I/O 的分类
文件读写方式的各种差异,导致 I/O 的分类多种多样。
缓冲与非缓冲 I/O
- 缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
- 非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
无论缓冲 I/O 还是非缓冲 I/O,它们最终还是要经过系统调用来访问文件。系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
直接与非直接 I/O
- 直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
- 非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。
想要实现直接 I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接 I/O。不过要注意,直接 I/O、非直接 I/O,本质上还是和文件系统交互。如果是在数据库等场景中,你还会看到,跳过文件系统读写磁盘的情况,也就是我们通常所说的裸 I/O。
阻塞与非阻塞 I/O
- 阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
- 非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后
再通过轮询或者事件通知的形式,获取调用的结果。
例如,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
同步与异步 I/O
- 同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
- 异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,反馈给应用程序。
例如,在访问管道或者网络套接字时,设置了 O_ASYNC 选项后,相应的 I/O 就是异步 I/O。这样,内核会再通过 SIGIO 或者 SIGPOLL,来通知进程文件是否可读写。
查看文件系统容量
文件系统和磁盘空间:
df -h
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 1.1M 1.9G 1% /dev/shm
tmpfs 1.9G 12M 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/mapper/centos-root 41G 6.8G 35G 17% /
/dev/sda2 1014M 153M 862M 16% /boot
tmpfs 378M 0 378M 0% /run/user/0
指定具体的目录或挂载点:
df -h /
[root@localhost ~]# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 41G 6.8G 35G 17% /
索引节点的容量:
df -hi
[root@localhost ~]# df -hi
Filesystem Inodes IUsed IFree IUse% Mounted on
devtmpfs 469K 398 469K 1% /dev
tmpfs 472K 3 472K 1% /dev/shm
tmpfs 472K 1.3K 471K 1% /run
tmpfs 472K 16 472K 1% /sys/fs/cgroup
/dev/mapper/centos-root 21M 70K 21M 1% /
/dev/sda2 512K 327 512K 1% /boot
tmpfs 472K 1 472K 1% /run/user/0
当发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。一般来说,删除这些小文件,或者把它们移动到索引节点充足的其他磁盘中,就可以解决这个问题。
目录项和索引节点缓存
[root@localhost ~]# cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
xfs_inode 27540 27540 960 34 8 : tunables 0 0 0 : slabdata 810 810 0
fuse_inode 0 0 768 42 8 : tunables 0 0 0 : slabdata 0 0 0
mqueue_inode_cache 36 36 896 36 8 : tunables 0 0 0 : slabdata 1 1 0
hugetlbfs_inode_cache 53 53 608 53 8 : tunables 0 0 0 : slabdata 1 1 0
sock_inode_cache 1071 1071 640 51 8 : tunables 0 0 0 : slabdata 21 21 0
shmem_inode_cache 1824 1824 680 48 8 : tunables 0 0 0 : slabdata 38 38 0
proc_inode_cache 15200 15696 672 48 8 : tunables 0 0 0 : slabdata 327 327 0
inode_cache 17380 17380 592 55 8 : tunables 0 0 0 : slabdata 316 316 0
dentry 62244 62244 192 42 2 : tunables 0 0 0 : slabdata 1482 1482 0
selinux_inode_security 30804 30804 40 102 1 : tunables 0 0 0 : slabdata 302 302 0
dentry 行表示目录项缓存,inode_cache 行,表示 VFS 索引节点缓存,其余的则是各种文件系统的索引节点缓存。
也可以用 slabtop 来查看:
[root@localhost ~]# slabtop
Active / Total Objects (% used) : 934307 / 1011266 (92.4%)
Active / Total Slabs (% used) : 22810 / 22810 (100.0%)
Active / Total Caches (% used) : 74 / 106 (69.8%)
Active / Total Size (% used) : 175731.83K / 188576.36K (93.2%)
Minimum / Average / Maximum Object : 0.01K / 0.19K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
582153 515278 88% 0.10K 14927 39 59708K buffer_head
62244 62244 100% 0.19K 1482 42 11856K dentry
46988 46988 100% 0.12K 691 68 5528K kernfs_node_cache
32512 32371 99% 0.06K 508 64 2032K kmalloc-64
30804 30804 100% 0.04K 302 102 1208K selinux_inode_security
28952 28952 100% 0.57K 517 56 16544K radix_tree_node
27540 27540 100% 0.94K 810 34 25920K xfs_inode
26880 26880 100% 0.02K 105 256 420K kmalloc-16
23414 23414 100% 0.17K 509 46 4072K xfs_ili
17380 17380 100% 0.58K 316 55 10112K inode_cache
15696 15200 96% 0.66K 327 48 10464K proc_inode_cache
14048 12400 88% 1.00K 439 32 14048K kmalloc-1024
10880 10880 100% 0.05K 128 85 512K shared_policy_node
10624 10624 100% 0.03K 83 128 332K kmalloc-32
10304 10304 100% 0.07K 184 56 736K avc_node
10240 10240 100% 0.01K 20 512 80K kmalloc-8
8904 8611 96% 0.19K 212 42 1696K kmalloc-192
8064 7067 87% 0.25K 126 64 2016K kmalloc-256
6919 6632 95% 0.21K 187 37 1496K vm_area_struct
10688 5789 54% 0.50K 167 64 5344K kmalloc-512
3108 3108 100% 0.38K 74 42 1184K mnt_cache
2772 2772 100% 0.09K 66 42 264K kmalloc-96
3009 2533 84% 0.08K 59 51 236K anon_vma
2816 2445 86% 0.12K 44 64 352K kmalloc-128
1824 1824 100% 0.66K 38 48 1216K shmem_inode_cache
1664 1548 93% 2.00K 104 16 3328K kmalloc-2048
1071 1071 100% 0.62K 21 51 672K sock_inode_cache
672 672 100% 0.19K 16 42 128K cred_jar
612 612 100% 0.31K 12 51 192K bio-3
572 572 100% 0.18K 13 44 104K xfs_log_ticket
555 555 100% 0.21K 15 37 120K xfs_btree_cur
570 418 73% 0.41K 15 38 240K xfs_efd_item
396 396 100% 0.11K 11 36 44K task_delay_info
通用块层
跟虚拟文件系统 VFS 类似,为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备。
通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能 :
- 第一个功能
跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;
向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。 - 第二个功能
通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
其中,对 I/O 请求排序的过程,也就是我们熟悉的 I/O 调度。事实上,Linux 内核支持四种 I/O 调度算法,分别是
- NONE
更确切来说,并不能算 I/O 调度算法。因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。 - NOOP
是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。 - CFQ
也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。 - DeadLine。
分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
I/O 栈
我们可以把 Linux 存储系统的 I/O 栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层。这三个 I/O 层的关系如下图所示,这其实也是 Linux 存储系统的 I/O 栈全景图。以Linux kernel-6.2为例:

根据这张 I/O 栈的全景图,我们可以更清楚地理解,存储系统 I/O 的工作原理。
- 文件系统层:包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
- 通用块层:包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
- 设备层:包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
存储系统的 I/O ,通常是整个系统中最慢的一环。所以, Linux 通过多种缓存机制来优化 I/O 效率。
例如,为了优化文件访问的性能,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,以减少对下层块设备的直接调用。同样,为了优化块设备的访问效率,会使用缓冲区,来缓存块设备的数据。
磁盘性能指标
磁盘性能的衡量标准有使用率、饱和度、IOPS、吞吐量以及响应时间等。这五个指标,是衡量磁盘性能的基本指标。
- 使用率:是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度:是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second):是指每秒的 I/O 请求数。
- 吞吐量:是指每秒的 I/O 请求大小。
- 响应时间:是指 I/O 请求从发出到收到响应的间隔时间。
要注意的是,使用率只考虑有没有 I/O,而不考虑 I/O 的大小。换句话说,当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求。
在数据库、大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能;而在多媒体等顺序读写较多的场景中,吞吐量才更能反映系统的整体性能。
磁盘 I/O 观测
iostat 是最常用的磁盘 I/O 性能观测工具,它来自于sysstat这个工具包,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
[root@localhost ~]# iostat -d -x
Linux 3.10.0-1160.71.1.el7.x86_64 (localhost.localdomain) 03/24/2025 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
scd0 0.00 0.00 0.00 0.00 0.01 0.00 114.22 0.00 1.50 1.50 0.00 1.17 0.00
sda 0.00 0.03 0.37 0.43 7.11 55.92 156.61 0.00 0.33 0.38 0.29 0.10 0.01
dm-0 0.00 0.00 0.35 0.46 6.69 55.89 155.56 0.00 0.43 0.41 0.45 0.10 0.01
dm-1 0.00 0.00 0.00 0.00 0.03 0.01 24.17 0.00 0.66 0.15 1.04 0.22 0.00
这些指标中,需要注意:
- %util :就是我们前面提到的磁盘 I/O 使用率;
- r/s + w/s :就是 IOPS;
- rkB/s+wkB/s :就是吞吐量;
- r_await + w_await :就是响应时间。
在观测指标时,结合请求的大小( rareq-sz 和 wareq-sz)一起分析。
进程 I/O 观测
除了每块磁盘的 I/O 情况,每个进程的 I/O 情况也是我们需要关注的重点。
上面提到的 iostat 只提供磁盘整体的 I/O 性能数据,缺点在于,并不能知道具体是哪些进程在进行磁盘读写。要观察进程的 I/O 情况,你还可以使用 pidstat 和 iotop 这两个工具。
给 pidstat 加上 -d 参数,你就可以看到进程的 I/O 情况:
[root@localhost ~]# pidstat -d
Linux 3.10.0-1160.71.1.el7.x86_64 (localhost.localdomain) 03/24/2025 _x86_64_ (2 CPU)
11:03:46 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
11:03:46 PM 0 1 0.92 13.55 0.01 systemd
11:03:46 PM 0 47 0.00 0.00 0.00 kworker/u256:1
11:03:46 PM 0 415 0.00 0.00 0.00 xfsaild/dm-0
11:03:46 PM 0 496 0.01 0.00 0.00 systemd-journal
11:03:46 PM 0 519 0.18 0.00 0.00 systemd-udevd
11:03:46 PM 0 525 0.00 0.00 0.00 lvmetad
11:03:46 PM 0 652 0.00 0.01 0.00 auditd
11:03:46 PM 0 674 0.01 0.00 0.00 systemd-logind
11:03:46 PM 81 675 0.01 0.00 0.00 dbus-daemon
11:03:46 PM 0 677 0.08 0.00 0.00 NetworkManager
11:03:46 PM 0 680 0.00 0.00 0.00 irqbalance
11:03:46 PM 0 681 0.07 0.00 0.00 VGAuthService
11:03:46 PM 0 682 0.04 0.00 0.00 vmtoolsd
11:03:46 PM 999 684 0.07 0.00 0.00 polkitd
11:03:46 PM 0 687 0.01 0.00 0.00 crond
11:03:46 PM 0 690 0.00 0.00 0.00 agetty
11:03:46 PM 0 943 0.11 0.00 0.00 tuned
11:03:46 PM 0 944 0.01 0.00 0.00 sshd
11:03:46 PM 0 947 0.01 0.02 0.01 rsyslogd
11:03:46 PM 26 965 0.13 0.01 0.00 postmaster
11:03:46 PM 26 1004 0.00 0.00 0.00 postmaster
11:03:46 PM 26 1008 0.00 0.00 0.00 postmaster
11:03:46 PM 26 1009 0.00 0.00 0.00 postmaster
11:03:46 PM 26 1014 0.00 0.00 0.00 postmaster
11:03:46 PM 26 1015 0.00 0.00 0.00 postmaster
11:03:46 PM 26 1016 0.00 0.00 0.00 postmaster
11:03:46 PM 0 1150 0.05 0.00 0.00 master
11:03:46 PM 89 1154 0.00 0.00 0.00 qmgr
11:03:46 PM 0 1444 0.03 0.00 0.00 sshd
11:03:46 PM 0 1446 0.01 0.00 0.00 sshd
11:03:46 PM 0 1448 3.81 40.34 0.06 bash
11:03:46 PM 0 1463 0.00 0.00 0.00 sftp-server
11:03:46 PM 0 1909 0.06 0.00 0.00 sshd
11:03:46 PM 0 1912 0.01 0.00 0.00 sshd
11:03:46 PM 0 1914 1.38 0.93 0.01 bash
11:03:46 PM 0 1929 0.00 0.00 0.00 sftp-server
11:03:46 PM 0 6466 0.00 0.00 0.00 su
11:03:46 PM 1000 6468 0.00 0.00 0.00 bash
从 pidstat 的输出你能看到,它可以实时查看每个进程的 I/O 情况,包括下面这些内容:
- 用户 ID(UID)和进程 ID(PID) 。
- 每秒读取的数据大小(kB_rd/s) ,单位是 KB。
- 每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
- 每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
- 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
除了可以用 pidstat 实时查看,根据 I/O 大小对进程排序,也是性能分析中一个常用的方法,可以用 iotop。iotop 是一个类似于 top 的工具,你可以按照 I/O 大小对进程排序,然后找到 I/O 较大的那些进程。
[root@localhost ~]# iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
30 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.02 % [kworker/1:1]
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 22
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
4 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]
6 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
7 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/0]
8 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_bh]
9 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_sched]
10 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [lru-add-drain]
11 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/0]
12 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/1]
13 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/1]
14 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/1]
16 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/1:0H]
18 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kdevtmpfs]
19 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [netns]
20 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [khungtaskd]
21 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [writeback]
22 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kintegrityd]
23 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [bioset]
24 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [bioset]
25 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [bioset]
26 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kblockd]
27 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [md]
28 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [edac-poller]
29 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdogd]
35 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kswapd0]
36 be/5 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksmd]
37 be/7 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [khugepaged]
38 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [crypto]
519 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd-udevd
46 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthrotld]
47 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/u256:1]
48 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kmpath_rdacd]
49 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kaluad]
51 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kpsmoused]
53 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ipv6_addrconf]
从这个输出可以看到,前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等。剩下的部分,则是从各个角度来分别表示进程的 I/O 情况,包括线程 ID、I/O 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待 I/O 的时钟百分比等。
I/O瓶颈的排查思路
思路一
先用 top ,来观察 CPU 和内存的使用情况;
再用 iostat ,来观察磁盘的 I/O 情况。
再用 pidstat ,观察进程的 I/O 情况。
最后用 strace 进行具体的跟踪。
思路二
先用 iostat 发现磁盘 I/O 性能瓶颈;
再借助 pidstat ,定位出导致瓶颈的进程;
随后分析进程的 I/O 行为;
最后,结合应用程序的原理,分析这些 I/O 的来源。
I/O优化思路
应用程序优化
- 可以用追加写代替随机写,减少寻址开销,加快 I/O 写的速度。
- 可以借助缓存 I/O ,充分利用系统缓存,降低实际 I/O 的次数。
- 可以在应用程序内部构建自己的缓存,或者用 Redis 这类外部缓存系统。
这样,一方面,能在应用程序内部,控制缓存的数据和生命周期;另一方面,也能降低其他应用程序使用缓存对自身的影响。 - 在需要频繁读写同一块磁盘空间时,可以用 mmap 代替 read/write,减少内存的拷贝次数。
- 在需要同步写的场景中,尽量将写请求合并,而不是让每个请求都同步写入磁盘,即可以用 fsync() 取代 O_SYNC。
- 在多个应用程序共享相同磁盘时,为了保证 I/O 不被某个应用完全占用,推荐使用 cgroups 的 I/O 子系统,来限制进程 / 进程组的 IOPS 以及吞吐量。
- 在使用 CFQ 调度器时,可以用 ionice 来调整进程的 I/O 调度优先级,特别是提高核心应用的 I/O 优先级。
ionice 支持三个优先级类:Idle、Best-effort 和 Realtime。其中, Best-effort 和 Realtime 还分别支持 0-7 的级别,数值越小,则表示优先级别越高。
文件系统优化
- 你可以根据实际负载场景的不同,选择最适合的文件系统。比如 Ubuntu 默认使用 ext4 文件系统,而 CentOS 7 默认使用 xfs 文件系统。
- 在选好文件系统后,还可以进一步优化文件系统的配置选项,包括文件系统的特性(如 ext_attr、dir_index)、日志模式(如 journal、ordered、writeback)、挂载选项(如 noatime)等等。
- 可以优化文件系统的缓存。比如,你可以优化 pdflush 脏页的刷新频率(比如设置 dirty_expire_centisecs 和 dirty_writeback_centisecs)以及脏页的限额(比如调整 dirty_background_ratio 和 dirty_ratio 等)。
- 在不需要持久化时,你还可以用内存文件系统 tmpfs,以获得更好的 I/O 性能 。
tmpfs 把数据直接保存在内存中,而不是磁盘中。比如 /dev/shm/ ,就是大多数 Linux 默认配置的一个内存文件系统,它的大小默认为总内存的一半。
磁盘优化
-
最简单有效的优化方法,就是换用性能更好的磁盘,比如用 SSD 替代 HDD。
-
我们可以使用 RAID ,把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。这样做既可以提高数据的可靠性,又可以提升数据的访问性能。
-
针对磁盘和应用程序 I/O 模式的特征,我们可以选择最适合的 I/O 调度算法。比方说,SSD 和虚拟机中的磁盘,通常用的是 noop 调度算法。而数据库应用,我更推荐使用 deadline 算法。
-
我们可以对应用程序的数据,进行磁盘级别的隔离。比如,我们可以为日志、数据库等 I/O 压力比较重的应用,配置单独的磁盘。
-
在顺序读比较多的场景中,我们可以增大磁盘的预读数据,比如,你可以通过下面两种方法,调整 /dev/sdb 的预读大小。
调整内核选项 /sys/block/sdb/queue/read_ahead_kb,默认大小是 128 KB,单位为 KB
使用 blockdev 工具设置,比如 blockdev --setra 8192 /dev/sdb
注意这里的单位是 512B(0.5KB),所以它的数值总是 read_ahead_kb 的两倍 -
我们可以优化内核块设备 I/O 的选项。比如,可以调整磁盘队列的长度 /sys/block/sdb/queue/nr_requests,适当增大队列长度,可以提升磁盘的吞吐量(当然也会导致 I/O 延迟增大)。
-
磁盘本身出现硬件错误,也会导致 I/O 性能急剧下降,所以发现磁盘性能急剧下降时,还需要确认,磁盘本身是不是出现了硬件错误。比如,你可以查看 dmesg 中是否有硬件 I/O 故障的日志。 还可以使用 badblocks、smartctl 等工具,检测磁盘的硬件问题,或用 e2fsck 等来检测文件系统的错误。如果发现问题,你可以使用 fsck 等工具来修复。


















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











