







从0开始带你成为Kafka消息中间件高手—第五讲
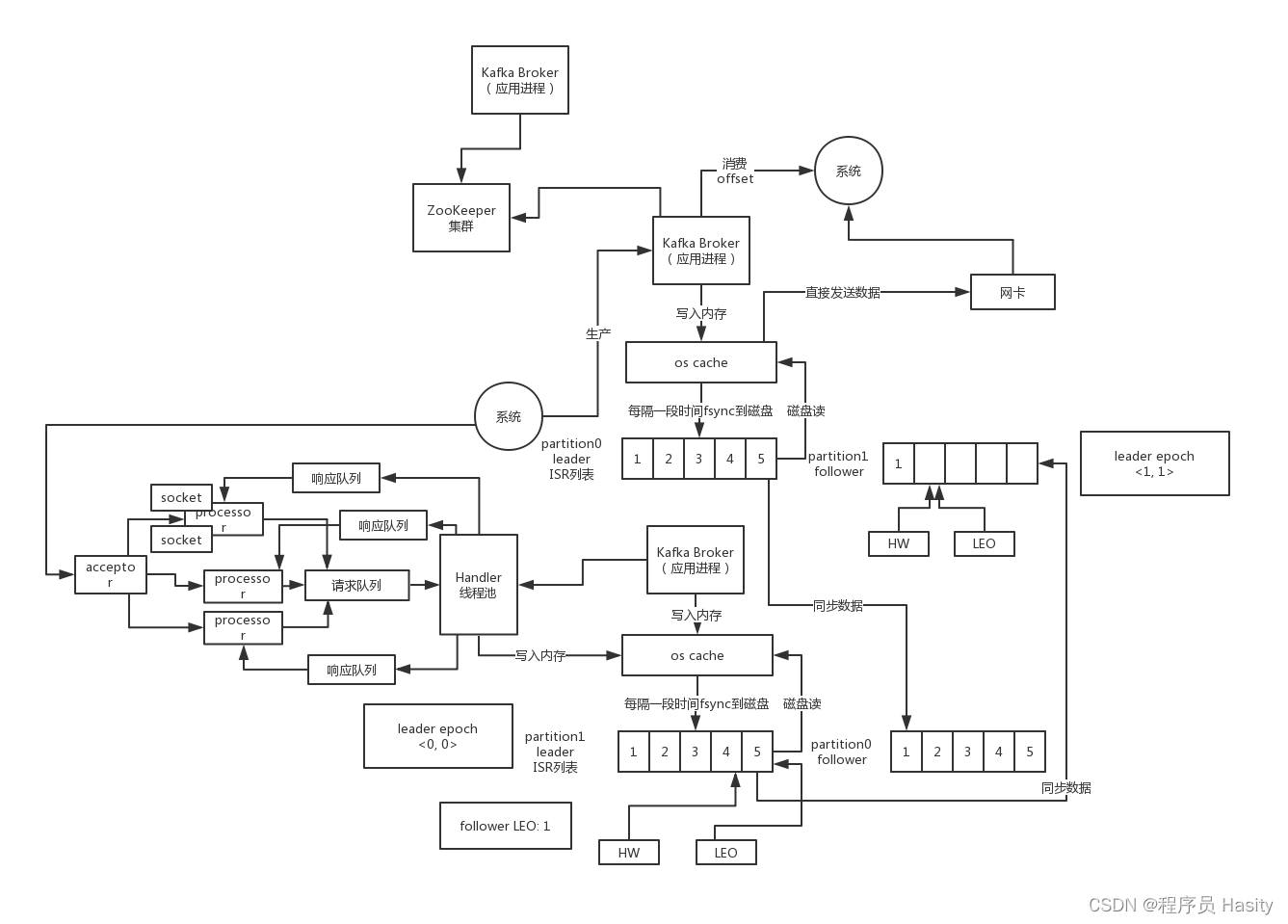
每个broker上都有一个acceptor线程和很多个processor线程,可以用num.network.threads参数设置processor线程的数量,默认是3,client跟一个broker之间只会创建一个socket长连接,他会复用
然后broker就用一个acceptor来监听每个socket连接的接入,分配这个socket连接给一个processor线程,processor线程负责处理这个socket连接,监听socket连接的数据传输以及客户端发送过来的请求,acceptor线程会不停的轮询各个processor来分配接入的socket连接
proessor需要处理多个客户端的socket连接,就是通过java nio的selector多路复用思想来实现的,用一个selector监听各个socket连接,看其是否有请求发送过来,这样一个processor就可以处理多个客户端的socket连接了
processor线程会负责把请求放入一个broker全局唯一的请求队列,默认大小是500,是queued.max.requests参数控制的,所以那几个processor会不停的把请求放入这个请求队列中
接着就是一个KafkaRequestHandler线程池负责不停的从请求队列中获取请求来处理,这个线程池大小默认是8个,由num.io.threads参数来控制,处理完请求后的响应,会放入每个processor自己的响应队列里
每个processor其实就是负责对多个socket连接不停的监听其传入的请求,放入请求队列让KafkaRequestHandler来处理,然后会监听自己的响应队列,把响应拿出来通过socket连接发送回客户端
不知道大家有没有思考过一个问题,就是Kafka集群中某个broker宕机之后,是谁负责感知到他的宕机,以及负责进行Leader Partition的选举?如果你在Kafka集群里新加入了一些机器,此时谁来负责把集群里的数据进行负载均衡的迁移?
包括你的kafka集群的各种元数据,比如说每台机器上有哪些partition,谁是leader,谁是follower,是谁来管理的?如果你要删除一个topic,那么背后的各种partition如何删除,是谁来控制?
还有就是比如kafka集群扩容加入一个新的broker,是谁负责监听这个broker的加入?如果某个broker崩溃了,是谁负责监听这个broker崩溃?
这里就需要一个kafka集群的总控组件,Controller。他负责管理整个kafka集群范围内的各种东西
在kafka集群启动的时候,会自动选举一台broker出来承担controller的责任,然后负责管理整个集群,这个过程就是说集群中每个broker都会尝试在zk上创建一个/controller临时节点
zk的一些基础知识和临时节点是什么,百度一下zookeeper入门
但是zk会保证只有一个人可以创建成功,这个人就是所谓controller角色
一旦controller所在broker宕机了,此时临时节点消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就争抢再次创建临时节点,保证有一台新的broker会成为controller角色
如果你现在创建一个Topic,肯定会分配几个Partition,每个partition还会指定几个副本,这个时候创建的过程中就会在zookeeper中注册对应的topic的元数据,包括他有几个partition,每个partition有几个副本,每个partition副本的状态,此时状态都是:NonExistentReplica
然后Kafka Controller本质其实是会监听zk上的数据变更的,所以此时就会感知到topic变动,接着会从zk中加载所有partition副本到内存里,把这些partition副本状态变更为:NewReplica,然后选择的第一个副本作为leader,其他都是follower,并且把他们都放到partition的ISR列表中
比如说你创建一topic,order_topic,3个partition,每个partition有2个副本,写入zk里去
/topics/order_topic
partitions = 3, replica_factor = 2
[partition0_1, partition0_2]
[partition1_1, partition1_2]
[partition2_1, partition2_2]
从每个parititon的副本列表中取出来第一个作为leader,其他的就是follower,把这些东西给放到partition对应的ISR列表里去
每个partition的副本在哪台机器上呢?会做一个均匀的分配,把partition分散在各个机器上面,通过算法来保证,尽可能把每个leader partition均匀分配在各个机器上,读写请求流量都是打在leader partition上的
同时还会设置整个Partition的状态:OnlinePartition
接着Controller会把这个partition和副本所有的信息(包括谁是leader,谁是follower,ISR列表),都发送给所有broker让他们知晓,在kafka集群里,controller负责集群的整体控制,但是每个broker都有一份元数据
如果你要是删除某个Topic的话,Controller会发送请求给这个Topic所有Partition所在的broker机器,通知设置所有Partition副本的状态为:OfflineReplica,也就是让副本全部下线,接着Controller接续将全部副本状态变为:ReplicaDeletionStarted
然后Controller还要发送请求给broker,把各个partition副本的数据给删了,其实对应的就是删除磁盘上的那些文件,删除成功之后,副本状态变为:ReplicaDeletionSuccessful,接着再变为NonExistentReplica
而且还会设置分区状态为:Offline



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









