






torch.inference_mode()
- 优先使用
inference_mode:
当仅需模型推理(如部署、预测服务、基准测试)且无需修改张量时,优先使用它以获得最佳性能。 - 使用
no_grad:
若需要在推理时临时修改张量(如调试或某些后处理操作),则用no_grad。
| 特性 | torch.inference_mode() | torch.no_grad() |
|---|---|---|
| 梯度计算 | 禁用 | 禁用 |
| 中间张量缓存 | 跳过 | 保留(可能浪费内存) |
| 张量可修改性 | 生成不可变张量(只读) | 允许修改张量 |
| 性能优化 | 更高 | 较低 |
| 适用场景 | 纯推理(如部署、预测) | 推理或需要临时修改张量的场景 |
简介
Q:Question ;A:Answer
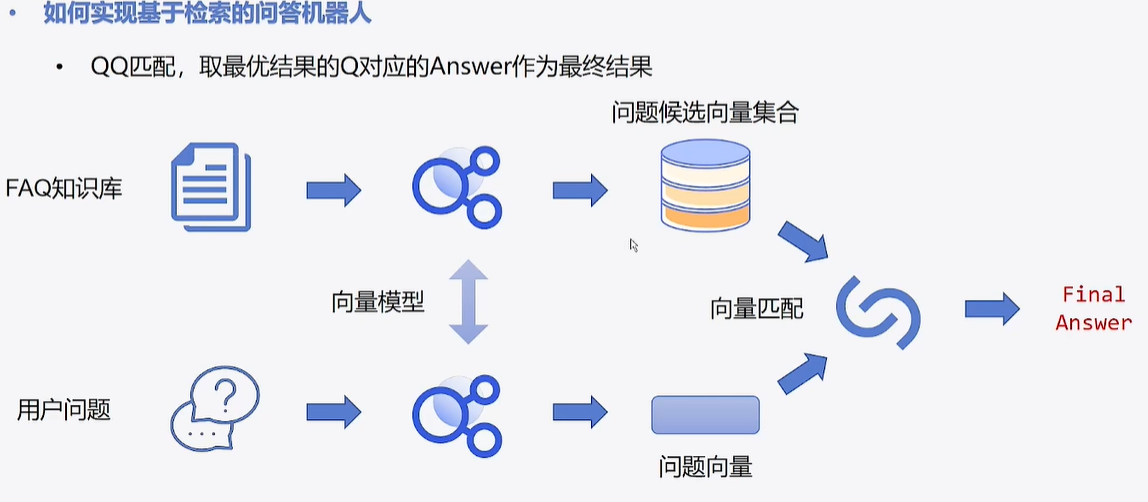
Faiss(Facebook AI Similarity Search)是由Meta(原Facebook)AI团队开发的一个开源库,专门用于高效相似性搜索和稠密向量聚类。它针对高维向量数据进行了高度优化,能够快速在大规模数据集中找到与目标向量最相似的Top-K结果,广泛应用于推荐系统、自然语言处理、图像检索等领域。
## 此处用CPU版本就够。还有gpu版本
pip install faiss-cpu
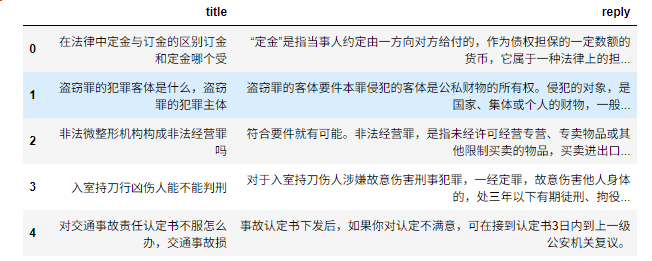
Step1 读取数据
import pandas as pd
data = pd.read_csv("./law_faq.csv")
data.head()
Step2 加载模型
## 此处用的是保存的checkpoint参数,文本相似任务的训练好的dual模型。
from dual_model import DualModel
# 需要完成前置模型训练
dual_model = DualModel.from_pretrained("../12-sentence_similarity/dual_model/checkpoint-500/")
dual_model = dual_model.cuda()
dual_model.eval()
print("匹配模型加载成功!")
from transformers import AutoTokenizer
tokenzier = AutoTokenizer.from_pretrained("hfl/chinese-macbert-base")
tokenzierStep3 将问题编码成向量
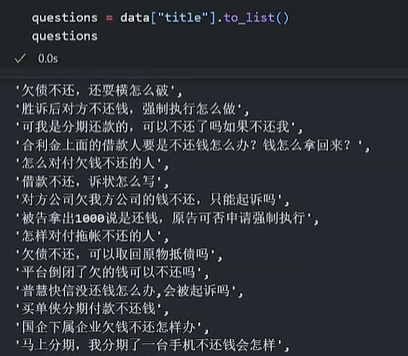
import torch
#进度条
from tqdm import tqdm
questions = data["title"].to_list()
vectors = [] #存储每个Batch数据
with torch.inference_mode():
for i in tqdm(range(0, len(questions), 32)):#BatchSize=32
batch_sens = questions[i: i + 32] #一次取一个Batch
inputs = tokenzier(batch_sens, return_tensors="pt", padding=True, max_length=128, truncation=True)
inputs = {k: v.to(dual_model.device) for k, v in inputs.items()}
vector = dual_model.bert(**inputs)[1]
vectors.append(vector)
vectors = torch.concat(vectors, dim=0).cpu().numpy()
vectors.shape #(18213,768),18213条数据,每个问题向量768Step4 创建索引
通过faiss 创建索引,把vector存起来,方便计算余弦
import faiss
index = faiss.IndexFlatIP(768) #向量长度
faiss.normalize_L2(vectors) #标准化,否则无法计算cos
index.add(vectors)
indexStep5 对问题进行向量编码
quesiton = "寻衅滋事"
with torch.inference_mode():
inputs = tokenzier(quesiton, return_tensors="pt", padding=True, max_length=128, truncation=True)
inputs = {k: v.to(dual_model.device) for k, v in inputs.items()}
vector = dual_model.bert(**inputs)[1]
q_vector = vector.cpu().numpy()
q_vector.shape # (1,768)Step6 向量匹配
index.search(q_vector,1)
Output:
# topk_result 每个个元素就是reply;此处方便查看,因此只选择第0
faiss.normalize_L2(q_vector)
scores, indexes = index.search(q_vector, 10)#查找top10
topk_result = data.values[indexes[0].tolist()]
topk_result[:, 0] # topk_result 每个个元素就是[titile,reply];
Step7 加载交互模型
# 通过Step6,召回QA对后,再对用户问题进行编码;
# 然后将QA对 和 用户问题 输入匹配交互模型,再取最终结果。
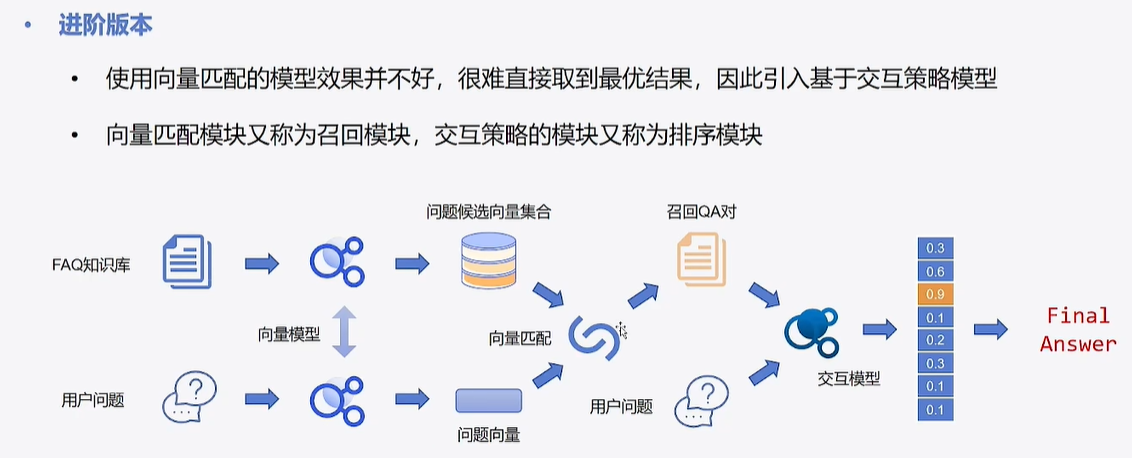
## 同样要用前面 训练好的cross模型checkpoint。
from transformers import BertForSequenceClassification
# 需要完成前置模型训练
corss_model = BertForSequenceClassification.from_pretrained("../12-sentence_similarity/cross_model/checkpoint-500/")
corss_model = corss_model.cuda()
corss_model.eval()
print("模型加载成功!")Step8 最终预测
首先把 topk_result 的title和 用户question 组成一对一;
# QA和用户问题配对 canidate = topk_result[:, 0].tolist() ques = [quesiton] * len(canidate) inputs = tokenzier(ques, canidate, return_tensors="pt", padding=True, max_length=128, truncation=True) inputs = {k: v.to(corss_model.device) for k, v in inputs.items()} with torch.inference_mode(): logits = corss_model(**inputs).logits.squeeze() result = torch.argmax(logits, dim=-1)#取最优结果索引 result #取出 reply canidate_answer = topk_result[:, 1].tolist() match_quesiton = canidate[result.item()] final_answer = canidate_answer[result.item()] match_quesiton, final_answer



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









