






简介
基本使用
Hugging Face – The AI community building the future.
加载在线数据集
# 和加载Model类似
from datasets import *
datasets = load_dataset("madao33/new-title-chinese")
datasetsa加载数据合集中某一项任务
# glue包含了多种任务;下面就是取的boolq任务
boolq_dataset = load_dataset("super_glue", "boolq")
boolq_dataset按照数据集划分进行加载
只加载训练集(测试集) or 训练集某一部分
#加载训练集 测试集validation
dataset = load_dataset("madao33/new-title-chinese", split="train")
dataset = load_dataset("madao33/new-title-chinese", split="validation")
dataset
#10~100条
dataset = load_dataset("madao33/new-title-chinese", split="train[10:100]")
dataset
#加载一半
dataset = load_dataset("madao33/new-title-chinese", split="train[:50%]")#
dataset
#加载 训练集前50%,验证集前10%
dataset = load_dataset("madao33/new-title-chinese", split=["train[:50%]", "validation[10%:]"])
dataset
#对训练集 前后50%,分俩次加载
dataset = load_dataset("madao33/new-title-chinese", split=["train[:50%]", "train[50%:]"])
dataset查看数据集
datasets = load_dataset("madao33/new-title-chinese")
datasets
datasets["train"][0] #训练集 第0条
datasets["train"][:2] #切片取法
datasets["train"]["title"][:5] #取 某字段 前五条
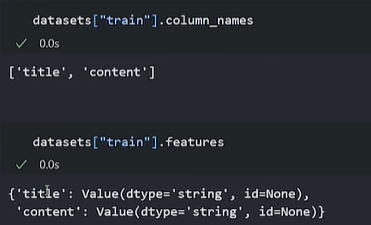
datasets["train"].column_names #取 列名
datasets["train"].features #各列特征## 返回的是个dict

## 列名及列名特征
数据划分
## stratify_by_column="label" 通过stratify_by_column指出标签字段,进行均衡采样
#直接指定 test_size划分
dataset = datasets["train"]
dataset.train_test_split(test_size=0.1)
# 分类数据集可以按照比例划分(标签均衡采样)
dataset = boolq_dataset["train"]
dataset.train_test_split(test_size=0.1, stratify_by_column="label") 数据选取与过滤
## 通过datasets['train'].select指定 索引 选取数据
## 通过datasets['train'].filter( lambda x : ) 过滤数据。返回还是一个Dataset。
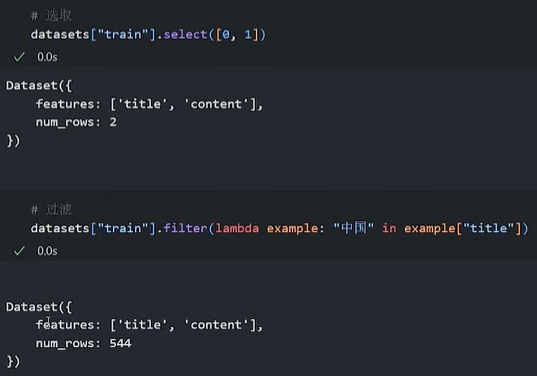
# 选取 第0、1条
datasets["train"].select([0, 1])
# 过滤
filter_dataset = datasets["train"].filter(lambda example: "中国" in example["title"])select及filter 和 上述直接 datasets['train'][ idx ] 的结果不一样。返回还是一个Dataset。
数据映射
datasets.map 类似 pandas.apply 可以调用函数对数据处理
def add_prefix(example):
example["title"] = 'Prefix: ' + example["title"]
return example
prefix_dataset = datasets.map(add_prefix)
prefix_dataset["train"][:10]["title"]OUTPUT

通过映射进行预处理
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
def preprocess_function(example, tokenizer=tokenizer):
model_inputs = tokenizer(example["content"]
, max_length=512, truncation=True)
labels = tokenizer(example["title"]
, max_length=32, truncation=True)
# label就是title编码的结果
model_inputs["labels"] = labels["input_ids"]
return model_inputs
processed_datasets = datasets.map(preprocess_function)
processed_datasetsOUTPUT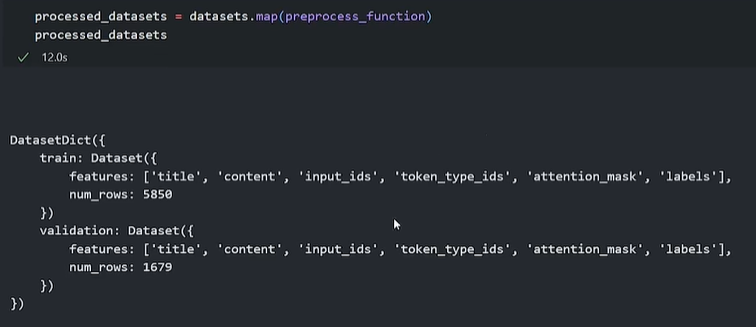
批处理、多线程、字段删除
## 支持fast_tokenizer,可以通过batched=True,批量处理加快速度
processed_datasets = datasets.map(preprocess_function, batched=True)
processed_datasets
## 不支持fast时,可以通过num_proc=4,多线程处理
processed_datasets = datasets.map(preprocess_function, num_proc=4)
processed_datasets
## 删除不需要的字段。remove_columns=【字段名,字段名】
processed_datasets = datasets.map(preprocess_function, batched=True, remove_columns=datasets["train"].column_names)
processed_datasets数据保存与加载
processed_datasets.save_to_disk("./processed_data")
processed_datasets = load_from_disk("./processed_data")
processed_datasets #和前面一样本地数据集
load_dataset(参1:文件类型,参2:文件路径,参3:划分给什么数据集)
与在线加载不同,就是参1。
dataset = load_dataset("csv"
, data_files="./ChnSentiCorp_htl_all.csv", split="train")
dataset
#和上述相同
dataset = Dataset.from_csv("./ChnSentiCorp_htl_all.csv")
dataset左:无参split;右:含参split。区别在于,无参会多套一层dict。
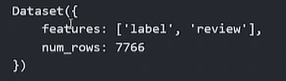
## 下面是通过给 文件路径列表,同时加载多个文件
dataset = load_dataset("csv"
, data_files=["./all_data/ChnSentiCorp_htl_all.csv"
, "./all_data/ChnSentiCorp_htl_all copy.csv"]
, split='train')
dataset加载文件夹内全部文件
# 通过给定 data_dir参数,加载文件夹下所有文件。
dataset = load_dataset("csv", data_dir='./all_data/', split='train')
dataset其他方式(Pandas)加载数据
可以通过Pandas读取数据后,使用Dataset.from_pandas,转换。
不止Pandas,还有多种,可以通过Dataset.from_xxx进行查看。
List格式的数据,要内嵌进dict,类似list转Pandas。
import pandas as pd
data = pd.read_csv("./ChnSentiCorp_htl_all.csv")
data.head()
dataset = Dataset.from_pandas(data)
dataset
# List格式的数据需要内嵌{},明确数据字段
data = [{"text": "abc"}, {"text": "def"}]
# data = ["abc", "def"] #这种就无法转换
Dataset.from_list(data)
自定义脚本加载
遇到复杂格式数据,可以通过自定义脚本加载。
下文中的json的paragraphs就包含多个字段(如左);直接load无法获取其子字段(如右)。
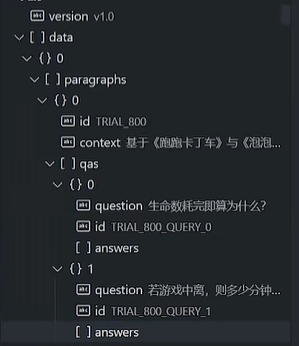
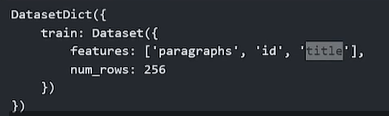
## 通过自定义脚本加载
## field指定数据在 data字段里
load_dataset("json", data_files="./cmrc2018_trial.json", field="data")
dataset = load_dataset("./load_script.py", split="train")
datasetOUTPUT
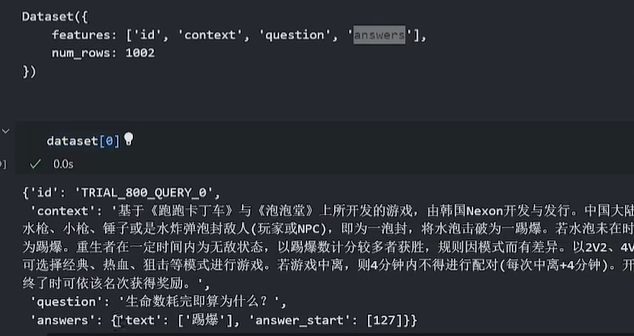
加载脚本load_script.py
首先 _info 定义数据集的特征,dataset.Features。
其次 _split_generators
_generate_examples 即 读取文件、并按格式和需求拆解字段;并返回和_info定义的相同格式数据
import json
import datasets
from datasets import DownloadManager, DatasetInfo
class CMRC2018TRIAL(datasets.GeneratorBasedBuilder):
def _info(self) -> DatasetInfo:
"""
info方法, 定义数据集的信息,这里要对数据的字段进行定义
:return:
"""
return datasets.DatasetInfo(
description="CMRC2018 trial",
features=datasets.Features({
"id": datasets.Value("string"),
"context": datasets.Value("string"),
"question": datasets.Value("string"),
"answers": datasets.features.Sequence(
{
"text": datasets.Value("string"),
"answer_start": datasets.Value("int32"),
}
)
})
)
def _split_generators(self, dl_manager: DownloadManager):
"""
返回datasets.SplitGenerator
涉及两个参数: name和gen_kwargs
name: 指定数据集的划分
gen_kwargs: 指定要读取的文件的路径, 与_generate_examples的入参数一致
:param dl_manager:
:return: [ datasets.SplitGenerator ]
"""
return [datasets.SplitGenerator(name=datasets.Split.TRAIN,
gen_kwargs={"filepath": "./cmrc2018_trial.json"})]
def _generate_examples(self, filepath):
"""
生成具体的样本, 使用yield
需要额外指定key, id从0开始自增就可以
:param filepath:
:return:
"""
# Yields (key, example) tuples from the dataset
with open(filepath, encoding="utf-8") as f:
data = json.load(f)
for example in data["data"]:
for paragraph in example["paragraphs"]:
context = paragraph["context"].strip()
for qa in paragraph["qas"]:
question = qa["question"].strip()
id_ = qa["id"]
answer_starts = [answer["answer_start"] for answer in qa["answers"]]
answers = [answer["text"].strip() for answer in qa["answers"]]
yield id_, {
"context": context,
"question": question,
"id": id_,
"answers": {
"answer_start": answer_starts,
"text": answers,
},
}

















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









