







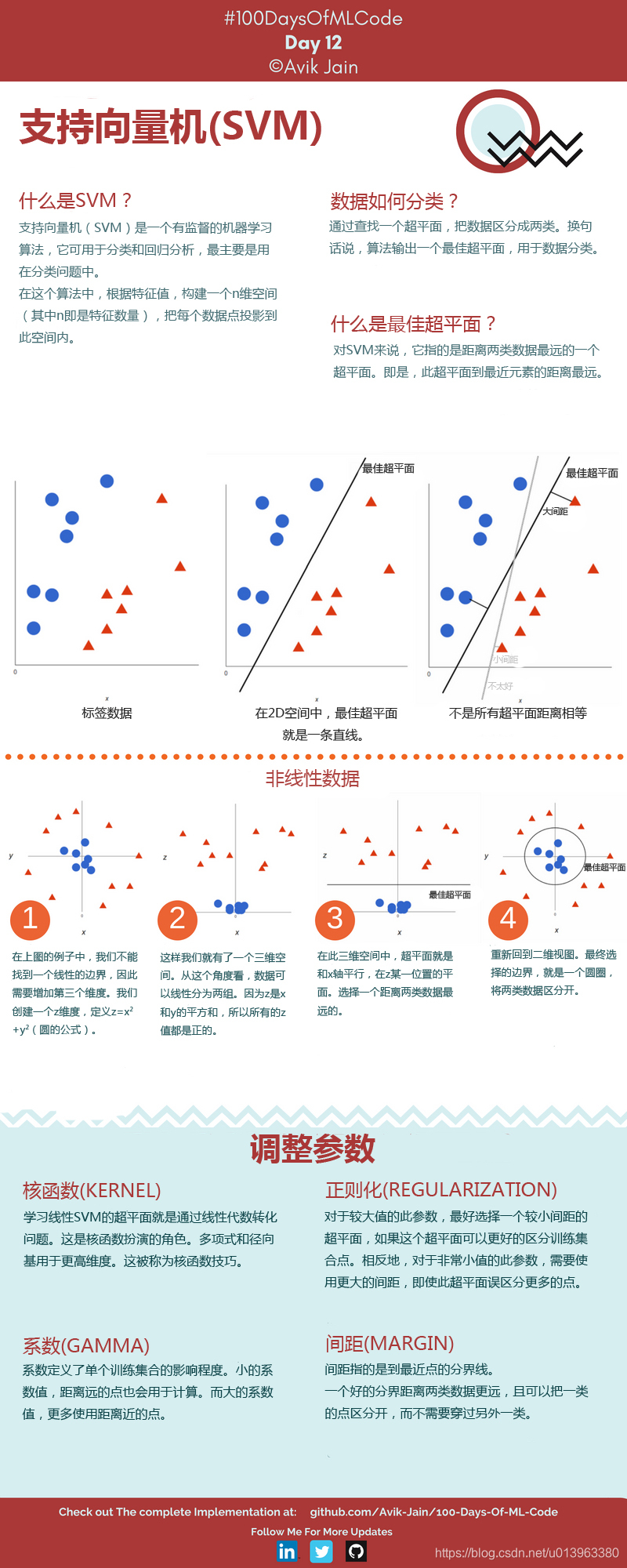
 SVM是一种二分类模型,旨在找到最佳超平面以最大化分类间隔。本文通过简单实例和可视化解释了SVM的基本概念,包括支持向量、间隔和超平面的选择标准。强调了大间隔的分类效果更好且更鲁棒。
SVM是一种二分类模型,旨在找到最佳超平面以最大化分类间隔。本文通过简单实例和可视化解释了SVM的基本概念,包括支持向量、间隔和超平面的选择标准。强调了大间隔的分类效果更好且更鲁棒。
大家好 我是小k 在学到这篇文章前 我曾在b站上看过菜菜的SVM课程 第一遍全程下来 基本上上最深的记忆点就是 SVM有三层理解 我们在课上能理解第一层就很不错了 而且SVM数学原理推理十分的困难 数学不好的小白是很难看懂的 我怀着敬畏心听完了后 好家伙 果然不出所料 只听了个大概 今天结合阅读了一些文章 做一些对SVM浅层总结
SVM和其基本概念:
svm是一种二分类模型,svm的主要目的就是要画出一条线 一更好的区分两类点 SVM 适合中小型数据样本、非线性、高维的分类问题。
Q1:能够画出多少条线对样本点进行区分?
答:线是有无数条可以画的,区别就在于效果好不好,每条线都可以叫做一个划分超平面。比如上面的绿线就不好,蓝线还凑合,红线看起来就比较好。我们所希望找到的这条效果最好的线就是具有 “最大间隔的划分超平面”。
Q2:为什么要叫作“超平面”呢?
答:因为样本的特征很可能是高维的,此时样本空间的划分就不是一条线了。
Q3:画线的标准是什么?/ 什么才叫这条线的效果好?/ 哪里好?
答:SVM 将会寻找可以区分两个类别并且能使间隔(margin)最大的划分超平面。比较好的划分超平面,样本局部扰动时对它的影响最小、产生的分类结果最鲁棒、对未见示例的泛化能力最强。
Q4:间隔(margin)是什么?
答:对于任意一个超平面,其两侧数据点都距离它有一个最小距离(垂直距离),这两个最小距离的和就是间隔。比如下图中两条虚线构成的带状区域就是 margin,虚线是由距离中央实线最近的两个点所确定出来的(也就是由支持向量决定)。但此时 margin 比较小,如果用第二种方式画,margin 明显变大也更接近我们的目标。
Q5:为什么要让 margin 尽量大?
答:因为大 margin 犯错的几率比较小,也就是更棒啦。

Q6:支持向量是什么?
答:从上图可以看出,虚线上的点到划分超平面的距离都是一样的,实际上只有这几个点共同确定了超平面的位置,因此被称作 “支持向量(support vectors)”,“支持向量机” 也是由此来的。
Q1-Q6 -> 原文链接:https://blog.youkuaiyun.com/qq_31347869/article/details/88071930
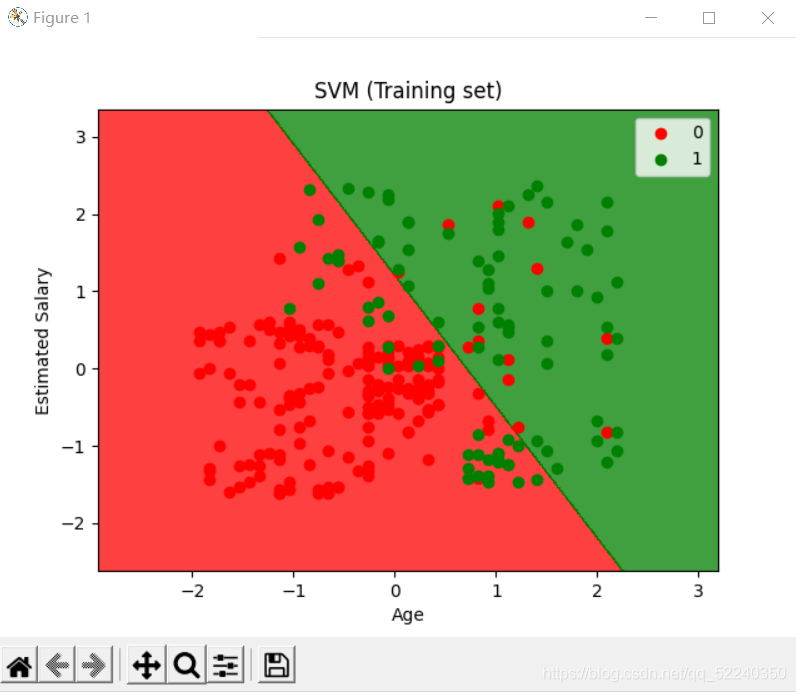
本文将会举个很简单的小例子 数据集和day4 day5一模一样 做是否购买的二分类 由于代码与前两天代码差距不大 这里我就一次性直接展示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv(r'D:\python\100daysdata\Social_Network_Ads.csv')
x = data.iloc[:,[2,3]].values
y = data.iloc[:,4].values
print(x[0])
print(y[0])
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=1314)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.fit_transform(x_test)
from sklearn.svm import SVC
classifier = SVC(kernel='linear',random_state=1314)
classifier.fit(x_train,y_train)
y_pred = classifier.predict(x_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy = (cm[0][0]+cm[0][1])/(cm[0][0]+cm[0][1]+cm[1][0]+cm[1][1])
print(accuracy)
//图像可视化
from matplotlib.colors import ListedColormap
X_set, Y_set = x_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(Y_set)):
plt.scatter(X_set[Y_set == j, 0], X_set[Y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('SVM (Training set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()附一张可视化图片:

















 7385
7385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









