







任务需求:
爬取一个网址,将网址的数据保存到csv中。
爬取网址:
https://www.iqiyi.com/ranks1/1/0?vfrm=pcw_home&vfrmblk=&vfrmrst=712211_dianyingbang_rebo_title网址页面:
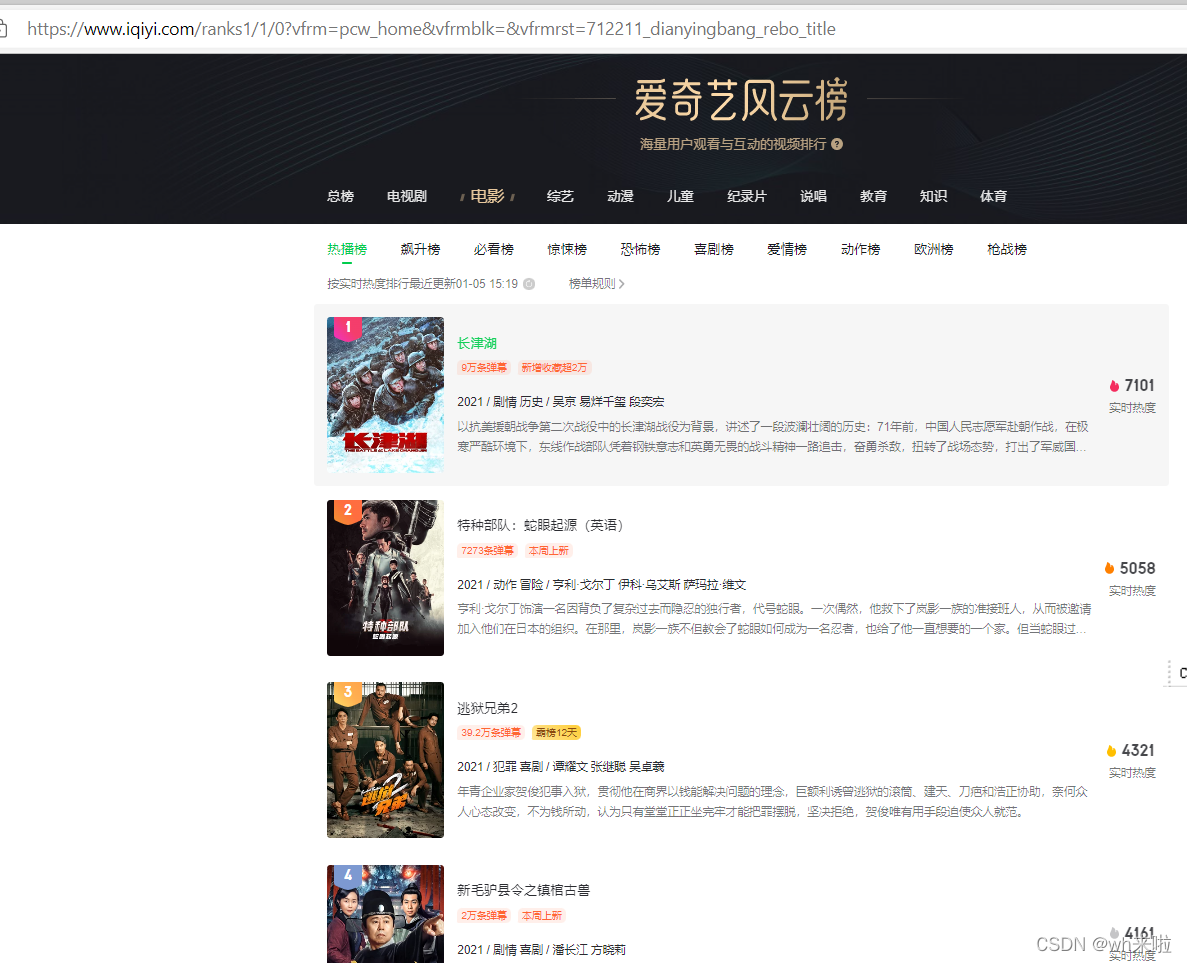
代码实现结果:
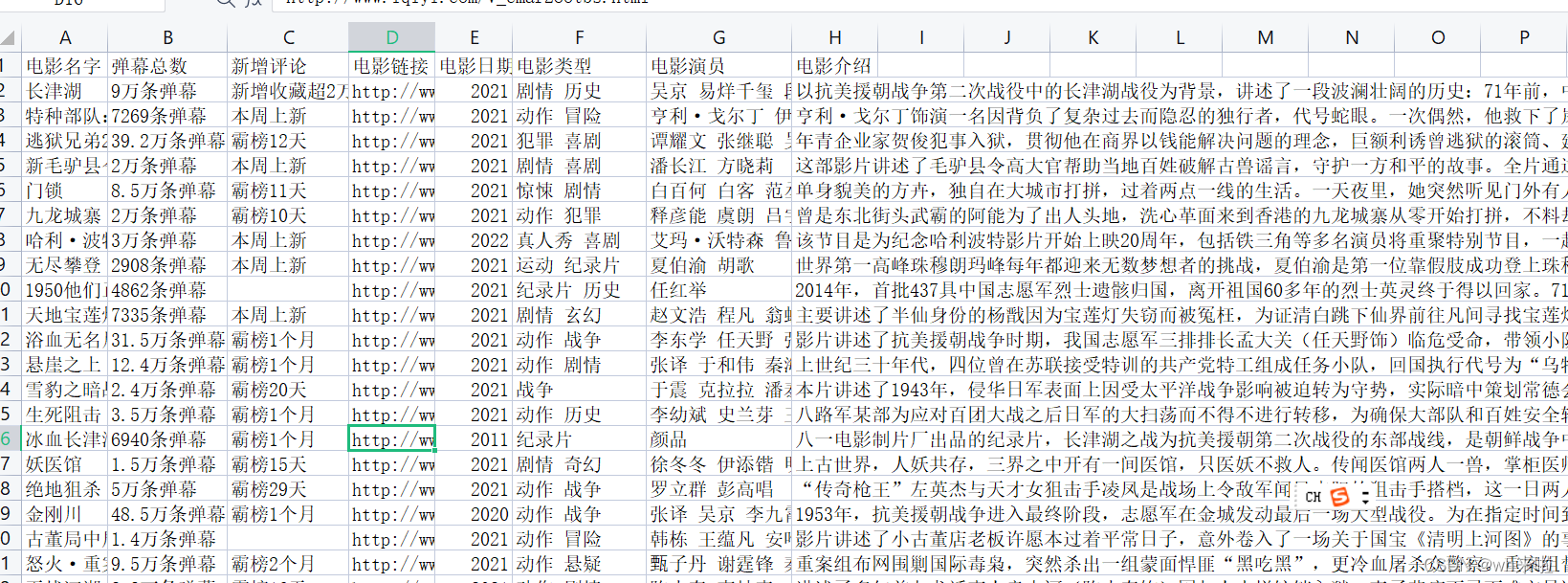
代码实现:
导入包:
import requests
import parsel
import csv设置csv文件格式:
设计未来数据的存储形式。
#打开文件
f = open('whxixi.csv', mode='a',encoding='utf-8',newline='')
#文件列名
csv_writer= csv.DictWriter(f,fieldnames=['电影名字',
'弹幕总数',
'新增评论',
'电影链接',
'电影日期',
'电影类型',
& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









