







5.ES的核心概念
- 索引
- 字段类型(mapping)
- 文档(documents)
5.1关系行数据库和elasticsearch客观的对比
在前面的学习中,我们已经掌握了es是什么,同时也把es的服务已经安装启动,那么es是如何去存储数据,数据结构是什么,又是如何实现搜索的呢?
我们先来聊聊ElasticSearch的相关概念吧!

elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
5.2物理设计
elasticsearch在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移!
一个人就是一个集群!默认的集群名elasticsearch
5.3逻辑设计
一个索引类型中,包含多个文档,比如说文档1、文档2。当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引>类型>文档ID,通过这个组合我们就能索引到某个具体的文档。
注意:ID不必是整数,实际上它是个字符串。
1. 文档 之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性: 自我包含:一篇文档同时包含字段和对应的值,也就是同时包含 key:value! 可以是层次型的:一个文档中包含自文档,复杂的逻辑实体就是这么来的!(就是一个json对象,fastjson进行自动转换) 灵活的结构:文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。 尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。 2. 类型 类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢? elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么么蛾子。 3. 索引(就是数据库) 索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
5.4节点和分片如何工作
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片(primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)
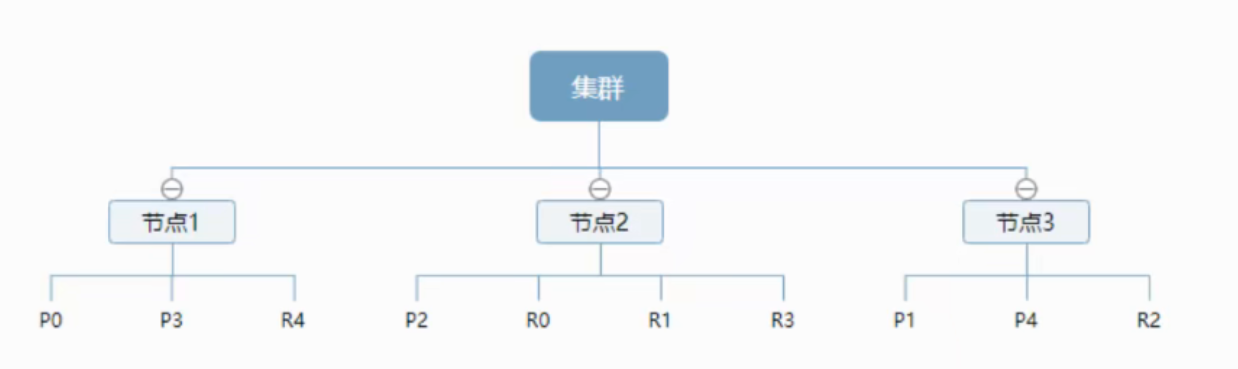
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
5.5倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。例如,现在有两个文档,每个文档包含如下内容:
study every day,good good up to forever #文档1包含的内容
To forever,study every day,good good up #文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
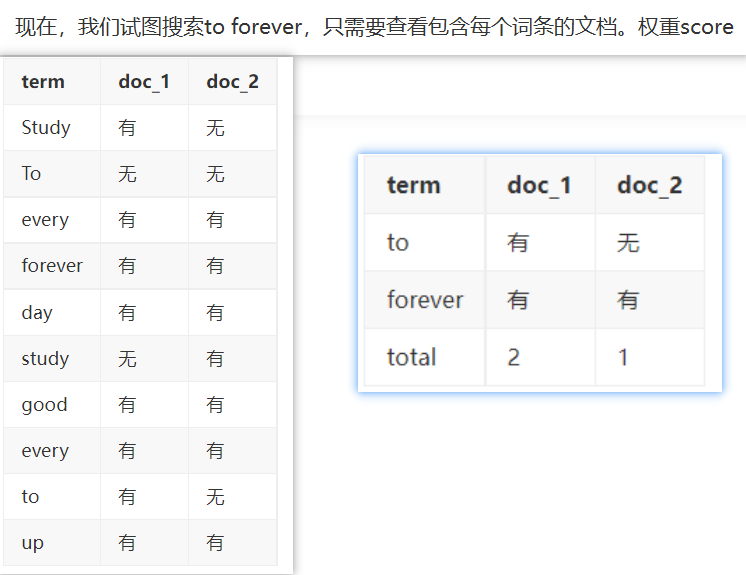
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
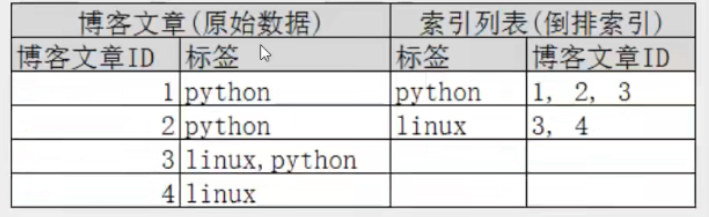 如果要搜索含有 python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。
如果要搜索含有 python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。
elasticsearch的索引和Lucene的索引对比:
在elasticsearch中,索引这个词被频繁使用,这就是术语的使用。在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!
如无特指,说起索引都是指elasticsearch的索引。
接下来的一切操作都在kibana中Dev Tools下的Console里完成。基础操作!
6.IK分词器插件
6.1概念
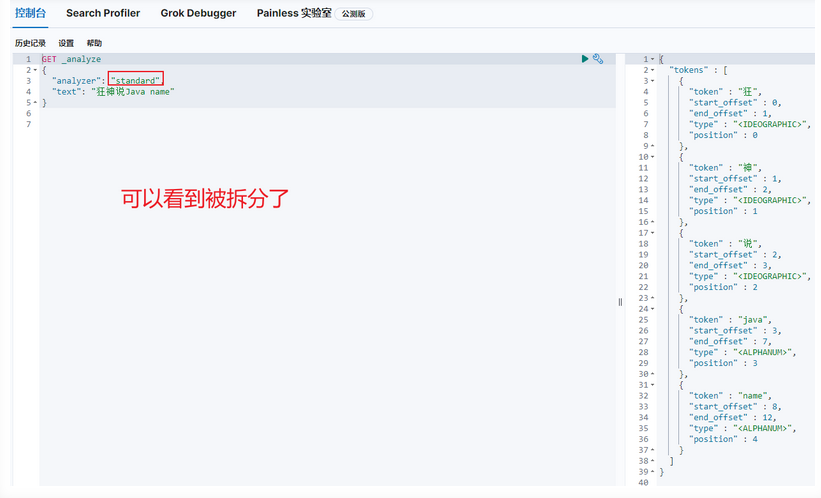
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱宝贝”会被分为“我””爱”,“宝”,”贝”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
ik提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分!一会我们测试!
如果要使用中文,建议使用IK分词器
6.2IK的安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载完成之后,解压放在elasticsearch的plugins文件下
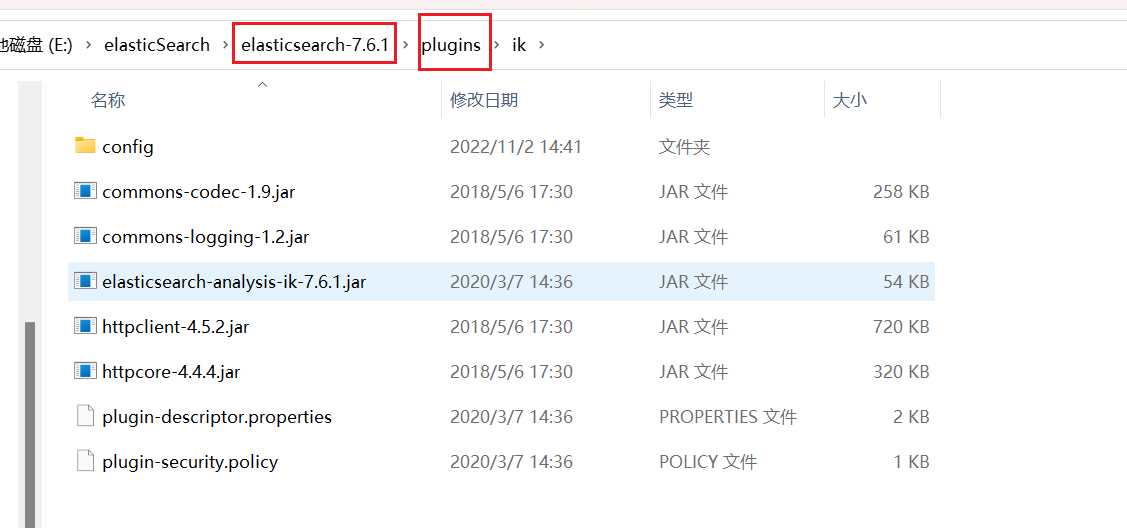 重新启动elasticsearch
重新启动elasticsearch

6.3使用kibana测试
其中ik_smart为最少切分
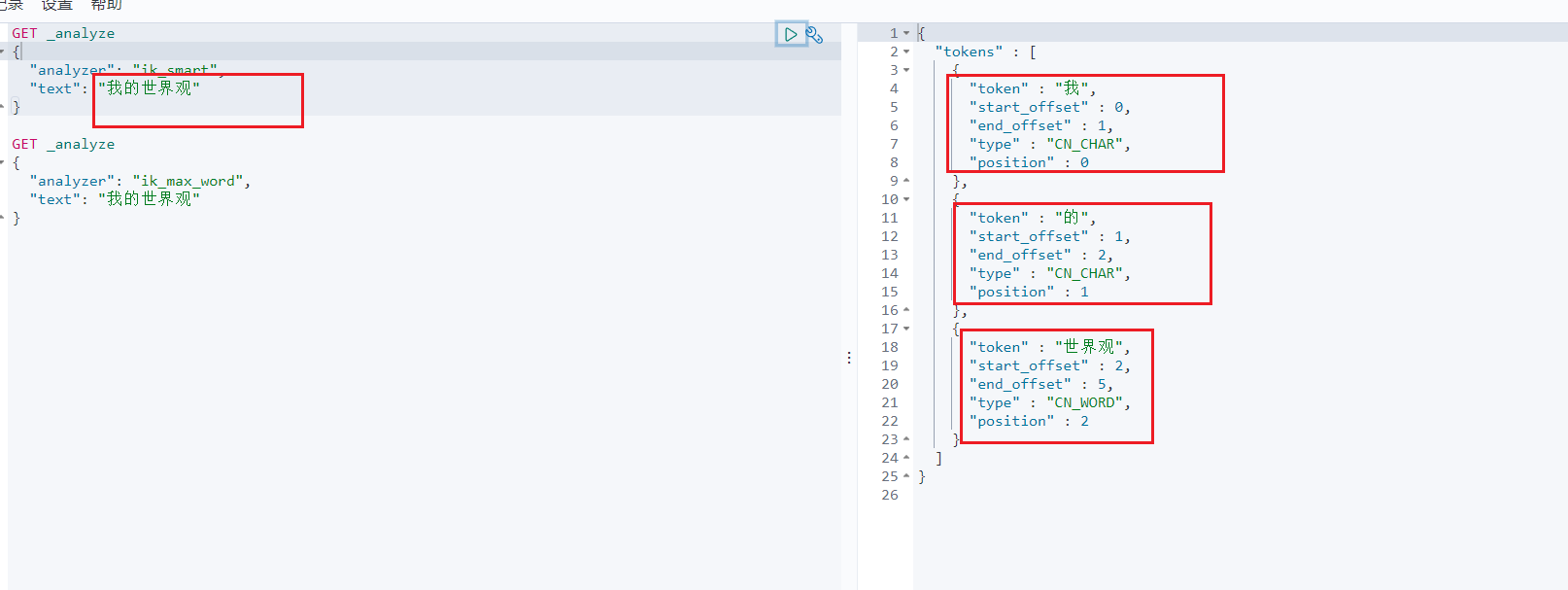
ik_max_word为最细粒度划分(穷尽词库)
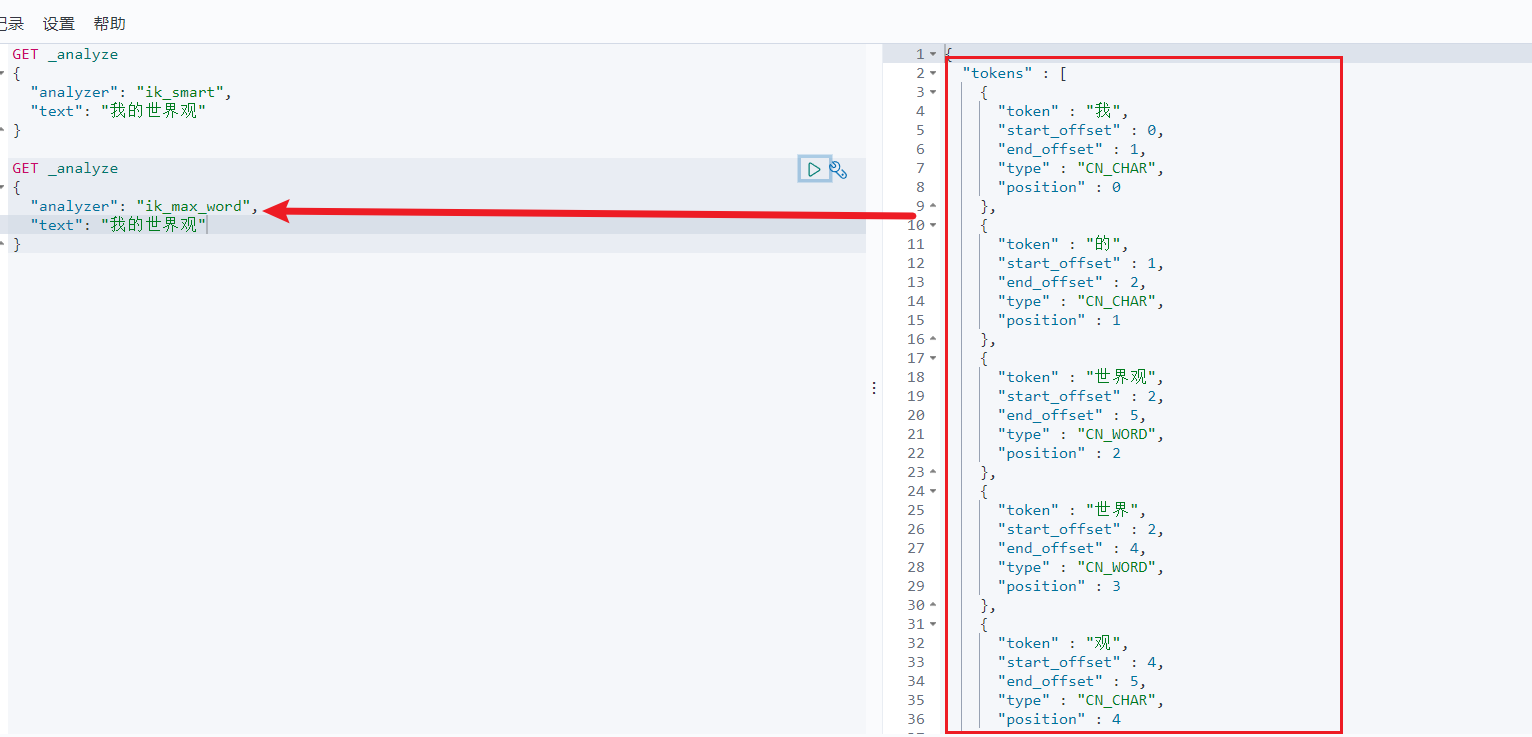
当我们输入”我的世界观”,发现问题:我的世界观,被拆开了。
这种自己需要的词,需要自己加到我们的分词器的字典中。
6.4ik分词器增加自己的配置
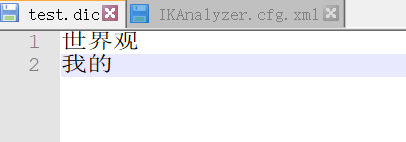

重启kibana
再次测试下,输入”我的世界观”,看下效果
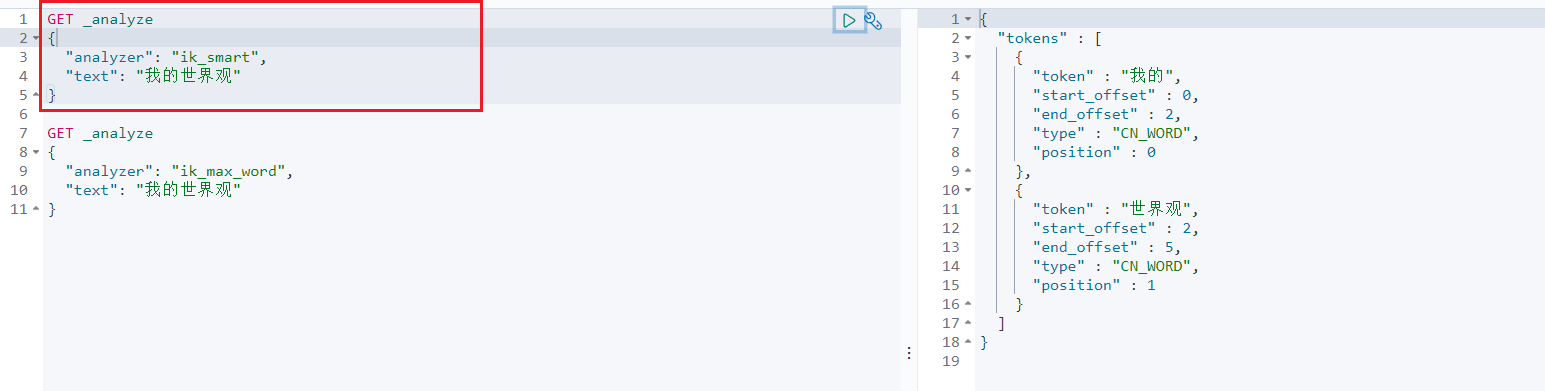
以后的话,我们需要自己配置分词就在自己定义的dic文件中进行配置即可!
7.restful风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
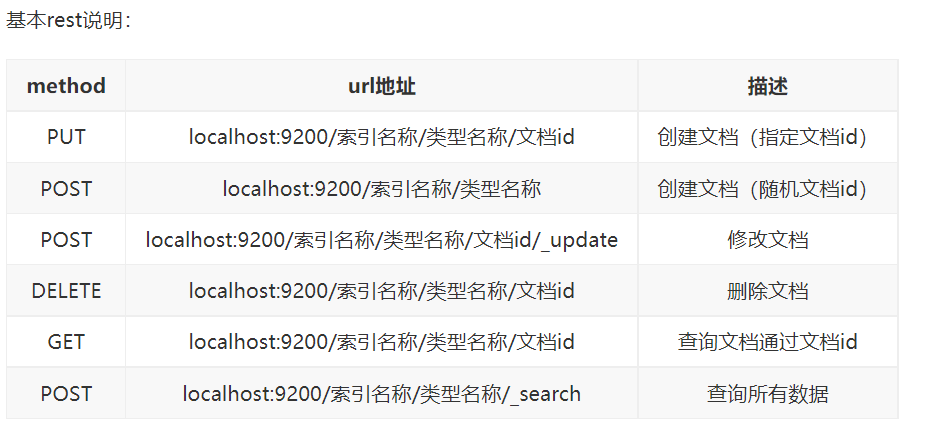
7.1关于索引的基本操作
创建一个索引
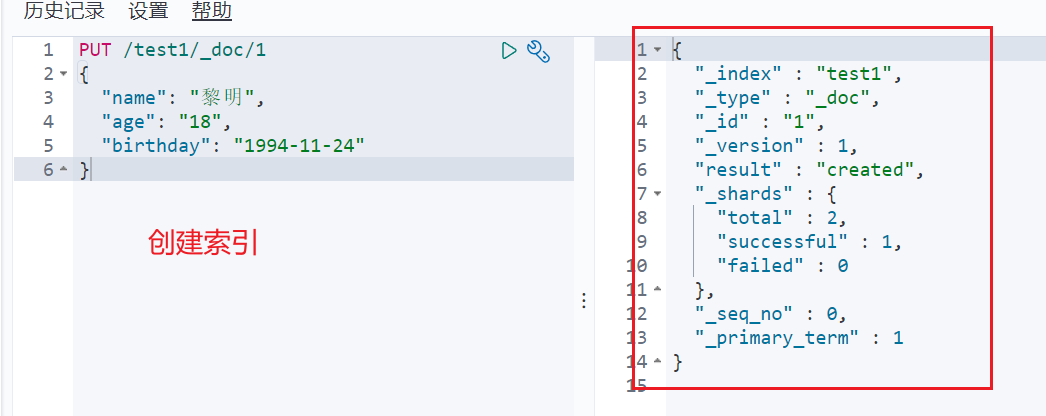 name这个字段需要指定类型吗?需要(毕竟我们关系型数据库是需要指定类型的)
name这个字段需要指定类型吗?需要(毕竟我们关系型数据库是需要指定类型的)

7.2指定字段类型
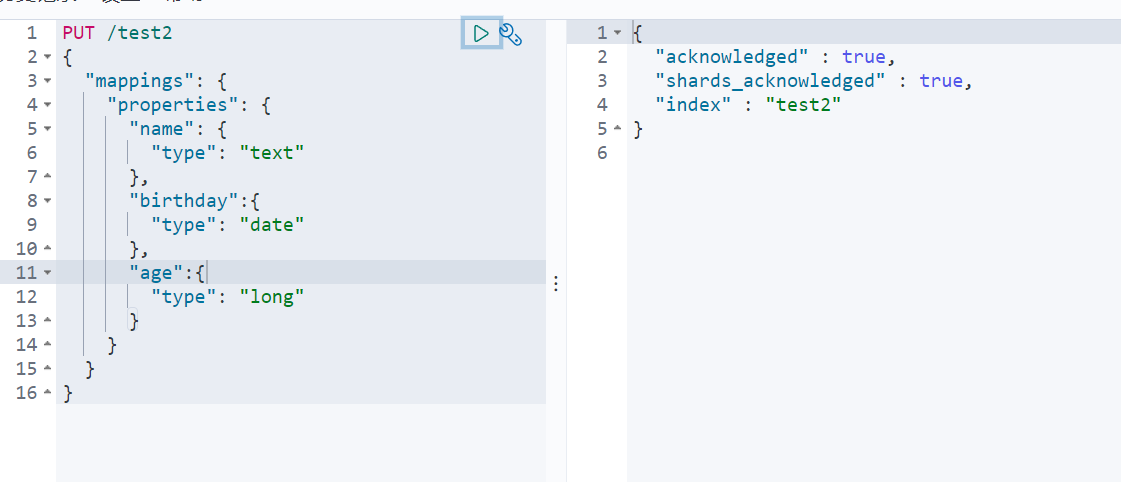
7.3获得这个规则(可以通过GET请求获取具体的信息)
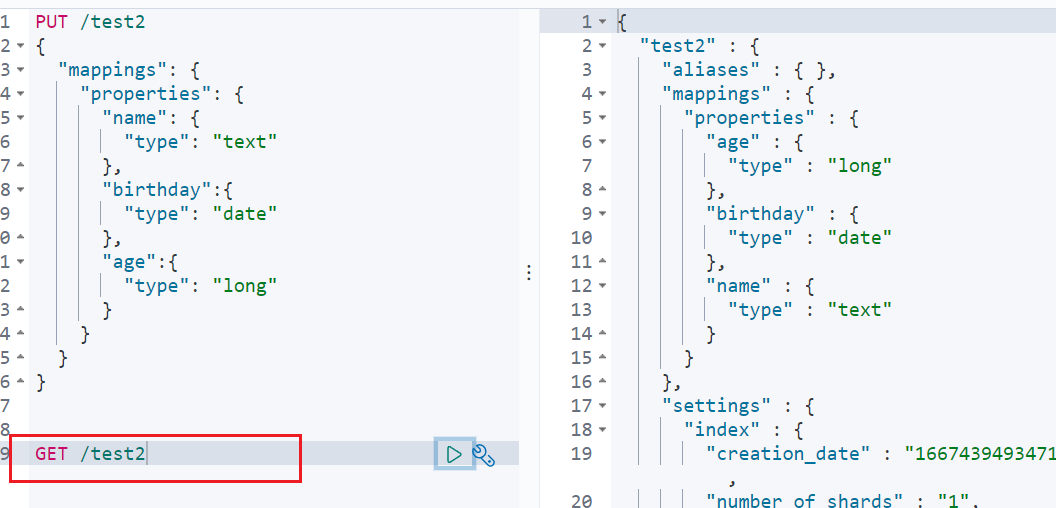
7.4查看默认信息
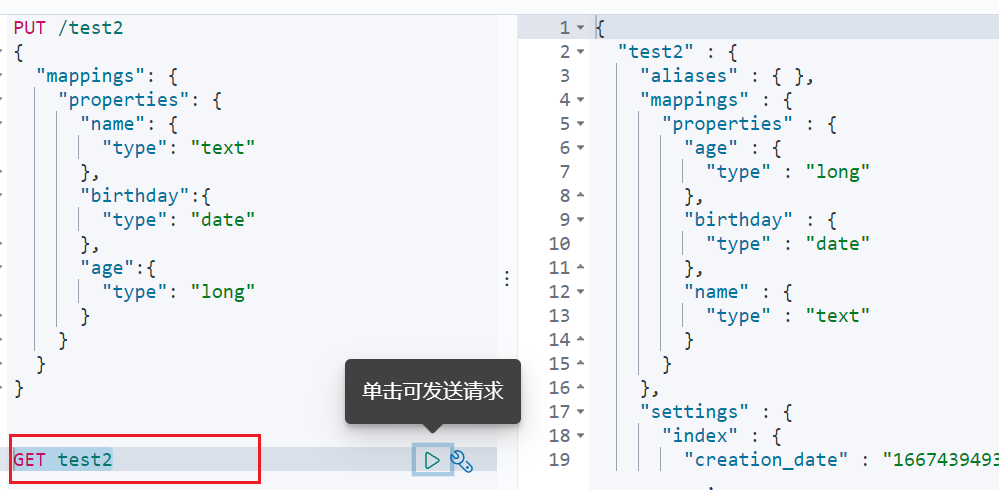 如果自己的文档字段没有指定,那么es就会给我们默认配置字段类型!
如果自己的文档字段没有指定,那么es就会给我们默认配置字段类型!
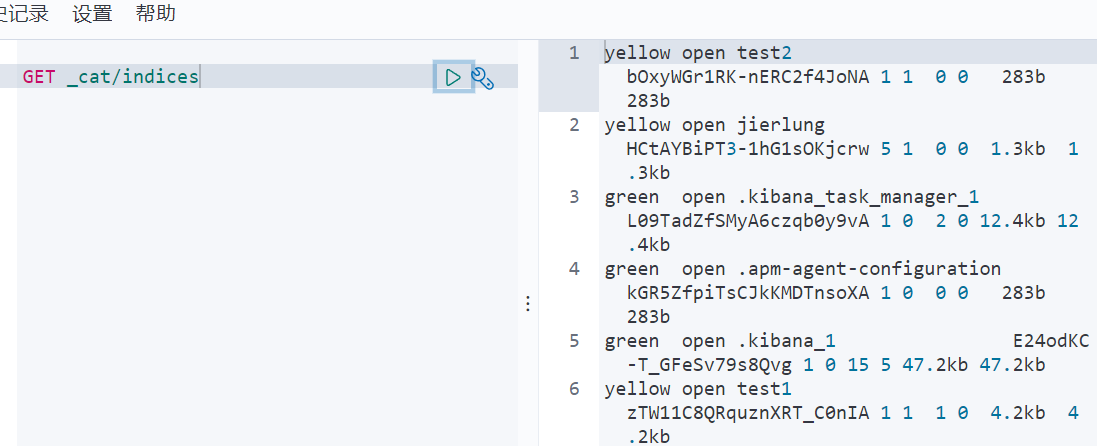
扩展:通过命令elasticsearch索引情况!(通过get_cat/可以获得es的当前的很多信息!)
GET _cat/health # 查看健康值

GET _cat/indices?v #查看所有东西的版本信息
7.5修改
提交,使用PUT,覆盖(弊端:如果漏掉一个字段,那么字段的值就没了)
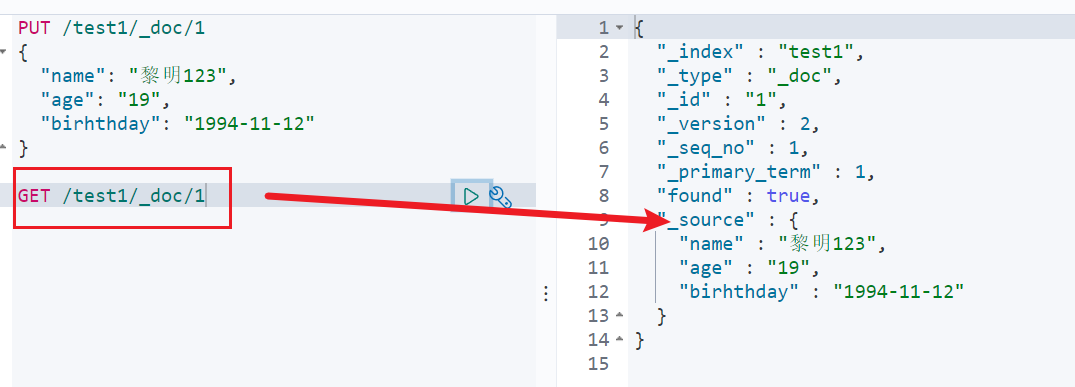
新的修改方法:使用post提交(7.x.x版本和8.x.x版本提交方式不一样)
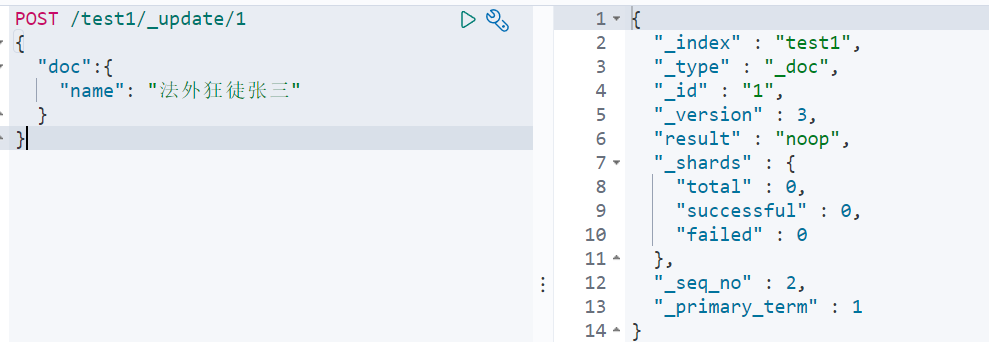
7.6删除
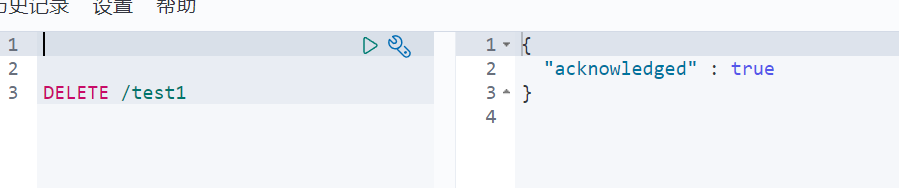
通过DELETE命令实现删除、根据你的请求来判断是删除索引还是删除文档记录!
使用RESTFUL风格是我们ES推荐大家使用的!
7.7基本操作(增删改查回顾)
7.7.1添加数据

7.7.2查询数据

7.7.3更新 PUT

7.7.4更新 POST

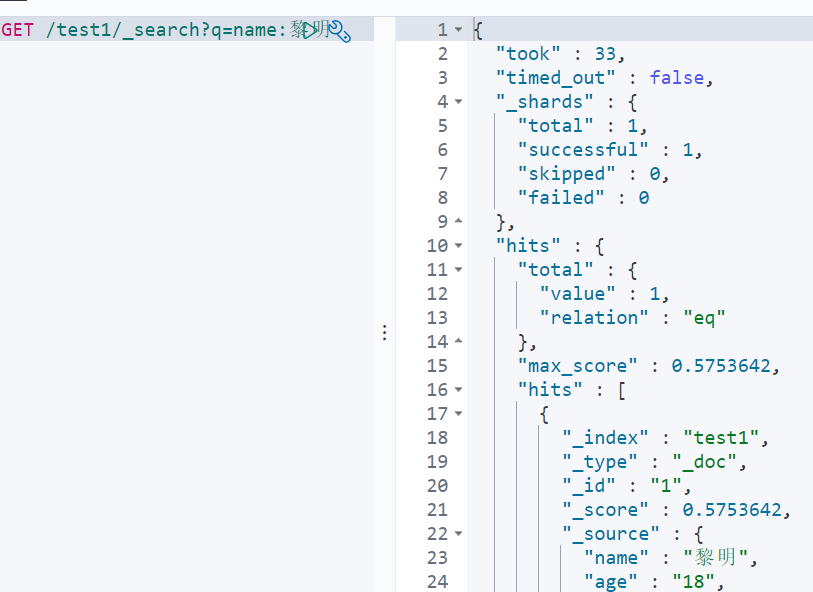
7.7.5简单操作(条件查询)
// 支持模糊查询 GET /kuangshen/_search?q=name:狂神说
7.7.6复杂操作(查询select:排序,分页,高亮,模糊查询,精准查询)
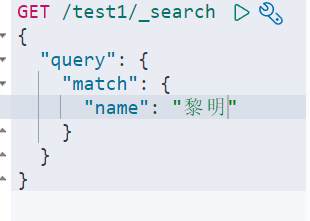
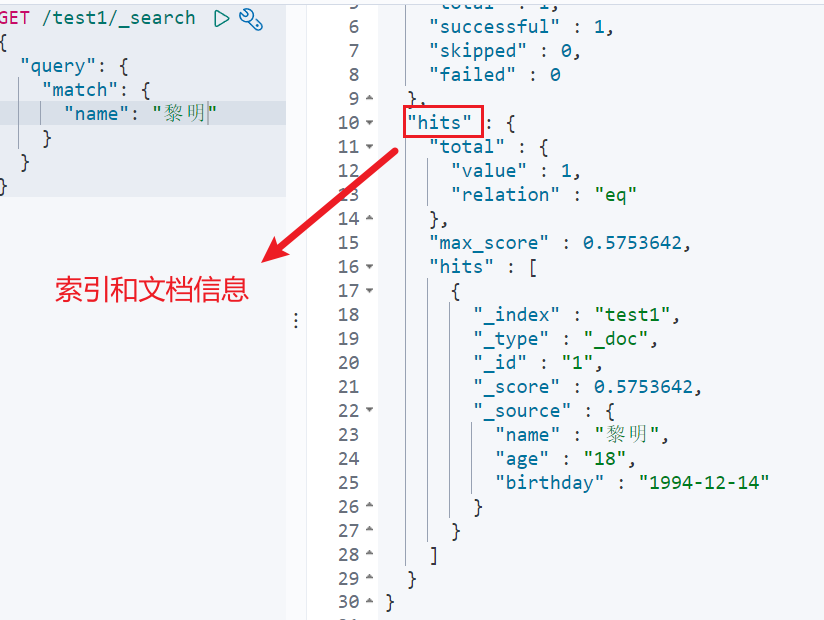
过滤字段查询(输出结果,不需要很多):(我们之后使用java操作es,所有的方法和对象就是这里面的key!)
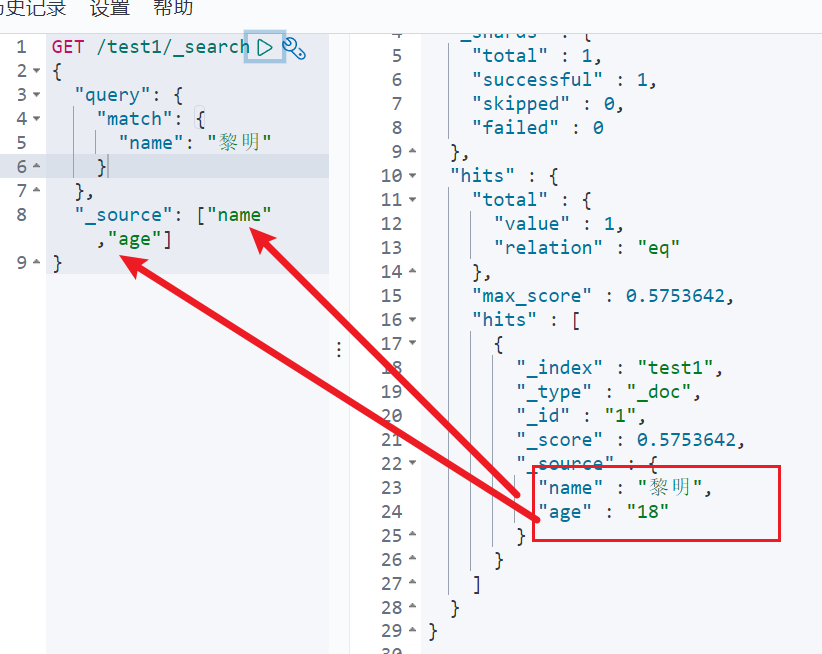 排序查询:
排序查询:
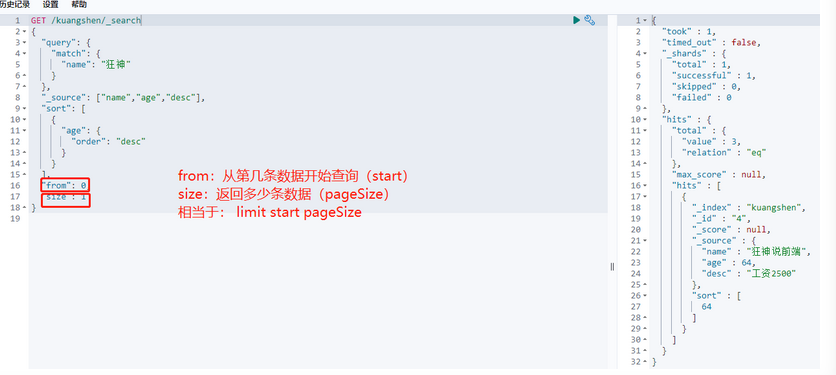
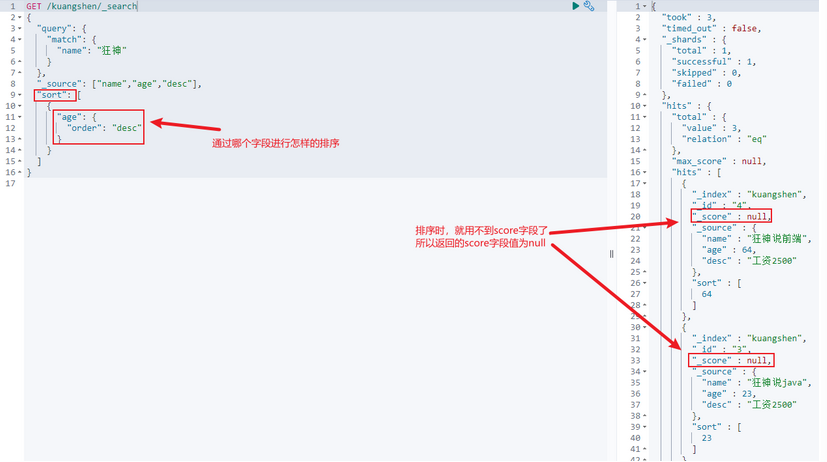 分页查询:(数据索引下标还是从0开始)
分页查询:(数据索引下标还是从0开始)
GET /kuangshen/_search/{currentPage}/{pageSize}
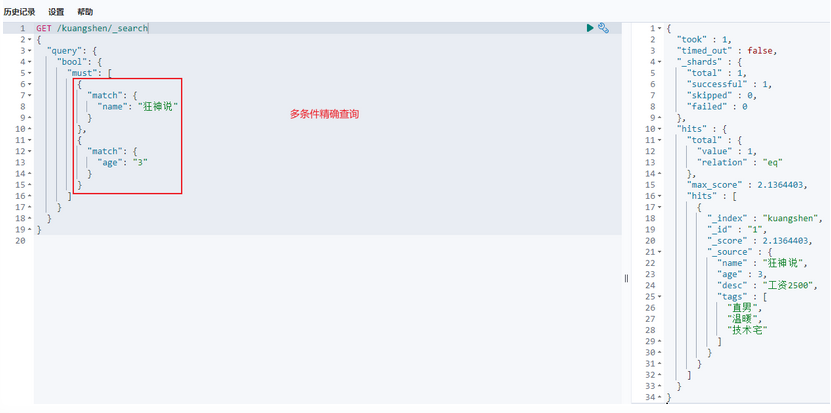
布尔值查询:
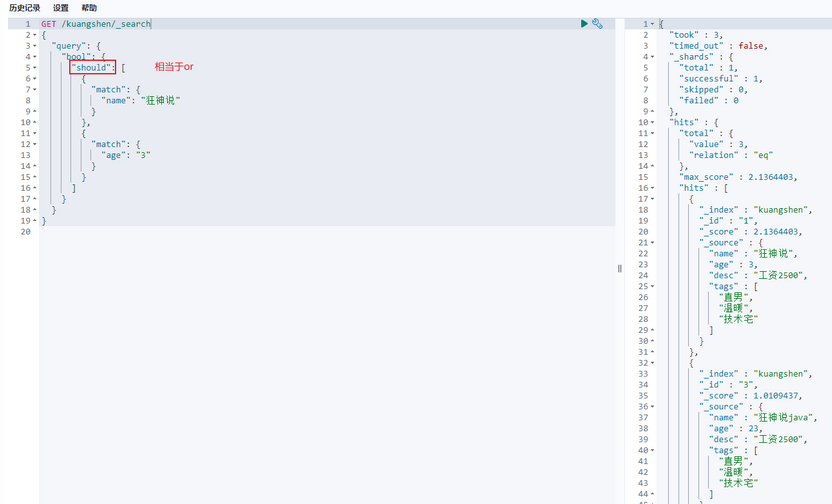
 should(or),所有的条件都要符合 where id=1 or name=xxx
should(or),所有的条件都要符合 where id=1 or name=xxx
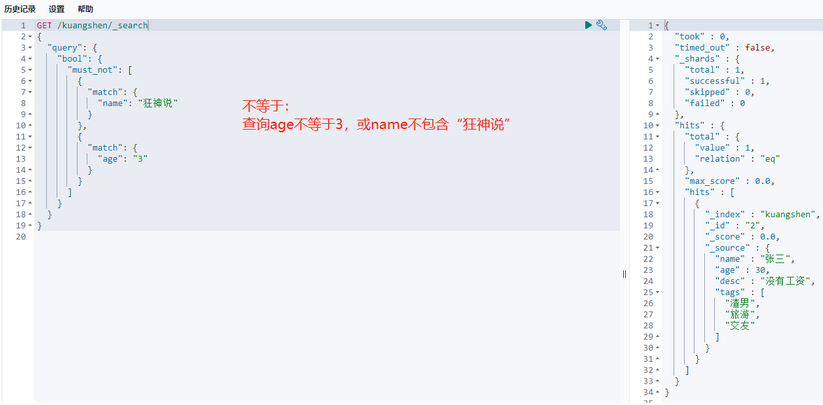
must_not (not)
filter查询过滤:
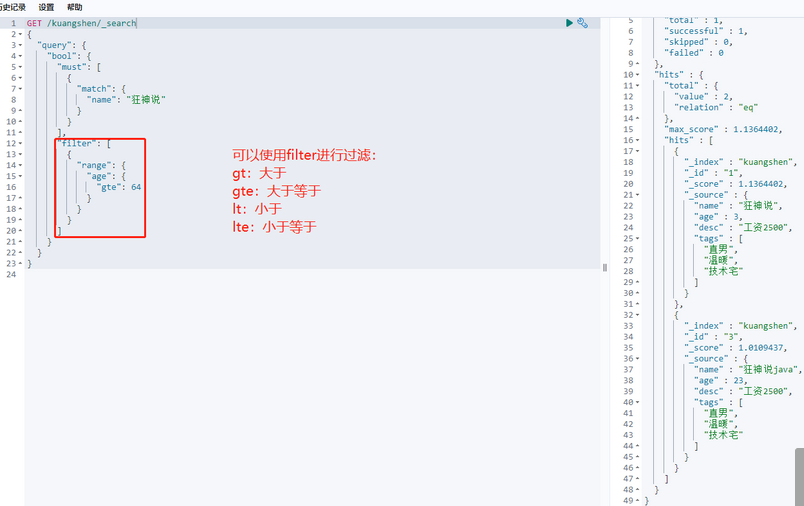
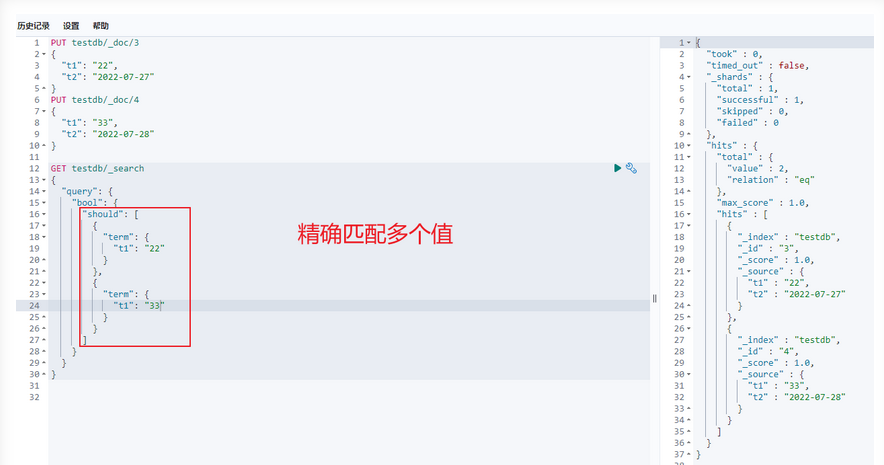
匹配多个条件:
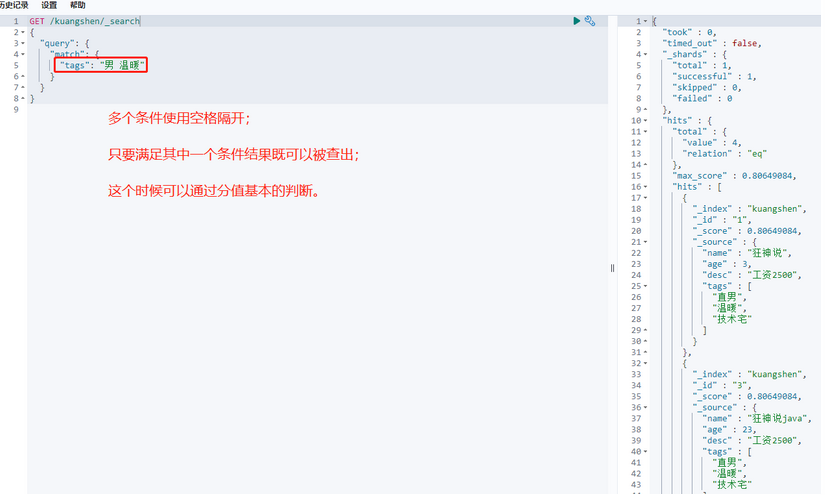
精确查询:
(term 查询是直接通过倒排索引指定的词条进程精确的查找的!)
关于分词:
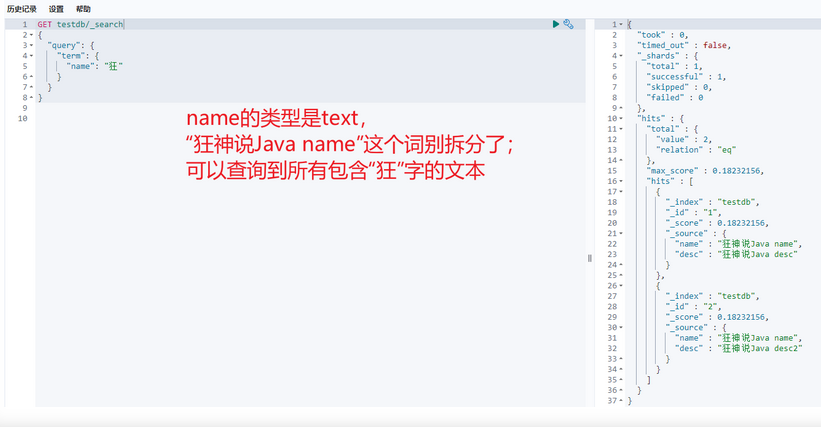
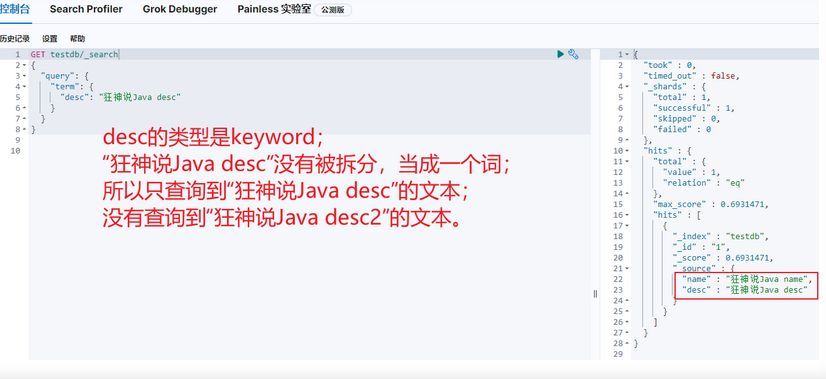
term:直接查询精确的。(两种情况:text、keyword)
match:会使用分词器解析!(先分析文档,然后在通过分析的文档进行查询!)
创建数据
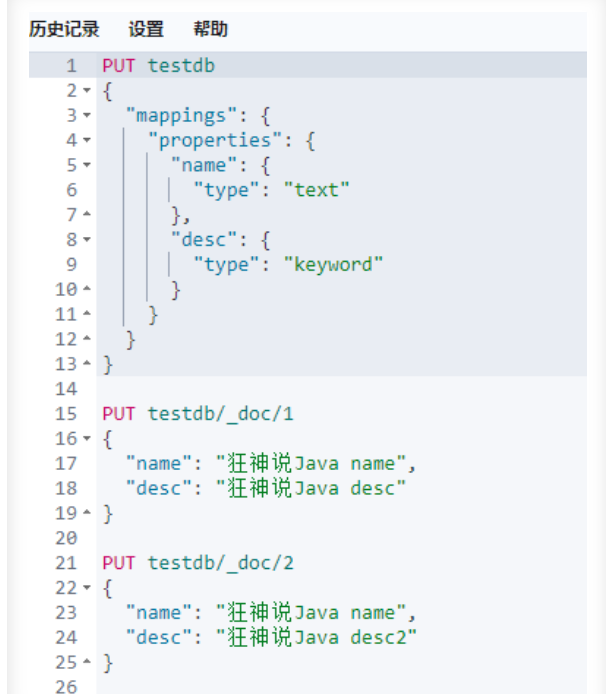
分析数据,查看结果
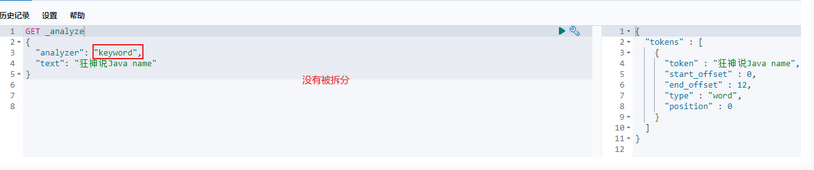
查询数据(keyword类型的字段不会被分词器解析)
多个值匹配精确查询:
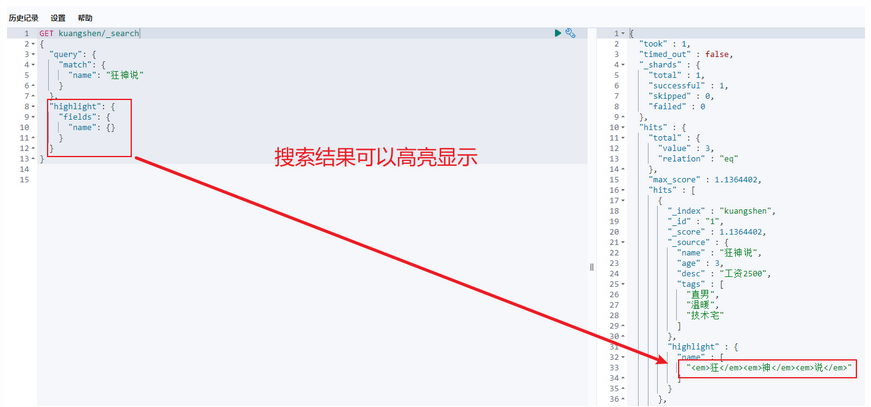
高亮查询:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









