







 本文介绍了在汇编语言实验中查找dd型和dw型数据的方法,以及如何确定不同数据类型的起始地址。通过计算和理解数据结构,可以避免手动查找的繁琐。实验结束后,使用u和g指令结束编程,并对使用table和栈进行了反思,将其与C语言中的结构体进行了类比。
本文介绍了在汇编语言实验中查找dd型和dw型数据的方法,以及如何确定不同数据类型的起始地址。通过计算和理解数据结构,可以避免手动查找的繁琐。实验结束后,使用u和g指令结束编程,并对使用table和栈进行了反思,将其与C语言中的结构体进行了类比。
查看其数据段数据如下
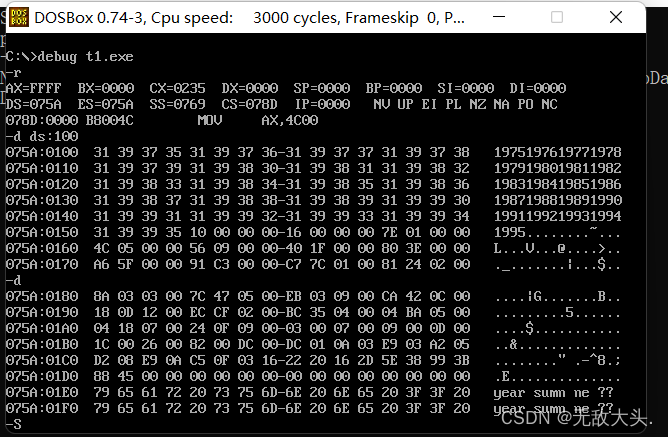
问题一:dd型和dw型的数据在哪?
在1995对应的字节后面有个 10 00 00 00 对应16 再往后4个字节有16 00 00 00对应22
问题二:如何查找对应的每种数据类型地址的起始地址
如上文,手动查找 ,太麻烦!
可以动手算 21个年份,每个年份4个字节 84个字节

对应54 则ds:(100+54) 即可找到 对应的收入数据首地址 依次类推 善用计算器
对应的人数数据首地址为ds:(100+A8)
结束编程查看结果
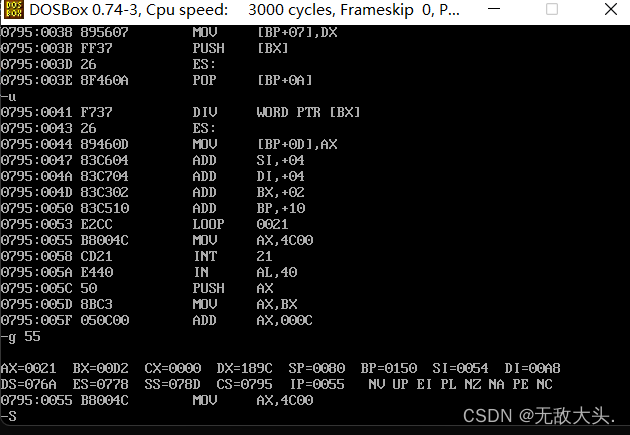 采用u指令和g指令快速结束编程
采用u指令和g指令快速结束编程
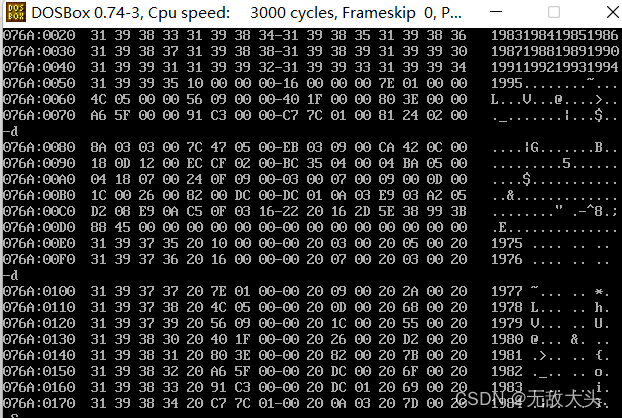
执行结果如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









