




 这篇博客详细介绍了MySQL中的子查询,包括单行子查询、多行子查询、相关子查询、EXISTS与NOT EXISTS的使用,以及在不同场景下的应用示例,帮助读者深入理解子查询的分类和操作。
这篇博客详细介绍了MySQL中的子查询,包括单行子查询、多行子查询、相关子查询、EXISTS与NOT EXISTS的使用,以及在不同场景下的应用示例,帮助读者深入理解子查询的分类和操作。
子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQL 4.1开始引入
目录
一. 分类
分类方式1:
我们按内查询的结果返回一条还是多条记录,将子查询分为 单行子查询 、 多行子查询 。
分类方式2: 我们按内查询是否被执行多次,将子查询划分为 相关(或关联)子查询 和 不相关(或非关联)子查询 。
- 注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
二. 单行子查询
2.1单行比较操作符
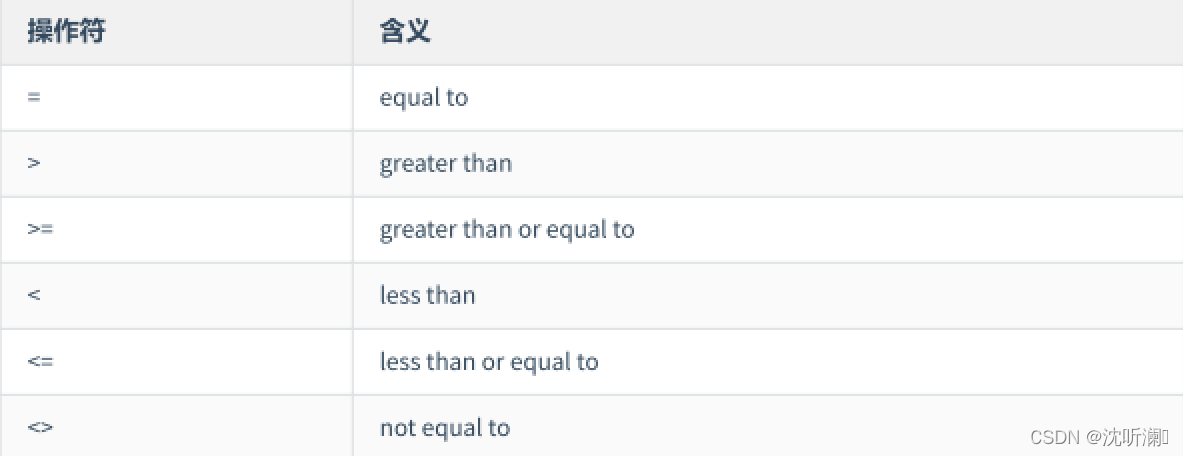
2.2 代码示例:
# 查询与141号员工或174号员工的manager_id和department_id相同的其他员工
SELECT employee_id, manager_id, department_id
FROM employees
WHERE manager_id IN
(SELECT manager_id
FROM employees
WHERE employee_id IN (174,141))
AND department_id IN
(SELECT department_id
FROM employees
WHERE employee_id IN (174,141))
AND employee_id NOT IN(174,141);2.3 HAVING 中的子查询
# 查询最低工资大于110号部门最低工资的部门id和其最低工资
SELECT department_id,MIN(salary)
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
HAVING MIN(salary) > (
SELECT MIN(salary)
FROM employees
WHERE department_id = 110
);2.4 CASE中的子查询
# 显式员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800
的department_id相同,则location为’Canada’,其余则为’USA’
SELECT employee_id, last_name,
(CASE department_id
WHEN
(SELECT department_id FROM departments
WHERE location_id = 1800)
THEN 'Canada' ELSE 'USA' END) location
FROM employees;三. 多行子查询
3.1 多行比较操作符
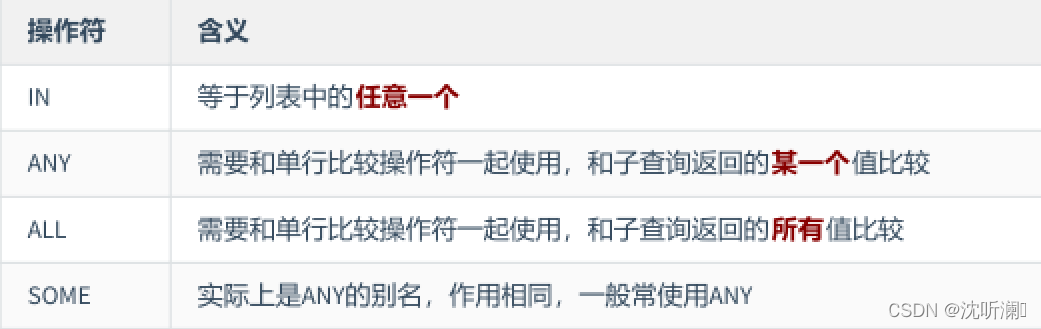
3.2 代码示例
# ANY / ALL:
# 返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、
# 姓名、job_id 以及salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ANY (
SELECT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
# 返回其它job_id中比job_id为‘IT_PROG’部门所有工资低的员工的员工号、
# 姓名、job_id 以及salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ALL (
SELECT salary
FROM employees
WHERE job_id = 'IT_PROG'
);#MySQL中聚合函数是不能嵌套使用的
#题目:查询平均工资最低的部门id
#MySQL中聚合函数是不能嵌套使用的。
#方式1:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_sal)
FROM(
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
) t_dept_avg_sal
);
#方式2:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL(
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
) 四. 相关子查询:
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询
#题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
#方式1:使用相关子查询
SELECT last_name,salary,department_id
FROM employees e1
WHERE salary > (
SELECT AVG(salary)
FROM employees e2
WHERE department_id = e1.`department_id`
);
#方式2:在FROM中声明子查询
SELECT e.last_name,e.salary,e.department_id
FROM employees e,(
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id) t_dept_avg_sal
WHERE e.department_id = t_dept_avg_sal.department_id
AND e.salary > t_dept_avg_sal.avg_sal
# 查询员工的id,salary,按照department_name 排序
SELECT employee_id,salary
FROM employees e
ORDER BY (
SELECT department_name
FROM departments d
WHERE e.`department_id` = d.`department_id`
) ASC;#结论:在SELECT中,除了GROUP BY 和 LIMIT之外,其他位置都可以声明子查询!
SELECT ....,....,....(存在聚合函数)
FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件
(LEFT / RIGHT)JOIN ... ON ....
WHERE 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....
#题目:若employees表中employee_id与job_history表中employee_id相同的数目不小于2,
#输出这些相同id的员工的employee_id,last_name和其job_id
SELECT *
FROM job_history;
SELECT employee_id,last_name,job_id
FROM employees e
WHERE 2 <= (
SELECT COUNT(*)
FROM job_history j
WHERE e.`employee_id` = j.`employee_id`
)五. EXISTS 与 NOT EXISTS
#查询公司管理者的employee_id,last_name,job_id,department_id信息
#方式1:自连接
SELECT DISTINCT mgr.employee_id,mgr.last_name,mgr.job_id,mgr.department_id
FROM employees emp JOIN employees mgr
ON emp.manager_id = mgr.employee_id;
#方式2:子查询
SELECT employee_id,last_name,job_id,department_id
FROM employees
WHERE employee_id IN (
SELECT DISTINCT manager_id
FROM employees
);
#方式3:使用EXISTS
SELECT employee_id,last_name,job_id,department_id
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e1.`employee_id` = e2.`manager_id`
);#查询departments表中,不存在于employees表中的部门的department_id和department_name
#方式1:
SELECT d.department_id,d.department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
#方式2:
SELECT department_id,department_name
FROM departments d
WHERE NOT EXISTS (
SELECT *
FROM employees e
WHERE d.`department_id` = e.`department_id`
);
SELECT COUNT(*)
FROM departments;

















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









