







 Phoenix作为HBase的SQL层,提供二级索引功能,优化多字段查询效率,尤其适用于读多写少的场景。二级索引包括覆盖索引和全局/局部索引,其中全局索引在读取时快速,但写入时性能下降。批量导入数据常用BulkLoad,通过MapReduce和HFileOutputFormat2生成HFiles,再用completebulkload工具导入。
Phoenix作为HBase的SQL层,提供二级索引功能,优化多字段查询效率,尤其适用于读多写少的场景。二级索引包括覆盖索引和全局/局部索引,其中全局索引在读取时快速,但写入时性能下降。批量导入数据常用BulkLoad,通过MapReduce和HFileOutputFormat2生成HFiles,再用completebulkload工具导入。
Phoenix二级索引
HBase因其历史原因只支持rowkey索引,当使用rowkey来查询数据时可以很快定位到数据位置。现实中,业务查询需求条件往往比较复杂,带有多个查询字段组合,如果用HBase查的话,只能全表扫描进行过滤,效率很低。而Phoenix支持除rowkey外的其它字段的索引创建,即二级索引,查询效率可大幅提升。(基于Coprocessor,可以更好的实现二级索引、复杂过滤规则、权限访问控制等更接地气的特性。)
二次索引设计思路
二级索引的本质就是建立各列值与行键之间的映射关系
如图,当要对F:C1这列建立索引时,只需建立F:C1各列值对其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询复合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值)
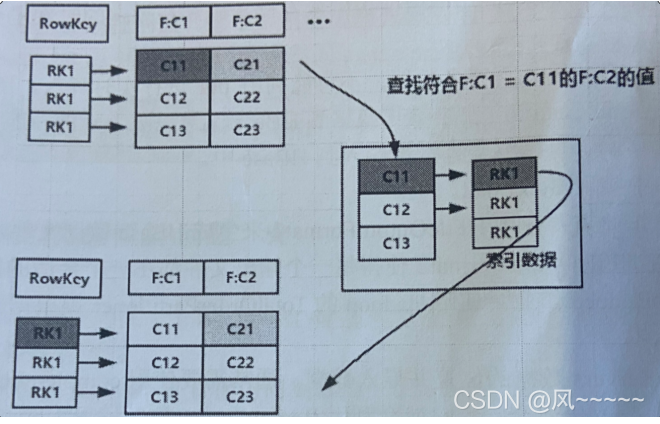
查询步骤:
-
根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1;
-
得到RK1后就自然能根据RK1来查询C2的值了,联合索引也是如此。
Phoenix原理
Phoenix的SQL实现原理基于一系列的Scan操作完成,Scan是HBase的批量扫描过程。这一系列的Scan操作也是分配到各台regionserver上通过Coprocessor来完成。主要用到的是RegionObserver,通过RegionObserver在postScannerOpen Hook 中将要用到的是RegionScanner替换成支持聚合操作的定制化Scanner,在真正执行聚合操作时,会通过自定的Scan属性传递给RegionScanner,在这个Scan中也可加入一些过滤条件,尽量减少返回Client的结果。
Phoenix二次索引
-
覆盖索引:索引表中就包含所想要的全部字段数据,这样只需通过访问索引表而无需访问主表,就能够得到数据。
-
全局索引:适用于读多写少的场景。全局索引在写数据时会消耗大量资源,所有对数据的增删改操作都会更新索引表,而索引表是分布在各个结点上的,性能会受到影响。好处就是,在读多的场景下如果查询的字段用到索引,效率会很快,因为可以很快定位到数据所在具体结点region上,对于写性能就很慢了,因为每写一次,需要更新所有结点上的索引表数据。
-
局部索引:适用于写多读少场景,和全局索引类似,Phoenix会在查询时自动选择是否使用索引。如果定义为局部索引,索引表数据和主表数据会放在同一regionserver上,避免写操作时跨节点写索引表带来的额外开销(如Global Indexes)。当使用局部索引查询时,即使查询字段不是索引字段,索引表也会正常使用,这和Global Indexes是有区别的。索引是存储在主表的一个独立的列族中。因为是局部索引,所以在client端查询使用索引时,需要扫描每个结点上的索引表以得到数据所在具体region位置,当region多时,查询时耗会很高,所以查询性能比较低,适合读少写多场景。
-
不可变索引和可变索引(根据表是否可变)
优点:基于Coprocessor的方案,从开发设计的角度看,把很多二级索引管理的细节都封装在Coprocessor具体实现类中,简化了数据访问者的使用。
缺点:Coprocessor方案入侵性比较强,增加了regionserver内部需要运行和维护二级索引关系表的代码逻辑,对regionserver的性能有一定的影响。
- 非Coprocessor方案(自行在外部构建和维护索引关系,基于Apach Lucene 的Elasticsearch(简称ES)或 Apache Solr)。
HBase数据批量导入
大量数据不可能put进行实时写入,采用BulkLoad方式。批量导数据又分为两种:
- 生成Hfiles,然后批量导数据;
- 直接将数据批量导入到HBase。
Hadoop实现BulkLoad
-
MapReduce作业需要使用HFileOutputFormat2来生成HBase数据文件。为了有效的导入数据,需要配置HFileOutputFormat2使得每一个输出文件都在一个合适的区域中。为了达到这个目的,MapReduce作业会使用TotalOrderPartitioner类根据表的key值将输出分割开来。
-
告诉RegionServers数据的位置并导入数据。通常需要使用completebulkload工具,将文件在HDFS上的位置传递给它,它将会利用regionserver将数据导入到相应的区域。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









