







前言:
我这个是经过我自己实践过的,自己装过N遍了,基本是没什么问题,我建议各位先扫一遍目录。
hadoop集群安装基础环境也在我的这个专栏里,如果想安装参考,可以自取。
谢谢参考,如果有疑问或者bug,欢迎提问指正。
目录
解压hadoop-2.7.7文件到/usr/local/ 目录下
修改hadoop 配置文件(hadoop-env.sh core-site.xml )后面还有三个
修改hadoop 配置文件(hdfs-site.xml mapred-site.xml yarn-site.xml slaves)
将master上的hadoop-2.7.7分配到worker1及worker2机器中
eg:一、master节点启动集群可能会遇到ssh权限认证问题
二、Hadoop3.xxx启动时会出现如下问题,我一开始用的是Hadoop2.xxx就没事
注意,完成后记得整一个快照,作为hadoop集群配置完成的备份
前言
之前安装的步骤是安装hadoop的前置工作,现在我们来到了真正的操作环节,目前的操作只需要在master上进行执行,然后可以通过复制到s1,s2。
eg:root/admin,三台都是
eg:master/admin
eg:worker1/admii
解压hadoop-2.7.7文件到/usr/local/ 目录下
之前我已经上传了hadoop配置文件在/opt目录下

现在我要将他解压到/usr/local目录下
命令:
tar -xzvf /opt/hadoop-2.7.7.tar.gz -C /usr/local/,即将opt下hadoop文件解压到/usr/local目录下

进入/usr/local目录下查看一下

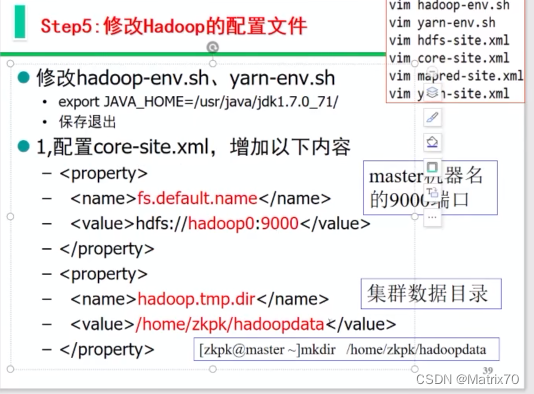
修改hadoop 配置文件(hadoop-env.sh core-site.xml )后面还有三个
前言
这一次是修改它的配置文件了,本次有hadoop-env.sh yarn-env.sh coresite.xml 三个xml文件。
进入到hadoop配置文件界面
/usr/local/hadoop-2.7.7/etc/hadoop
编辑hadoop-env.sh配置文件
添加环境变量,这个环境变量是JDK的
#配置java环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_144
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#;
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

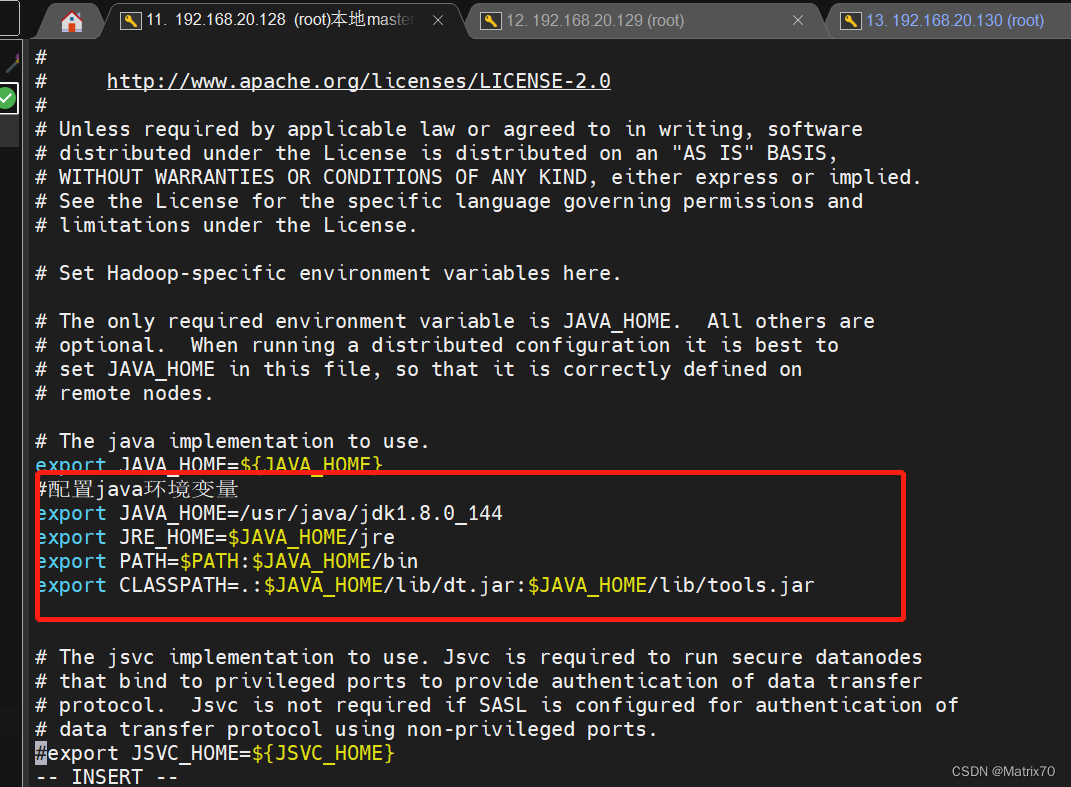
修改完,保存退出,source一下,让文件生效
source hadoop-env.sh 
修改core-site.xml配置文件
vi core-site.xml
添加如下内容:
<configuration>
<!--master及其端口-->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<!--指定hadoop运行时产生文件的存放目录,这个目录一定要创建,三台都要-->
<property>
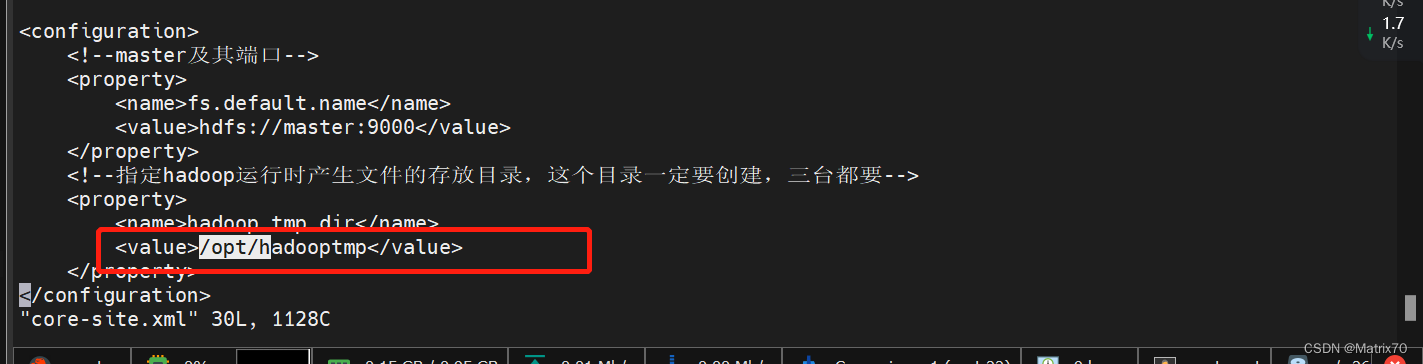
<name>hadoop.tmp.dir</name>
<value>/opt/hadooptmp</value>
</property>
</configuration>我再3.2.4时候更改了一下目录。
<configuration>
<!--master及其端口-->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<!--指定hadoop运行时产生文件的存放目录,这个目录一定要创建,三台都要-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data</value>
</property>
</configuration>完事后保存配置 ,记得创建目录

注意:FS是给两个主机用的,单节点的用defaultname
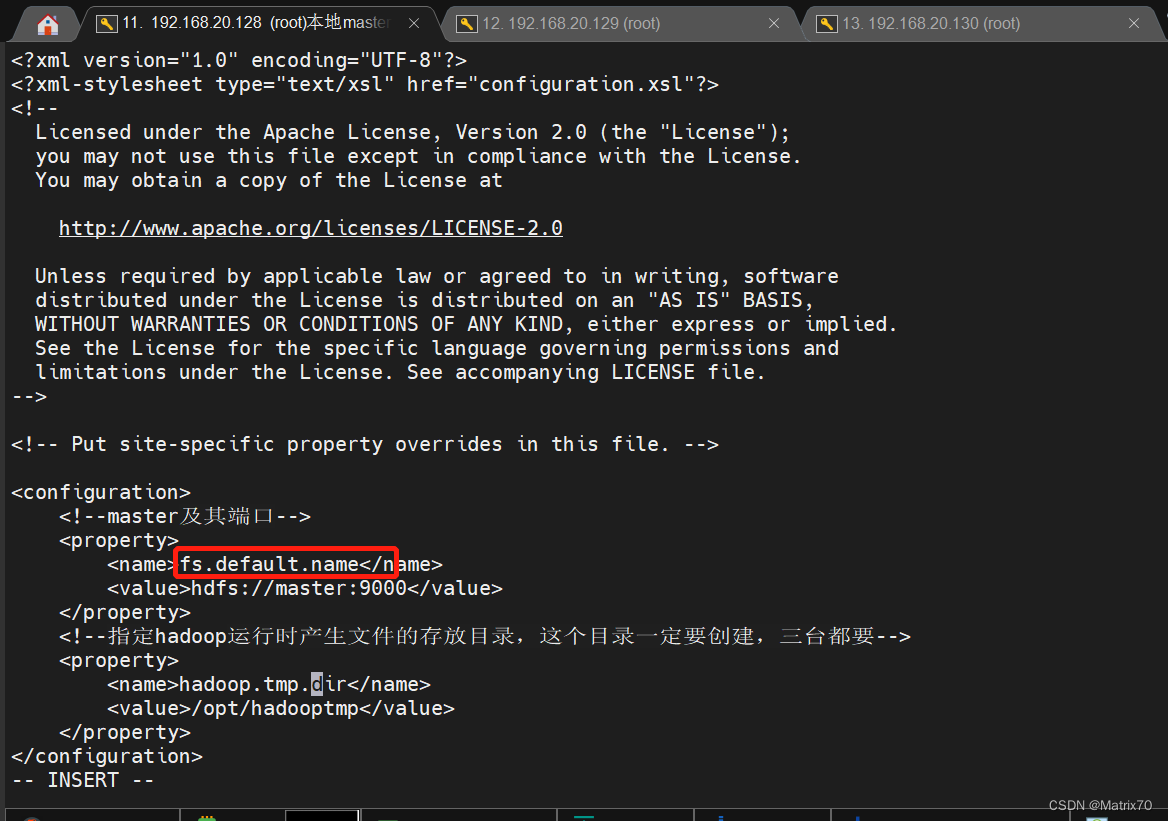
如下图,配置到name,下面的value是主机名,9000端口

下面的这个地址临时文件。hadoop运行的临时文件地址,我们自己指定一个目录,我想放在opt目录下:

修改hadoop 配置文件(hdfs-site.xml mapred-site.xml yarn-site.xml slaves)
hdfs-site.xml mapred-site.xml yarn-site.xml slaves修改hdfs-site.xml配置文件
小技巧:注意hdfs-site.xml 中配置的副本在不同机器上,一般设置2~3就行,我们两台从机,就是增加容错性
vi hdfs-site.xml
修改如下图:
<configuration>
<!--保存副本数,默认是3,我配置为2-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--是否启用hdfs权限,当值为false时,代表关闭-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--配置namenode对应地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.44.128:50070</value>
</property>
</configuration>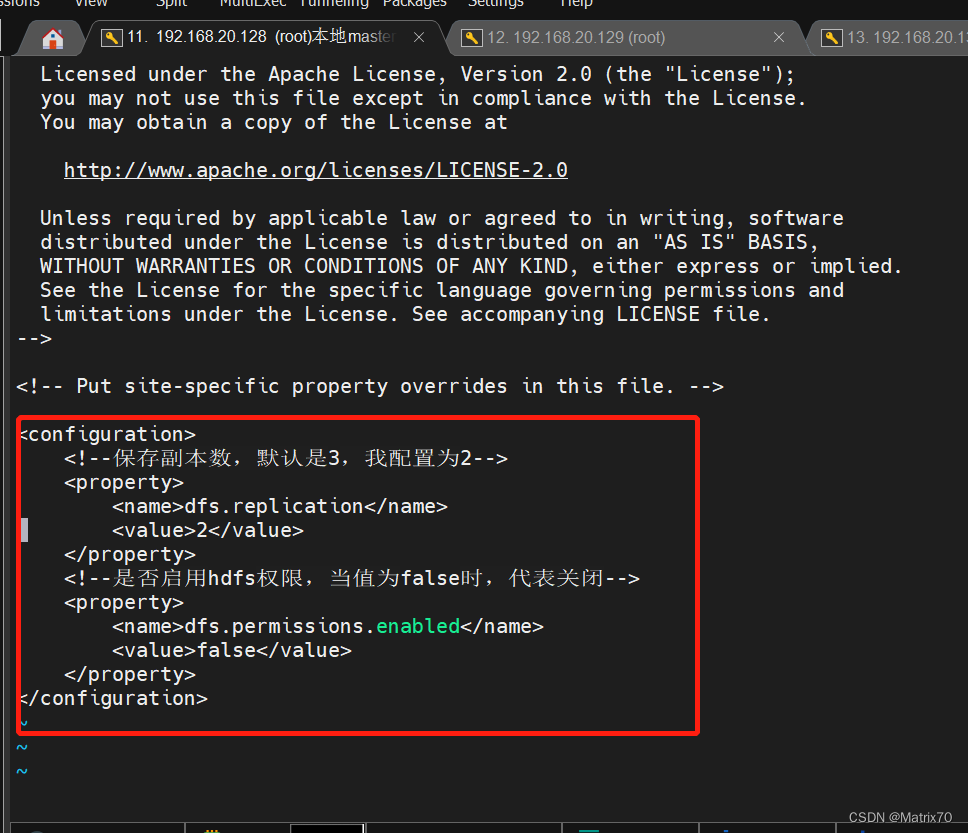
保存配置。
mapred-site.xml
对于mapred-site.xml ,如果我们这里没有这个文件怎么办:目录下是mapred-site.xml.tmplate,可以改完此配置后为其重命名mapred-site.xml 。我这里就没有,如果有,就不必重命名,直接修改就好。
 vi
vi

修改配置:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!--配置MR资源调度框架YARN-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.child.tmp</name>
<value>/opt/tempmr</value>
</property>
</configuration>
如下图
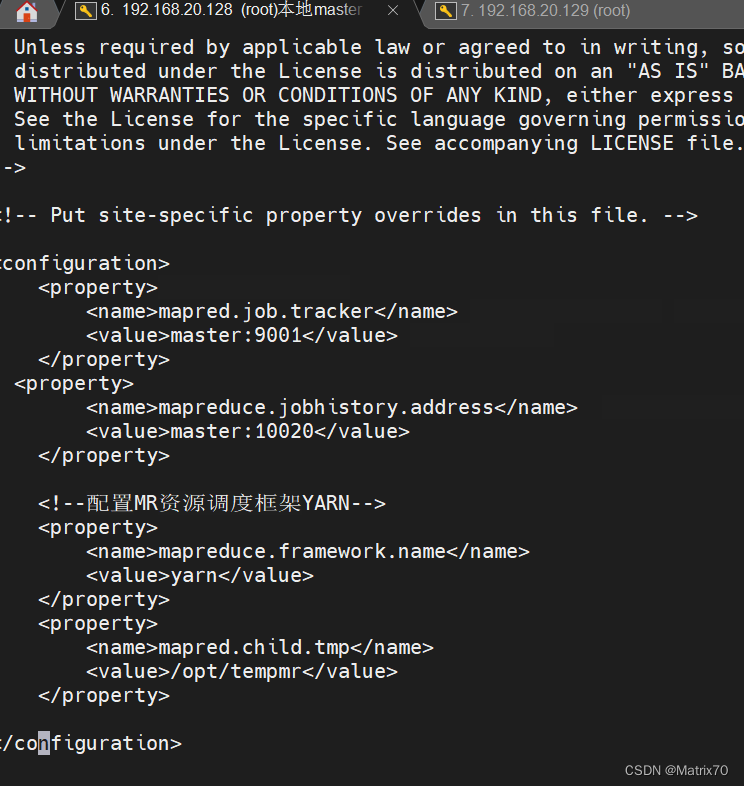
修改完保存配置,随后重命名为 mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
功能
配置这个是干啥用的,framework有三个模式,第一个class,yarn,local,这个最好看官网,我的解释能力有限。已知的是class已经淘汰了,yarn是计算系统,local是本地的,我们用的是yarn,构建框架,使用yarn进行资源配置和管理。截止今天,我知道了这三个模式及区别
mapreduce.framework.name 用于指定 Hadoop 中 MapReduce 作业的运行框架,
-
classic(经典模式):-
这是 Hadoop 最早期的 MapReduce 实现,也称为 MR1(MapReduce 1)。
-
在这个模式下,MapReduce 作业由 JobTracker 和 TaskTracker 管理。
-
由于资源管理和作业调度的耦合性较高,扩展性和灵活性较差,逐渐被 YARN 取代。
-
-
yarn(推荐模式):-
这是 Hadoop 2.x 及以后版本的默认模式,基于 YARN(Yet Another Resource Negotiator)资源管理系统。
-
YARN 将资源管理和作业调度分离,提高了集群的扩展性和资源利用率。
-
在这个模式下,MapReduce 作业由 ResourceManager 和 NodeManager 管理,适合大规模集群。
-
-
local(本地模式):-
这个模式用于在本地机器上运行 MapReduce 作业,不依赖 Hadoop 集群。
-
适合开发和测试,但不适合生产环境。
-
编辑yarn配置文件 yarn-site.xml
在这里,资源管理器的hostname我们指定机器名,设置为主机,我的是master;还有一个shuffle参数,它的值是对shuffle的一个命名,高本版后只允许 字符,数字,下划线等,以前有. ,我们把.改为_
vi yarn-site.xml
 加入下面的内容,如下图
加入下面的内容,如下图
<configuration>
<!-- Site specific YARN configuration properties -->
<!--资源管理器,master节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--配置节点管理器上运行的附加服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--关闭虚拟内存检测-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--yarn.application.classpath 配置没有这个配置,测试MapReduce时可能会报错-->
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_HOME/share/hadoop/common/*,
$HADOOP_HOME/share/hadoop/common/lib/*,
$HADOOP_HOME/share/hadoop/hdfs/*,
$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOME/share/hadoop/mapreduce/*,
$HADOOP_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,
$HADOOP_HOME/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
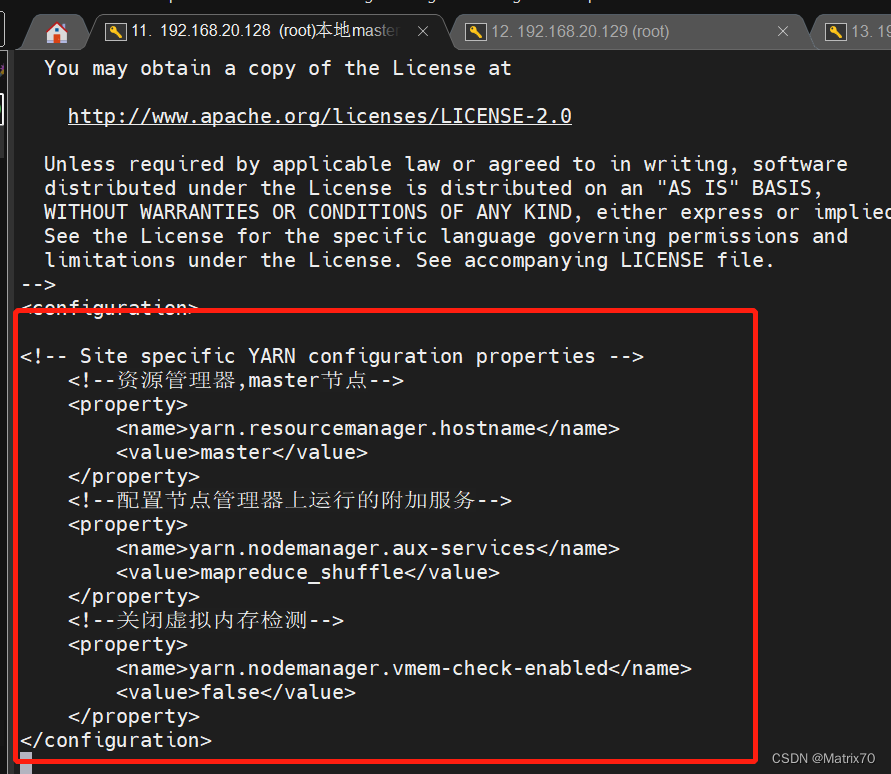
修改完保存一下配置
slaves文件
(注:现在由于非洲老表那边,在3.几版本的hadoop,都叫做worker,我现在用的是2.7.7,所以这个文件名还是slaves )
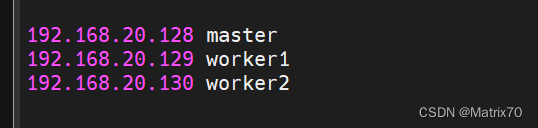
这个文件里文件名和ip地址都行,我的叫做worker1,worker2,填进slaves就行,一行一个主机名
(注:我之前主机名前都带一个hadoop-,我现在简化了把他删了。)
主:namenode ,用来管理NN机器的名称
从:datanode ,数据节点的机器名称
编辑yarn-env.sh配置文件(待定,目前不用修改)
将master上的hadoop-2.7.7分配到worker1及worker2机器中
将master文件夹拷贝到worker1及worker2中了。
在master上使用scp -r 命令递归的复制到worker中,如果之前有直接覆盖就行
scp -r /usr/local/hadoop-2.7.7 worker1:/usr/local/hadoop-2.7.7
scp -r /usr/local/hadoop-2.7.7 worker2:/usr/local/hadoop-2.7.7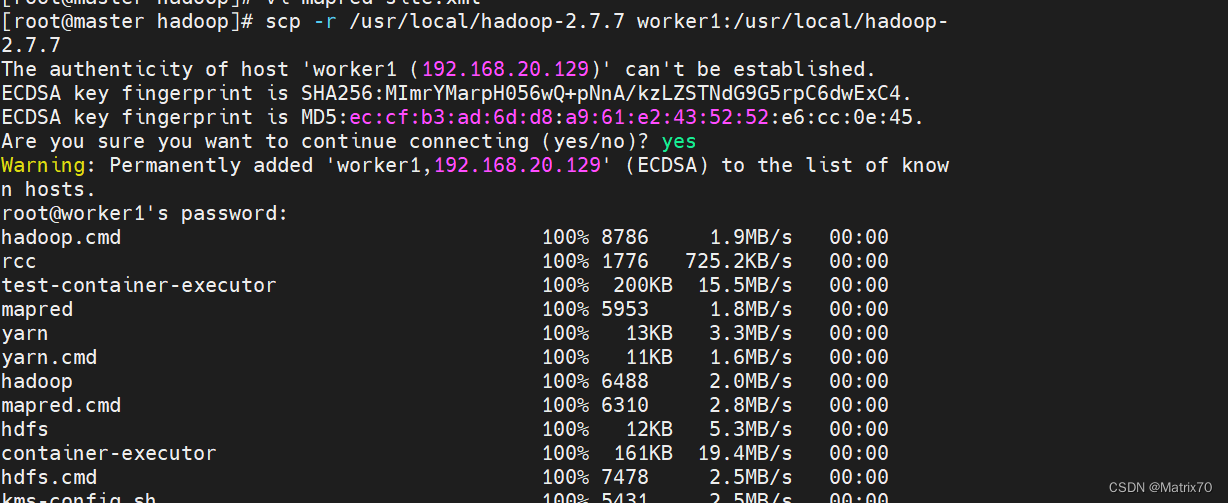
。。
备注:
1、如果此命令报错,我的问题是我在后面把三台的hostname改了,因此主机找到不worker地址,需要把三台的/etc/hosts中对应的主机名改了就行,当然可以直接使用hadoop-worker1也行。原来的是
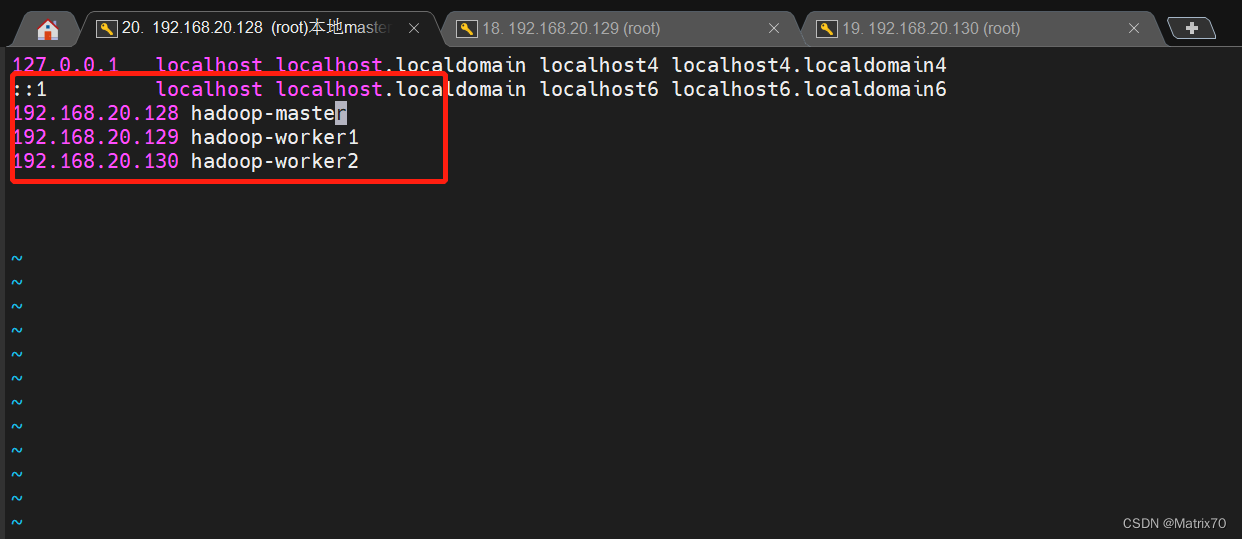
改过后

2、还有一点,我使用scp命令传输文件时,出现传输过去了,但是在另一台机器上打开时发现不是我传输过去的文件,需要我讲源文件删除,再重新scp发送就可以了。
一开始我以为传输不过去,于是我做了一个小demo,将文件传输到/opt文件下,scp命令没问题,因此我意识到是文件未删除无法进行覆盖的缘故。
(希望后续随水平提高能够有更好的解释)
记录一个问题
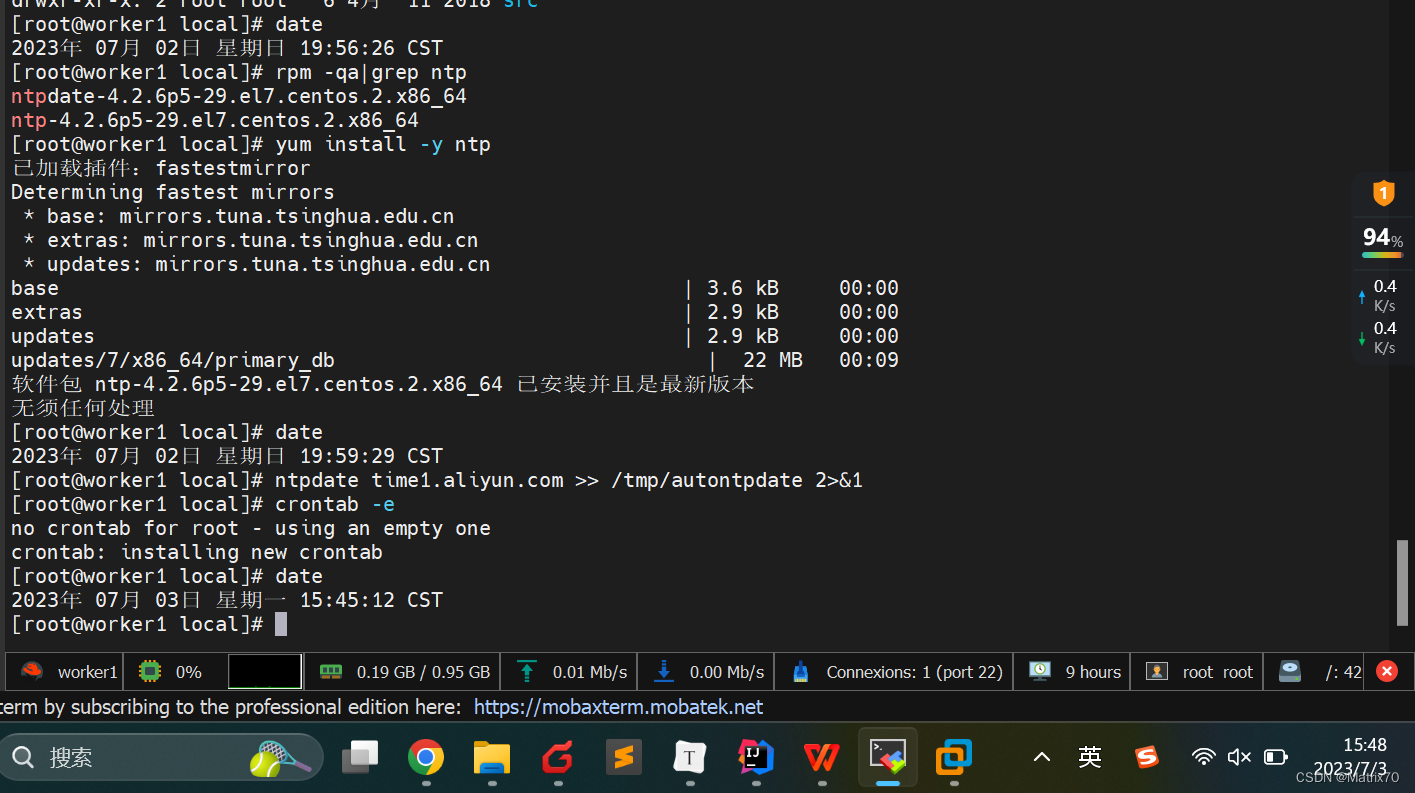
在后续进行测试时:发现三台机子的时间对不上,只有master是正确的,如图所示,定位问题为
我只在master上配置了时间,忘记在worker上配置时间同步了,因此需要在这两台机器上进行对应的时间同步操作。
Hadoop系统环境变量配置
前言
系统环境变量
添加
三台都要配置,现在master上,追加到文件末尾就行,我之前实在/etc/profile中添加的
这个是我最新的配置。之前是144和2.7.7
#配置java环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_181
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
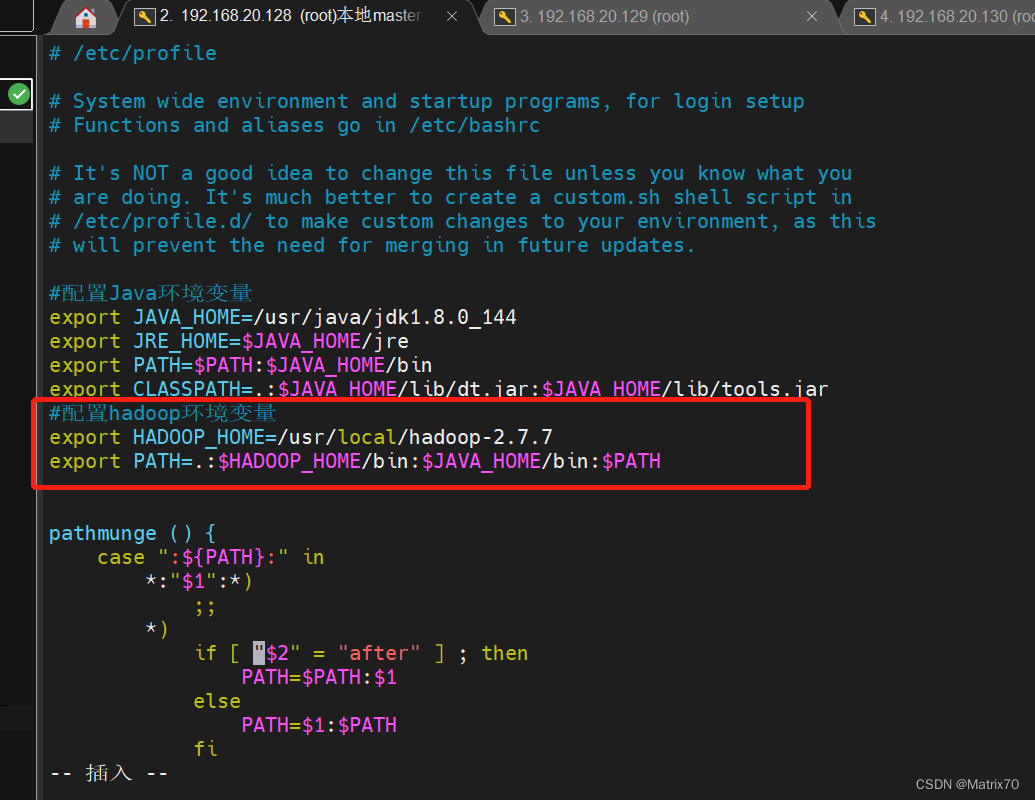
#配置hadoop环境变量
export HADOOP_HOME=/usr/local/hadoop-3.2.4
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
#HADOOP_CLASSPATH配置
export HADOOP_CLASSPATH=$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/l ib/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/hdfs/lib/*:$HADOOP_HOME/share /hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*:$HADOOP_HOME/share/hadoop/yarn/ *:$HADOOP_HOME/share/hadoop/yarn/lib/*
source一下
source 文件才会生效,不然会找不到命令
source /etc/profile
创建数据目录
这个配置好文件其实就可以创建了,三台都要配置i
之前修改 core-site.xml文件时,我们有一个hadoop.tmp.dir,要建立好这个文件夹,三台机器都要建立。

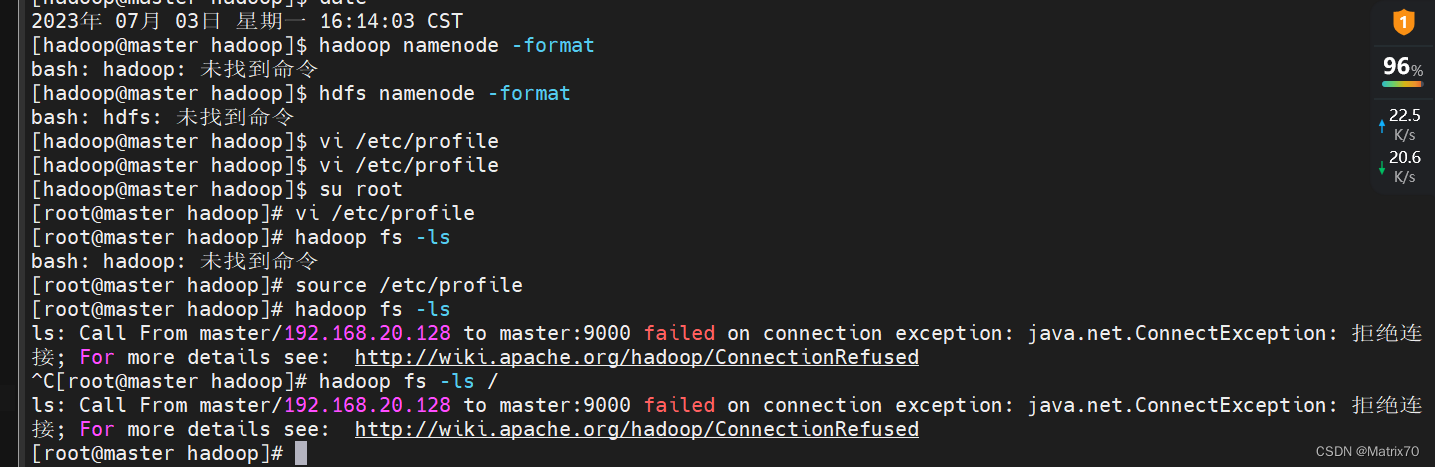
没格式化之前使用命令
会出现如下错误,因此需要格式化一下,保存快照
启动Hadoop集群
启动hadoop集群以此检验我们的配置是否正确
格式化文件系统
在格式化之前最好给三台机子做一个快照,保存一次,因为格式化只能执行一次。在master节点上执行如下命令
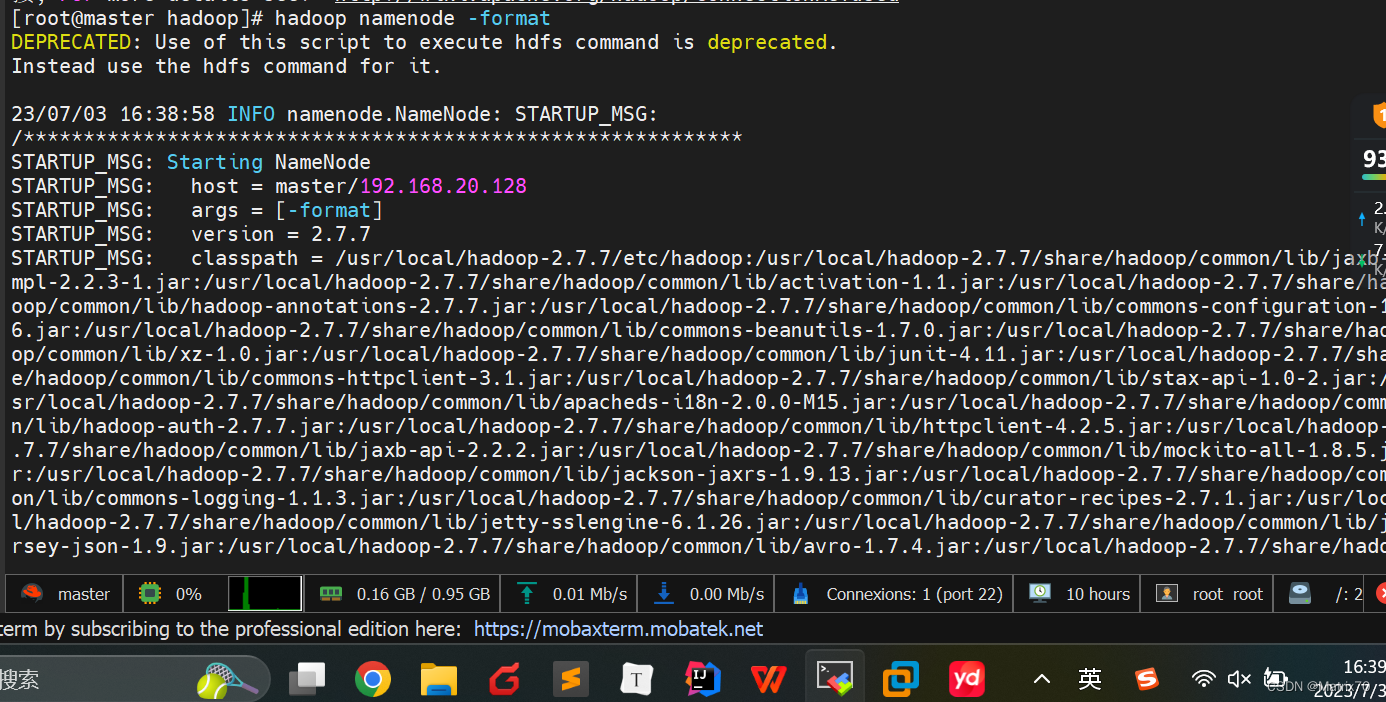
hadoop namenode -format如果看到如下信息,则表示格式化成功,出现其他例如exception及error则表示出现异常
启动Hadoop
1、只需要在master上面启动,进入如下sbin目录下
cd /usr/local/hadoop-2.7.7/sbin/随后执行start-all.sh,启动所有,包括了start-dfs.sh及start-yarn.sh,启动完毕
./start-all.sh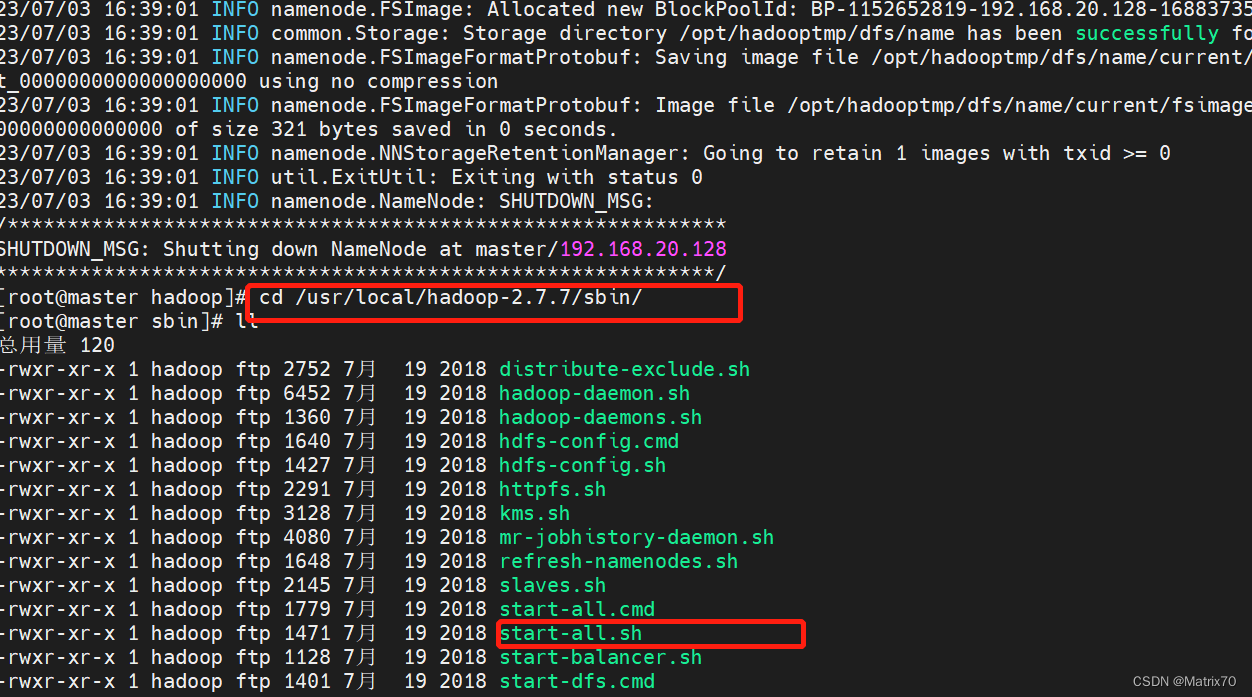
启动结果如下:
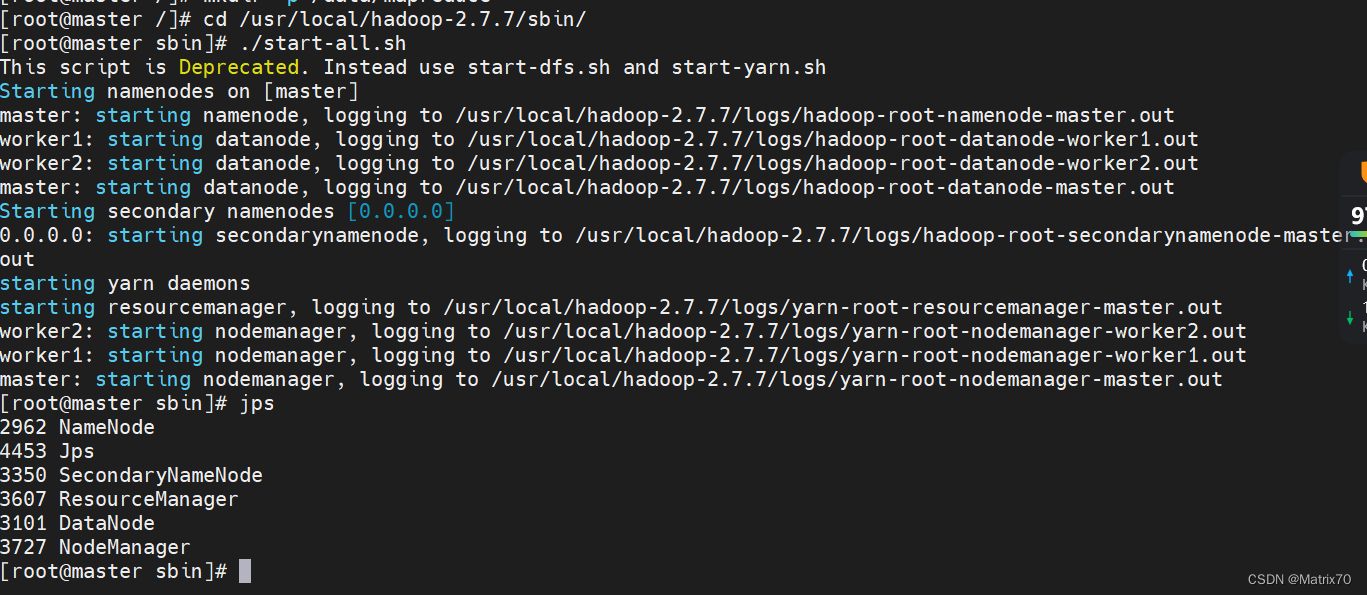
以上我们就启动完毕了,注意我使用root用户启动的。
2、另一种启动方式分布启动,分两步
1)第一步启动文件系统start-dfs.sh
如果报错,查看日志logs,并检查响应配置文件hdfs-site.xml及core-site.xml.
2)第二步启动yarn计算框架
如果报错,查看logs,并检查对应配置文件yarn-site.xml及mapred-site.xml。
eg:一、master节点启动集群可能会遇到ssh权限认证问题
到这一步,能使得启动出现问题的无非是权限问题,另一个就是配置文件的问题,排除配置文件问题,那就是权限问题,搞定了,后面就可以了
报错如下:
root@worker2's password: worker2: Permission denied, please try again.
root@worker1's password: worker1: Permission denied, please try again.
0.0.0.0: Host key verification failed.
worker1: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
worker2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
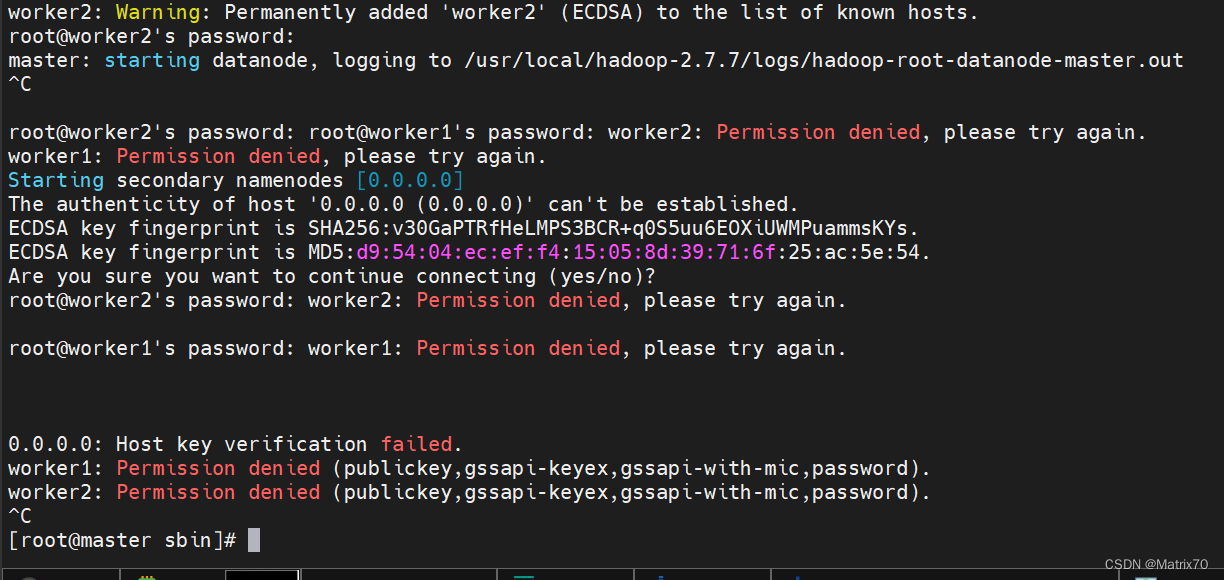
解决:
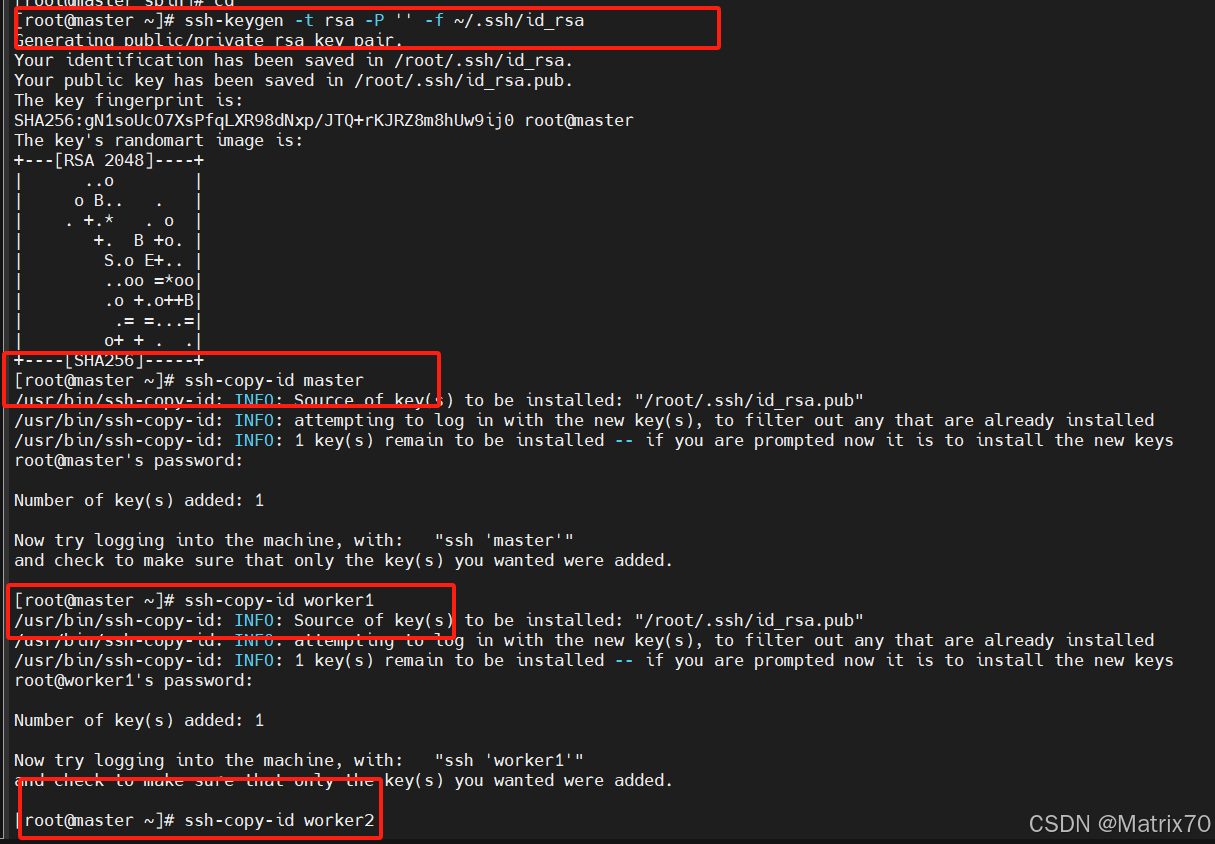
权限问题,我的解决方法比较暴力,我把root用户,hadoop用户的三台机子的ssh免密都配置了一遍,ssh公钥忘记追加到authorized_keys中了,将master节点的id_rsa.pub 文件内容追加到authorized_keys文件中。只需要配置master节点到worker1,worker2的就行。
具体操作如下:
1.在master节点上生成SSH密钥对
#在master节点上生成SSH密钥对
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa2.将生成的公钥分发到所有节点(包括master自身)
ssh-copy-id master
ssh-copy-id worker1
ssh-copy-id worker2这样就基本完成了。可以测试一下。
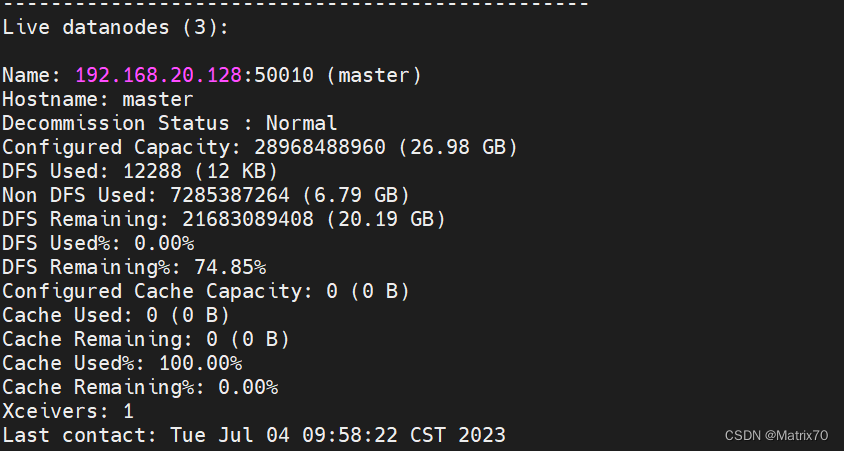
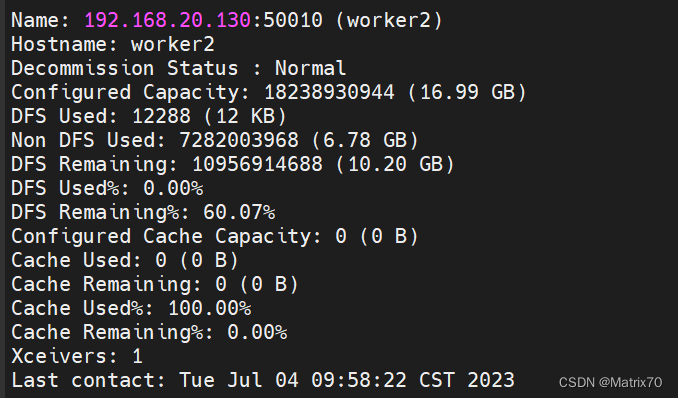
这个是启动成功后的进程信息。



#使用终端查看集群状态
hadoop dfsadmin -report

jps查看进程
namenode,datanode, RM ,SN,NM,出现代表启动成功,安装一大半了。

二、Hadoop3.xxx启动时会出现如下问题,我一开始用的是Hadoop2.xxx就没事
执行启动hadoop集群
报错:
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.问题分析:
以 root 用户身份启动 Hadoop 集群时,系统没有找到必要的环境变量来定义运行 Hadoop 服务的用户。Hadoop 不允许直接以 root 用户启动服务,而是要求你指定一个非 root 用户来运行这些服务。我们需要定义环境变量来指定运行 Hadoop 服务的用户
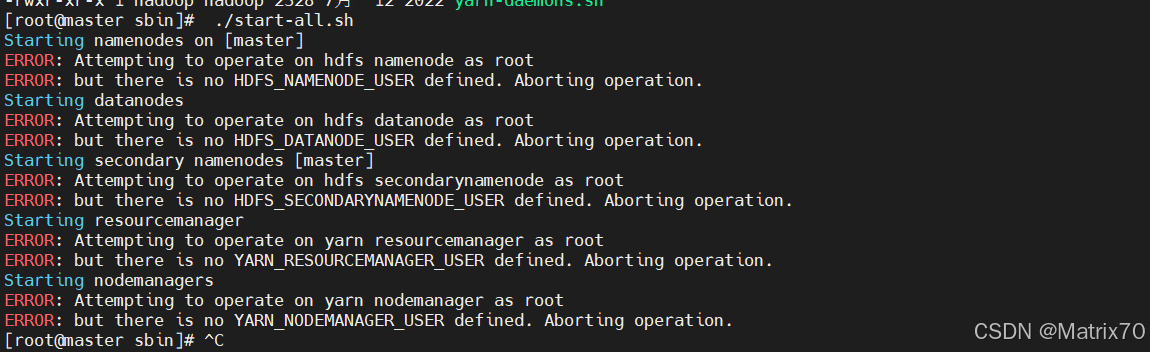
解决方案一:
(有风险,root 用户拥有系统的最高权限,如果 Hadoop 服务存在漏洞,攻击者可能会利用这些漏洞获取 root 权限,从而完全控制系统。如果 Hadoop 以 root 用户运行,生成的文件和目录可能会以 root 用户权限创建,这可能导致其他用户无法访问或修改这些文件)
vi /etc/profile
然后添加即可,这个我在上面的配置中已经添加了。
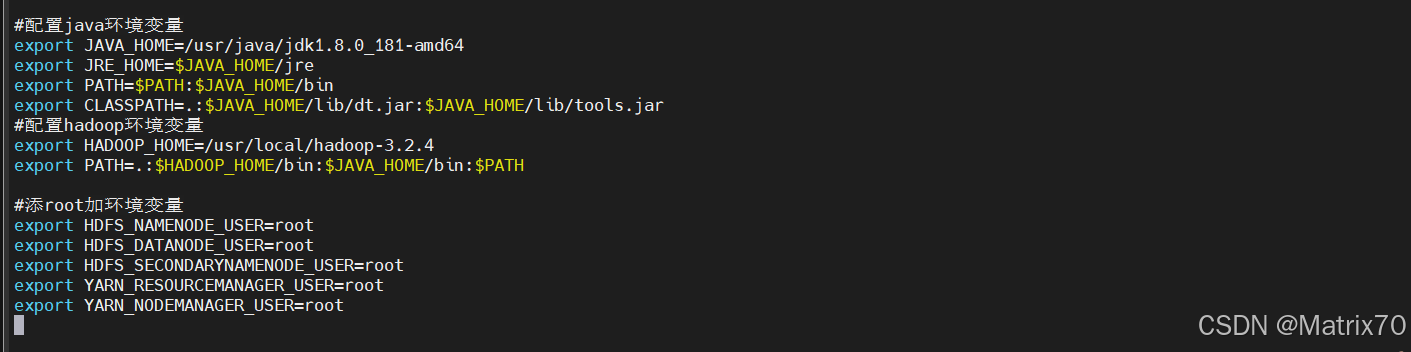
#添root加环境变量
#告诉 Hadoop 使用 root 用户来启动和管理相应的服务
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
测试Hadoop集群实例
一、蒙特卡洛方法
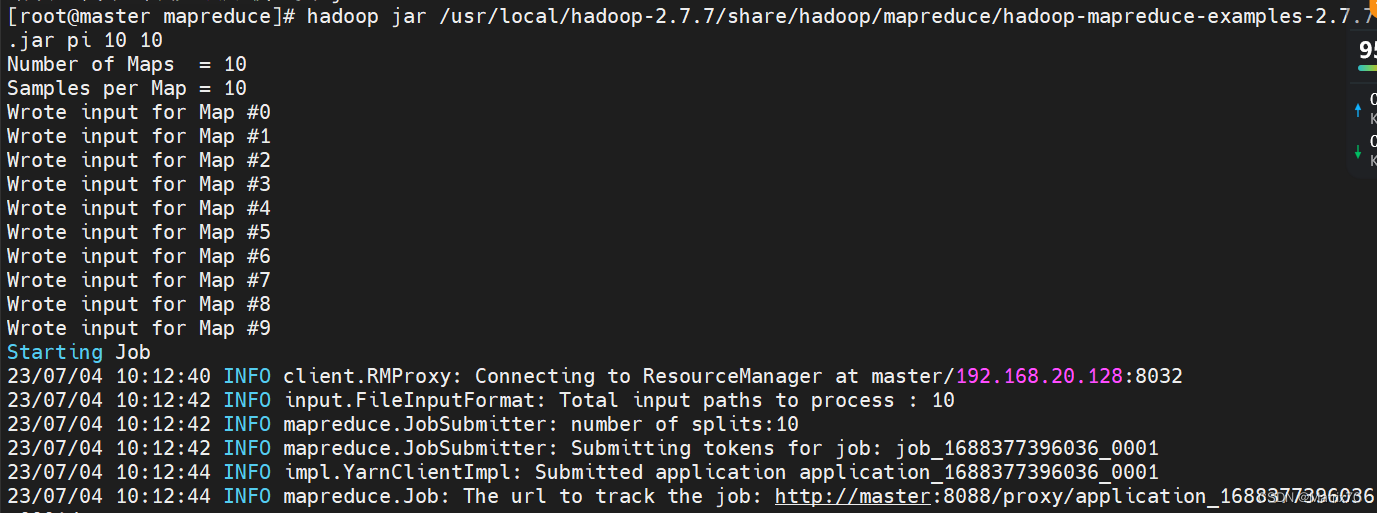
进入到 /usr/local/hadoop-2.7.7/share/hadoop/mapreduce看看jar包是否存在,再执行下面语句:
hadoop jar /usr/local/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10出现下面的情况,说明我们的hadoop安装成功了
一、测试mapreduce时可能会出现问题和解决方案:
问题1、搭建好Hadoop环境后,执行命令测试MapReduce环境出现如下错误:
Hadoop之hadoop-mapreduce-examples测试执行及报错处理_恒悦sunsite的博客-优快云博客
hadoop :java.io.FileNotFoundException: File does not exist:_wx5caecf2ed0645的技术博客_51CTO博客
java.io.FileNotFoundException: File does not exist: hdfs://xxx_FishMAN_已存在的博客-优快云博客
hadoop jar /usr/local/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10
.....
java.io.FileNotFoundException: File does not exist: hdfs://master:9000/user/root/QuasiMonteCarlo_1688449896784_1689988777/out/reduce-out
at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
......

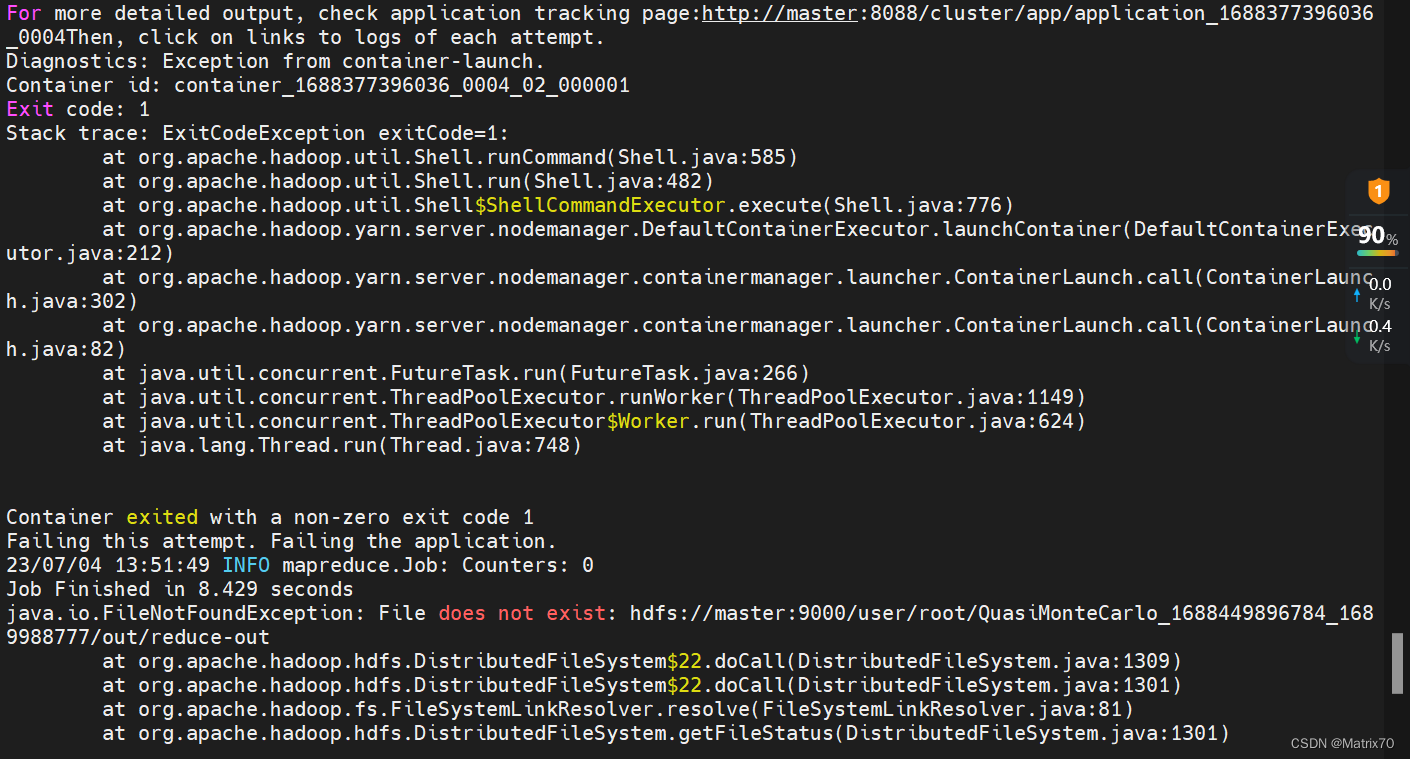

问题分析:看这条,
java.io.FileNotFoundException: File does not exist: hdfs://master:9000/user/root/QuasiMonteCarlo_1688449896784_1689988777/out/reduce-out
说是找不到文件,什么文件?怎么创建?再查资料,可能是找不到主类?并不是,再查,是否是hadoop文件的配置和项目代码的引用配置文件是否冲突了?并没有,
可能是java环境配置问题,还有一个可能是执行语句写错了,检查配置文件,没啥问题啊!!
解决:我切换到hadoop用户,再切换回来root用户,在执行就行了?!!!!!
这是什么鬼?
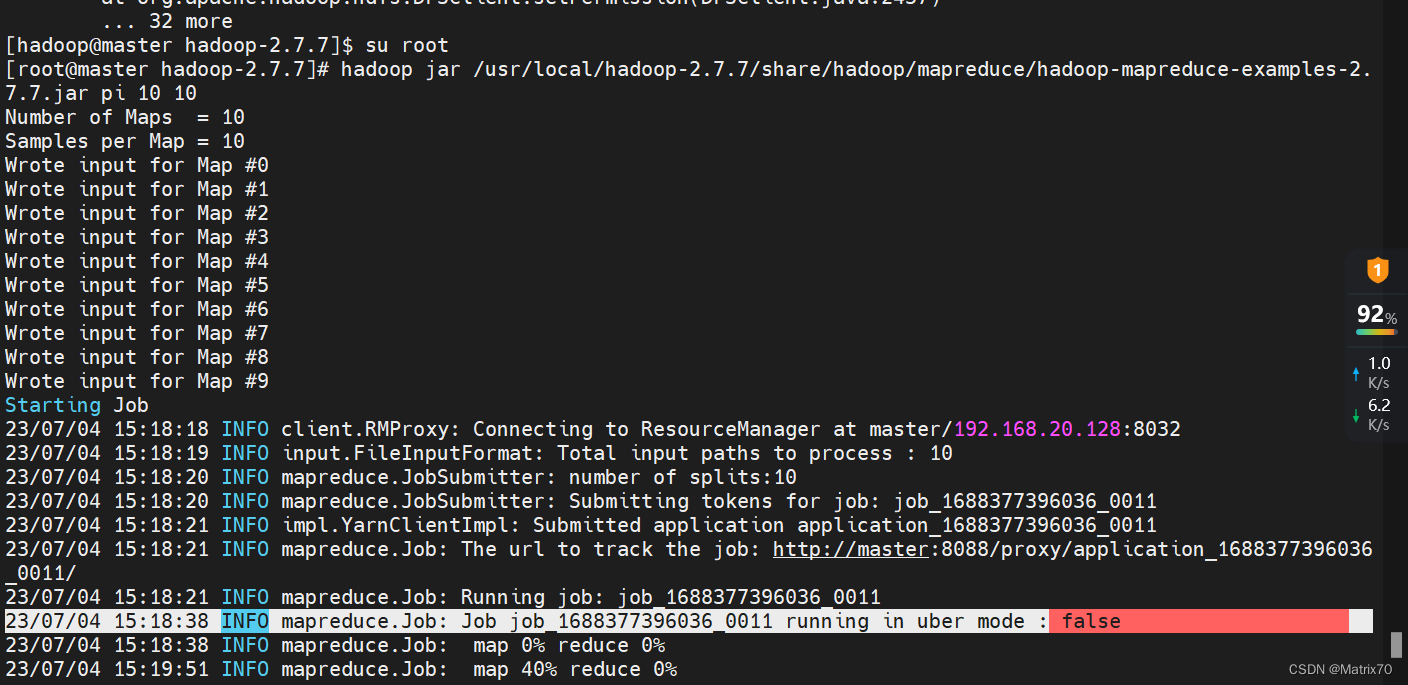
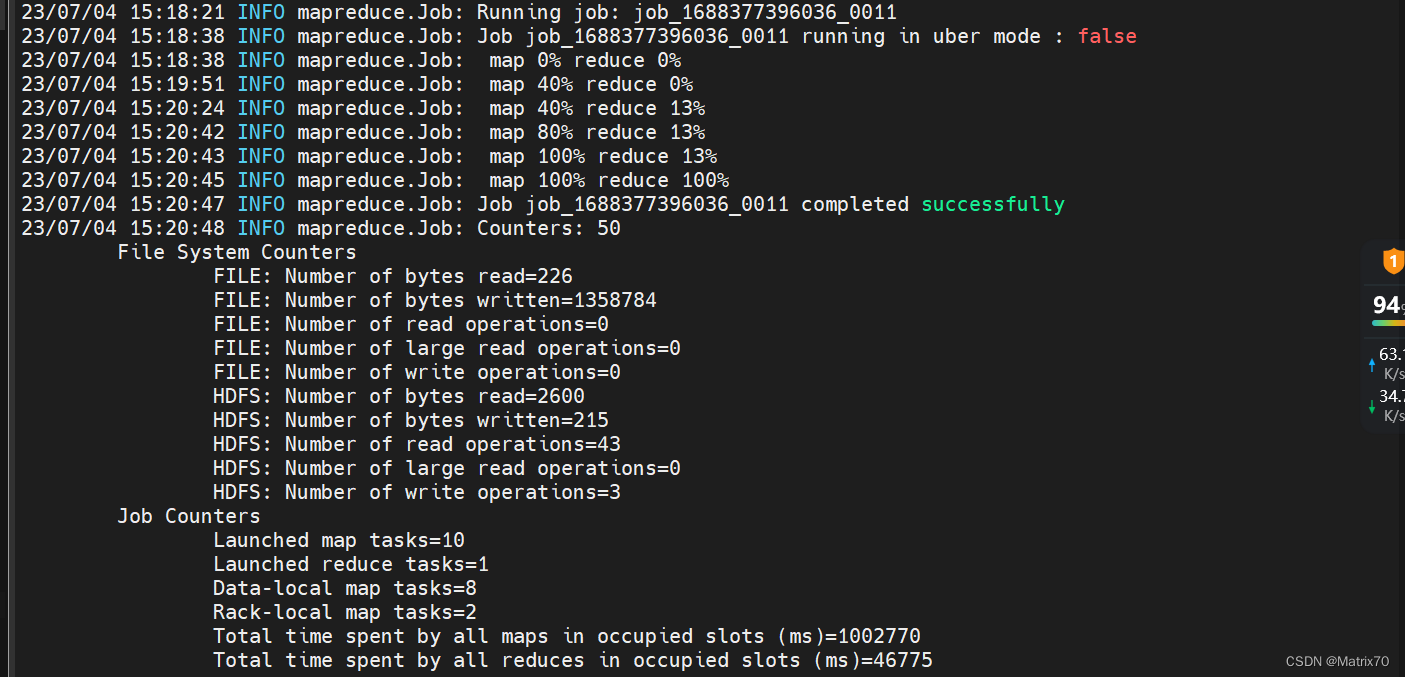

shit! 消耗好几个小时。。。。什么鬼。
问题2:我在测试hadoop3.2.4时候出现这个问题,错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
hadoop jar /usr/local/hadoop-3.2.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar pi 10 10
[root@master mapreduce]# hadoop jar /usr/local/hadoop-3.2.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar pi 10 10
Number of Maps = 10
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
2025-03-04 10:14:00,983 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.44.128:8032
2025-03-04 10:14:01,534 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1741053733274_0002
2025-03-04 10:14:01,759 INFO input.FileInputFormat: Total input files to process : 10
2025-03-04 10:14:01,848 INFO mapreduce.JobSubmitter: number of splits:10
2025-03-04 10:14:02,471 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1741053733274_0002
2025-03-04 10:14:02,472 INFO mapreduce.JobSubmitter: Executing with tokens: []
2025-03-04 10:14:02,726 INFO conf.Configuration: resource-types.xml not found
2025-03-04 10:14:02,727 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2025-03-04 10:14:02,827 INFO impl.YarnClientImpl: Submitted application application_1741053733274_0002
2025-03-04 10:14:02,914 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1741053733274_0002/
2025-03-04 10:14:02,915 INFO mapreduce.Job: Running job: job_1741053733274_0002
2025-03-04 10:14:06,952 INFO mapreduce.Job: Job job_1741053733274_0002 running in uber mode : false
2025-03-04 10:14:06,956 INFO mapreduce.Job: map 0% reduce 0%
2025-03-04 10:14:06,981 INFO mapreduce.Job: Job job_1741053733274_0002 failed with state FAILED due to: Application application_1741053733274_0002 failed 2 times due to AM Container for appattempt_1741053733274_0002_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2025-03-04 10:14:06.696]Exception from container-launch.
Container id: container_1741053733274_0002_02_000001
Exit code: 1
[2025-03-04 10:14:06.732]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
[2025-03-04 10:14:06.732]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
For more detailed output, check the application tracking page: http://master:8088/cluster/app/application_1741053733274_0002 Then click on links to logs of each attempt.
. Failing the application.
2025-03-04 10:14:07,016 INFO mapreduce.Job: Counters: 0
Job job_1741053733274_0002 failed!
[root@master mapreduce]#
问题解决方案:
1、我是这么解决的:先永久设置 HADOOP_CLASSPATH
#编辑配置文件
vi /etc/profile
#添加下面的路径
export HADOOP_CLASSPATH=$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/l ib/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/hdfs/lib/*:$HADOOP_HOME/share /hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*:$HADOOP_HOME/share/hadoop/yarn/ *:$HADOOP_HOME/share/hadoop/yarn/lib/*
#source一下使其生效
source /etc/profile
2、然后再检查 yarn-site.xml 文件,确保 yarn.application.classpath 配置正确。我这里是没有配置这个。配置完,然后再跑就行了
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_HOME/share/hadoop/common/*,
$HADOOP_HOME/share/hadoop/common/lib/*,
$HADOOP_HOME/share/hadoop/hdfs/*,
$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOME/share/hadoop/mapreduce/*,
$HADOOP_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,
$HADOOP_HOME/share/hadoop/yarn/lib/*
</value>
</property>注意,完成后记得整一个快照,作为hadoop集群配置完成的备份
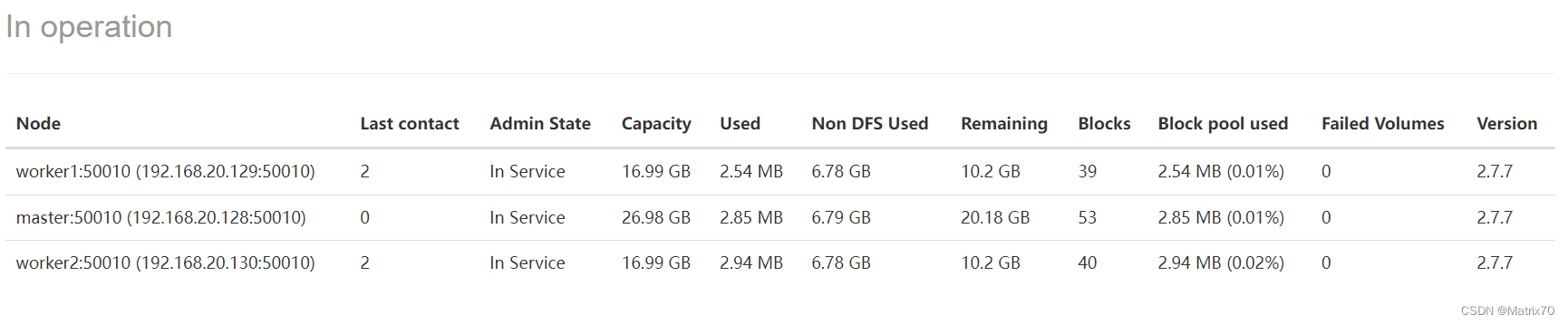
Hadoop集群的状态查看
我用的是谷歌浏览器,直接地址栏键入50070端口的链接,如果没配置hdfs对应的地址,就访问不了,可以一下hdfs-site.xml
以此查看DataNode与NameNode是否正常。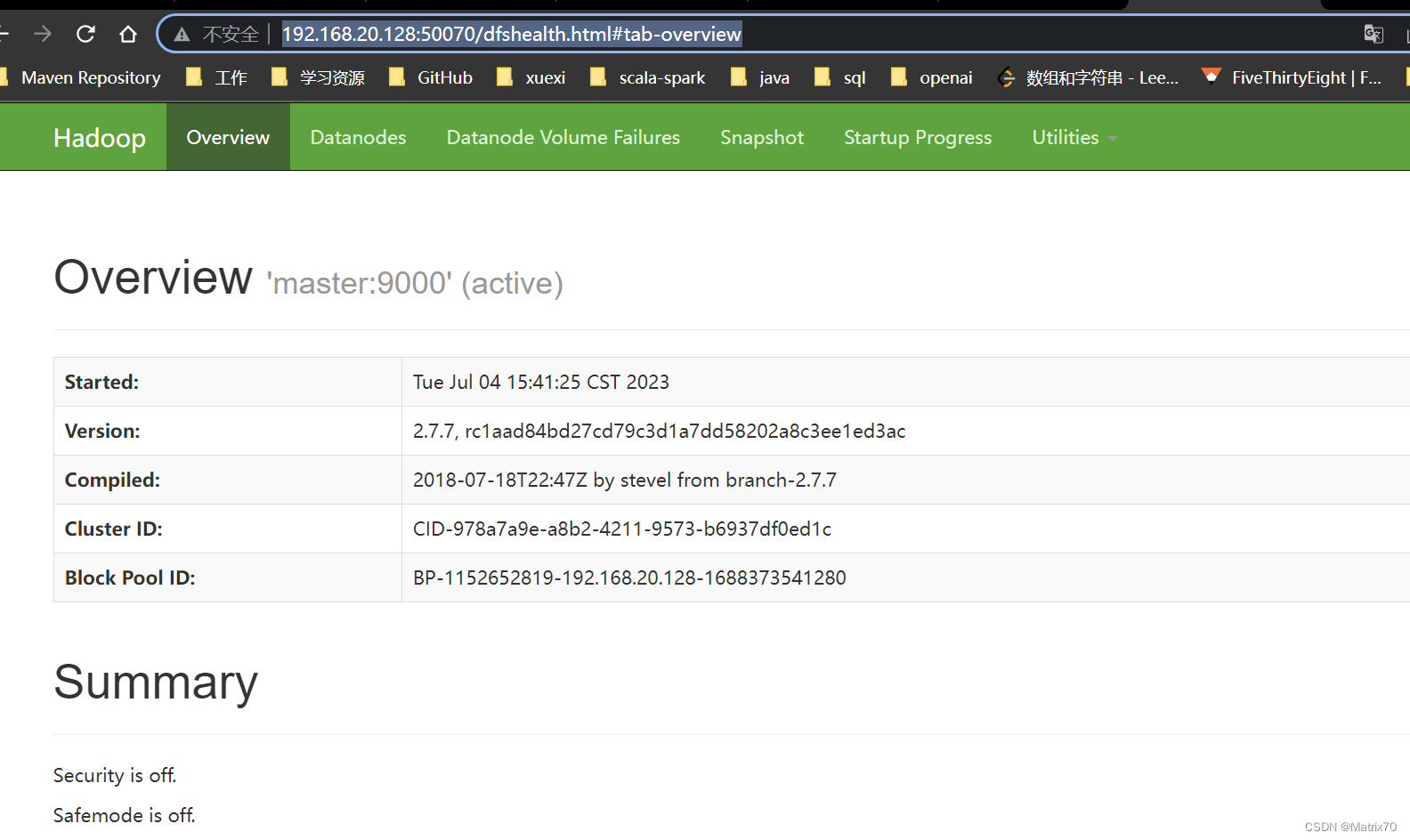
停止Hadoop
普通停止和分布式停止
1、普通停止:
在sbin目录下执行
./stop-all.sh
2、分布停止hadoop集群:
在sbin目录下执行 ./stop-dfs.sh 停止文件系统 ./stop-yarn.sh 停止yarn调度



















 5589
5589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











