






使用规则
1.最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。
2.索引失效情况
2.1在索引上进行运算符操作时索引失效。
- 未使用运算符查询时(根据电话号码查时走索引)
explain select * from tb_user where phone='17799990000'
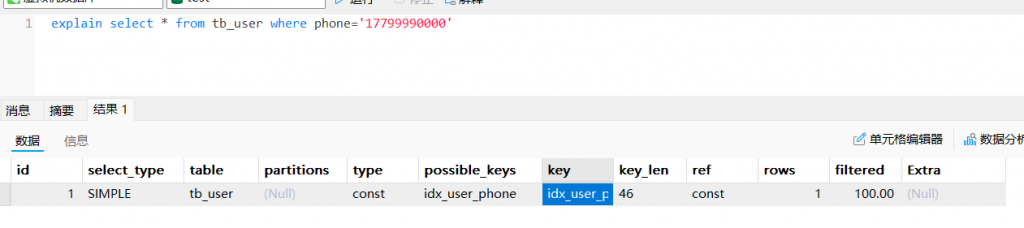
- 使用运算符查询时查询不走索引
explain select * from tb_user where substring(phone,10,2)='00'
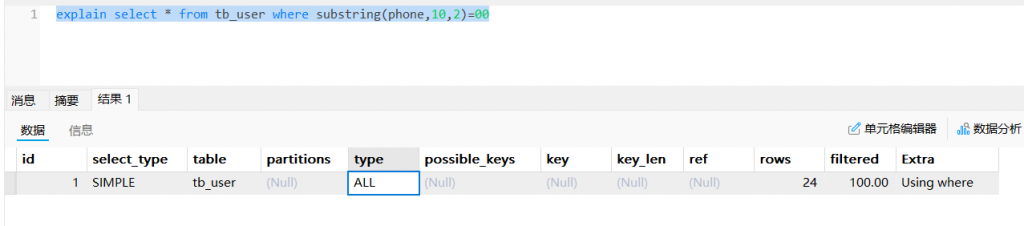
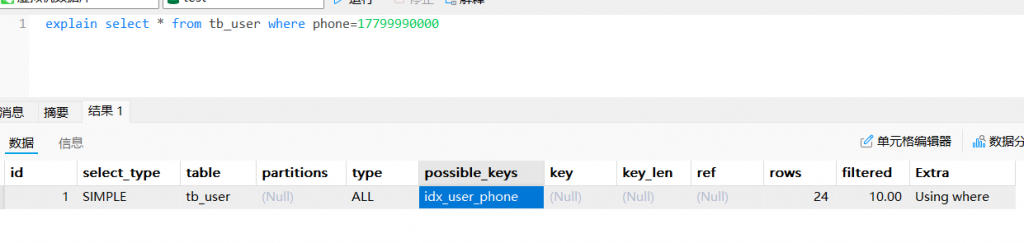
2.2字符串不加单引号索引失效(虽然不加单引号的时候也能查到数据单实际上是一个隐藏的类型转换)
- 并且在联合索引也会使后续的索引部分失效
explain select * from tb_user where phone=17799990000
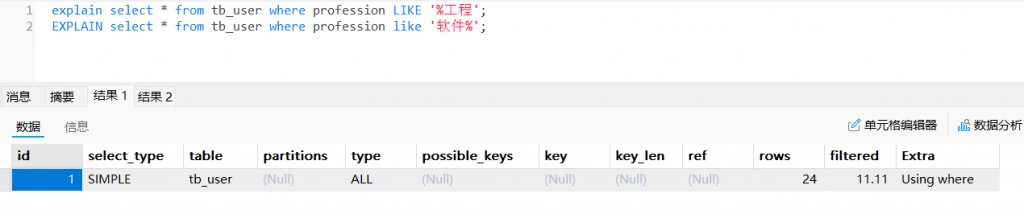
2.3模糊查询(头部的模糊匹配索引失效,尾部的模糊查询索引不失效)
explain select * from tb_user where profession LIKE '%工程';
EXPLAIN select * from tb_user where profession like '软件%';

2.4or连接的条件(用or分割还得条件,如果or前条件中有索引后条件没有用索引,所有条件将不会用到索引)
EXPLAIN select * from tb_user where age=23 OR id=10 ;

2.5数据分布影响(如果MySQL评估使用索引比全表更慢,则不使用索引)
3.sql提示
概述
SQL提示,是优化数据库的一个重要的搜段,简单来说,就是在SQL语句中加入一些人为的提示来优化操作的目的。
示列:当查询一个条件含有多个索引如:单列索引和联合索引时可以通过SQL提示来指定索引的使用
- use index:(建议使用单列索引,但MySQL会自行判断该索引是否高效从而判断是否接受该建议)
EXPLAIN select * from tb_user use INDEX(idx_user_pro) where profession=‘软件工程’

- ignore index:(忽略索引)
EXPLAIN select * from tb_user IGNORE INDEX(idx_user_pro) where profession='软件工程'

- force index:(强制使用索引)
EXPLAIN select * from tb_user FORCE INDEX(idx_user_pro) where profession='软件工程'

4.覆盖索引
概述
尽量使用覆盖索引(查询所有了索引,并且需要返回的列,在该索引中已经全部能够找到),减少select *
- using indexcondition:查询使用了索引,但是需要回表查询数据
- using Where;using index:查询使用了索引但数据都在索引中不需要回表
示列:
select * from tb_user where id=2;
select * from tb_user where name=‘Arm’
- 两条语句上面的效率高,因为上面可以直接通过id索引查到,而下面只能通过二级索引name查到id,再回表到聚集索引查询。
5.前缀索引
概述
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
5.1语法
create index idx_xxxx on table_name(column(n)) ;
示例:
- 为tb_user表的email字段,建立长度为5的前缀索引。
CREATE index idx_user_email_5 on tb_user(email(5));

5.2.前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
//通过获取所有字段时的选择性
select count(distinct email) / count(*) from tb_user ;
//通过获取前部分字段时的选择性
select count(distinct substring(email,1,5)) / count(*) from tb_user ;
6.单列索引与联合索引
-
单列索引:即一个索引只包含单个列。
-
联合索引:即一个索引包含了多个列。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
7.索引设计原理
-
针对于数据量较大,且查询比较频繁的表建立索引。
-
针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
-
尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
-
如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
-
尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
-
要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
-
如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
-
尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
-
要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
-
如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









