




深度森林目标
| 目标:解决深度学习是否可以用不可微模块实现的问题 |
| 笔记: 1、什么是可微分模块? 在深度学习中,尤其是基于神经网络的模型中,“可微分”是一个非常重要的概念。它指的是模型的输出相对于其参数的导数是存在的且可以计算的。这个特性使得我们能够利用梯度下降等优化算法来训练模型,即通过不断调整参数,使得模型的输出与真实值之间的误差最小化。 神经网络之所以成功,很大程度上归功于其可微分的特性。 神经网络中的每个神经元都执行一个简单的数学运算,这些运算都是可微分的。通过将这些可微分的运算层层叠加,就构成了一个复杂的神经网络。 2、什么是非可微分模块? 与可微分模块相反,非可微分模块是指其输出相对于输入或参数的导数不存在或难以计算的模块。这些模块通常涉及到一些离散的操作、搜索过程或符号运算,这些操作在数学上是不可微的。 常见的非可微分操作包括:
离散化操作举例:
搜索和优化问题举例:
符号运算: 符号运算是指对数学表达式中的符号进行操作,而不是对具体的数值进行计算。这些符号可以代表变量、常数、函数等。在符号运算中,我们关注的是表达式的结构和变换,而不是求得一个具体的数值结果。符号代表的是一个概念,而不是一个具体的数值。对于符号的操作,我们很难定义一个连续的、可导的函数。 |
gcForest
| 深度神经网络中的表征学习主要通过逐层处理原始数据中的特征来实现。 |
| 笔记: Representation learning (表征学习):
Deep neural networks (深度神经网络):
Layer-by-layer processing (逐层处理):
Raw features (原始特征):
深度神经网络通过逐层堆叠多个隐藏层,来对原始数据进行逐层处理。每一层都会学习到比上一层更抽象、更复杂的特征。最终,通过这些层层递进的特征提取,神经网络可以学习到对任务有用的高层语义特征,从而实现对数据的准确分类或预测。 举个例子: 假设我们要训练一个神经网络来识别猫的图片。
|
接下来讲gcForest的级联森林结构,先补充几个概念。
信息增益 |
| 信息增益(Information Gain)用于衡量一个特征对于分类任务的重要性。简单来说,它告诉我们使用某个特征来划分数据集能够带来多少信息增益,也就是能够让数据集变得多“纯”。 举个例子: 你有一堆水果,你需要根据颜色、形状等特征来将它们分类。信息增益就像一个工具,可以帮你找出哪个特征最能有效地将水果分到正确的类别中。 信息增益越大,说明使用这个特征进行划分后,数据集的纯度提高得越多,这个特征也就越重要 在决策树算法中,我们通常选择信息增益最大的特征作为节点的划分属性。这样可以保证每次划分都能最大程度地减少数据集的不确定性,从而构建出更准确的决策树。 |
决策树 |
| 决策树通过一系列规则对数据进行分类或回归。其结构就像一棵树,从根节点开始,通过分支节点不断向下延伸,最终到达叶子节点。每个节点代表一个属性测试,每个分支代表一个测试结果,而叶子节点则对应于最终的分类结果或数值。 决策树的工作原理:
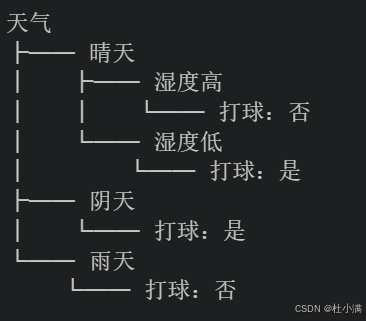
举个例子: 假设我们想要根据天气情况来决定是否打球。 我们收集了一些历史数据,包括天气(晴天、阴天、雨天)、温度(高、低)、湿度(高、低)以及是否打球(是、否)。 构建决策树
最终得到的决策树可能如下:
解释决策树:
|
随机森林:由决策树构成的强大集成学习算法 |
| 什么是随机森林: 随机森林(Random Forest)是一种集成学习方法,它通过构建多棵决策树,并对这些树的预测结果进行投票表决(分类)或取平均值(回归)来实现最终的预测。 随机指的是在构建每棵决策树的过程中,会引入随机性,以减少过拟合的风险并提高模型的泛化能力。 (核心思想就是多棵决策树投票表决) 随机森林的工作原理:
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1403
1403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









