







字节流介绍
一切文件数据(文本、图片、视频等)在存储时,都是使用二进制的形式保存都可以通过字节流进行数据传输
字节流顶层抽象基类InputStream和OutputStream
InputStream:字节输入流
声明:
public abstract class InputStream implements Closeable
InputStream是一个抽象类,是字节输入流的顶层抽象,所有的字节输入流的类都是其子类, 实现了Closeable接口,该接口中提供close方法,流使用结束后需要显性关闭
输入流是读操作,提供读相关方法:
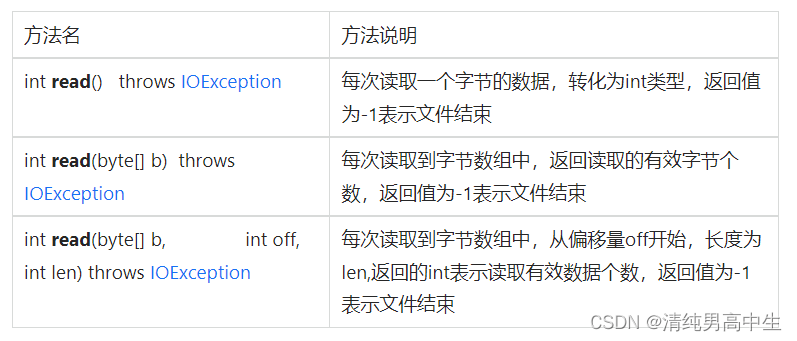
流读取的操作流程
1、打开流:new FileInputStream
2、流读取:read
3、关闭流
String path = "/Users/gongdezhe/Desktop/IO/test1.txt";
InputStream inputStream = null;
try {
//1、打开流,可能会抛出FileNotFoundException,即给定的文件不存在时抛出异常
inputStream = new FileInputStream(path);
System.out.println("打开流成功");
/**
* long skip(long n)
* 表示跳过多少要读取的数据 n表示跳过的数据
* n需要在有效范围内
*/
// inputStream.skip(6);
/**
* int available()
* 还有有效的数据个人
*/
//读取数据
/**
* int read()
* 每次读取一个字节 会抛出IOException异常
* 返回结果表示读取的字节数据
*/
int read = inputStream.read();
System.out.println((char)read);
System.out.println(inputStream.available());
int read1 = inputStream.read();
System.out.println((char)read1);
System.out.println(inputStream.available());
/**
* int read(byte b[])
* 批量读,每次读取数据到byte数组中
* 返回值表示读取的有效数据个数
*/
byte[] bytes = new byte[10];
// int read = inputStream.read(bytes);
// System.out.println(new String(bytes,0,read));
/**
* int read(byte b[], int off, int len)
* 第一个参数:表示将数据从内核读取到用户缓冲区域byte
* 第二个参数:byte数组的偏移量
* 第三个参数:表示需要读取的长度
*
* 注意:参数中off要小于字节数组,且off+len <字节数组
*/
// int read = inputStream.read(bytes, 3, 7);
//inputStream.read(bytes);
// System.out.println(new String(bytes));
// //多个数据如何读,循环读
// int i = 0;
// while ((i = inputStream.read(bytes)) != -1) {
// //第一次 as
// //第二次 df
// //第三次 sf
// System.out.print(new String(bytes,0,i));
// }
// System.out.println();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (inputStream != null) {
try {
//将关闭流放在finally
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件输入流:
FileInputStream:文件输入流,从源设备是文件
public class FileInputStream extends InputStream
是InputStream的具体实现类
构造函数:
FileInputStream(String path) throws FileNotFoundException
FileInputStream(File file) throws FileNotFoundException
当传入的文件不存在是,运行时会抛出FileNotFoundExeception异常
读操作:
public int read() throws IOException {
return read0();
}
private native int read0() throws IOException;
private native int readBytes(byte b[], int off, int len) throws IOException;
底层调用的是read0或者readBytes的native方法
读取操作注意点:
1、如何判断数据是否读取结束 ,通过-1表示读取结束
2、读取全部文件 循环读取数据(关注每次读取数据的有效个数)
OutputStream:字节输出流
OutputStream是字节输出的基类
public abstract class OutputStream implements Closeable, Flushable
核心方法:
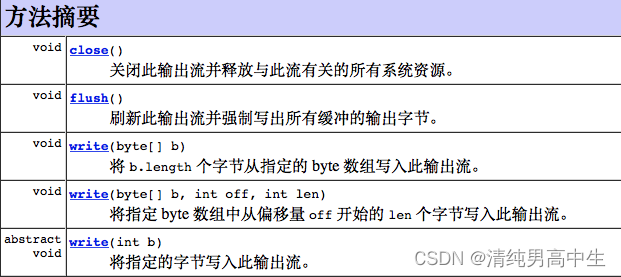
文件输出流
FileOutputStream:将数据写入目标设备:文件
构造函数:
FileOutputStream(String name) throws FileNotFoundException
FileOutputStream(String name, boolean append) throws FileNotFoundException
FileOutputStream(File file) throws FileNotFoundException
FileOutputStream(File file, boolean append) throws FileNotFoundException
当文件不存在时,会创建出指定文件,当路径不存在时,会抛出FileNotFoundException异常
append默认是false,表示写入的数据会覆盖文件原本内容,如果append为true,可以进行内容追加,将新写入的内容追加到文件的后面
方法调用:
String path = "/Users/gongdezhe/Desktop/IO/test1.txt";
FileOutputStream outputStream=null;
try {
outputStream = new FileOutputStream(path);
//写一个字节
/**
* void write(int b) throws IOException
* 每次写一个字节
*/
// outputStream.write('d');
/**
* void write(byte b[])
* 批量写:byte数组内容写入到底层
*
*/
byte[] bytes = {'a', 'b', 'c'};
// outputStream.write("hello".getBytes());
/**
* void write(byte b[], int off, int len) throws IOException
* 批量写
* 第一个参数:数据源 byte数组
* 第二个参数:偏移量 从byte数组指定偏移量写
* 第三个参数:长度,从偏移量开始写的长度
*/
byte[] bytes1 = "hello tulun".getBytes();
outputStream.write(bytes1,6,5);
//将数据刷入磁盘
outputStream.flush();
练习:拷贝功能
/**
* 拷贝功能
*
* @param sourPath :源地址
* @param DestPath :目的地址
*/
public static void copyFile(String sourPath, String DestPath) {
/**
* 源地址:将数据读取出来,FileInputStream
* 目的地址:将数据写入,FileOutputStream
*/
File file1 = new File(sourPath);
if (!file1.exists()) {
System.out.println("源文件不存在,结束拷贝");
return;
}
FileInputStream fis = null;
FileOutputStream fop = null;
try {
fis = new FileInputStream(file1);
fop = new FileOutputStream(DestPath);
byte[] bytes = new byte[1024];
int len = 0;
//不断循环读出并写入目的地
while ((len = fis.read(bytes)) != -1) {
fop.write(bytes, 0, len);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (fis != null) {
fis.close();
}
if (fop != null) {
fop.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
字符流:
Reader:字符输入流
Reader是IO库提供到的一个输入流基类
和InputStream的区别是:InputStream是一个字节流,操作的是以byte为单位读取
Reader是一个字符流,操作的是以char为单位读取
public abstract class Reader implements Readable, Closeable
读取方法:
public int read() throws IOException
public int read(char cbuf[]) throws IOException
public int read(char cbuf[], int off, int len) throws IOException
public int read(java.nio.CharBuffer target) throws IOException
Writer:字符输出流
字符输出流,
Writer操作的是字符,以char为单位进行操作
OutputStream操作的是字节,以byte为单位操作
Writer操作带有编码装换器的OutputStream
Reader操作带有编码转换器的InputStream
Writer的声明形式
public abstract class Writer implements Appendable, Closeable, Flushable {
提供方法:

FileReader
主要从磁盘文件中读取数据
FileWriter
向磁盘文件中写入数据
关于构造函数:注意:当路径不存在时,会抛出FileNotFoundExeption异常
读取操作:
//读取数据
int read = fd.read();
System.out.println((char) read);
/**
* int read(char cbuf[]) throws IOException
* 批量读取操作
* 读取的数据放入char数组中
* 返回结果表示读取数据的有效个数
*/
char[] chars = new char[12];
int read1 = fd.read(chars);
System.out.println(new String(chars,0,read1));
/**
* int read(char cbuf[], int offset, int length)
* 批量读取
*/
fd.read();
FileWriter操作
文件的写操作
构造函数:

构造函数注意:
1、如果文件不存在可以自动创建,如果目录不存在,则抛出异常
2、如果需要将写入的数据以追加的形式存储,需要传递append参数为true
方法介绍:
FileWriter fw = null;
try {
fw = new FileWriter(path,true);
/**
* void write(int c)
* 每次写入一个字符的ASCII码
*/
// fw.write('a');
/**
* void write(char cbuf[])
* 批量写入
* 将char数组内容写入
*/
char[] chars = {'a', 'b', 'c'};
// fw.write(chars);
/**
* void write(char cbuf[], int off, int len)
* 批量写入char数组
*/
// fw.write(chars,0,3);
/**
* void write(String str)
* 写入字符串
*/
// fw.write("hello");
/**
* void write(String str, int off, int len)
* 写入部分字符串
* off指定字符串的偏移量 len表示写入的长度
*/
// fw.write("hello",0,5);
fw.append(" tulun");
fw.flush();
高级流介绍:
转换流:
将字节流和字符流进行相互转换
OutputStreamWriter:将字节输出流转换为字符输出流
InputStreamReader:将字节输入流转换为字符输入流
public class OutputStreamWriter extends Writer
public OutputStreamWriter(OutputStream out) {
super(out);
try {
se = StreamEncoder.forOutputStreamWriter(out, this, (String)null);
} catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
public class InputStreamReader extends Reader
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object
} catch (UnsupportedEncodingException e) {
// The default encoding should always be available
throw new Error(e);
}
}
InputStreamReader
Reder和InputStream的关系
普通的Reader实际上是基于InputStream改造的,因为Reader需要从INputStream中读取字节流(byte),然后根据编码设置,在转化为字符流(char),在底层实现上持有一个转换器(StreamDecoder)
//字节流
//原始流
FileInputStream inputStream = new FileInputStream(path);
//高级流,通过封装原始流提供高级特征
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
缓冲流:
提高IO读写速度
缓冲流划分:字节缓冲流、字符缓冲流
字节缓冲流:BufferedInputStream、BufferedOutputStream
字符缓冲流:BufferedReader、BufferedWriter
以字符缓冲流为例介绍
字符输出流: String readLine() 分行读取 读取结束为null
字符输入流: void newLine() 根据当前系统,写入一个换行符
对象流:
序列化和发序列化
序列化:将对象转化为字节流的过程,可以将流进行保存到磁盘或者是发送到网络中(rpc)
反序列化:将字节流转化为对象的过程
序列化的特点:
1、在Java中,只要一个类实现了Serializable接口,那么就可以支持序列化和反序列化
2、通过ObjectInputStream和ObjectOutputStream对对象进行序列化和发序列化
3、transient关键字用于控制变量的序列化,在变量前添加该关键字,可以阻止该字段被序列化到文件中,在反序列化后,transient关键字修饰的变量给定的就是初始化,对象类型是null,int类型是0
4、虚拟机是否允许反序列化,不仅仅取决于类路径和代码是否一致,还要看两个类的序列化Id是否一致
什么是serialVersionUID?
称之为版本标识符,使用对象的哈希码序列化会标记在对象上
两种生成方式,
一种是默认的1L
另一种是通过类名、接口名、成员变量及属性等生成的64位的哈希字段,UID的生成的默认值是依赖于Java编译器的,对于同一个类,不同的编译器生成的结果UID可能是不同
版本号的作用:
1、确保不同的版本有不同的UID
2、在类中新增或者修改属性,不设置UID,会抛出异常
对象流的处理使用ObjectInputStream和ObjectOutputStream类
以ArrayList为例介绍序列化和反序列化
在ArrayList中定义了writeObject和readObject方法
在序列化的过程中,如果被定义的类中定义类writeObject,虚拟机会试图来调用类中writeObject方法来进行序列化,如果没有这个存在,调用默认的ObjectOutputStream中defaultWriteObject方法来序列化
反序列化的类似
对ArrayList集合进行序列化和反序列代码如下:
public static void objectReader() {
String path = "/Users/gongdezhe/Desktop/IO/test1.txt";
try {
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream(path));
ArrayList list = (ArrayList) inputStream.readObject();
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void objectWrite() {
String path = "/Users/gongdezhe/Desktop/IO/test1.txt";
ArrayList <Integer> list = new ArrayList <>(100);
list.add(11);
list.add(22);
list.add(33);
try {
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream(path));
outputStream.writeObject(list);
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
源码实现思路
在ArrayList中显性实现了WriteObject和ReadObject方法。
在堆ArrayList的对象进行序列化和反序列化过程中,会自动调用到ArrayList中定义的WriteObject和ReadObject方法,
在ArrayList中存储数据的属性定义为ElementData属性,该属性是通过transient关键字修饰
该关键字的目的是不让修改的属性参与序列化,而ArrayList中数据就存储在elementData中,如果不参与序列化,则ArrayList中的数据则无法持久化
这就需要进行特殊处理
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
通过源码实现可知:在序列化的过程中(WriteObject),只对有效的数据参与了序列化,反序列化就拿到的是有效的数据
ArrayList中中writeObject或者readObject方法是如何调用的?
writeObject->writeObject0->writeOrdinaryObject->writeSerialData->invokeWriteObject


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









