







1 正向最大匹配算法
1.1 基础理论
正向最大匹配(Forward Maximum Matching)是一种基于规则的中文分词方法。它是最早被提出和广泛应用的分词算法之一。该算法从待分词的文本的开头开始,逐步匹配最长的词语,直到整个文本被分词完毕。
基本思想是将待分词的文本与一个预先构建好的词典进行匹配。词典中的词语按照长度从长到短排序,这样可以保证在匹配过程中优先匹配最长的词语。算法从文本的开头开始,尝试匹配词典中最长的词语,如果匹配成功,则将该词语作为一个分词结果,并将文本指针移动到匹配词语的后面继续匹配。如果匹配失败,则将文本指针向后移动一个字符,继续匹配下一个最长的词语,直到整个文本被分词完毕。
正向最大匹配算法的优点是简单高效,适用于大部分常见的中文文本。然而,它也存在一些缺点。由于仅考虑了最长匹配,可能会导致歧义和错误的分词结果。例如,对于词典中没有的新词或专有名词,算法可能无法正确分词。为了解决这些问题,可以通过引入更复杂的规则、使用更大的词典或结合其他分词算法进行改进。
如下图所示为具体作用流程:

1.2 代码实现
class forward_match:
def __init__(self,text,user_dict):
self.text = text
self.user_dict = user_dict
self.max_len = max([len(item) for item in user_dict]) #词典中最长的词语,防止匹配出错
def cut_forward(self):
result=[]
length = len(self.text)
index = 0
while length > 0:
#在开始新一轮的匹配之前先将word置为None
word = None
for size in range(self.max_len, 0, -1):
if length - size < 0:
continue
piece = self.text[index:index+size]
if piece in self.user_dict:
word = piece
result.append(word)
length -= size
index += size
break
# 没有匹配上输出单个字符
if word is None:
length-=1
index += 1
return result
2 反向最大匹配算法
2.1 基础理论
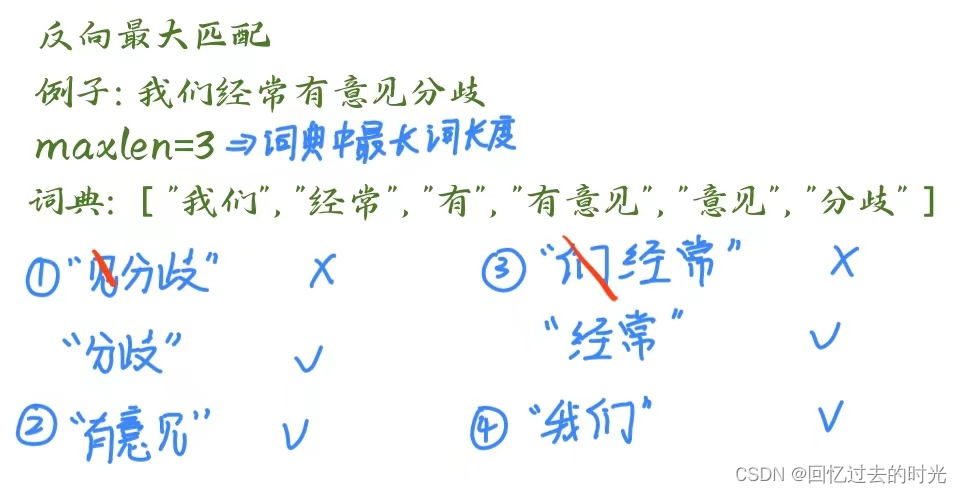
反向最大匹配(Reverse Maximum Matching)是一种基于规则的中文分词算法,与正向最大匹配算法相对应。它从待分词的文本的末尾开始,逐步匹配最长的词语,直到整个文本被分词完毕。
与正向最大匹配算法不同,反向最大匹配算法从文本的末尾开始,尝试匹配词典中最长的词语。如果匹配成功,则将该词语作为一个分词结果,并将文本指针移动到匹配词语的前面继续匹配。如果匹配失败,则将文本指针向前移动一个字符,继续匹配下一个最长的词语,直到整个文本被分词完毕。
反向最大匹配算法的思想与正向最大匹配算法类似,只是匹配的方向相反。它也具有简单高效的特点,适用于大部分常见的中文文本。然而,同样存在歧义和错误分词的问题,对于新词或专有名词可能无法正确分词。
如下图所示为具体作用流程:
2.2 代码实现
class backward_match:
def __init__(self,text,user_dict):
self.text = text
self.user_dict = user_dict
self.max_len = max([len(item) for item in user_dict]) #词典中最长的词语,防止匹配出错
def cut_backward(self):
result=[]
index = len(self.text)
while index > 0:
#在开始新一轮的匹配之前先将word置为None
word = None
for size in range(self.max_len, 0, -1):
if index - size < 0:
continue
piece = self.text[(index-size):index]
if piece in self.user_dict:
word = piece
result.append(word)
index -= size
break
# 没有匹配上输出单个字符
if word is None:
index -= 1
return result[::-1]
3 双向最大匹配算法
3.1 基础理论
双向最大匹配(Bidirectional Maximum Matching)是一种结合了正向最大匹配和反向最大匹配的中文分词算法。它通过同时从文本的开头和末尾开始匹配,然后根据一定的规则进行合并和消歧,得到最终的分词结果。
算法的基本思想是将待分词的文本分别使用正向最大匹配和反向最大匹配算法进行分词,得到两个分词结果。然后根据一定的规则进行合并和消歧,得到最终的分词结果。
合并规则可以根据具体需求进行设计,常见的规则包括:
- 长度优先:如果正向最大匹配和反向最大匹配得到的分词结果长度相同,优先选择正向最大匹配的结果。
- 单字词优先:如果正向最大匹配和反向最大匹配得到的分词结果中包含单字词,优先选择包含单字词的结果。
- 词频优先:如果正向最大匹配和反向最大匹配得到的分词结果中包含相同的词语,优先选择词频较高的结果。
通过合并规则,可以将正向最大匹配和反向最大匹配的结果进行合并,消除歧义,得到更准确的分词结果。
双向最大匹配算法在一定程度上克服了正向最大匹配和反向最大匹配算法的缺点,提高了分词的准确性。然而,它仍然无法解决所有的歧义问题,对于一些特殊情况仍可能出现错误的分词结果。
3.2 代码实现
class both_match:
def __init__(self,text,user_dict):
self.text = text
self.user_dict = user_dict
self.max_len = max([len(item) for item in user_dict]) #词典中最长的词语,防止匹配出错
def cut_both(self):
#正向最大匹配
word_forward = forward_match(self.text,self.user_dict)
result_forward = word_forward.cut_forward()
#反向最大匹配
word_backward = backward_match(self.text,self.user_dict)
result_backward = word_backward.cut_backward()
#返回分词数较少者
if (len(result_forward) != len(result_backward)):
if (len(result_forward) < len(result_backward)):
return result_forward
else:
return result_backward
else:#若分词数量相同,进一步判断
forward_single = 0
backward_single = 0
isEqual = True #用以标志结果是否相同
for i in range(len(result_forward)):
if(result_forward[i] != result_backward[i]):
isEqual = False
#统计单字数
if(len(result_forward[i])==1):
forward_single += 1
if(len(result_backward[i])==1):
backward_single += 1
if(isEqual):
return result_forward
if(forward_single < backward_single):
return result_forward
else:
return result_backward
4 总结
如下图所示是基于相同的词典对同一语句进行的分词结果:
从图中观察可知双向匹配算法是符合了长度优先这一原则,正向匹配算法的结果词语数量更少,因此输出的是正向最大匹配的结果。

对于这三种算法来说,最重要的还是要有一个完善的词典进行匹配,词典的好坏在极大程度上决定着分词的效果,目前在中文分词中已有一些开源的词典如jieba,哈工大LTP分词词典,ICTCLAS分词词典等,可根据实际使用的需要下载使用,或根据特定的使用场景自行构建词典。

















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









