




目录
简介:Selenium 是一套开源的自动化测试框架,主要用于 Web 应用程序的自动化测试。它支持多种编程语言(如 Python、Java、C#、JavaScript 等)和浏览器(Chrome、Firefox、Edge 等),可模拟用户操作(点击、输入、导航等),是 Web 自动化测试和爬虫开发的常用工具。
核心用途
-
Web 自动化测试
-
功能测试:模拟用户操作(登录、表单提交、页面跳转)。
-
回归测试:确保代码更新后原有功能正常。
-
-
网页数据抓取
-
处理动态加载内容(如 JavaScript 渲染的页面),比传统爬虫更强大。
-
-
自动化任务
-
自动填写表单、批量操作网页、监控网站变化等。
-
一、配置环境
1.安装Selenium
pip install selenium2.安装谷歌浏览器驱动
点击chrome浏览器最右侧的“三个点”图标,然后点击弹出的“帮助”中的“关于Google Chrome”,查看自己的版本信息。
找到自己版本的驱动,这样在下载对应版本的 Chrome 驱动即可(阿里云盘存有139.0版本的驱动)
打开 下载chromedriver.storage.googleapis.com/index.html。单击对应的版本。(这是国内的,没有最新的版本驱动)
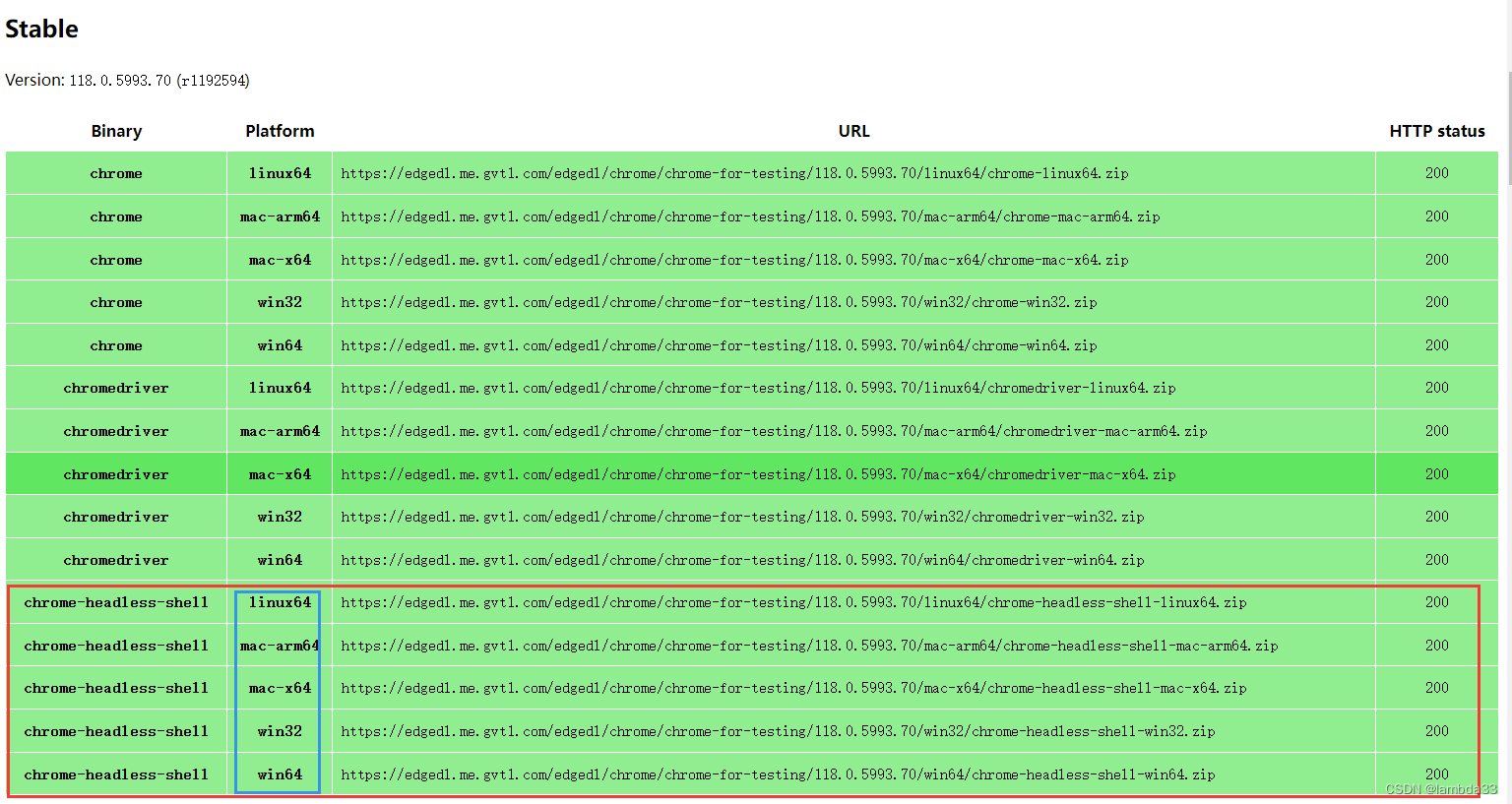
Chrome for Testing availability这是下载最新驱动的网址(记得是下载下面的)
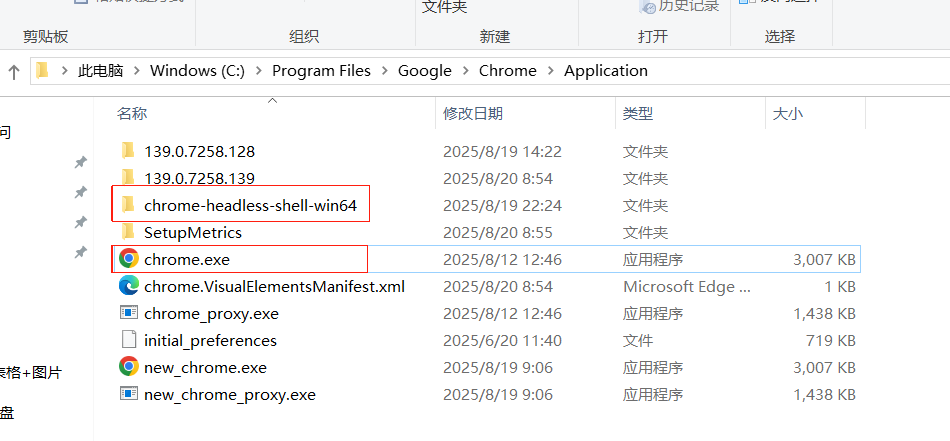
将 chromedriver.exe(或者驱动目录) 保存到任意位置,并把当前路径保存到环境变量
(环境变量--系统变量--path--新建--然后再把chromedriver.exe的路径放进去,在这里我的是C:\Program Files\Google\Chrome\Application\chrome-headless-shell-win64)。
(建议驱动目录保存在谷歌浏览器安装目录下)
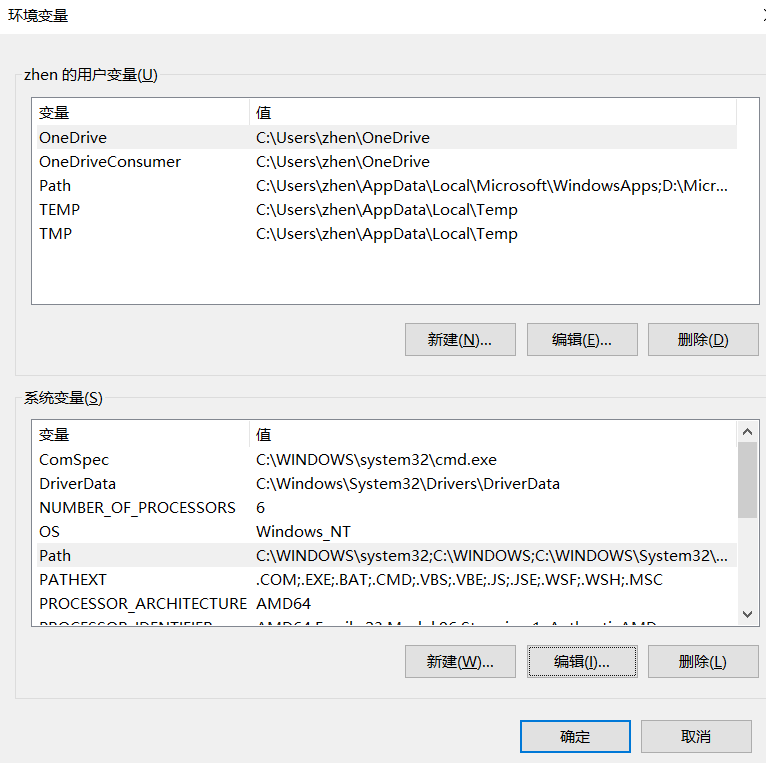
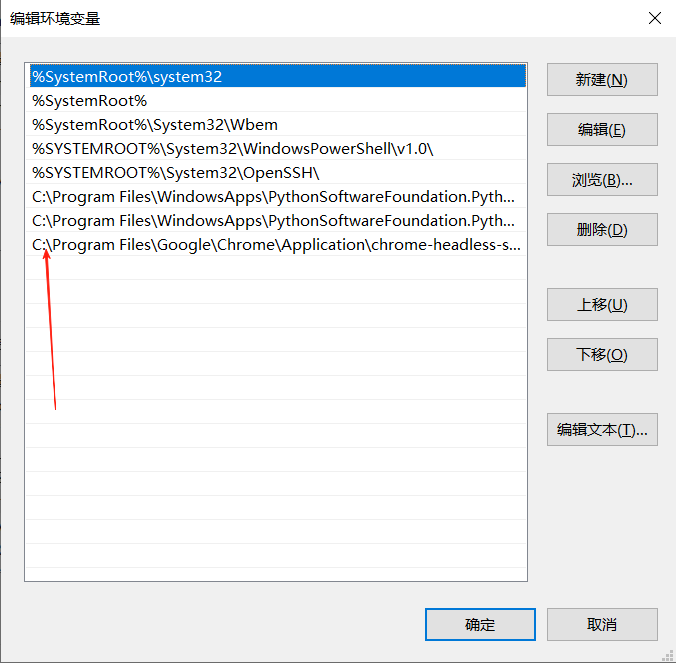
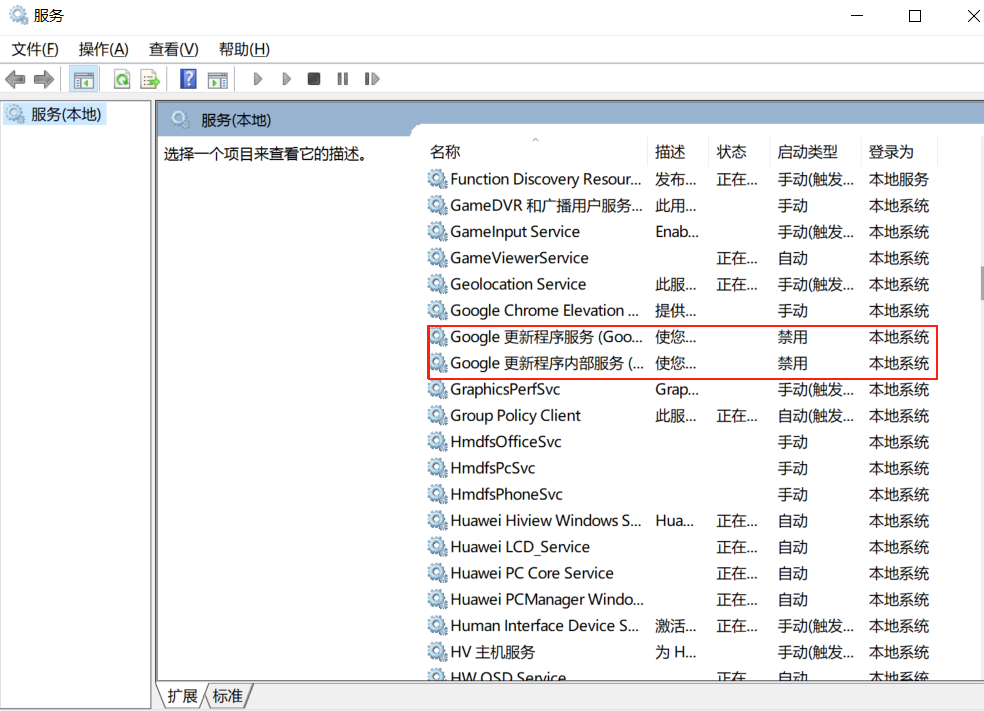
为了防止谷歌一直更新,导致驱动与谷歌版本号不匹配。现在我们将谷歌禁止自动更新,在电脑中搜索服务,在里面找到Google更新的字眼,然后右击属性,将他禁止。

添加驱动成功后使用下面代码进行测试。(能弹出谷歌就说明驱动安装成功了)
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
弹出谷歌之后就会闪退,我们需要用到延迟等待,下面我们用谷歌搜索一下百度试试(弹出百度界面说明可以正常使用了)
from selenium import webdriver
import time
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com/')
time.sleep(5)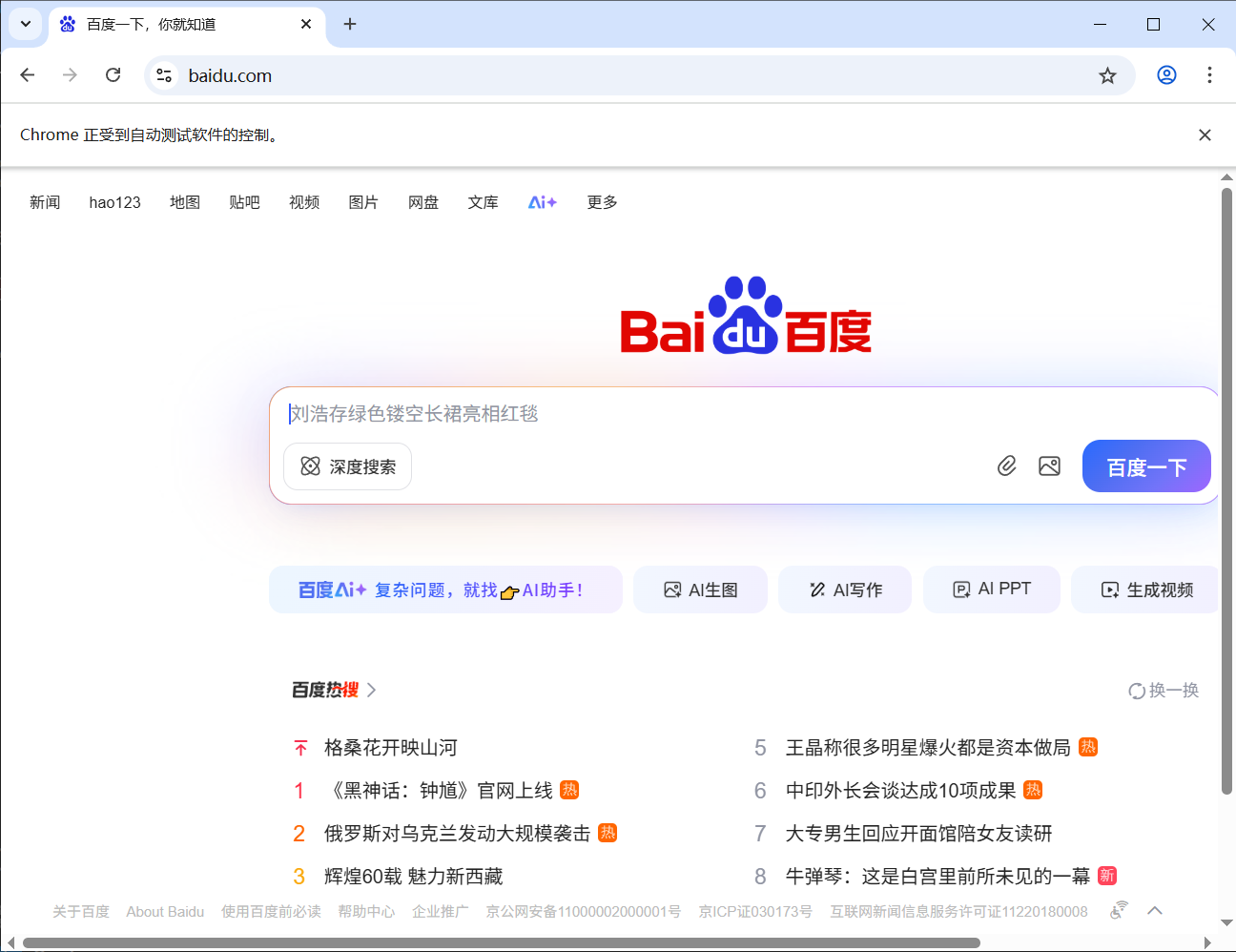
二、selenium基础知识
1.对页面进行操作
(1)初始化浏览器对象
前面我们已经把Chrome驱动添加到环境变量了,所以我们可以直接初始化界面。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 关闭浏览器
browser.close()
(2)访问页面用get()获取
也可以将网址保存在path中,这样后期更改网址方便。
这里网址中前面有个r:r表示"raw string"(原始字符串),它的作用是让字符串中的反斜杠 \ 不被解释为转义字符。
在这个特定的网址情况下,其实不需要使用r。
r主要用在文件路径或正则表达式中,因为这些地方经常包含反斜杠\:
path=r'https://www.baidu.com/'from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度
path='https://www.baidu.com/'
browser.get(path)
# 关闭浏览器
browser.close()
(3)设置浏览器大小
set_window_size(宽度,高度)方法可以用来设置浏览器大小(就是分辨率),而maximize_window则是设置浏览器为全屏。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get('https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500宽度*500高度
browser.set_window_size(500,500)
time.sleep(2)
# 关闭浏览器
browser.close()
(4)前进/后退页面。
forward()方法可以用来实现前进,back()可以用来实现后退。同理可得,在点击跳转页面之后,也可以用这个来实现前进和回退。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
#打开百度
browser.get('https://www.baidu.com')
#请求间隔两秒
time.sleep(2)
# 打开b站
browser.get('https://www.bilibili.com/')
time.sleep(2)
# 后退到百度
browser.back()
time.sleep(2)
# 前进到b站
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
(5)获取页面的基础属性
如网页标题、网址、浏览器名称、页面源码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
2.定位页面元素
按 【F12】 进入开发者工具。我们要做的就是从代码中定位获取我们需要的元素。进入之后,要是复制了Xpath,可以按【ctrl+f】组合键来搜索元素。
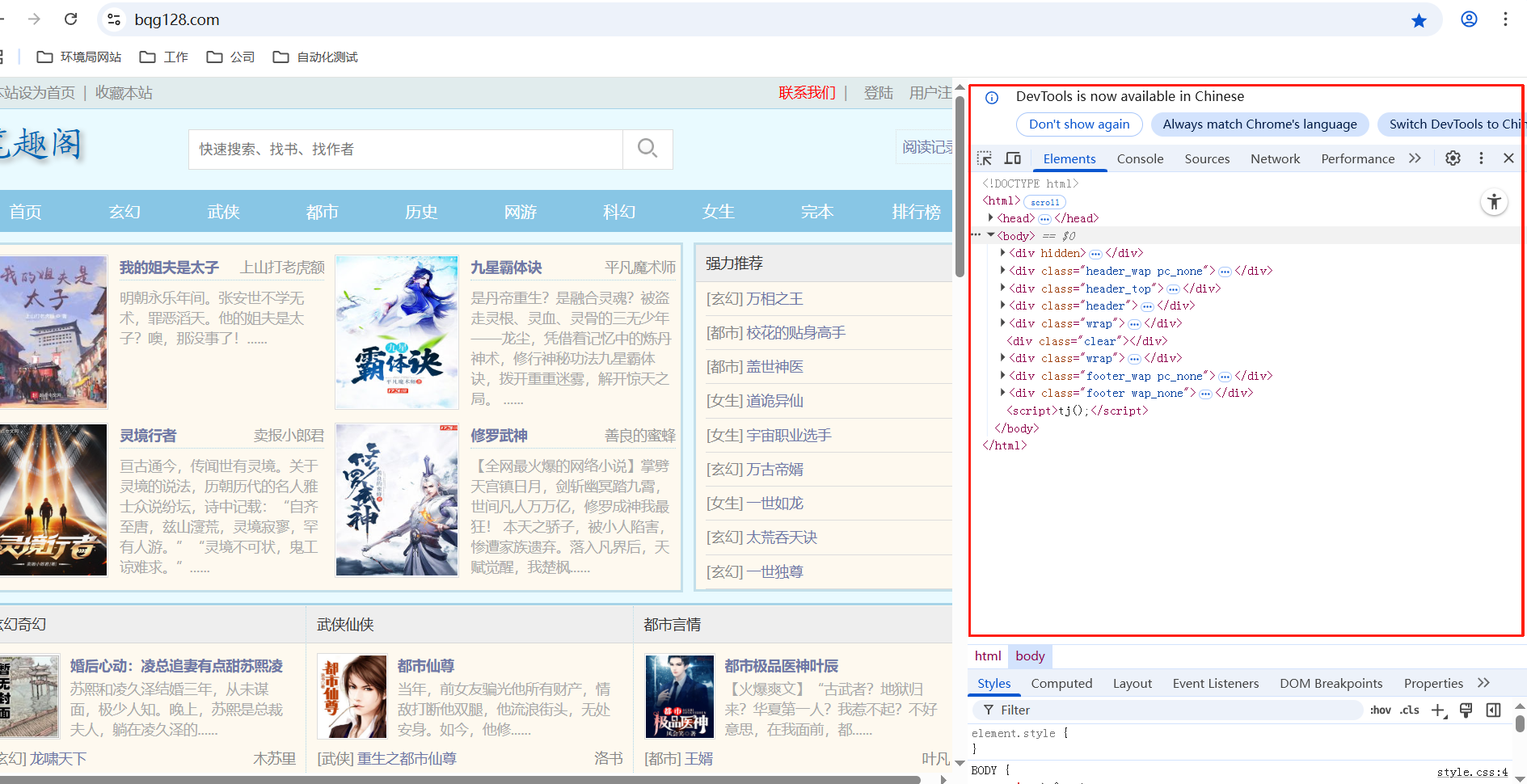
(1)定位元素
下面我们来介绍一些Selenium提供的一些方法。通过webdriver对象的 find_element(by=“属性名”, value=“属性值”)(通常用ID,会更准确)
| 属性 | 函数 |
| xpath | find_element(by=By.XPATH, value="") |
| link_text | find_element(by=By.LINK_TEXT, value="") |
| partial_link_text | find_element(by=By.PARTIAL_LINK_TEXT, value="") |
| tag_name | find_element(by=By.TAG_NAME, value="") |
| css_selector | find_element(by=By.CSS_SELECTOR, value="") |
| id | find_element(by=By.ID, value="") |
| class_name | ind_element(by=By.CLASS_NAME, value="") |
(2)常用定位(by参数)
from selenium.webdriver.common.by import By
# 定位ID为"username"的元素
username_input = driver.find_element(by=By.ID, value="username")
# 定位name为"email"的元素
email_input = driver.find_element(by=By.NAME, value="email"
# 定位class为"btn-primary"的元素
submit_btn = driver.find_element(by=By.CLASS_NAME, value="btn-primary")
# 定位第一个<div>元素
div_element = driver.find_element(by=By.TAG_NAME, value="div")
# 定位文本为"登录"的链接
login_link = driver.find_element(by=By.LINK_TEXT, value="登录")
# 定位包含"忘记密码"的链接
forgot_pw_link = driver.find_element(by=By.PARTIAL_LINK_TEXT, value="忘记密码")
#多种CSS选择器示例
element1 = driver.find_element(by=By.CSS_SELECTOR, value="input[type='text']")
element2 = driver.find_element(by=By.CSS_SELECTOR, value=".container > .header")
element3 = driver.find_element(by=By.CSS_SELECTOR, value="#submit-btn")
# 多种XPath示例
element1 = driver.find_element(by=By.XPATH, value="//input[@name='username']")
element2 = driver.find_element(by=By.XPATH, value="//div[@class='content']/p[1]")
element3 = driver.find_element(by=By.XPATH, value="//button[contains(text(),'提交')]")(3)百度搜索页面
进入百度,找到搜索框进行定位,找到元素,下面用的是ID,还可以使用CSS或者Xpath来定位。
(请求的时候要延迟等待time.sleep(4)或者隐式等待,不然页面可能会闪退)
登录界面会涉及到需要验证码识别登录(再继续学习Python OCR工具pytesseract详解)
网址:https://blog.youkuaiyun.com/u010698107/article/details/121736386
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 定位搜索框并输入文本
search_box = driver.find_element(by=By.ID, value="chat-textarea")
search_box.send_keys("Selenium自动化测试")
# 定位搜索按钮并点击
search_btn = driver.find_element(by=By.ID, value="chat-submit-button")
search_btn.click()
time.sleep(4)search_box = driver.find_element(by=By.XPATH, value='//*[@id="chat-textarea"]')3.模拟鼠标操作
导入ActionChains 类。
from selenium.webdriver.common.action_chains import ActionChains
(1)常见操作介绍
| 操作 | 函数 |
| 右击 | context_click() |
| 双击 | double_click() |
| 拖拽 | double_and_drop() |
| 悬停 | move_to_element() |
| 执行 | perform() |
(2)悬停操作
先找到元素定位,再用鼠标进行悬停。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
#设置全屏
driver.maximize_window()
# 创建ActionChains实例
actions = ActionChains(driver)
driver.get("https://www.baidu.com")
# 用ID定位到设置链接
settings = driver.find_element(By.ID, value="s-usersetting-top")
# 鼠标悬停操作
actions.move_to_element(settings).perform()
time.sleep(10)
print("鼠标已悬停在设置上")
(3)拖拽操作
这里只是举例说明,没有在网页上操作过。
# 拖拽元素从source到target
source = driver.find_element(By.ID, "draggable")
target = driver.find_element(By.ID, "droppable")
actions.drag_and_drop(source, target).perform()
# 或者使用:
# actions.click_and_hold(source).move_to_element(target).release().perform()
print("拖拽完成")(4)键盘组合操作
from selenium.webdriver.common.keys import Keys
search_box = driver.find_element(By.ID, "kw")
search_box.send_keys("selenium")
# Ctrl+A (全选)
actions.key_down(Keys.CONTROL).send_keys("a").key_up(Keys.CONTROL).perform()
# Ctrl+C (复制)
actions.key_down(Keys.CONTROL).send_keys("c").key_up(Keys.CONTROL).perform()
# 在新输入框粘贴
another_input = driver.find_element(By.ID, "another-input")
another_input.click()
actions.key_down(Keys.CONTROL).send_keys("v").key_up(Keys.CONTROL).perform()(5)模拟登录时的复杂操作
def complex_login_flow():
driver.get("http://example.com/login")
# 1. 输入用户名
username = driver.find_element(By.NAME, "username")
actions.click(username).send_keys("testuser").perform()
# 2. Tab键切换到密码框
actions.send_keys(Keys.TAB).perform()
# 3. 输入密码
actions.send_keys("password123").perform()
# 4. 回车登录
actions.send_keys(Keys.ENTER).perform()
print("登录流程完成")4.模拟键盘操作
(1)导入keys类并介绍
from selenium.webdriver.common.keys import Keys
| 操作 | 函数 |
| 删除键 | send_keys(Keys.BACK_SPACE) |
| 空格键 | send_keys(Keys.SPACE) |
| 制表键 | send_keys(Keys.TAB) |
| 回退键 | send_keys(Keys.ESCAPE) |
| 回车 | send_keys(Keys.ENTER) |
| 全选 | send_keys(Keys.CONTRL,‘a’) |
| 复制 | end_keys(Keys.CONTRL,‘c’) |
| 剪切 | send_keys(Keys.CONTRL,‘x’) |
| 粘贴 | send_keys(Keys.CONTRL,‘v’) |
| 键盘F1 | send_keys(Keys.F1) |
(2)百度搜索+回车
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
time.sleep(5)
# 定位百度输入框,并输入内容
driver.find_element("id","chat-textarea").send_keys("Selenium自动化测试")
# 定位百度输入框,按下回车键,以此代替点击搜索按钮
driver.find_element("id","chat-textarea").send_keys(Keys.ENTER)
time.sleep(5)from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
time.sleep(5)
#先定位到搜索框
search_box = driver.find_element(by=By.ID, value="chat-textarea")
#直接输入并回车
search_box.send_keys("Selenium自动化测试"+ Keys.ENTER)
time.sleep(5)from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
time.sleep(5)
#先定位到搜索框
search_box = driver.find_element(by=By.ID, value="chat-textarea")
#输入内容
search_box.send_keys("Selenium自动化")
#输入回车
search_box.send_keys(Keys.RETURN) # ENTER和RETURN效果相同
time.sleep(5)(3)常用组合键
我们经常使用的Ctrl+A,Ctrl+C都是组合键。在使用按键操作的时候我们需要借助一下send_keys()来模拟操作。
Keys.CONTROL也就是我们键盘上的Ctrl键。
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
time.sleep(5)
driver.find_element("id", "chat-textarea").send_keys("Selenium自动化测试")
#全选
driver.find_element("id", "chat-textarea").send_keys(Keys.CONTROL, 'a')
#复制
driver.find_element("id", "chat-textarea").send_keys(Keys.CONTROL, 'c')
#粘贴
driver.find_element("id", "chat-textarea").send_keys(Keys.CONTROL, 'v')
#粘贴
driver.find_element("id", "chat-textarea").send_keys(Keys.CONTROL, 'v')
time.sleep(5)(4)填写表单
#改成要填写表单的地址
driver.get("http://example.com/form")
#定位到元素
name_field = driver.find_element(By.NAME, "name")
# 填写表单并使用Tab键切换
name_field.send_keys("张三" + Keys.TAB + "25" + Keys.TAB + "zhangsan@email.com")5.延迟等待
需要等待一定的时间,整个页面才会完整的加载出来,所以我们用get()获取页面之后,需要延迟等待几秒,下面来介绍一下延迟等待的三种方式。(一般我都是用强制等待)
(1)强制等待
在执行get方法之后,执行time.sleep(n) 强制等待n秒。使用简单,但效率低下,正式文本中尽量避免使用。
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 强制等待5秒
time.sleep(5)(2)隐式等待(一般推荐)
implicitly_wait()设置等待时间,如果到时间有元素节点没有加载出来,就会抛出异常。
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
#隐式等待
driver.implicitly_wait(10)(3)显式等待
设置一个等待时间和一个条件,在规定时间内,每隔一段时间查看下条件是否成立,如果成立那么程序就继续执行,否则就抛出一个超时异常。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 创建WebDriverWait实例,设置最大等待时间10秒,轮询间隔0.5秒
wait = WebDriverWait(driver, timeout=10, poll_frequency=0.5)
# 等待元素可见
search_box = wait.until(EC.visibility_of_element_located((By.ID, "chat-textarea")))
# 等待元素可点击
search_btn = wait.until(EC.element_to_be_clickable((By.ID, "chat-submit-button")))
# 输入搜索词
search_box.send_keys("Selenium")
search_btn.click()(4)按回车关闭浏览器
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 创建WebDriverWait实例,设置最大等待时间50秒,轮询间隔0.5秒
wait = WebDriverWait(driver, timeout=50, poll_frequency=0.5)
# 等待元素可见
search_box = wait.until(EC.visibility_of_element_located((By.ID, "chat-textarea")))
# 等待元素可点击
search_btn = wait.until(EC.element_to_be_clickable((By.ID, "chat-submit-button")))
# 输入搜索词
search_box.send_keys("Selenium")
search_btn.click()
input("按回车键关闭浏览器") # 等待用户输入
driver.quit()6.切换操作
(1)窗口切换
switch_to.windows()
在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 switch_to.windows() 方法。
在点击跳转后,使用 switch_to 切换窗口,window_handles 返回的 handle 列表是按照页面出现时间进行排序的,最新打开的页面肯定是最后一个,这样用 driver.window_handles[-1] + switch_to 即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 key(别名) 与 value(handle),保存到字典中,后续根据 key 来取 handle 。
A.两个窗口之间切换
driver.switch_to.window(driver.window_handles[-1])from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
#搜索Selenium自动化测试得到网页1,再点击搜索出来的第一个网页得到网页2,在网页2再点击一个地方得到网页3,最后把网页2关掉。
#1、先进入到百度,并设置为全屏,设置全局等待缓冲6秒
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://www.baidu.com")
driver.implicitly_wait(6)
#2、先定位到搜索框,输入Selenium自动化测试并按回车
search_box = driver.find_element(by=By.ID, value="chat-textarea")
search_box.send_keys("Selenium自动化测试"+ Keys.ENTER)
#time.sleep(3)
#3、先获取并保存当前(主窗口)的句柄
main_window_handle = driver.current_window_handle
#4、找到要点击的元素定位,并创建ActionChains实例,再点击一个网页
search_box2 = driver.find_element(by=By.XPATH, value='//*[@id="1"]/div/h3/a')
actions = ActionChains(driver)
actions.click (search_box2).perform()
#5、等待新窗口打开,并获取所有窗口句柄(有时候句柄可能不止两个)
all_handles = driver.window_handles
#6. 找到新窗口的句柄
# 方法A: 循环遍历,找到不是主窗口句柄的那个(当有多个窗口时)
#for handle in all_handles:
# if handle != main_window_handle:
# new_window_handle = handle
# break
# 方法B(更简单): 直接假设新窗口是列表最后一个
new_window_handle = all_handles[-1]
#7. 切换到新窗口
driver.switch_to.window(new_window_handle)
print(f"已切换到新窗口,标题是: {driver.title}")
#8. 切换之后现在可以在新窗口中进行操作了,找到元素并点击
element_in_new_tab = driver.find_element(By.XPATH, '//*[@id="root"]/div/div[1]/div[5]/div[1]/div/div/div/a')
element_in_new_tab.click()
#8. 操作完成后,如果需要关闭新窗口并回到主窗口
driver.close() # 关闭当前(新)标签页
driver.switch_to.window(main_window_handle) # 将控制权交回主窗口
print(f"已切换回主窗口,标题是: {driver.title}")
input("按回车键关闭浏览器") # 等待用户输入
driver.quit()B.多个窗口之间切换
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
#先进入到百度,并设置为全屏,设置全局等待缓冲6秒
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://www.baidu.com")
driver.implicitly_wait(6)
#输入Selenium自动化测试并按回车
search_box = driver.find_element(by=By.ID, value="chat-textarea")
search_box.send_keys("Selenium自动化测试"+ Keys.ENTER)
#获取并保存当前(主窗口)的句柄
main_window_handle = driver.current_window_handle
#点击网页
for i in range(2):
driver.find_element(by=By.XPATH, value='//*[@id="1"]/div/h3/a').click()
#获取所有窗口句柄
all_handles = driver.window_handles
# 切换到第二个新窗口(索引为2,因为0是主窗口)
driver.switch_to.window(all_handles[2])
driver.find_element(By.XPATH, '//*[@id="root"]/div/div[1]/div[5]/div[1]/div/div/div/a').click()
# 切换到第一个新窗口(索引为1)
driver.switch_to.window(all_handles[1])
driver.find_element(By.XPATH, '//*[@id="root"]/div/div[1]/div[5]/div[1]/div/div/div/a').click()
# 最后切换回主窗口
driver.switch_to.window(main_window_handle)
print(f"已切换回主窗口,标题是: {driver.title}")
input("按回车键关闭浏览器") # 等待用户输入
driver.quit()(2)表单切换
很多页面也会用带 frame/iframe 表单嵌套,对于这种内嵌的页面 selenium 是无法直接定位的,需要使用 switch_to.frame() 方法将当前操作的对象切换成 frame/iframe 内嵌的页面。比如第三方登录窗口(微信、QQ登录)
switch_to.frame() 默认可以用的 id 或 name 属性直接定位,但如果 iframe 没有 id 或 name ,这时就需要使用 xpath 进行定位。
假如我们有以下HTML结构:
<html>
<body>
<h1>主页面标题</h1>
<!-- 第一个iframe,有id -->
<iframe id="loginFrame" name="login" src="login.html">
#document
<html>
<body>
<input type="text" id="username" placeholder="用户名">
<input type="password" id="password" placeholder="密码">
<button id="loginBtn">登录</button>
</body>
</html>
</iframe>
<!-- 第二个iframe,只有class -->
<iframe class="video-player" src="video.html">
#document
<html>
<body>
<button id="playBtn">播放</button>
<div id="videoContent">视频内容</div>
</body>
</html>
</iframe>
</body>
</html>A.通过IDid或name属性切换(最常用)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("your_page_url")
# 通过id切换
driver.switch_to.frame("loginFrame") # 使用id
# 或者通过name切换(如果iframe有name属性)
# driver.switch_to.frame("login") # 使用name
# 操作iframe内的元素
username_field = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "username"))
)
username_field.send_keys("testuser")
# 切换回主文档
driver.switch_to.default_content()
# 现在可以操作其他iframe或主文档元素B.通过WebElement对象切换(最灵活)
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("your_page_url")
# 先定位到iframe元素本身
iframe_element = driver.find_element(By.CLASS_NAME, "video-player")
# 然后将该WebElement作为参数传入
driver.switch_to.frame(iframe_element)
# 操作第二个iframe中的视频控件
driver.find_element(By.ID, "playBtn").click()
# 切换回主文档
driver.switch_to.default_content()假如我们有以下HTML结构:
<iframe id="outerFrame">
#document
<html>
<body>
<iframe id="innerFrame">
#document
<html>
<body>
<button id="deepButton">深层按钮</button>
</body>
</html>
</iframe>
</body>
</html>
</iframe>C.处理嵌套iframe
有时候iframe内部还嵌套着其他iframe,需要层层切换。
# 切换到外层iframe
driver.switch_to.frame("outerFrame")
# 再切换到内层iframe
driver.switch_to.frame("innerFrame")
# 现在可以操作最内层的元素
driver.find_element(By.ID, "deepButton").click()
# 如果要返回主文档,需要逐层返回或直接跳回
driver.switch_to.parent_frame() # 回到外层iframe
driver.switch_to.parent_frame() # 回到主文档
# 或者直接跳回主文档
driver.switch_to.default_content() # 直接回到最外层D.关键方法总结
| 方法 | 描述 |
|---|---|
switch_to.frame(frame_reference) | 切换到指定的iframe |
switch_to.default_content() | 从任何iframe层级直接切换回最外层的主文档 |
switch_to.parent_frame() | 从当前iframe切换回它的父级(上一层) |
E.最佳实践和注意事项
a.优先使用id/name:通过id或name属性切换是最稳定可靠的方式。
b.使用显式等待:在切换iframe后,使用WebDriverWait等待iframe内的元素加载完成。
c.及时切换回主文档:操作完iframe后,记得使用 default_content() 或 parent_frame() 返回,否则后续查找元素会失败。
d.处理不可见的iframe:有些iframe可能默认不显示,需要先触发某些操作才会出现
e.调试技巧:如果找不到元素,首先检查:
-
是否忘记了切换到正确的iframe?
-
是否需要等待iframe加载?
-
iframe是否是动态加载的?
7.对Cookie操作
cookies 是识别用户登录与否的关键,爬虫中常常使用 selenium + requests 实现 cookie持久化,即先用 selenium 模拟登陆获取 cookie ,再通过 requests 携带 cookie 进行请求。
webdriver 提供 cookies 的三种操作:读取、添加、删除
| get_cookies | 以字典的形式返回当前会话中可见的 cookie 信息 |
| get_cookie(name) | 返回 cookie 字典中 |
| key == name | cookie 信息 |
| add_cookie(cookie_dict) | 将 cookie 添加到当前会话中 |
| delete_cookie(name) | 删除指定名称的单个 cookie |
| delete_all_cookies() | 删除会话范围内的所有cookie |
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
8.下拉进度条做法
execute_script方法
| 滚动方式 | JavaScript 代码示例 | 适用场景 |
|---|---|---|
| 针对整个文档 | document.documentElement.scrollTop = 1000 | 绝大多数标准网页5 |
| 针对 body 元素 | document.body.scrollTop = 1000 | 一些旧式或特殊结构的网页 |
| 针对特定元素 | document.getElementById('myDiv').scrollTop = 1000 | 页面内具有独立滚动区域的容器(如聊天框) |
| 滚动到元素可见 | arguments[0].scrollIntoView(); | 需要将特定元素滚动到视口内时 |
| 滚动指定距离 | window.scrollBy(0, 500); | 需要相对当前滚动位置进行滚动 |
注意:对于整个文档的滚动,document.documentElement.scrollTop 和 document.body.scrollTop 在不同浏览器或不同DOCTYPE声明的页面中行为可能不同。如果一个不行,可以尝试另一个。
其他滚动技巧
除了设置固定的 scrollTop,你还可以使用:
-
window.scrollTo(x, y): 滚动到文档中的特定坐标。(比如页面底部) -
window.scrollBy(x, y): 相对于当前位置滚动一段距离。这在模拟逐段滚动阅读时很实用。 -
element.scrollIntoView(): 让特定的元素滚动到视口内。这是确保元素可见再进行操作(如点击)的推荐方法。
(1)找到页面高度
| 属性 | 描述 |
|---|---|
window.innerHeight | 浏览器中间可视区域的高度 |
window.outerHeight | 整个浏览器窗口的高度 |
document.documentElement.clientHeight | 视口高度(不包括滚动条) |
document.documentElement.scrollHeight | 整个网页的完整高度(包括需要滚动才能看到的部分) |
document.documentElement.offsetHeight | 文档高度(包括边框和滚动条) |
#获取页面高度,使用 || 操作符是因为不同浏览器对页面高度的计算方式不同
total_height = driver.execute_script("return document.body.scrollHeight || document.documentElement.scrollHeight;")# 获取可视页面的高度
viewport_height = driver.execute_script("return window.innerHeight;") (2)缓慢分段滚动到页面底部(模拟阅读行为)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 初始化浏览器驱动
driver = webdriver.Chrome()
driver.get("https://baike.baidu.com/item/Selenium/18266")
#获取全页面高度(包括没有滑动到的部分),兼容不同浏览器
total_height = driver.execute_script("return document.body.scrollHeight || document.documentElement.scrollHeight;")
#获取可视页面高度,并每次滚动一个视口高度的80%
viewport_height = driver.execute_script("return window.innerHeight;")
scroll_step = viewport_height * 0.8
#设置页面初始高度为0
current_position = 0
#循环语句,当初始高度小于全页面高度时
while current_position < total_height:
# scrollTo(x,y)滑动到指定坐标的位置
driver.execute_script(f"window.scrollTo(0, {current_position});")
#没滑动一次current_position就加上页面的百分80%高度
current_position += scroll_step
# 暂停一下,模拟阅读速度
time.sleep(0.5)
# 最终确保滚动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight || document.documentElement.scrollHeight);")
print("已滚动到页面底部")
# 等待2秒观察效果
time.sleep(2) (3)滚到页面顶部
driver.execute_script("window.scrollTo(0, 0);")(4)滚到页面特定位置(三分之一)
target_position = total_height // 3
driver.execute_script(f"window.scrollTo(0, {target_position});")(5)滚动到特定元素
#异常处理框架
try:
# 尝试精确查找和滚动
...
except Exception as e:
# 降级处理方案
...from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 初始化浏览器驱动 (请确保 chromedriver 在 PATH 环境变量中,或使用 executable_path 参数指定路径)
driver = webdriver.Chrome()
driver.get("https://baike.baidu.com/item/Selenium/18266")
driver.implicitly_wait(30)
total_height = driver.execute_script("return document.body.scrollHeight || document.documentElement.scrollHeight;")
print("尝试滚动到‘发展历程’章节...")
try:
# 使用更稳定的XPath尝试定位“发展历程”这个标题
development_title = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.XPATH, "//h2[contains(., '发展历程')] | //h2[contains(., '历史')] | //div[contains(@class, 'heading') and contains(., '发展历程')]"))
# 如果找不到“发展历程”,尝试找“历史”或其他标题,或者根据实际页面调整选择器
)
# 执行JS,将该元素滚动到视口中间
driver.execute_script("arguments[0].scrollIntoView({behavior: 'smooth', block: 'center'});", development_title)
# behavior: 'smooth' 可实现平滑滚动(但取决于浏览器支持)
# block: 'center' 将元素滚动到视口中央
print("已滚动到‘发展历程’章节")
except Exception as e:
print(f"未找到‘发展历程’章节或滚动失败: {e}")
# 备选方案:滚动到中间位置
mid_point = total_height // 2
driver.execute_script(f"window.scrollTo(0, {mid_point});")
print("已滚动到页面中部")
#强制在页面停留3秒
time.sleep(3)(6)滑动到动态元素页面可见
当我们需要定位的元素是动态元素,或者我们不确定它在哪时,可以先找到这个元素然后再使用JS操作。
target = driver.find_element_by_id('id')
driver.execute_script("arguments[0].scrollIntoView();", target)
(7)判断元素是否存在
def is_element_exist(browser,xpath):
try:
element=browser.find_element(by=By.XPATH,value=xpath)
flag=True
except:
flag=False
return flag
9.xpath方法
XPath是一门在XML文档中查找信息的语言,被用于在XML和HTML文档中通过元素和属性进行导航。
七种节点类型
| 元素 | 如 <book>, <title> |
| 属性 | 如 id="main" |
| 文本 | 元素中的文本内容 |
| 注释 | <!-- 注释 --> |
| 命名空间节点 | |
| 处理指令 | |
| 文档根节点 |
(1)XPath路径表达式
| 表达式 | 含义 |
| nodename | 选取此节点的所有子节点(div) |
| / | 从根节点选取 |
| // | 选择任意位置的某个节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
(2)XPath语法通配符
| 通配符 | 含义 |
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型节点 |
(3)谓语
用于查找特定节点或包含特定值的节点,写在方括号中:
//div[@class='content'] // 选择 class 属性为 content 的 div
//ul/li[1] // 选择每个 ul 的第一个 li 子元素
//a[contains(@href,'example')] // 选择 href 属性包含 'example' 的 a 标签(4)基本Xpath定位
A.通过标签名定位
# 定位所有 div 元素
driver.find_element(By.XPATH, "//div")
# 定位所有 input 元素
driver.find_element(By.XPATH, "//input")B.通过ID定位
# 定位 ID 为 "username" 的元素
driver.find_element(By.XPATH, "//*[@id='username']")
# 定位 ID 为 "password" 的 input 元素
driver.find_element(By.XPATH, "//input[@id='password']")C.通过 class 定位
# 定位 class 为 "form-control" 的元素
driver.find_element(By.XPATH, "//*[@class='form-control']")
# 定位 class 包含 "btn" 的元素
driver.find_element(By.XPATH, "//*[contains(@class, 'btn')]")
# 定位 class 同时包含 "btn" 和 "btn-primary" 的元素
driver.find_element(By.XPATH, "//*[contains(@class, 'btn') and contains(@class, 'btn-primary')]")(5)使用文本内容定位
A.精确文本匹配
# 定位文本内容为 "登录" 的按钮
driver.find_element(By.XPATH, "//button[text()='登录']")
# 定位文本内容为 "忘记密码?" 的链接
driver.find_element(By.XPATH, "//a[text()='忘记密码?']")B.部分文本匹配
# 定位文本包含 "用户" 的元素
driver.find_element(By.XPATH, "//*[contains(text(), '用户')]")
# 定位文本以 "欢迎" 开头的元素
driver.find_element(By.XPATH, "//*[starts-with(text(), '欢迎')]")
# 定位文本以 "!" 结尾的元素
driver.find_element(By.XPATH, "//*[substring(text(), string-length(text())) = '!']")(6)使用属性定位
A.属性组合
# 定位 type="text" 且 name="username" 的 input 元素
driver.find_element(By.XPATH, "//input[@type='text' and @name='username']")
# 定位 type="submit" 或 type="button" 的 input 元素
driver.find_element(By.XPATH, "//input[@type='submit' or @type='button']")B.属性值部分匹配
# 定位 name 属性以 "user" 开头的元素
driver.find_element(By.XPATH, "//*[starts-with(@name, 'user')]")
# 定位 name 属性以 "name" 结尾的元素
driver.find_element(By.XPATH, "//*[ends-with(@name, 'name')]") # 注意:ends-with 是 XPath 2.0 函数,可能不被所有浏览器支持
# 定位 href 属性包含 "login" 的元素
driver.find_element(By.XPATH, "//*[contains(@href, 'login')]")(7)层级关系定位
A.父子关系
# 定位 id 为 "container" 的 div 下的所有 input 元素
driver.find_element(By.XPATH, "//div[@id='container']//input")
# 定位直接子元素
driver.find_element(By.XPATH, "//form/input") # form 的直接子 input 元素B.兄弟关系
# 定位紧随 h2 标题后的第一个 p 元素
driver.find_element(By.XPATH, "//h2/following-sibling::p[1]")
# 定位在 p 元素之前的所有 h2 元素
driver.find_element(By.XPATH, "//p/preceding-sibling::h2")C.父元素
# 定位包含特定 span 的 div 父元素
driver.find_element(By.XPATH, "//span[text()='详情']/parent::div")(8)索引元素
# 定位第二个 div 元素
driver.find_element(By.XPATH, "(//div)[2]")
# 定位表格中的第三行
driver.find_element(By.XPATH, "//table//tr[3]")
# 定位最后一个 div 元素
driver.find_element(By.XPATH, "(//div)[last()]")(9)模糊定位
A.使用contains() 包含函数,文本包含某个词语
contains(str1, str2): 判断 str1 是否包含 str2# 定位文本包含 "用户" 的元素
driver.find_element(By.XPATH, "//*[contains(text(), '用户')]")B.使用starts-with() 包含函数
starts-with(str1, str2): 判断 str1 是否以 str2 开头# 定位文本以 "欢迎" 开头的元素
driver.find_element(By.XPATH, "//*[starts-with(text(), '欢迎')]")C.使用count() 包含函数
count(node-set): 计算节点数量D.使用last() 包含函数
last(): 返回最后一个节点E.使用position() 包含函数
position(): 返回节点位置(10)逻辑定位
使用逻辑运算符 – and、or;可以根据一个元素的多个属性进行定位,确保唯一性
(11)轴定位
轴定位是根据父节点,兄弟节点等节点来定位本节点,使用语法: 轴名称 :: 节点名称,使用较多场景:页面显示为一个表格样式的数据列。
| 描述 | 表达式 |
| 定位当前节点后的所有节点 | //标签名[@属性=属性值]/follow::标签名[@属性=属性值] |
| 定位同一节点后的所有同级节点 | //标签名[@属性=属性值]/follow-sibling::标签名[@属性=属性值] |
| 定位当前节点的所有子节点 | //标签名[@属性=属性值]/child::标签名[@属性=属性值] |
| 定位当前节点前的所有节点 | //标签名[@属性=属性值]/preceding::标签名[@属性=属性值] |
| 定位同一个节点前的所有同级节点 | //标签名[@属性=属性值]/preceding-sibling::标签名[@属性=属性值] |
| 定位当前节点的所有父节点 | //标签名[@属性=属性值]/parent::标签名[@属性=属性值] |
| 定位当前节点的所有祖父节点 | //标签名[@属性=属性值]/ancestor::标签名[@属性=属性值] |
XPath 最佳实践
1.优先使用 ID 或唯一属性://*[@id="uniqueId"] 比 //div/div/div[3] 更可靠
2.避免过度复杂的路径:太长的路径容易因页面结构变化而失效
3.使用 contains 处理动态类名://div[contains(@class,'product')]
4.结合 CSS 选择器:某些场景下 CSS 选择器可能更简洁
5.测试 XPath 表达式:先在浏览器控制台测试再写入代码

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









