







十二、容器
在Java中,容器(也称为集合)是处理数据集合的核心组件。深入理解Java容器对于处理大规模数据、提高代码效率和编写高性能程序至关重要。Java中提供了许多容器类,这些类位于java.util包中,分为两类:Collection和Map。
以下详细介绍List、Set、Map和Queue这几个主要的Java容器,并通过详细的源码分析和工作中的实际应用,来深入理解这些容器的本质。
注:源码基于JDK1.8。
概览
容器主要包括 Collection 和 Map 两种:
- Collection 存储着对象的集合
- 而 Map 存储着键值对(两个对象)的映射表。
1.Collection
API说明
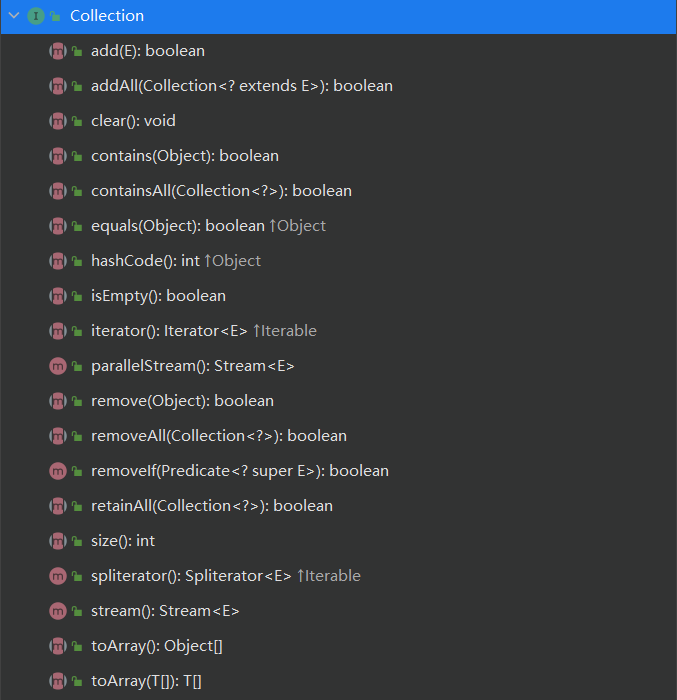
Collection 是 Java 中集合框架的根接口,是 List、Set 和 Queue 等子接口的公共父接口。Collection 定义了基本的集合操作方法,比如添加、删除、查询等,用于处理一组对象。
1.Collection 接口的说明
Collection 接口位于 java.util 包中,定义了操作集合对象的通用方法。它不能直接实例化,但通过子接口(如 List、Set、Queue)来使用。常用方法包括:
-
添加元素:
boolean add(E e): 向集合中添加元素,成功返回true。boolean addAll(Collection<? extends E> c): 添加另一个集合的所有元素到当前集合中。
-
删除元素:
boolean remove(Object o): 删除集合中的指定元素,成功返回true。boolean removeAll(Collection<?> c): 删除集合中所有与指定集合中匹配的元素。boolean retainAll(Collection<?> c): 只保留集合中与指定集合匹配的元素。void clear(): 清空集合中的所有元素。
-
查询操作:
boolean contains(Object o): 判断集合中是否包含指定元素。boolean containsAll(Collection<?> c): 判断当前集合是否包含另一个集合的所有元素。int size(): 返回集合中元素的数量。boolean isEmpty(): 判断集合是否为空。
-
集合迭代:
Iterator<E> iterator(): 返回一个用于遍历集合元素的迭代器。
-
数组转换:
Object[] toArray(): 将集合转换为一个对象数组。<T> T[] toArray(T[] a): 将集合转换为指定类型的数组。
2.工作中的使用场景
- List 接口(
ArrayList、LinkedList):在需要有序存储元素并且允许重复时使用,例如实现员工名单、订单列表等。 - Set 接口(
HashSet、TreeSet):在需要保证集合中的元素不重复时使用,比如记录唯一标识(ID)、过滤重复数据等。 - Queue 接口(
LinkedList、PriorityQueue):在需要遵循特定顺序处理元素时使用,例如任务调度、消息队列等。
在实际开发中,通常使用子接口(如 List、Set)的实现类实例化集合。例如:
List<String> list = new ArrayList<>();
Set<Integer> set = new HashSet<>();
Queue<String> queue = new LinkedList<>();
3.注意事项
- 选择合适的子接口:根据实际需求选择合适的集合类型。例如,
List用于有序且可重复的场景,Set用于存储唯一元素的场景,Queue用于遵循 FIFO(先入先出)或优先级处理的场景。 - 线程安全性:
Collection接口及其大多数实现类不是线程安全的。在多线程环境下,需要使用同步包装器(如Collections.synchronizedList)或使用并发集合(如ConcurrentHashMap、CopyOnWriteArrayList)。 - 效率问题:不同集合在添加、删除、查询等操作上有不同的性能表现。例如,
ArrayList适合随机访问,但插入、删除效率低;LinkedList插入、删除效率高,但随机访问性能较差。需要根据场景选择合适的集合实现。 - 避免操作空集合:在调用集合操作方法前,检查集合是否为空 (
isEmpty()) 可以避免空指针异常。
4.常用子接口和实现类
-
List:
- 实现类:
ArrayList、LinkedList、Vector、Stack - 特点:允许重复,有序(元素按插入顺序存储),支持通过索引随机访问。
- 实现类:
-
Set:
- 实现类:
HashSet、LinkedHashSet、TreeSet - 特点:不允许重复,无序(
HashSet),有序(LinkedHashSet、TreeSet)。
- 实现类:
-
Queue:
- 实现类:
LinkedList、PriorityQueue - 特点:用于按特定顺序处理元素,如 FIFO、优先级。
- 实现类:
通过灵活运用 Collection 接口及其子接口的各种实现,可以满足不同的编程需求。
2.Map
包含的API
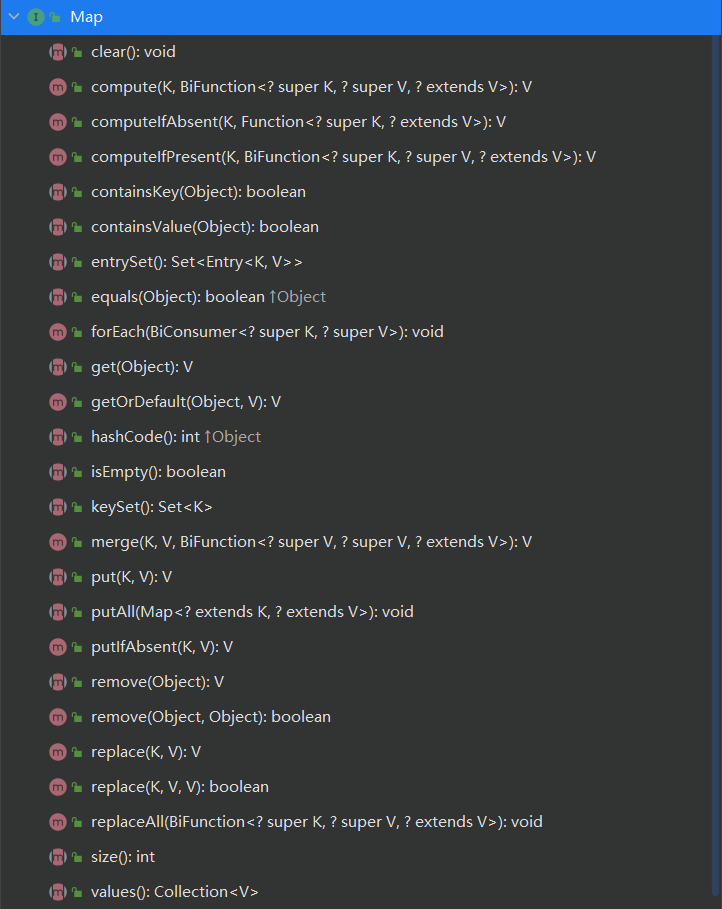
API说明
Map 是 Java 集合框架中的一个重要接口,它用于存储键值对(key-value)映射。Map 不继承自 Collection 接口,因为它表示一组键值对,而不是单独的元素集合。常用的 Map 实现类有 HashMap、TreeMap、LinkedHashMap、Hashtable 和 ConcurrentHashMap 等。
1. Map 接口的说明
Map 接口提供了操作键值对映射的基本方法,包括插入、删除、查找和遍历键值对等操作。常用的方法包括:
-
添加和更新键值对:
V put(K key, V value): 将指定的键值对添加到Map中。如果键已经存在,替换对应的值,并返回旧值。void putAll(Map<? extends K, ? extends V> m): 将另一个Map中的所有键值对添加到当前Map中。V putIfAbsent(K key, V value): 仅当键不存在时,添加键值对。
-
删除键值对:
V remove(Object key): 删除指定键对应的键值对,返回被删除的值。boolean remove(Object key, Object value): 只有在键值对匹配时才删除,成功返回true。
-
查询操作:
V get(Object key): 返回指定键对应的值,若键不存在则返回null。boolean containsKey(Object key): 判断Map中是否包含指定键。boolean containsValue(Object value): 判断Map中是否包含指定值。int size(): 返回Map中键值对的数量。boolean isEmpty(): 判断Map是否为空。
-
遍历
Map:Set<K> keySet(): 返回所有键的Set集合。Collection<V> values(): 返回所有值的Collection集合。Set<Map.Entry<K, V>> entrySet(): 返回所有键值对的Set集合,每个元素是一个Map.Entry对象。
2. 工作中的使用场景
- 存储键值映射关系:
Map主要用于存储键值对的映射关系,常见的场景包括存储用户信息(<userId, User>)、缓存数据(<key, value>)等。 - 计数器:利用
Map实现某个对象的计数器,比如统计字符出现次数、产品销售统计等。 - 查找表:
Map可作为查找表使用,通过键快速找到对应的值。比如,根据订单号查询订单详情、根据配置项名称获取配置值等。 - 缓存机制:
Map可以用来实现简单的缓存机制(如HashMap+LinkedHashMap实现 LRU 缓存),在内存中存储一部分数据,减少重复计算或数据库查询。
3. 注意事项
-
键的唯一性:
Map中的键必须是唯一的。如果插入一个已存在的键,新的值会替换旧的值。 -
null键和值:HashMap允许一个null键和多个null值。Hashtable不允许null键或值。TreeMap允许null值,但不允许null键(因为需要对键进行比较)。
-
线程安全:
HashMap、TreeMap、LinkedHashMap等实现类不是线程安全的,在多线程环境中需要通过同步机制或使用并发类(如ConcurrentHashMap)来保证线程安全。 -
性能考虑:
HashMap基于哈希表实现,查询、插入、删除的平均时间复杂度为 O(1)。TreeMap基于红黑树实现,键值对是有序的,查询、插入、删除的时间复杂度为 O(log n)。- 如果对键值对的顺序有要求,选择
LinkedHashMap或TreeMap;若仅追求性能,使用HashMap。
4. 常用实现类
-
HashMap:- 基于哈希表实现,允许一个
null键和多个null值。 - 无序,键值对存储顺序不固定。
- 常用于快速查找,如缓存数据、对象映射等。
- 基于哈希表实现,允许一个
-
LinkedHashMap:- 继承自
HashMap,内部维护了一个双向链表,记录插入顺序。 - 适用于需要保持插入顺序或访问顺序的场景,例如实现 LRU 缓存。
- 继承自
-
TreeMap:- 基于红黑树实现,键值对是有序的。
- 可以根据键的自然顺序(实现
Comparable接口)或自定义比较器(Comparator)进行排序。 - 适用于需要对键排序的场景,如统计、排名等。
-
Hashtable:- 古老的线程安全实现,不允许
null键和null值。 - 性能较低,通常不推荐使用,推荐用
ConcurrentHashMap代替。
- 古老的线程安全实现,不允许
-
ConcurrentHashMap:- 线程安全,适用于多线程环境。
- 通过分段锁(Java 8 后为 CAS + 红黑树)实现高效的并发操作。
5. 示例代码
以下是 HashMap 的一些常用操作示例:
import java.util.HashMap;
import java.util.Map;
public class MapExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
// 添加键值对
map.put("Apple", 3);
map.put("Banana", 2);
map.put("Orange", 5);
// 更新键值对
map.put("Apple", 4);
// 查找值
int appleCount = map.get("Apple"); // 返回 4
// 判断键是否存在
boolean hasBanana = map.containsKey("Banana"); // 返回 true
// 删除键值对
map.remove("Orange");
// 遍历键值对
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
在这段代码中,我们创建了一个 HashMap 来存储水果的名称和数量,并演示了添加、更新、查找、删除和遍历键值对的操作。
总结
Map 是 Java 中处理键值对数据的核心接口。选择合适的 Map 实现类是关键:如果需要快速查找,使用 HashMap;如果需要顺序或排序,选择 LinkedHashMap 或 TreeMap;在多线程环境中,使用 ConcurrentHashMap。
继承结构图
1.为什么要熟悉?
熟悉继承结构图在实际开发中有以下几个好处:
- 加深对类层次结构的理解
继承结构图展示了类与类之间的关系,包括接口、抽象类和具体类。通过掌握这些关系,开发者可以清楚地了解一个类的特性来自于哪些父类或接口,从而更好地理解类的功能和设计意图。
- 优化代码复用
通过继承结构,开发者能够更有效地利用继承体系进行代码复用。例如,明白常见容器(如 ArrayList、LinkedList)都继承自 List 接口,能够帮助开发者在接口上编写代码,从而提高程序的灵活性和可扩展性。
- 便于选择合适的类或接口
理解继承结构有助于开发者在面对某些需求时,选择最合适的类或接口。例如,List 提供有序的集合,而 Set 不允许重复项,了解这些接口的继承关系,可以帮助你为不同的应用场景选择正确的数据结构。
- 掌握多态性
继承结构是多态性的基础。熟悉继承关系可以帮助开发者利用父类或者接口来实现多态,在实际编程中利用更灵活的方式操作对象,增强代码的可扩展性和维护性。
- 阅读源码和设计模式的基础
在阅读 Java 类库的源码或学习设计模式时,继承结构的理解至关重要。很多设计模式(如装饰器模式、模板方法模式等)依赖于继承结构的设计思想。熟悉这种继承图,可以帮助你更快理解和掌握这些模式的实现。
- 调试和排查问题
了解继承结构在调试中也非常有用,特别是当你遇到某个方法的行为与预期不符时,可以快速定位到继承链中的哪个类实现了该方法,并理解其行为。
总结:
熟悉继承结构图不仅能帮助开发者理解类之间的设计和关系,还能提高代码复用性、灵活性和可维护性,帮助你做出更合适的设计决策并更高效地调试代码。
2.示例
由于同类型的大多集合继承的内容类似。故此挑选典型容器来加以说明。
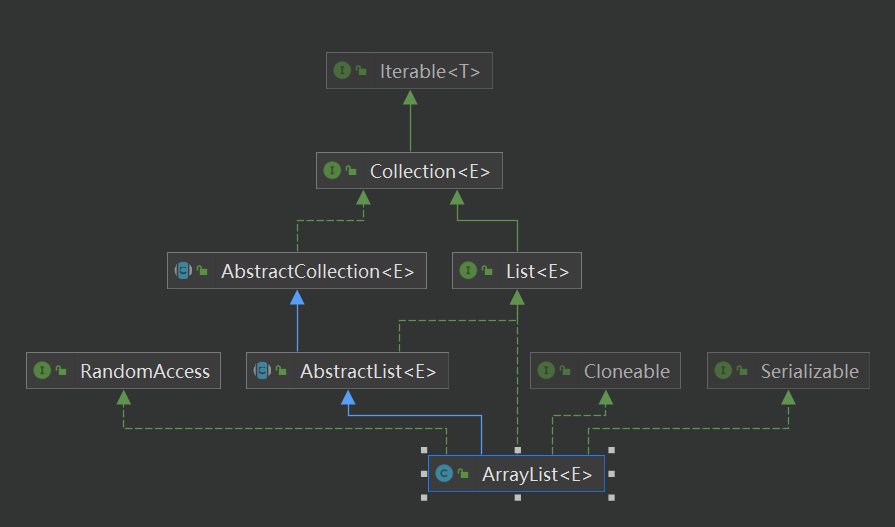
由图所示,继承和实现的多个接口和类,每个接口或类在集合框架中都扮演着特定的角色。下面我们来逐一分析:
-
Iterable<T>接口-
用途:
Iterable接口是集合框架的根接口,所有实现它的类都可以使用for-each循环。它定义了一个iterator()方法,返回一个Iterator对象,允许遍历集合中的元素。 -
适用场景:任何需要遍历集合的场景,比如在
for-each语句中使用集合。 -
List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } -
为什么说使用
for-each来替换iterator遍历会更强呢?-
for-each循环比Iterator的while循环更强的原因可以总结为以下几点:- 代码简洁性:
for-each隐藏了Iterator的创建和方法调用,简化了遍历代码。 - 可读性:
for-each更直观,清楚表达了遍历的意图,容易理解和维护。 - 减少出错风险:
for-each避免了手动调用hasNext()和next()可能带来的错误。 - 一致性:
for-each可以用于遍历数组和集合,保持代码风格一致。 - 编译器优化:
for-each循环可能经过编译器的底层优化,执行效率更高。
但在需要修改集合(如删除元素)时,
Iterator仍是必要的工具。 - 代码简洁性:
-
-
-
Collection<E>接口- 用途:
Collection是所有集合类的基接口,定义了集合的一些基础操作,如添加、删除、包含元素等。它还继承了Iterable接口。 - 使用场景:提供基础集合操作的通用接口,例如List、Set、Queue都是
Collection的子接口。
- 用途:
-
List<E>接口- 用途:
List是一个有序集合,允许元素重复并可以通过索引来访问集合中的元素。List继承了Collection接口,增加了按位置访问、插入、删除等操作。 - 适用场景:适用于对元素有顺序要求,并且允许重复的场景,例如任务列表,购物车等。
- 用途:
-
AbstractCollection<E>抽象类- 用途:**
AbstractCollection是Collection接口的骨架实现,提供了一些常见的集合操作(如:size()、isEmpty()、toArray()等)的默认实现。**它帮助减少重复代码,使子类只需实现特定的方法即可。 - 使用场景:作为自定义集合类的基础,减少重复实现常见操作的代码。
- 用途:**
-
AbstractList<E>抽象类- 用途:**
AbstractList是List接口的骨架实现,提供了get(int index)和set(int index,E element)等操作的默认实现。**开发者只需要实现一些基础方法,如size()和get(),就可以快速构建一个List类。 - 适用场景:简化
List类的实现,为具体的List子类(如ArrayList)提供骨架支持。
- 用途:**
-
RandomAccess接口- 用途:
RandomAccess是一个标识接口(没有定义任何方法),标识实现类支持快速随机访问(通过索引快速访问元素)。像ArrayList这样的类由于底层是数组实现,因此可以通过RandomAccess来标识支持高效的随机访问。 - 适用场景:在处理
List时,如果集合实现了RandomAccess,那么可以优先选择通过索引操作,而不是使用Iterator来遍历。
- 用途:
-
Cloneable接口- 用途:
Cloneable接口是一个标识接口,表明一个类的对象可以通过调用clone()方法来生成它的浅拷贝。如果一个类实现了Cloneable接口,它应该覆盖clone()方法,否则会抛出CloneNotSupportedException。 - 适用场景:适用于需要复制对象的场景,如需要生成一个对象的副本用于临时操作。
- 用途:
-
Serializable接口- 用途:
Serializable是一个标识接口,表明一个类的实例可以序列化,即可以将对象转换为字节流,随后可以通过反序列化将字节流还原成对象。 - 适用场景:适用于需要对象持久化的场景,例如将对象保存到文件、数据库或通过网络传输时。
- 用途:
3.总结
Iterable<T>和Collection<E>定义了集合操作的基本能力和遍历方法。List<E>进一步扩展了集合,支持有序、可重复的元素列表操作。AbstractCollection<E>和AbstractList<E>提供了集合的骨架实现,减少了开发者重复实现基础功能的工作量。RandomAccess是标识接口,表明支持高效随机访问。Cloneable和Serializable是用于对象复制和序列化的标识接口。
这些接口和类的组合帮助构建了 Java 强大的集合框架,每个类和接口都有其特定的用途和适用场景。
Collection
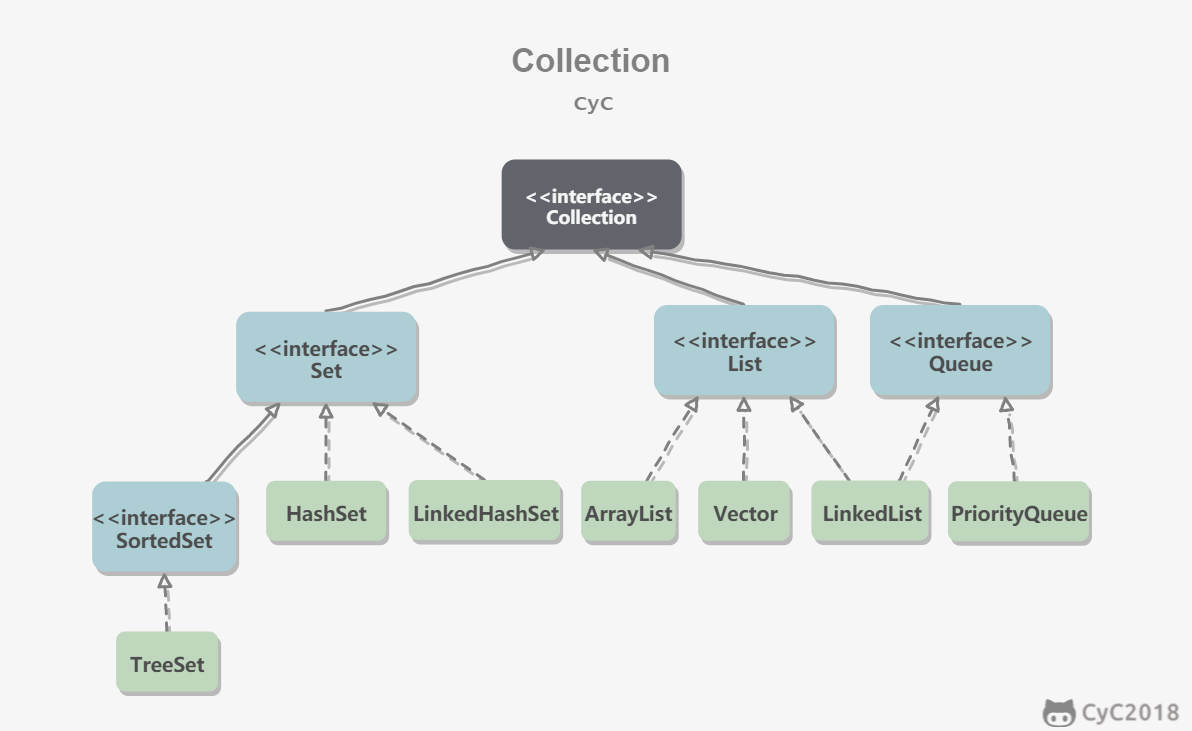
1. Set
TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如HashSet,HashSet查找的时间复杂度为 O(1),TreeSet则为O(logN)。HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历HashSet得到的结果是不确定的。LinkedHashSet:具有HashSet的查找效率,并且内部使用双向链表维护元素的插入顺序。
2. List
概述
ArrayList:底层使用动态数组实现,支持随机访问,插入和删除操作在末尾时效率较高,但是在中间位置插入或删除会导致元素移动,性能较差。Vector:和ArrayList类似,但它是线程安全的,当底层将整个集合上锁,性能较差。逐渐被淘汰。LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList还可以用作栈、队列和双向队列。
ArrayList
适用场景
ArrayList是一个基于数组实现的动态数组,它的容量可以自动扩展,适用于频繁读取元素的场景。
工作场景
在需要快速随机访问元素时,ArrayList是一个很好的选择,例如在内存缓存、搜索结果,用户列表等场景中。
3. Queue
LinkedList:可以用它来实现双向队列。PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
Map
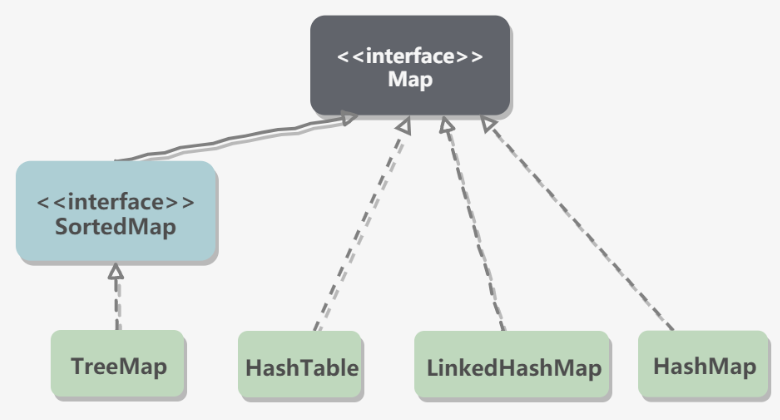
说明:
TreeMap:基于红黑树实现。HashMap:基于哈希表实现。HashTable:和HashMap类似,但它是线程安全的,这意味着同一时刻多个线程同时写入HashTable不会导致数据不一致。它是遗留类,不应该去使用它,而是使用ConcurrentHashMap来支持线程安全,ConcurrentHashMap的效率会更高,因为ConcurrentHashMap引入了分段锁。LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
容器中的设计模式
迭代器模式
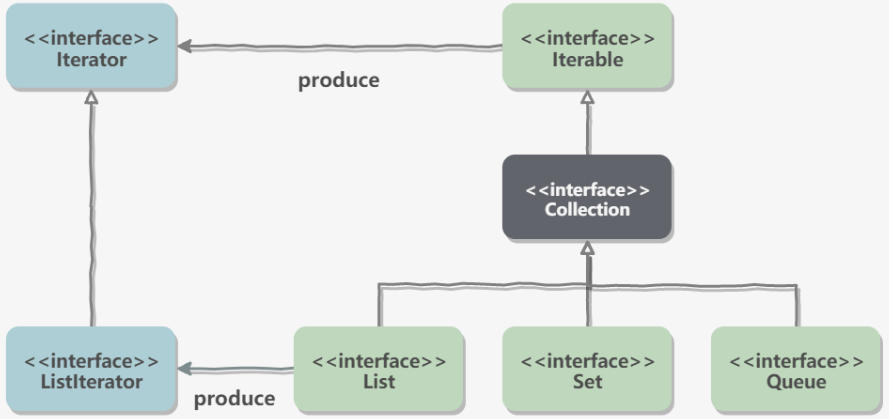
Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
从 JDK 1.5 之后可以使用 foreach 方法来遍历实现了 Iterable 接口的聚合对象。
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
for (String item : list) {
System.out.println(item);
}
适配器模式
java.util.Arrays#asList() 可以把数组类型转换为 List 类型。
@SafeVarargs
public static <T> List<T> asList(T... a)
应该注意的是 asList() 的参数为泛型的变长参数,不能使用基本类型数组作为参数,只能使用相应的包装类型数组。
Integer[] arr = {
1, 2, 3};
List list = Arrays.asList(arr);
也可以使用以下方式调用 asList():
List list = Arrays.asList(1, 2, 3);
源码分析
如果没有特别说明,以下源码分析基于 JDK 1.8。
在 IDEA 中 double shift 调出 Search EveryWhere,查找源码文件,找到之后就可以阅读源码。
ArrayList
1. 概览
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
//数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;
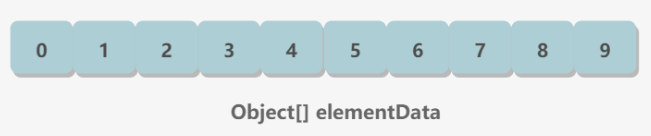
2.存储结构
3.扩容
添加元素时:
- 使用
ensureCapacityInternal()方法来保证容量足够 - 如果不够时,需要使用
grow()方法进行扩容,新容量的大小为oldCapacity + (oldCapacity >> 1),即oldCapacity+oldCapacity/2。其中oldCapacity>> 1 需要取整,所以新容量大约是旧容量的 1.5 倍左右。(oldCapacity为偶数就是 1.5 倍,为奇数就是 1.5 倍-0.5) - 扩容操作需要调用
Arrays.copyOf()把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建ArrayList对象时就指定大概的容量大小,减少扩容操作的次数。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
4.删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
5.序列化
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。
保存元素的数组 elementData 使用 transient 修饰: transient 关键字声明数组默认不会被序列化。
transient Object[] elementData; // non-private to simplify nested class access
ArrayList 实现了 writeObject() 和 readObject()来控制只序列化数组中有元素填充那部分内容。
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
序列化时:
- 需要使用
ObjectOutputStream的writeObject()将对象转换为字节流并输出。 - 而
writeObject()方法在传入的对象存在writeObject()的时候会去反射调用该对象的writeObject()来实现序列化。 - 反序列化使用的是
ObjectInputStream的readObject()方法,原理类似。
ArrayList list = new ArrayList();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(list);
6.Fail-Fast
modCount 用来记录 ArrayList 结构发生变化的次数。
结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
在进行序列化或者迭代等操作时:
- 需要比较操作前后
modCount是否改变, - 如果改变了需要抛出
ConcurrentModificationException。 - 代码参考上节序列化中的
writeObject()方法。
7.汇总分析
由于源码篇幅较大,主要对ArrayList中最关键的部分进行详细注释,包括构造方法、核心属性、常用方法(如add(),remove(),get()等)。
import java.util.*;
// ArrayList 是一个基于数组实现的动态列表,允许随机访问并支持自动扩容
public class ArrayList<E> extends AbstractList<E 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









