







 本文介绍了Pandas库中的核心数据结构——序列(Series)和数据框(DataFrame),包括如何构造、索引以及进行基本的数据操作。重点讨论了通过列表、字典和Numpy数组创建序列,以及通过嵌套列表、字典和二维数组构建数据框。此外,还讲解了如何读取文本文件(如CSV、TXT)的数据,处理数据中的缺失值、异常值,并进行了数据子集的选择。文章还涉及了数据类型转换、统计描述和数据清洗的基本方法。
本文介绍了Pandas库中的核心数据结构——序列(Series)和数据框(DataFrame),包括如何构造、索引以及进行基本的数据操作。重点讨论了通过列表、字典和Numpy数组创建序列,以及通过嵌套列表、字典和二维数组构建数据框。此外,还讲解了如何读取文本文件(如CSV、TXT)的数据,处理数据中的缺失值、异常值,并进行了数据子集的选择。文章还涉及了数据类型转换、统计描述和数据清洗的基本方法。
Pandas模块的核心操作对象就是序列(Series)和数据框(DataFrame)。序列可以理解为数据集中的一个字段,数据框是指含有至少两个字段(或序列)的数据集。
构造序列
通过同质的列表或元组构建。
通过字典构建。
通过Numpy中的一维数组构建。
通过数据框DataFrame中的某一列构建
# 导入模块
import pandas as pd
import numpy as np
# 构造序列
gdp1 = pd.Series([2.8,3.01,8.99,8.59,5.18])
gdp2 = pd.Series({'北京':2.8,'上海':3.01,'广东':8.99,'江苏':8.59,'浙江':5.18})
gdp3 = pd.Series(np.array((2.8,3.01,8.99,8.59,5.18)))
print(gdp1)
print(gdp2)
print(gdp3)
0 2.80
1 3.01
2 8.99
3 8.59
4 5.18
dtype: float64
北京 2.80
上海 3.01
广东 8.99
江苏 8.59
浙江 5.18
dtype: float64
0 2.80
1 3.01
2 8.99
3 8.59
4 5.18
dtype: float64
。不管是列表、元组还是一维数组,构造的序列结果都是第一个打印的样式。该样式会产生两列,第一列属于序列的行索引(可以理解为行号),自动从0开始,第二列才是序列的实际值。通过字典构造的序列就是第二个打印样式,仍然包含两列,所不同的是第一列不再是行号,而是具体的行名称(label),对应到字典中的键,第二列是序列的实际值,对应到字典中的值。
序列与一维数组有极高的相似性,获取一维数组元素的所有索引方法都可以应用在序列上,而且数组的数学和统计函数也同样可以应用到序列对象上,不同的是,序列会有更多的其他处理方法。
# 取出gdp1中的第一、第四和第五个元素
print('行号风格的序列:\n',gdp1[[0,3,4]])
# 取出gdp2中的第一、第四和第五个元素
print('行名称风格的序列:\n',gdp2[[0,3,4]])
# 取出gdp2中上海、江苏和浙江的GDP值
print('行名称风格的序列:\n',gdp2[['上海','江苏','浙江']])
# 数学函数--取对数
print('通过numpy函数:\n',np.log(gdp1))
# 平均gdp
print('通过numpy函数:\n',np.mean(gdp1))
print('通过序列的方法:\n',gdp1.mean())
行号风格的序列:
0 2.80
3 8.59
4 5.18
dtype: float64
行名称风格的序列:
北京 2.80
江苏 8.59
浙江 5.18
dtype: float64
行名称风格的序列:
上海 3.01
江苏 8.59
浙江 5.18
dtype: float64
通过numpy函数:
0 1.029619
1 1.101940
2 2.196113
3 2.150599
4 1.644805
dtype: float64
通过numpy函数:
5.714
通过序列的方法:
5.714
如果序列是行名称风格,既可以使用位置(行号)索引,又可以使用标签(行名称)索引;如果需要对序列进行数学函数的运算,一般首选numpy模块,因为Pandas模块在这方面比较缺乏;如果是对序列做统计运算,既可以使用numpy模块中的函数,也可以使用序列的“方法”,一般首选序列的“方法”,因为序列的“方法”更加丰富,如计算序列的偏度、峰度等,而Numpy是没有这样的函数的。
构造数据框
数据框实质上就是一个数据集,数据集的行代表每一条观测,数据集的列则代表各个变量。在一个数据框中可以存放不同数据类型的序列,如整数型、浮点型、字符型和日期时间型,而数组和序列则没有这样的优势,因为它们只能存放同质数据。构造一个数据库可以应用如下方式:
通过嵌套的列表或元组构造。
通过字典构造。
通过二维数组构造。
通过外部数据的读取构造。
# 构造数据框
df1 = pd.DataFrame([['张三',23,'男'],['李四',27,'女'],['王二',26,'女']])
df2 = pd.DataFrame({'姓名':['张三','李四','王二'],'年龄':[23,27,26],'性别':['男','女','女']})
df3 = pd.DataFrame(np.array([['张三',23,'男'],['李四',27,'女'],['王二',26,'女']]))
print('嵌套列表构造数据框:\n',df1)
print('字典构造数据框:\n',df2)
print('二维数组构造数据框:\n',df3)
嵌套列表构造数据框:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
字典构造数据框:
姓名 年龄 性别
0 张三 23 男
1 李四 27 女
2 王二 26 女
二维数组构造数据框:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
构造数据框需要使用到Pandas模块中的DataFrame函数,如果通过嵌套列表或元组构造数据框,则需要将数据框中的每一行观测作为嵌套列表或元组的元素;如果通过二维数组构造数据框,则需要将数据框的每一行写入到数组的行中;如果通过字典构造数据框,则字典的键构成数据框的变量名,对应的值构成数据框的观测。尽管上面的代码都可以构造数据框,但是将嵌套列表、元组或二维数组转换为数据框时,数据框是没有具体的变量名的,只有从0到N的列号。所以,如果需要手工构造数据框的话,一般首选字典方法。
文本文件的读取
读取txt或csv格式中的数据,可以使用Pandas模块中的read_table函数或read_csv函数。这里的“或”并不是指每个函数只能读取一种格式的数据,而是这两种函数均可以读取文本文件的数据。由于这两个函数在功能和参数使用上类似
pd.read_table(filepath_or_buffer, sep='\t', header='infer', names=None, usecols=None,skiprows=None, skipfooter=None, comment=None, encoding=None, parse_dates=False, thousands=None)
filepath_or_buffer:指定txt文件或csv文件所在的具体路径。
sep:指定原数据集中各字段之间的分隔符,默认为Tab制表符。
header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称。
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的
表头。
index_col:指定原数据集中的某些列作为数据框的行索引(标签)。
usecols:指定需要读取原数据集中的哪些变量名。
dtype:读取数据时,可以为原数据集的每个字段设置不同的数据类型。
converters:通过字典格式,为数据集中的某些字段设置转换函数。
skiprows:数据读取时,指定需要跳过原数据集开头的行数。
skipfooter:数据读取时,指定需要跳过原数据集末尾的行数。
nrows:指定读取数据的行数。
na_values:指定原数据集中哪些特征的值作为缺失值。
skip_blank_lines:读取数据时是否需要跳过原数据集中的空白行,默认为True。
parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试
解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字
典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)。
thousands:指定原始数据集中的千分位符。
comment:指定注释符,在读取数据时,如果碰到行首指定的注释符,则跳过改行。
encoding:如果文件中含有中文,有时需要指定字符编码。
数据集并不是从第一行开始,前面几行实际上是数据集的来源说明,读取数据时需要注意什么问题。数据集的末尾3行仍然不是需要读入的数据,如何避免后3行数据的读入。中间部分的数据,第四行前加了#号,表示不需要读取该行,该如何处理。数据集中的收入一列,千分位符是&,如何将该字段读入为正常的数值型数据。如果需要将year、month和day三个字段解析为新的birthday字段,该如何做到。数据集中含有中文,一般在读取含中文的文本文件时都会出现编码错误
数据来源:某公司人事记录表
时间范围:2017.1.1~2017.6.30
year,month,day,gender,occupation,income
1990,3,7,男,销售经理,6&000
1989,8,10,女,化妆师,8&500
# 1991,10,10,男,后端开发,13&500
1992,10,7,女,前端设计,6&500
1985,6,15,男,数据分析师,18&000
该数据集仅用作参考!
不可以用于他用!
备注于2018年2月。
# 读取文本文件中的数据
user_income = pd.read_table(r'data_test01.txt', sep = ',',
parse_dates={'birthday':[0,1,2]},skiprows=2, skipfooter=3,
comment='#', encoding='utf8', thousands='&')user_income
birthday gender occupation income
0 1990-03-07 男 销售经理 6000
1 1989-08-10 女 化妆师 8500
2 1992-10-07 女 前端设计 6500
3 1985-06-15 男 数据分析师 18000
由于read_table函数在读取数据时,默认将字段分隔符sep设置为Tab制表符,而原始数据集是用逗号分割每一列,所以需要改变sep参数parse_dates参数通过字典实现前三列的日期解析,并合并为新字段birthday;skiprows和
skipfooter参数分别实现原数据集开头几行和末尾几行数据的跳过;由于数据部分的第四行前面加了#号,因此通过comment参数指定跳过的特殊行;这里仅改变字符编码参数encoding是不够的,还需要将原始的txt文件另存为UTF-8格式;最后,对于收入一列,由于千分位符为&,因此为了保证数值型数据的正常读入,需要设置thousands参数为&。
pd.read_excel(io, sheetname=0, header=0, skiprows=None,
skip_footer=0, index_col=None, names=None,
parse_cols=None, parse_dates=False,
na_values=None, thousands=None,
convert_float=True)
io:指定电子表格的具体路径。
sheetname:指定需要读取电子表格中的第几个Sheet,既可以传递整数也可以传递具体
的Sheet名称。
header:是否需要将数据集的第一行用作表头,默认为是需要的。
skiprows:读取数据时,指定跳过的开始行数。
skip_footer:读取数据时,指定跳过的末尾行数。
index_col:指定哪些列用作数据框的行索引(标签)。
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的
表头。
parse_cols:指定需要解析的字段。
parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试
解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字
典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)。
na_values:指定原始数据中哪些特殊值代表了缺失值。
thousands:指定原始数据集中的千分位符。
convert_float:默认将所有的数值型字段转换为浮点型字段。
converters:通过字典的形式,指定某些列需要转换的形式。
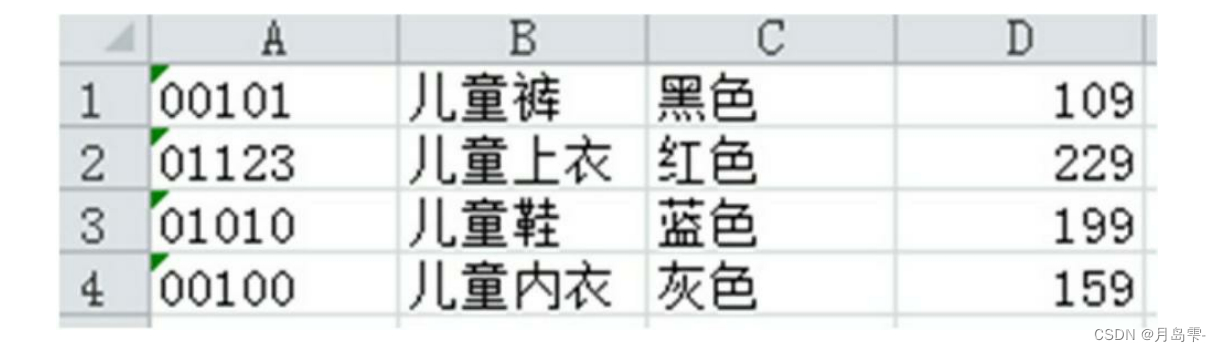
一
点是该表没有表头,如何读数据的同时就设置好具体的表头;另一点是数据集的第一列实际上是字符型的字段
child_cloth = pd.read_excel(io = r'd:\data_test02.xlsx', header = None,
names = ['Prod_Id','Prod_Name','Prod_Color','Prod_Price'], converters = {0:str})
child_cloth
Prod_Id Prod_Name Prod_Color Prod_Price
0 00101 儿童裤 黑色 109
1 01123 儿童上衣 红色 229
2 01010 儿童鞋 蓝色 199
3 00100 儿童内衣 灰色 159
数据类型转换与描述性统计
sec_cars=pd.read_table('sec_cars.csv',sep=',')
sec_cars.head()
sec_cars.shape
sec_cars.dtypes
Brand Name Boarding_time Km(W) Discharge Sec_price New_price
0 众泰 众泰T600 2016款 1.5T 手动 豪华型 2016年5月 3.96 国4 6.8 9.42万
1 众泰 众泰Z700 2016款 1.8T 手动 典雅型 2017年8月 0.08 国4,国5 8.8 11.92万
2 众泰 大迈X5 2015款 1.5T 手动 豪华型 2016年9月 0.80 国4 5.8 8.56万
3 众泰 众泰T600 2017款 1.5T 手动 精英贺岁版 2017年3月 0.30 国5 6.2 8.66万
4 众泰 众泰T600 2016款 1.5T 手动 旗舰型 2016年2月 1.70 国4 7.0 11.59万
该数据集一共包含了10 948条记录和7个变量,除二手车价格Sec_price和行驶里程数Km(W)为浮点型数据之外,其他变量均为字符型变量。但是,从表5-5来看,二手车的上牌时间Boarding_time应该为日期型,新车价New_price应该为浮点型,为了后面的数据分析,需要对这两个变量进行类型的转换
sec_cars.Boarding_time = pd.to_datetime(sec_cars.Boarding_time,format='%Y年%m月')
sec_cars.New_price = sec_cars.New_price.str[:-1].astype('float')
Brand Name Boarding_time Km(W) Discharge Sec_price New_price
0 众泰 众泰T600 2016款 1.5T 手动 豪华型 2016-05-01 3.96 国4 6.8 9.42
1 众泰 众泰Z700 2016款 1.8T 手动 典雅型 2017-08-01 0.08 国4,国5 8.8 11.92
2 众泰 大迈X5 2015款 1.5T 手动 豪华型 2016-09-01 0.80 国4 5.8 8.56
3 众泰 众泰T600 2017款 1.5T 手动 精英贺岁版 2017-03-01 0.30 国5 6.2 8.66
4 众泰 众泰T600 2016款 1.5T 手动 旗舰型 2016-02-01 1.70 国4 7.0 11.59
上牌时间Boarding_time更改为了日期型数据,新车价格New_price更改为了浮点型数据。需要说明的是,Pandas模块中的to_datetime函数可以通过
format参数灵活地将各种格式的字符型日期转换成真正的日期数据;由于二手车新车价格含有“万”字,因此不能直接转换数据类型,为达到目的,需要三步走,首先通过str方法将该字段转换成字符串,然后通过切片手段,将“万”字剔除,最后运用astype方法,实现数据类型的转换
sec_cars.New_price.str[:-1]
sec_cars.New_price[:-1]
sec_cars.Sec_price.values[:-1]
num_variables = sec_cars.columns[sec_cars.dtypes !=‘object’][1:]
sec_cars[num_variables].apply(func = skew_kurt, axis = 0)
# 数据的描述性统计
sec_cars.describe()
# 数据的形状特征
# 挑出所有数值型变量
num_variables = sec_cars.columns[sec_cars.dtypes !='object'][1:]
# 自定义函数,计算偏度和峰度
def skew_kurt(x):
skewness = x.skew()
kurtsis = x.kurt()
# 返回偏度值和峰度值
return pd.Series([skewness,kurtsis], index = ['Skew','Kurt'])
# 运用apply方法
sec_cars[num_variables].apply(func = skew_kurt, axis = 0)
字符型变量(如二手车品牌Brand、排放量Discharge等)该如何做统计描述呢?仍然可以使用describe方法,所不同的是,需要设置该方法中的include参数
# 离散型变量的统计描述
sec_cars.describe(include = ['object'])
Brand Name Discharge
count 10984 10984 10984
unique 104 4374 33
top 别克 经典全顺 2010款 柴油 短轴 多功能 中顶 6座 国4
freq 1346 126 4262
如上结果包含离散变量的四个统计值,分别是非缺失观测数、唯一水平数、频次最高的离散值和具体的频次。以二手车品牌为例,一共有10 984辆二手车,包含104种品牌,其中别克品牌最多,高达1 346辆。需要注意的是,如果对离散型变量作统计分析,需要将“object”以列表的形式传递给include参数。对于离散型变量,运用describe方法只能得知哪个离散水平属于“明星”值。
统计的是各个离散值的频次,甚至是对应的频率,该如何计算呢?这里直接给出如下代码(以二手车品的标准排量Discharge为例)
Freq = sec_cars.Discharge.value_counts()
# 离散变量频次统计
Freq = sec_cars.Discharge.value_counts()
Freq_ratio = Freq/sec_cars.shape[0]
Freq_df = pd.DataFrame({'Freq':Freq,'Freq_ratio':Freq_ratio})
Freq_df.head()
Freq Freq_ratio
国4 4262 0.388019
欧4 1848 0.168245
欧5 1131 0.102968
国4,国5 843 0.076748
国3 772 0.070284
如上结果所示,构成的数据框包含两列,分别是二手车各种标准排量对应的频次和频率,数据框的行索引(标签)就是二手车不同的标准排量。如果需要把行标签设置为数据框中的列,可以使用reset_index方法,具体操作如下:
# 将行索引重设为变量
Freq_df.reset_index(inplace = True)
Freq_df.head()
index Freq Freq_ratio
0 国4 4262 0.388019
1 欧4 1848 0.168245
2 欧5 1131 0.102968
3 国4,国5 843 0.076748
4 国3 772 0.070284
reset_index
将reset_index方法中的inplace参数设置为True,表示直接对原始数据集进
行操作,影响到原数据集的变化,否则返回的只是变化预览,并不会改变原数据集。

如何更改出生日期birthday和手机号tel两个字段的数据类型。
如何根据出生日期birthday和开始工作日期start_work两个字段新增年龄和工龄两个字
段。
如何将手机号tel的中间四位隐藏起来。
如何根据邮箱信息新增邮箱域名字段。
如何基于other字段取出每个人员的专业信息
# 数据读入
df = pd.read_excel(r'd:\data_test03.xlsx')
# 各变量数据类型
print(df.dtypes)
# 将birthday变量转换为日期型
df.birthday = pd.to_datetime(df.birthday, format = '%Y/%m/%d')
# 将手机号转换为字符串
df.tel = df.tel.astype('str')
# 新增年龄和工龄两列
df['age'] = pd.datetime.today().year - df.birthday.dt.year
df['workage'] = pd.datetime.today().year - df.start_work.dt.year
# 将手机号中间四位隐藏起来
df.tel = df.tel.apply(func = lambda x : x.replace(x[3:7], '****'))
# 取出邮箱的域名
df['email_domain'] = df.email.apply(func = lambda x : x.split('@')[1])
# 取出用户的专业信息
df['profession'] = df.other.str.findall('专业:(.*?),')
# 去除birthday、start_work和other变量
df.drop(['birthday','start_work','other'], axis = 1, inplace = True)
df.head()
name gender income tel email age workage email_domain profession
0 赵一 男 15000 136****1234 zhaoyi@qq.com 34 11 qq.com [电子商务]
1 王二 男 12500 135****2234 wanger@163.com 33 9 163.com [汽修]
2 张三 女 18500 135****3330 zhangsan@qq.com 36 14 qq.com [数学]
3 李四 女 13000 139****3388 lisi@gmail.com 32 9 gmail.com [统计学]
4 刘五 女 8500 178****7890 liuwu@qq.com 31 9 qq.com [美术]
通过dtypes方法返回数据框中每个变量的数据类型,由于出生日期birthday为字符型、手
机号tel为整型,不便于第二问和第三问的回答,所以需要进行变量的类型转换。这里通
过Pandas模块中的to_datetime函数将birthday转换为日期型(必须按照原始的birthday格
式设置format参数);使用astype方法将tel转换为字符型。
对于年龄和工龄的计算,需要将当前日期与出生日期和开始工作日期进行减法运算,
而当前日期的获得,则使用了Pandas子模块datetime中的today函数。由于计算的是相隔
的年数,所以还需进一步取出日期中的年份(year方法)。需要注意的是,对于birthday和
start_work变量,使用year方法之前,还需使用dt方法,否则会出错。
隐藏手机号的中间四位和衍生出邮箱域名变量,都是属于字符串的处理范畴,两个问
题的解决所使用的方法分布是字符串中的替换法(replace)和分割法(split)。由于替换
法和分割法所处理的对象都是变量中的每一个观测,属于重复性工作,所以考虑使用
序列的apply方法。需要注意的是,apply方法中的func参数都是使用匿名函数,对于隐藏
手机号中间四位的思路就是用星号替换手机号的中间四位;对于邮箱域名的获取,其思
路就是按照邮箱中的@符风格,然后取出第二个元素(列表索引为1)。
从other变量中获取人员的专业信息,该问题的解决使用了字符串的正则表达式,不管
是字符串“方法”还是字符串正则,在使用前都需要对变量使用一次str方法。由于findall
返回的是列表值,因此衍生出的email_domain字段值都是列表类型,如果读者不想要这
个中括号,可以参考第三问或第四问的解决方案,这里就不再赘述了。
如果需要删除数据集中的某些变量,可以使用数据框的drop方法。该方法接受的第一个
参数,就是被删除的变量列表,尤其要注意的是,需要将axis参数设置为1,因为默然
drop方法是用来删除数据框中的行记录。
重复数据
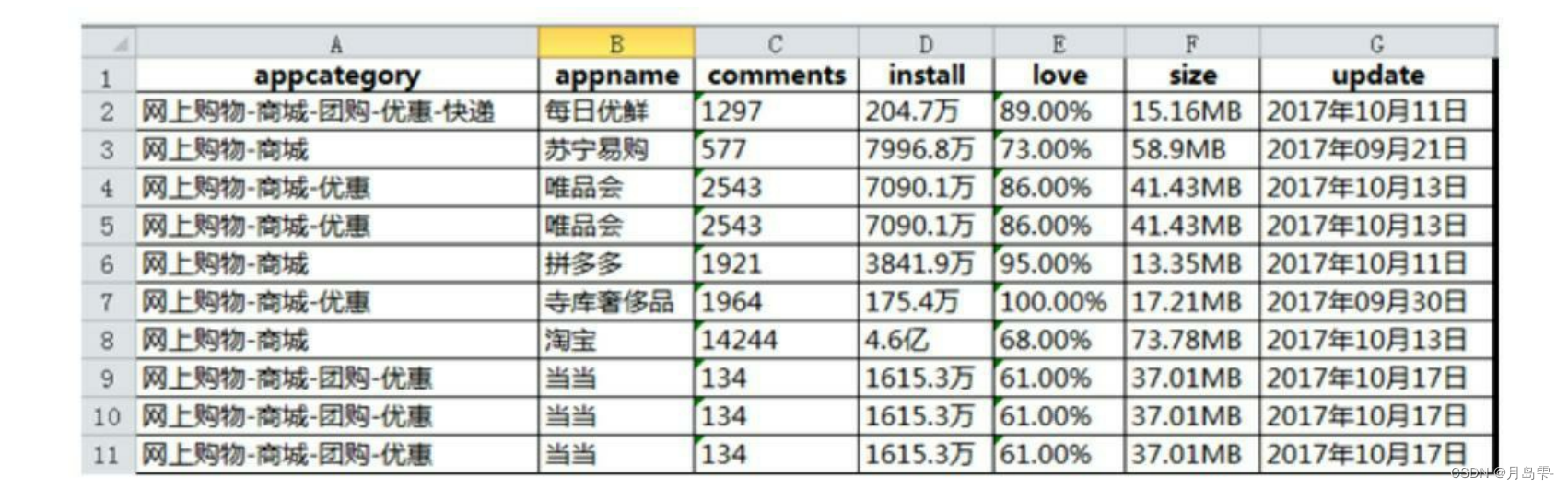
可以使用duplicated方法进行验证,但是该方法返回的是数据集每一行的检验结果,即10行数据会返回10个bool值。很显然,这样也不能直接得知数据集的观测是否重复,为了能够得到最直接的结果,可以使用any函数。该函数表示的是个条件判断中,只要有一个条件为True,则any函数的结果就为True。正如结果所示,any函数的运用返回True值,说明该数据集是存在重复观测的
# 数据清洗
# 数据读入
df = pd.read_excel('data_test04.xlsx')
# 重复观测的检测
df.duplicated()
print('数据集中是否存在重复观测:\n',any(df.duplicated()))
# 删除重复项
df.drop_duplicates(inplace = True)
0 False
1 False
2 False
3 True
4 False
5 False
6 False
7 False
8 True
9 True
dtype: bool
数据集中是否存在重复观测:
True
缺失值
当遇到缺失值(Python中用NaN表示)时,可以采用三种方法处置,分别是删除法、替换法和插补法。删除法是指当缺失的观测比例非常低时(如5%以内),直接删除存在缺失的观测,或者当某些变量的缺失比例非常高时(如85%以上),直接删除这些缺失的变量;替换法是指用某种常数直接替换那些缺失值,例如,对连续变量而言,可以使用均值或中位数替换,对于离散变量,可以使用众数替换;插补法是指根据其他非缺失的变量或观测来预测缺失值,常见的插补法有回归插补法、K近邻插补法、拉格朗日插补法等。
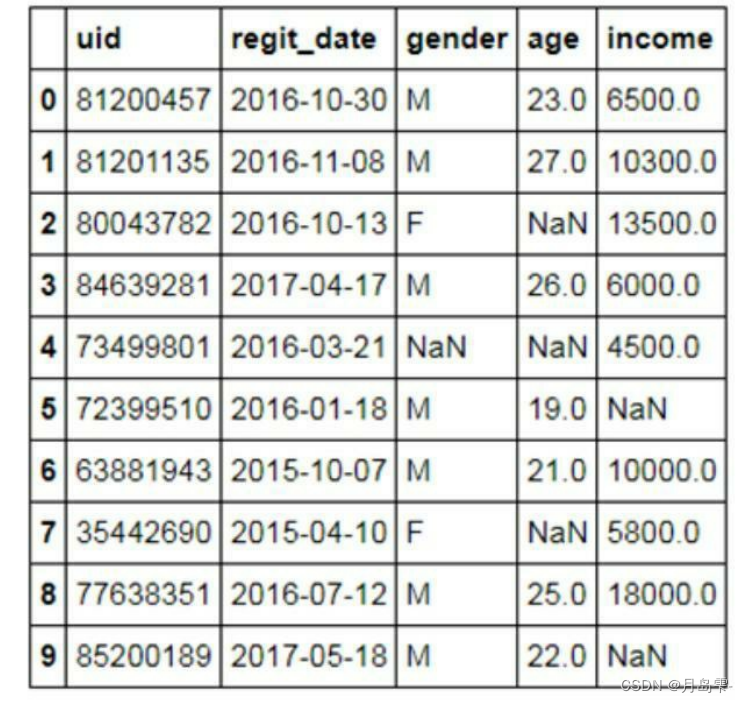
检测数据集是否存在重复观测使用的是isnull方法,该方法仍然是基于每一行的检测,所以仍然需要使用any函数,返回整个数据集中是否存在缺失的结果。从代码返回的结果看,该数据集确实是存在缺失值的。
# 数据读入
df = pd.read_excel(r'd:\data_test05.xlsx')
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
# 删除法之记录删除
df.dropna()
# 删除法之变量删除
df.drop('age', axis = 1)
# 替换法之前向替换
df.fillna(method = 'ffill')
# 替换法之后向替换
df.fillna(method = 'bfill')
# 替换法之常数替换
df.fillna(value = 0)
# 替换法之统计值替换
df.fillna(value = {'gender':df.gender.mode()[0], 'age':df.age.mean(), 'income':df.income.median()})
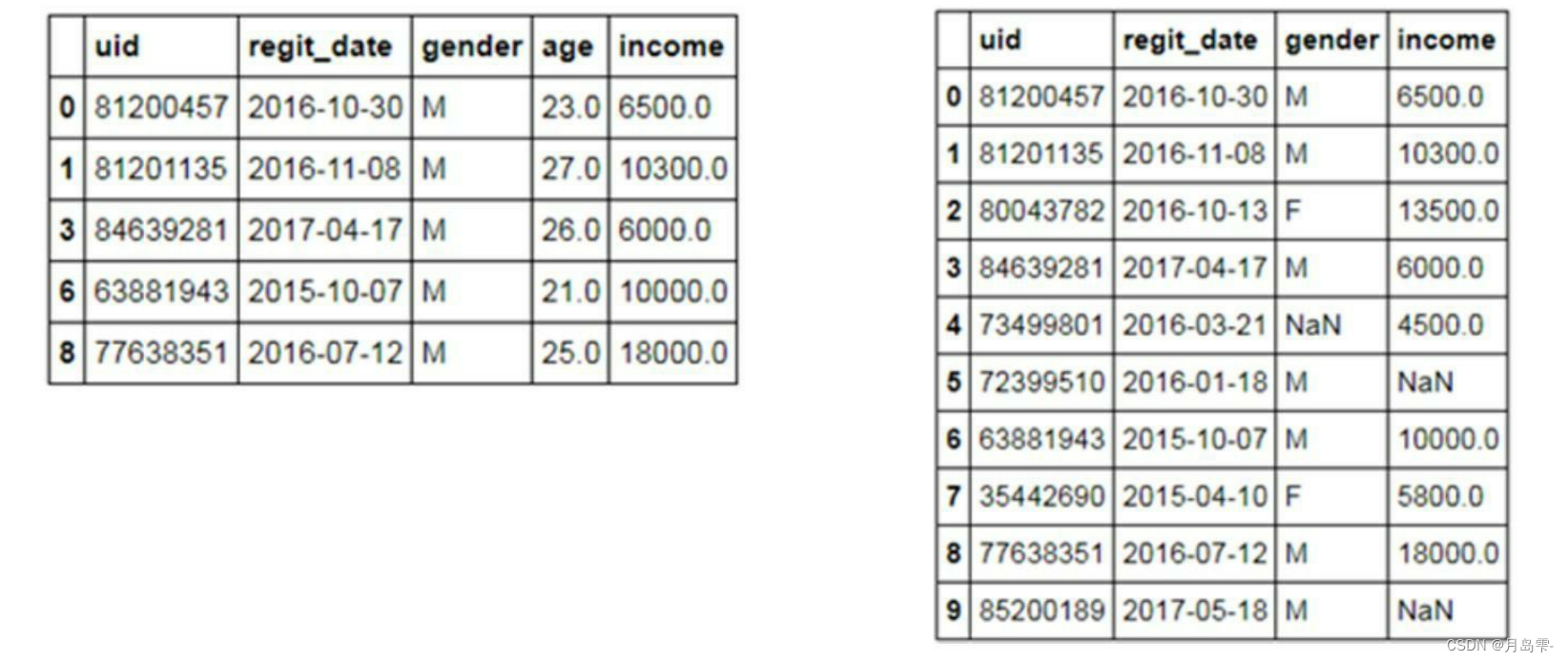
左表为行删除法,即将所有含缺失值的行记录全部删除,使用dropna方法;
右表为变量删除法,由于原数据集中age变量的缺失值最多,所以使用drop方法将age变量删除。
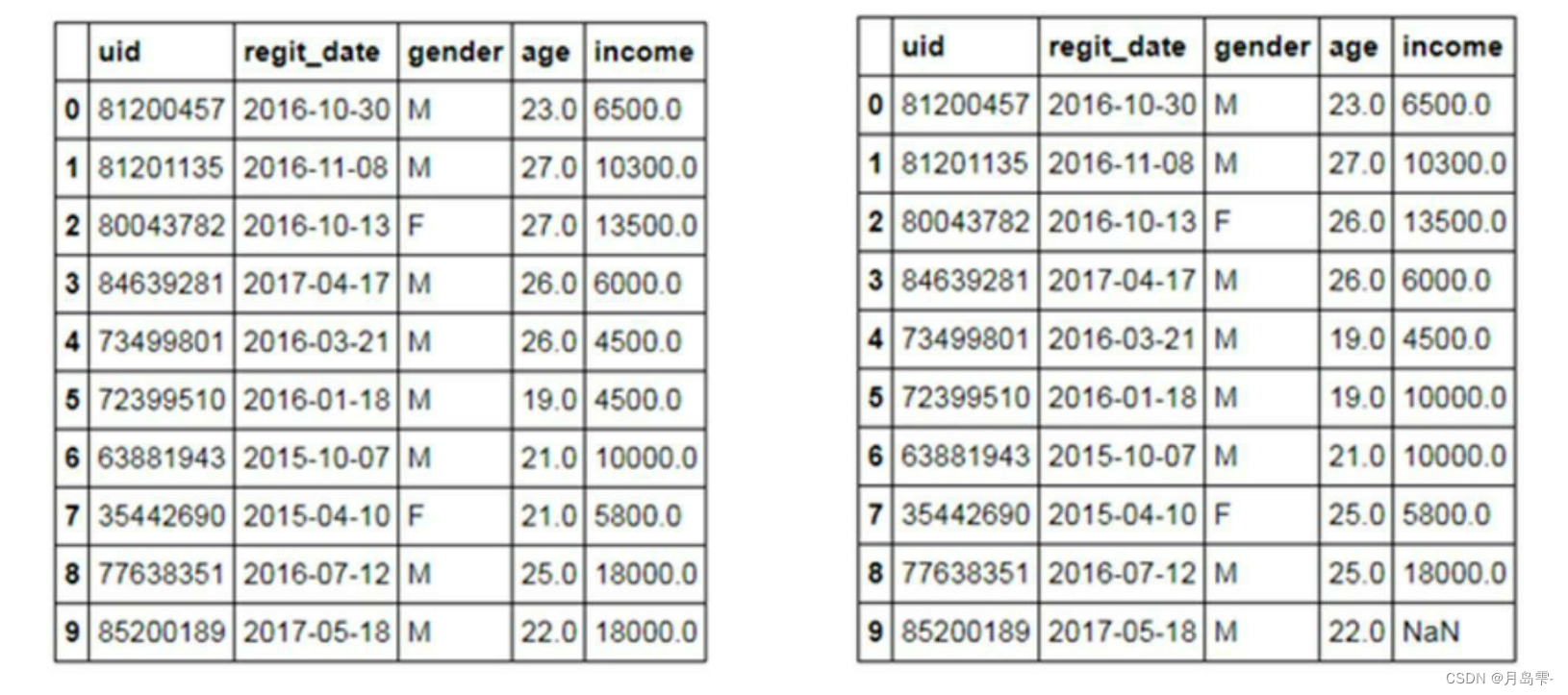
缺失值的替换需要借助于fillna方法,该方法中的method参数可以接受’ffill’和’bfill’两种值,分别代表前向填充和后向填充。前向填充是指用缺失值的前一个值替换(如左表所示),而后向填充则表示用缺失值的后一个值替换(如右表所示)。右表中的最后一个记录仍包含缺失值,是因为后向填充法找不到该缺失值的后一个值用于替换。缺失值的前向填充或后向填充一般适用于时间序列型的数据集,因为这样的数据前后具有连贯性,而一般的独立性样本并不适用该方法。
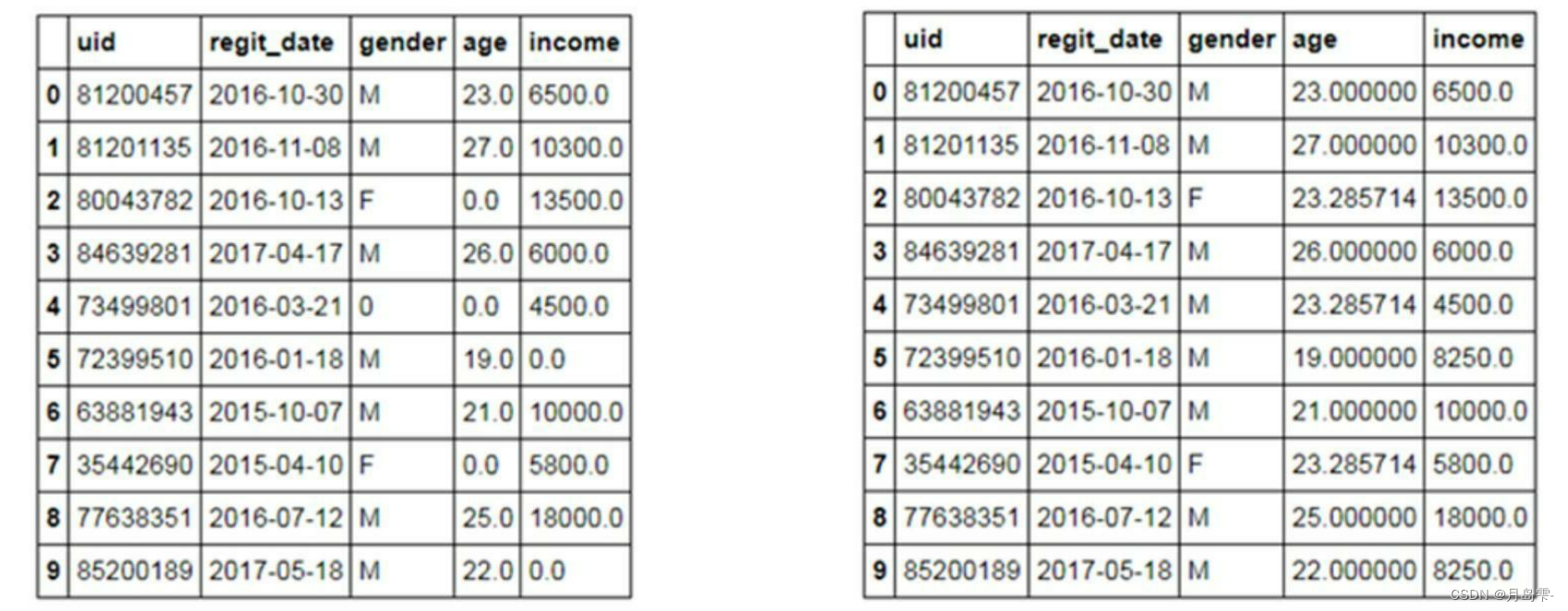
另一种替换手段仍然是使用fillna方法,只不过不再使用method参数,而是使用value参数。左表是使用一个常数0替换所有的缺失值(有些情况是有用的,例如某人确实没有工作,故收入为0),但是该方法就是典型的“以点概面”,非常容易导致错误,例如结果中的性别莫名多出异样的0值;右表则是采用了更加灵活的替换方法,即分别对各缺失变量使用不同的替换值(需
要采用字典的方式传递给value参数),性别使用众数替换,年龄使用均值替换,收入使用中位数替换。需要说明的是,如上代码并没有实际改变df数据框的结果,因为dropna、drop和fillna方法并没有使inplace参数设置为True。读者可以在实际的学习和工作中挑选一个适当的缺失值处理方法,然后将该方法中的inplace参数设置为True,进而可以真正地改变你所处理的数据集。


# 数据读入
sunspots = pd.read_table('dsunspots.csv', sep = ',')
# 异常值检测之标准差法
xbar = sunspots.counts.mean()
xstd = sunspots.counts.std()
print('标准差法异常值上限检测:\n',any(sunspots.counts > xbar + 2 * xstd))
print('标准差法异常值下限检测:\n',any(sunspots.counts < xbar - 2 * xstd))
# 异常值检测之箱线图法
Q1 = sunspots.counts.quantile(q = 0.25)
Q3 = sunspots.counts.quantile(q = 0.75)
IQR = Q3 - Q1
print('箱线图法异常值上限检测:\n',any(sunspots.counts > Q3 + 1.5 * IQR))
print('箱线图法异常值下限检测:\n',any(sunspots.counts < Q1 - 1.5 * IQR))
标准差法异常值上限检测:
True
标准差法异常值下限检测:
False
箱线图法异常值上限检测:
True
箱线图法异常值下限检测:
False
# 导入绘图模块
import matplotlib.pyplot as plt
# 设置绘图风格
plt.style.use('ggplot')
# 绘制直方图
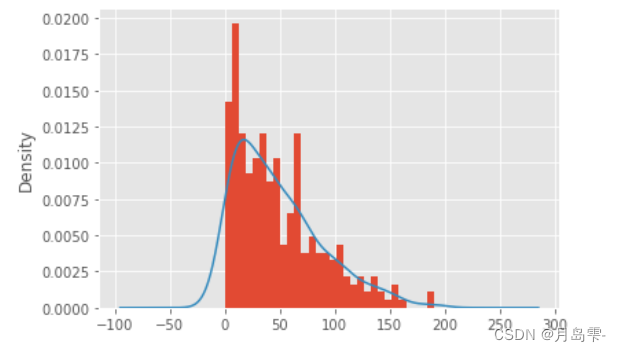
sunspots.counts.plot(kind = 'hist', bins = 30, density = True,stacked=True)
# 绘制核密度图
sunspots.counts.plot(kind = 'kde')
# 图形展现
plt.show()
使用替换法来处理异常值,即使用低于判别上限的最大值或高于判别下限的最小值替换
# 替换法处理异常值
print('异常值替换前的数据统计特征:\n',sunspots.counts.describe())
# 箱线图中的异常值判别上限
UL = Q3 + 1.5 * IQR
print('判别异常值的上限临界值:\n',UL)
# 从数据中找出低于判别上限的最大值
replace_value = sunspots.counts[sunspots.counts < UL].max()
print('用以替换异常值的数据:\n',replace_value)
# 替换超过判别上限异常值
sunspots.counts[sunspots.counts > UL] = replace_value
print('异常值替换后的数据统计特征:\n',sunspots.counts.describe())
异常值替换前的数据统计特征:
count 289.000000
mean 48.613495
std 39.474103
min 0.000000
25% 15.600000
50% 39.000000
75% 68.900000
max 190.200000
Name: counts, dtype: float64
判别异常值的上限临界值:
148.85000000000002
用以替换异常值的数据:
141.7
异常值替换后的数据统计特征:
count 289.000000
mean 48.066090
std 37.918895
min 0.000000
25% 15.600000
50% 39.000000
75% 68.900000
max 141.700000
Name: counts, dtype: float64
数据子集
iloc、loc和ix
[rows_select,cols_select]
iloc只能通过行号和列号进行数据的筛选,读者可以将iloc中的“i”理解为“integer”,即只能向[rows_select, cols_select]指定整数列表。该索引方式与数组的索引方式类似,都是从0开始,可以间隔取号,对于切片仍然无法取到上限。
loc要比iloc灵活一些,读者可以将loc中的“l”理解为“label”,即可以向[rows_select,cols_select]指定具体的行标签(行名称)和列标签(字段名)。注意,这里是标签不再是索引。而且,还可以将rows_select指定为具体的筛选条件,在iloc中是无法做到的。
ix是iloc和loc的混合,读者可以将ix理解为“mix”,该“方法”吸收了iloc和loc的优点,使数据框子集的获取更加灵活
# 数据子集的获取
# 构造数据集
df1 = pd.DataFrame({'name':['张三','李四','王二','丁一','李五'],
'gender':['男','女','女','女','男'],
'age':[23,26,22,25,27]}, columns = ['name','gender','age'])
df1
name gender age
0 张三 男 23
1 李四 女 26
2 王二 女 22
3 丁一 女 25
4 李五 男 27
如上结果所示,如果原始数据的行号与行标签(名称)一致,iloc、loc和ix三种方法都可以取出满足条件的数据子集。所不同的是,iloc运用了索引的思想,故中间三行的表示必须用1:4,因为切片索引取不到上限,同时,姓名和年龄两列也必须用数值索引表示;loc是指获取行或列的标签(名称),由于该数据集的行标签与行号一致,所以1:3就表示对应的3个行名称,而姓名和年龄两列的获取就不能使用数值索引了,只能写入具体的变量名称;ix则混合了iloc与loc的优点,如果数据集的行标签与行号一致,则ix对观测行的筛选与loc的效果一样,但是ix对变量名的筛选既可以使用对应的列号(如代码所示),也可以使用具体的变量名称。
pandas版本0.20.0及其以后版本中,ix已经不被推荐使用
假如数据集没有行号,而是具体的行名称,该如何使用这三种方法实现中间三行数据的获取
# 将员工的姓名用作行标签
df2 = df1.set_index('name')
df2
# 取出数据集的中间三行
df2.iloc[1:4,:]
df2.loc[['李四','王二','丁一'],:]
df2.ix[1:4,:]
gender age
name
张三 男 23
李四 女 26
王二 女 22
丁一 女 25
李五 男 27
这时的数据集是以员工姓名作为行名称,不再是之前的行号,对于目标数据的返回同样可以使用iloc、loc和ix三种方法。对于iloc来说,不管什么形式的数据集都可以使用,始终表示行索引,即取哪些行下标的观测;loc就不能使用数值表示行标签了,因为此时数据集的行标签是姓名,所以需要写入中间三行对应的姓名;通过ix方法,既可以用行索引(如代码所示)表示,也可以用行标签表示,可根据读者的喜好选择。由于并没有对数据集的变量做任何限制,所以cols_select用英文冒号表示,代表取出数据集的所有变量。
在实际的学习和工作中,观测行的筛选很少是通过写入具体的行索引或行标签,而是对某些列做条件筛选,进而获得目标数据。例如,在上面的df1数据集中,如何返回所有男性的姓名和年龄
# 使用筛选条件,取出所有男性的姓名和年龄
# df1.iloc[df1.gender == '男',]
df1.loc[df1.gender == '男',['name','age']]
name age
0 张三 23
4 李五 27
如果是基于条件的记录筛选,只能使用loc和ix两种方法。正如代码所示,对iloc方法的那行代码做注释,是因为iloc不允许使用条件筛选,这行代码是无法运行成功的。对变量名的筛选,loc必须指定具体的变量名,而ix既可以使用变量名,也可以使用字段的数值索引。
concat函数和merge函数
pd.concat(objs, axis=0, join='outer', join_axes=None,
ignore_index=False, keys=None)
objs:指定需要合并的对象,可以是序列、数据框或面板数据构成的列表
axis:指定数据合并的轴,默认为0,表示合并多个数据的行,如果为1,就表示合并多个数据的列
join:指定合并的方式,默认为outer,表示合并所有数据,如果改为inner,表示合并公共部分的数据
join_axes:合并数据后,指定保留的数据轴
ignore_index:bool类型的参数,表示是否忽略原数据集的索引,默认为False,如果设为True,就表示
忽略原索引并生成新索引
keys:为合并后的数据添加新索引,用于区分各个数据部分
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'))
left:指定需要连接的主
right:指定需要连接的辅表
how:指定连接方式,默认为inner内连,还有其他选项,如左连left、右连right和外连outer
on:指定连接两张表的共同字段


















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









