






文接上回,这篇主要讲编写网页爬虫时,模仿请求头(“User-Agent")....
为什么有的时候需要模仿请求头呢?
防止被识别为爬虫: 网站通常会使用一些机制来检测是否是正常用户访问,或者是爬虫行为。通过模仿浏览器的请求头,尤其是“User-Agent”,可以让爬虫看起来像是一个普通用户的访问请求,而不是机器自动发送的请求。如果不设置请求头,很多网站可能会根据请求头中的信息(如没有
User-Agent,或是User-Agent显示为Python库等)来识别并阻止爬虫访问。获取动态内容: 一些网站(特别是现代的Web应用)使用JavaScript动态加载数据。此时,单纯的HTTP请求可能无法获得完整的数据,因为数据是通过前端请求(可能会携带复杂的请求头)加载的。爬虫模仿真实浏览器的请求头,特别是“Referer”和“Origin”,可能会帮助爬虫获取这些动态内容。
反爬虫机制: 许多网站会设置反爬虫策略(如防止频繁请求,或基于IP和请求头来限制访问)。一些反爬虫机制依赖于请求头来判断请求的合法性。通过添加适当的请求头,爬虫可以规避这些反爬虫措施。例如,通过“Accept-Language”、“Accept-Encoding”等请求头,模拟浏览器的行为,网站就更难判断是否为爬虫。
请求头与会话/状态管理: 请求头中还可能包含一些会话信息(如
Cookie),如果网站需要特定的会话状态或认证信息,爬虫就需要在请求头中添加相关信息(如通过登录获取的Cookie)。如果没有设置这些请求头,爬虫可能无法获取需要的数据。
有些网站会为了防止爬虫,会通过检查请求头来区分正常用户请求和爬虫,尤其是检查User-Agent。比如:微博,推特,脸书等通常会检查User-Agent及Referer,Accept-Language等请求头的内容;淘宝,京东等网站也会为了防止爬虫抢购商品要求模拟用户的请求头;知乎,网易等新闻网站也会检查来防止恶意抓取;还有谷歌等搜索引擎也会。。。。
下面以zhi hu(不要拿来干坏事啊,孩子害怕,啊啊啊啊)为例:
先不模仿请求头,来看看会发生什么:
import requests
from bs4 import BeautifulSoup
url = "https://www.zhihu.com/"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
print(soup.prettify())
else:
print('请求失败,状态码为:', response.status_code)输出结果如下图:
![]()
模仿请求头后又是什么样子呢?
import requests
from bs4 import BeautifulSoup
# 模拟请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9',
'cookie': '_zap=17fb613e-0b8d-4db2-8fdc-74f75ec299f3; _xsrf=74889dab-e7fe-43eb-a37a-06a15d243203; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1736060516; HMACCOUNT=131631636F0FBB99; d_c0=AVDSx_pkzRmPTsUuzqzx5S-mkqAZn_OCO9w=|1736060517; SESSIONID=ApNczpeiTAW4Hz4TbcH6IgkEHn1hDvrA5KgnIjLaE7G; captcha_session_v2=2|1:0|10:1736060518|18:captcha_session_v2|88:emFUdnBXWmFXV3VxMlVxQnVnWFpQNXpscHh0R1JzY01SRSszb1JNZkV4MEY5TVBzT2JHejRIM1lSYWoxYmlhcw==|66743907d2c25300c86b90bca1d1e217881d247a83430bb584a53562d130add6; JOID=UV0XBkhAwPKApIDFE0bmoXdf4g4LB7e75d72p30Uh6Kz6vr3QCfuieGigcUSLni9ridOsTWeySN5uZlgE5xi9Qg=; osd=Wl4WB05Lw_OBoovGEkfgqnRe4wgABLa649X1pnwSjKGy6_z8Qybvj-qhgMQUJXu8ryFFsjSfzyh6uJhmGJ9j9A4=; __snaker__id=FDLCJM69PiJknI78; gdxidpyhxdE=mPRr3SufJgB1DR1%2F52jxse%2FnC9MoZyH507%2F8qDu%5C%2B8ou8CxvMWvyjl8IXALw4MTMCiDmins4o%2FtWwvqYJzHwcr7uzH16hRSuX3hpbwnM%2BY7z6H4PDc5e4YTKZUTwvwSaNA4C0cReclEbJa%2B%2FJsJwkhOKR2f1tR1YqjOODw2wlc%2BdQxeq%3A1736061417316; o_act=login; utm_source=google; ref_source=other_https://www.zhihu.com/signin?next=/; expire_in=15552000; q_c1=13927f3b95af41128eca2c8a279cd2c6|1736060534000|1736060534000; tst=r; BEC=684e706569bf16169217bb2a788786f3; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1736060533; z_c0=2|1:0|10:1736060535|4:z_c0|92:Mi4xd2dLSEN3QUFBQUFCVU5MSC1tVE5HUmNBQUFCZ0FsVk5kbnhuYUFDeTNfOGxuck1HeDFySnNmLWk4T25NbkhlYTNR|e065d32c177ef2166916eca37bc6aa0dc29db187e7a429e70c01e64ed3291be0',
'upgrade-insecure-requests': '1',
}
url = "https://www.zhihu.com/"
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
print(soup.prettify())
else:
print('请求失败,状态码为:', response.status_code)输出结果如下图:
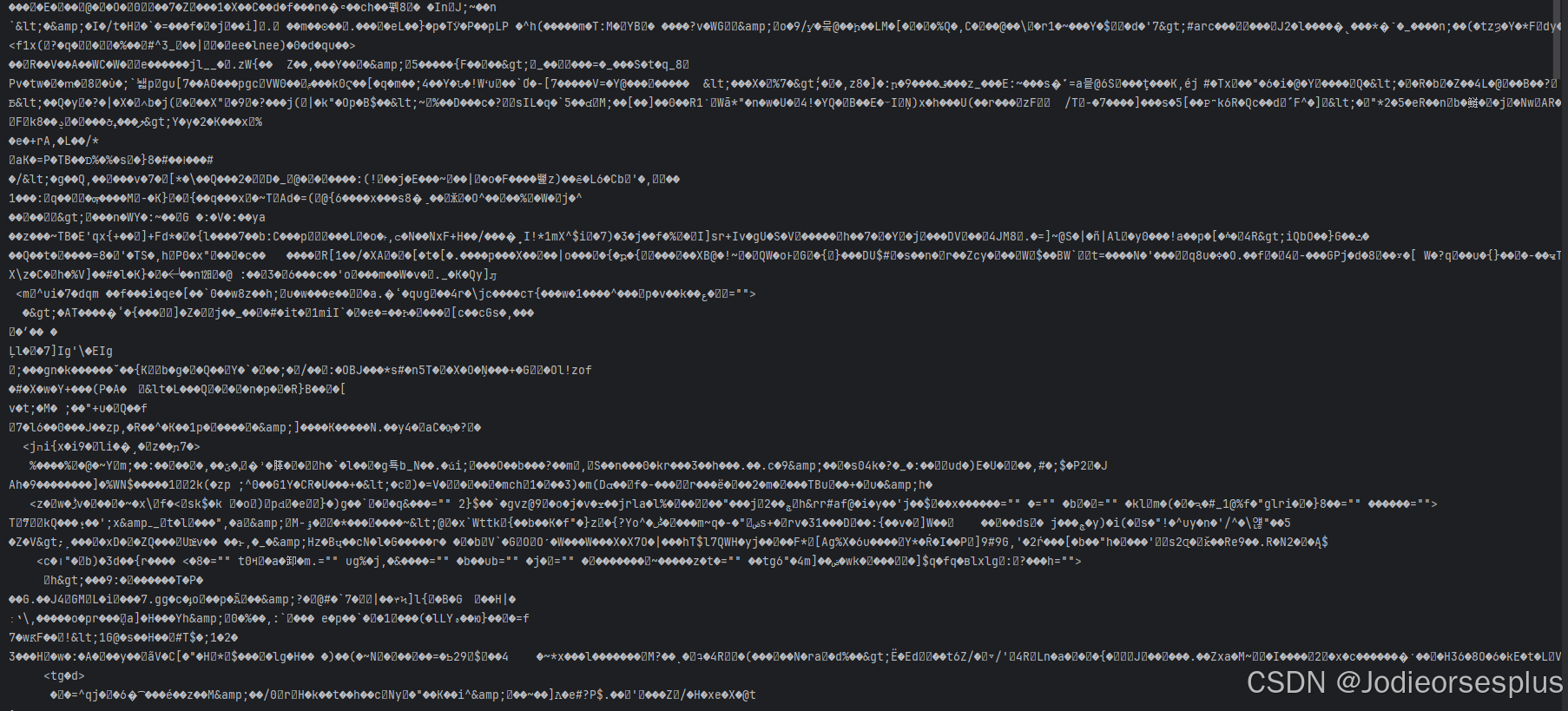
可以看到有了输出结果,但是一堆乱码。但这个乱码其实就是我们想要的内容,但为什么是乱码其实就涉及到更深层的东西了,不是这篇博文要说的重点。
某些网站,比如知乎,可能对爬虫流量返回加密或混淆的内容,这种情况下需要模拟更完整的浏览器行为,可以用selenium。如果以后心血来潮再讨论讨论吧,哈哈哈,三分钟热度。
未来可能不会写,也可能会写,先剧透一下(下面的代码你应该是要安装一点东西的,时间太久不太记得了):
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
# 配置 selenium 的浏览器选项
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
options.add_argument('--disable-gpu') # 禁用GPU
options.add_argument('--no-sandbox') # 非沙盒模式
# 初始化 WebDriver
driver = webdriver.Chrome(options=options)
# 目标URL
url = "https://www.zhihu.com/"
# 访问网页
driver.get(url)
# 等待页面加载完成(根据网络情况设置适当等待时间)
time.sleep(5)
# 获取渲染后的页面HTML
html = driver.page_source
# 使用 BeautifulSoup 解析
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())
# 关闭浏览器
driver.quit()输出结果(只post部分截图吧。保命要紧!!!):
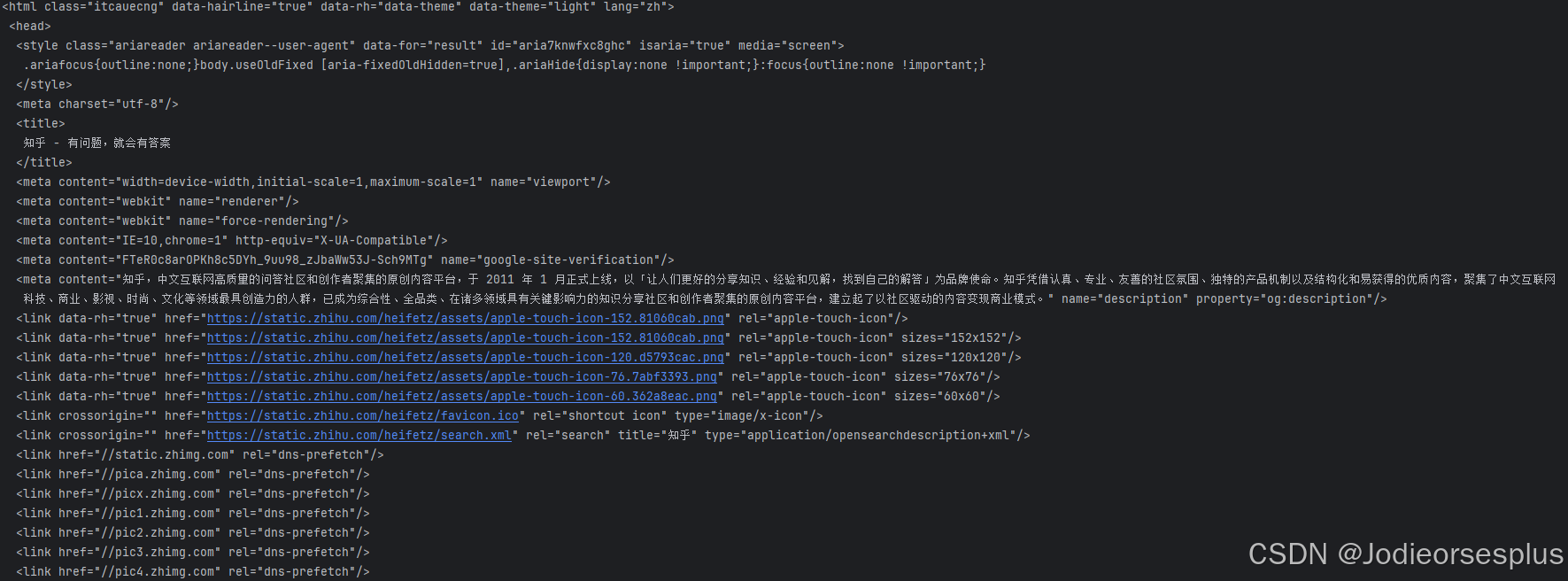
对了,后续请期待下一篇博文。有什么建议和好的指导,欢迎私信或者留言,大家一同进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









