







获取途径(🛰):NzqDssm16
课题意义及目标
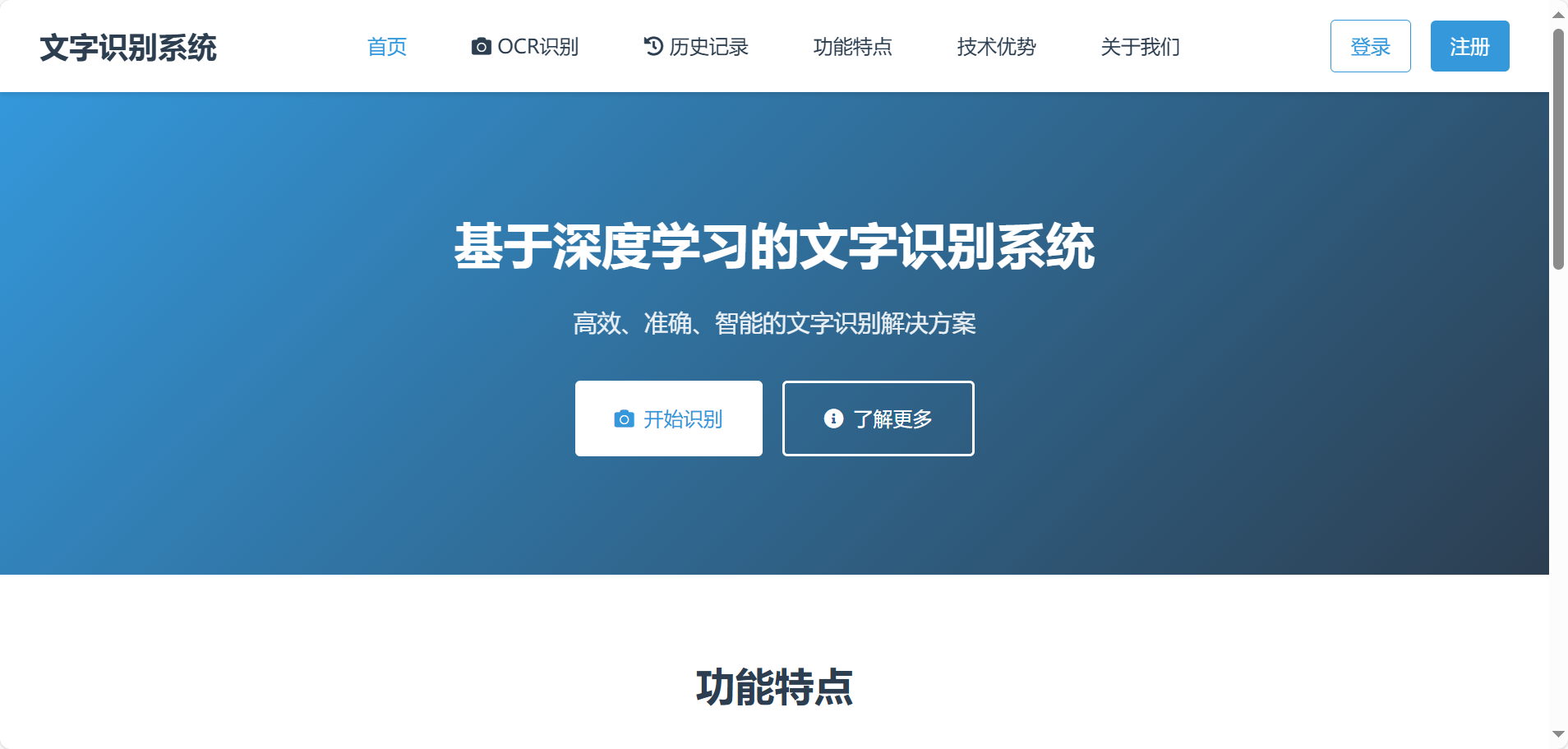
在当今数字化信息时代,文字信息呈爆炸式增长。随着全球化的发展,多语言文字识别的需求日益增长。传统的文字识别方法在面对复杂多样的字体、模糊或有干扰的文本图像时,识别准确率有限,且处理效率低下,难以满足大规模、高精度文字识别的需求。实际应用中的文字图像可能会受到光照不均、噪声干扰、拍摄角度倾斜等多种因素影响。在一些对实时性要求较高的场景,如实时视频文字识别、快速文档处理等,需要文字识别系统能够快速给出识别结果。为解决这些问题,本研究设计并实现基于深度学习的文字识别系统。该系统旨在利用深度学习强大的特征学习与模式识别能力,有效提高文字识别的准确率与速度,能够广泛应用于文档数字化、图像文字提取、无障碍阅读等多个领域,自动识别和提取文字信息,提高办公效率,降低人工录入的成本和错误率。深度学习通过构建深层次的神经网络模型,能够自动学习文字的特征,从大量数据中提取更具代表性的模式 ,从而显著提高文字识别的准确率,尤其是在复杂场景下的识别效果。推动文字识别技术向智能化、高效化方向发展,为相关领域的信息处理与利用提供更精准、便捷的技术手段。
主要任务
本课题旨在验证模型在合成数据集训练下的零样本学习能力,特别是对未包含中文字符的识别准确性;同时优化网络在自然场景中的实际性能,解决文字变形、光照不均及复杂背景干扰等问题。
(1)架构设计
采用前后端分离模式,将前端展示逻辑和后端业务逻辑分离,使开发、维护和部署更具灵活性。前端负责与用户交互,后端专注于业务处理和数据管理。并且前端通过 HTTP 请求(如 GET、POST、PUT、DELETE)与后端 API 进行交互。
(2)前端技术
前端基于原生HTML/CSS/JavaScript构建响应式页面。HTML 是构建网页的基础语言,用于定义网页的结构和内容。它使用标签来标识不同类型的内容,如标题、段落、链接、图像等。CSS 用于控制网页的外观和布局。它可以设置颜色、字体、间距、边框等样式,使网页更加美观。JavaScript 是一种编程语言,用于为网页添加交互性和动态效果。它可以响应用户的操作,如点击按钮、提交表单等。
(3)后端技术
利用 Django REST framework(DRF)搭建后端。Django 是一个功能强大的 Python Web 框架,DRF 在其基础上提供了丰富的工具和类,方便快速开发 RESTful API,处理后端的业务逻辑、数据存储和接口提供等任务。
(4)模型技术
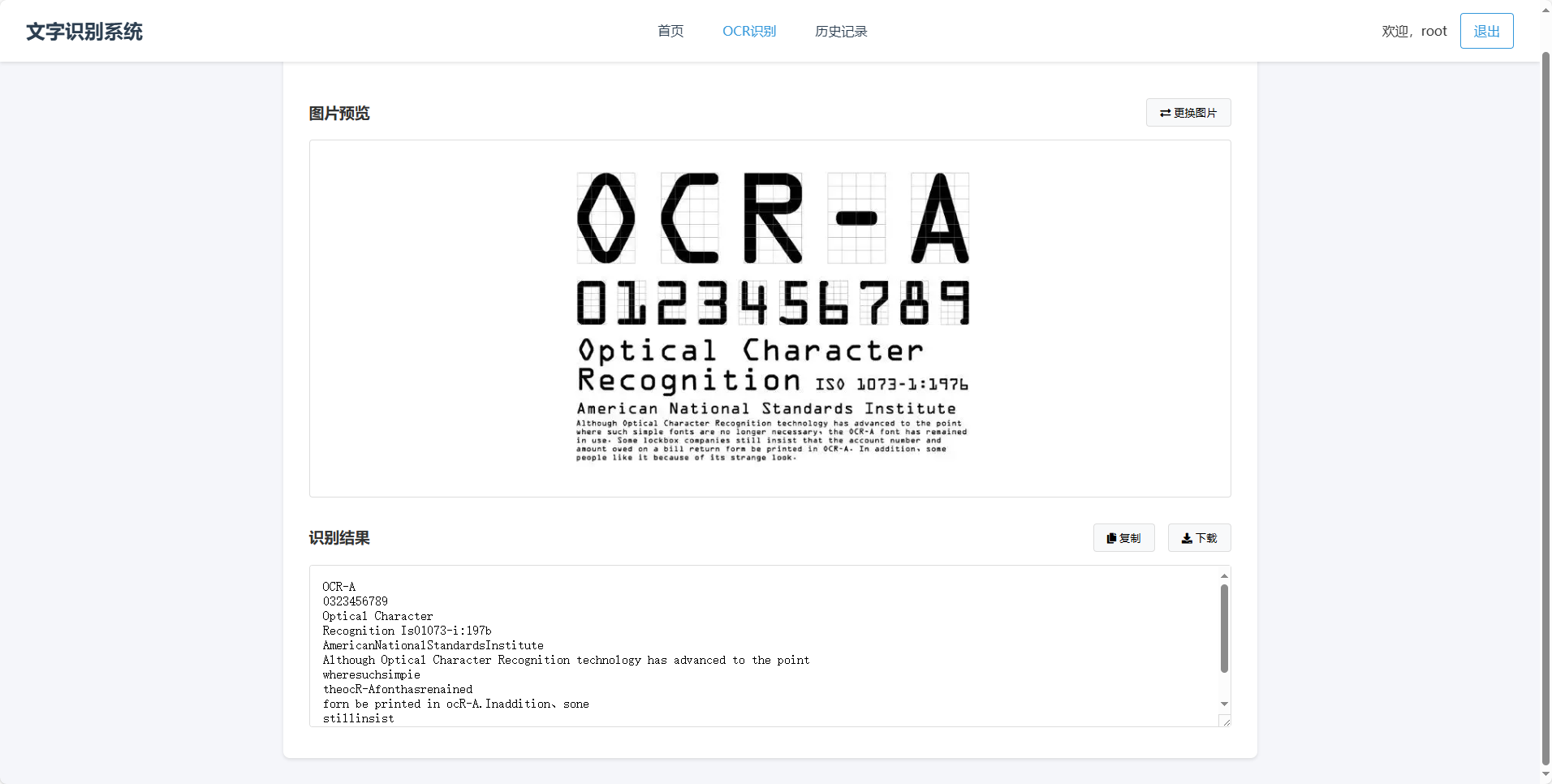
采用 Paddle 框架来构建模型。Paddle-Ocr是百度开源的深度学习平台,提供了丰富的深度学习工具和模型库,支持模型的训练、优化和部署。文字识别模型采用 DBNet(可微分二值化网络)+CRNN(卷积循环神经网络)的组合,DBNet 负责文本检测,CRNN 负责文本识别,两者结合实现高效准确的文字识别功能。
(5)功能实现
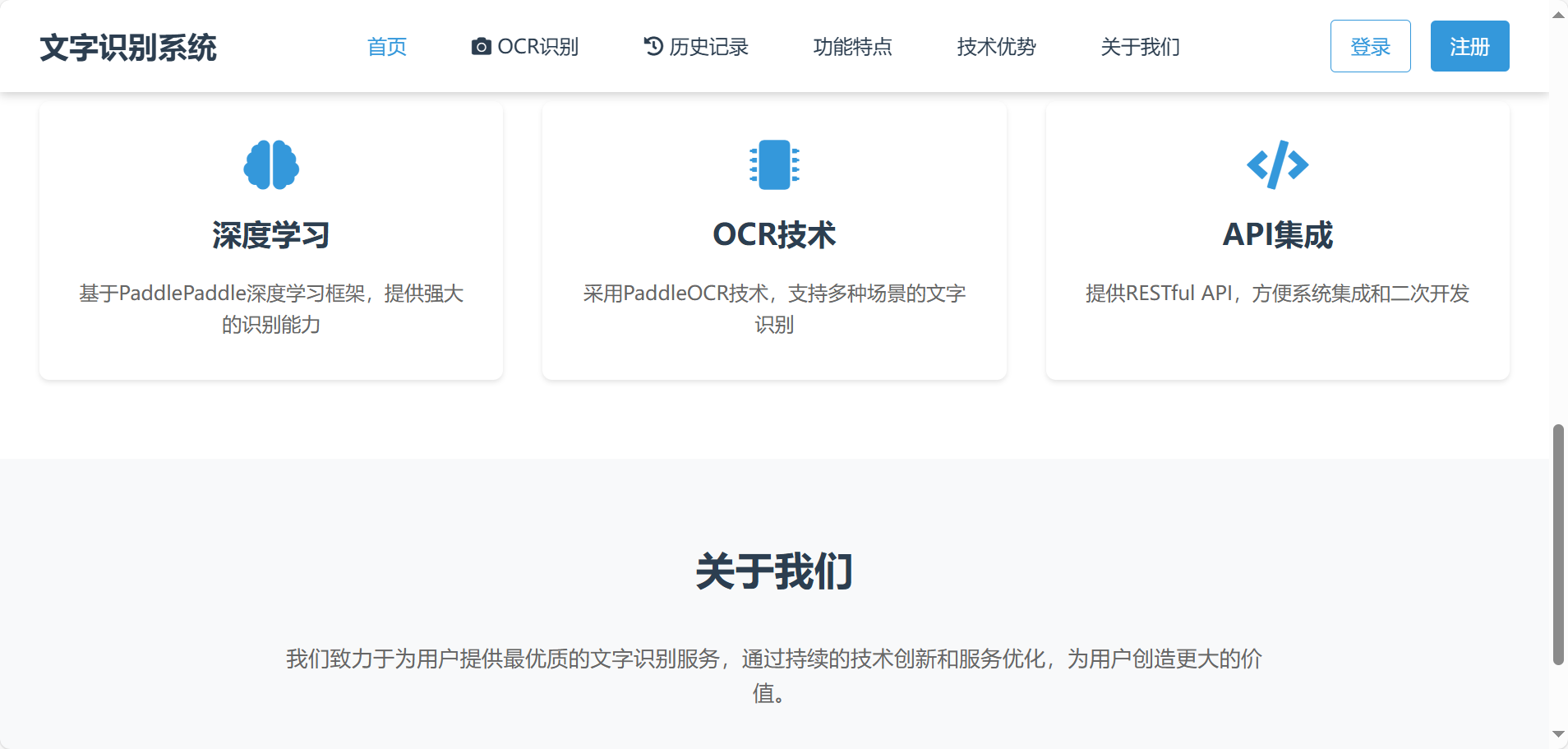
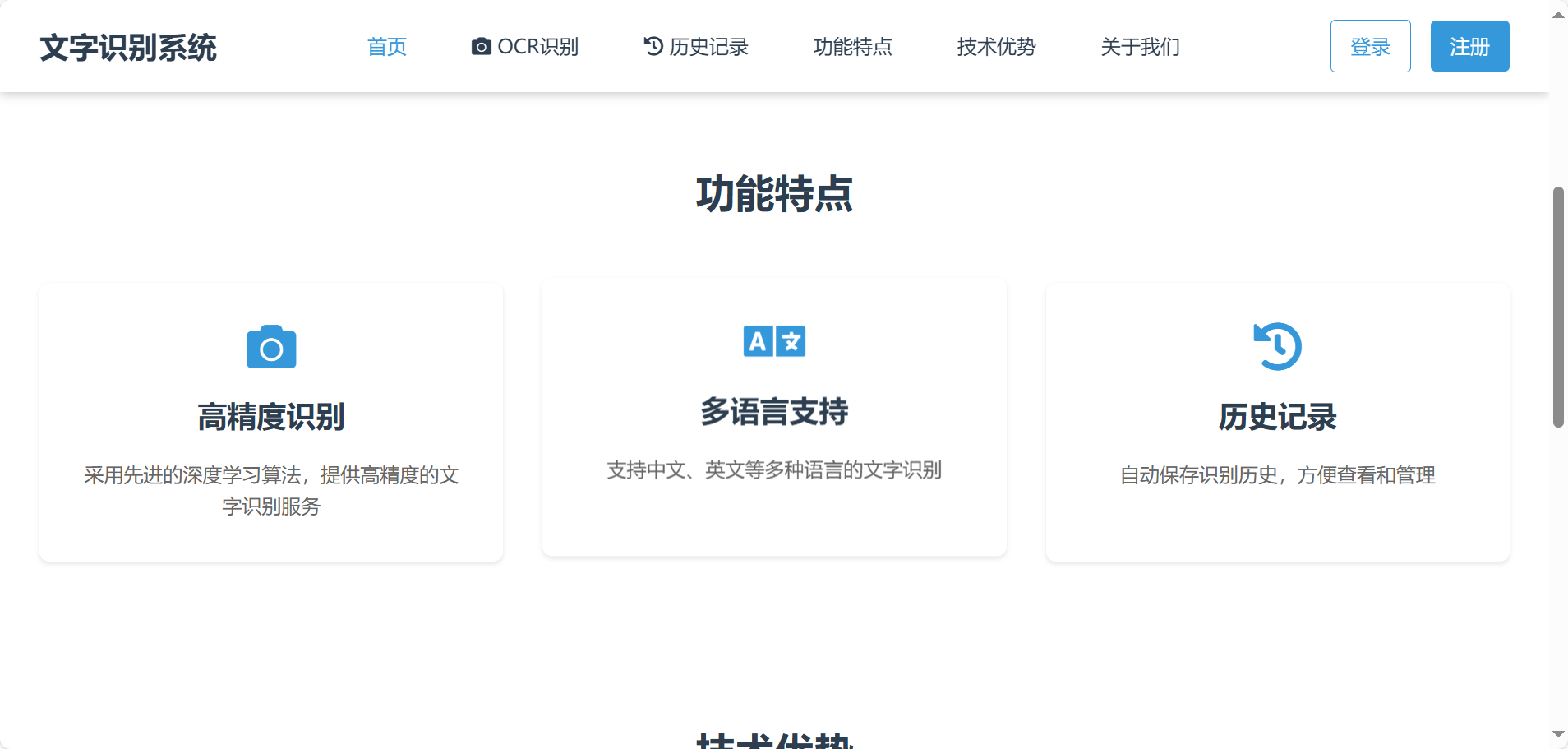
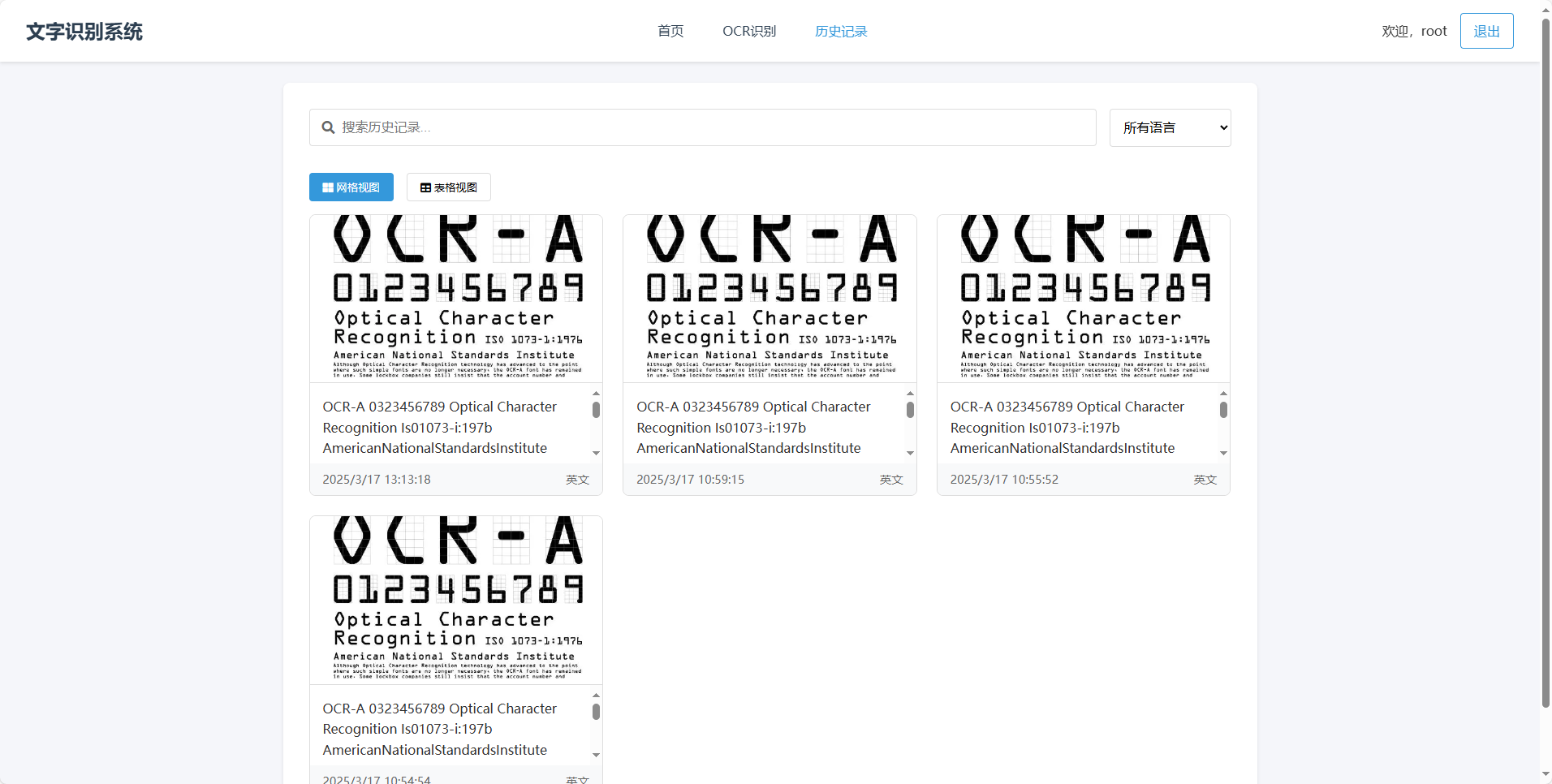
可识别常见的文本内容,识别后可以对识别文本进行复制。支持英语、汉语等多种语言的识别。如车牌识别等特定应用场景的识别功能。包含个人信息页面和历史识别记录页面等,用于用户管理个人信息和查看过往识别记录。
(6)系统对接与稳定性保障
实现前后端正常对接,通过合理的接口设计和数据传输协议,确保前后端数据交互顺畅。同时,系统具备屏蔽错误操作的能力,在用户进行非法或错误操作时进行提示或拦截,保证系统的稳定性和可靠性,并且在使用过程中保证流畅度,减少卡顿和延迟现象。


















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











