






首先进入官方下载官方代码。
https://github.com/ultralytics/ultralytics
终端打开:
code /home/tony/桌面/csdn/ultralytics-main
安装yolov11环境:
pip install ultralytics
下载官方的预训练模型放入代码目录下。
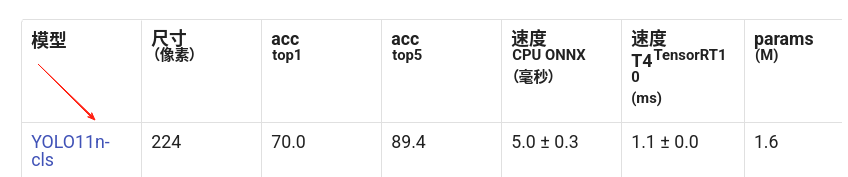
开始制作数据集:
我在百度上查找了10张铅笔,10张钢笔,10张尺子,10张橡皮。其中钢笔和铅笔划分为笔类制作数据集。我们要修改数据集名称:大分类+小分类,比如:bi_gangbi
数据集划分:
import os
import random
import shutil
def split_dataset(source_dir, output_dir, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1):
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 创建训练集、验证集和测试集目录
train_dir = os.path.join(output_dir, 'train')
val_dir = os.path.join(output_dir, 'val')
test_dir = os.path.join(output_dir, 'test')
for dir_path in [train_dir, val_dir, test_dir]:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
# 获取所有类别
classes = os.listdir(source_dir)
for class_name in classes:
class_dir = os.path.join(source_dir, class_name)
if os.path.isdir(class_dir):
# 获取该类别的所有图片文件
image_files = [f for f in os.listdir(class_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
random.shuffle(image_files)
# 计算划分数量
num_images = len(image_files)
num_train = int(num_images * train_ratio)
num_val = int(num_images * val_ratio)
num_test = num_images - num_train - num_val
# 划分图片
train_images = image_files[:num_train]
val_images = image_files[num_train:num_train + num_val]
test_images = image_files[num_train + num_val:]
# 创建类别子目录
train_class_dir = os.path.join(train_dir, class_name)
val_class_dir = os.path.join(val_dir, class_name)
test_class_dir = os.path.join(test_dir, class_name)
for dir_path in [train_class_dir, val_class_dir, test_class_dir]:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
# 移动图片到相应目录
for image in train_images:
src = os.path.join(class_dir, image)
dst = os.path.join(train_class_dir, image)
shutil.copy2(src, dst)
for image in val_images:
src = os.path.join(class_dir, image)
dst = os.path.join(val_class_dir, image)
shutil.copy2(src, dst)
for image in test_images:
src = os.path.join(class_dir, image)
dst = os.path.join(test_class_dir, image)
shutil.copy2(src, dst)
# 源数据集目录,需替换为实际的源目录
source_dataset_dir = 'dataset'
# 输出目录,需替换为实际的输出目录
output_dataset_dir = 'datasets'
split_dataset(source_dataset_dir, output_dataset_dir)
数据集结构为:
datasets
├── train
│ ├── bi_gangbi
│ │ ├── pen1.jpg
│ │ ├── pen2.jpg
│ │ └── ...
│ ├── bi_qianbi
│ │ ├── pencil1.jpg
│ │ ├── pencil2.jpg
│ │ └── ...
│ ├── xiang_pi
│ │ ├── eraser1.jpg
│ │ ├── eraser2.jpg
│ │ └── ...
│ └── ge_chi
│ ├── ruler1.jpg
│ ├── ruler2.jpg
│ └── ...
├── val
│ ├── bi_gangbi
│ │ ├── pen3.jpg
│ │ ├── pen4.jpg
│ │ └── ...
│ ├── bi_qianbi
│ │ ├── pencil3.jpg
│ │ ├── pencil4.jpg
│ │ └── ...
│ ├── xiang_pi
│ │ ├── eraser3.jpg
│ │ ├── eraser4.jpg
│ │ └── ...
│ └── ge_chi
│ ├── ruler3.jpg
│ ├── ruler4.jpg
│ └── ...
├── test
│ ├── bi_gangbi
│ │ ├── pen5.jpg
│ │ ├── pen6.jpg
│ │ └── ...
│ ├── bi_qianbi
│ │ ├── pencil5.jpg
│ │ ├── pencil6.jpg
│ │ └── ...
│ ├── xiang_pi
│ │ ├── eraser5.jpg
│ │ ├── eraser6.jpg
│ │ └── ...
│ └── ge_chi
│ ├── ruler5.jpg
│ ├── ruler6.jpg
│ └── ...
设置配置文件:
修改官方配置文件:ultralytics/cfg/models/11/yolo11-cls.yaml
修改第8行的nc,如果你有一个类就改成1,如果有n个类就改成n
我这边是4类,所以我填的是4
好了,修改完配置文件,我们要开始训练了。
train_cls.py
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
# # Load a model
# model = YOLO("yolo11n-cls.yaml") # build a new model from YAML
# model = YOLO("yolo11n-cls.pt") # load a pretrained model (recommended for training)
model = YOLO("/home/tony/桌面/csdn/ultralytics-main_cls/ultralytics/cfg/models/11/yolo11-cls.yaml").load("yolo11n-cls.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="datasets", epochs=30, imgsz=640)开始训练:
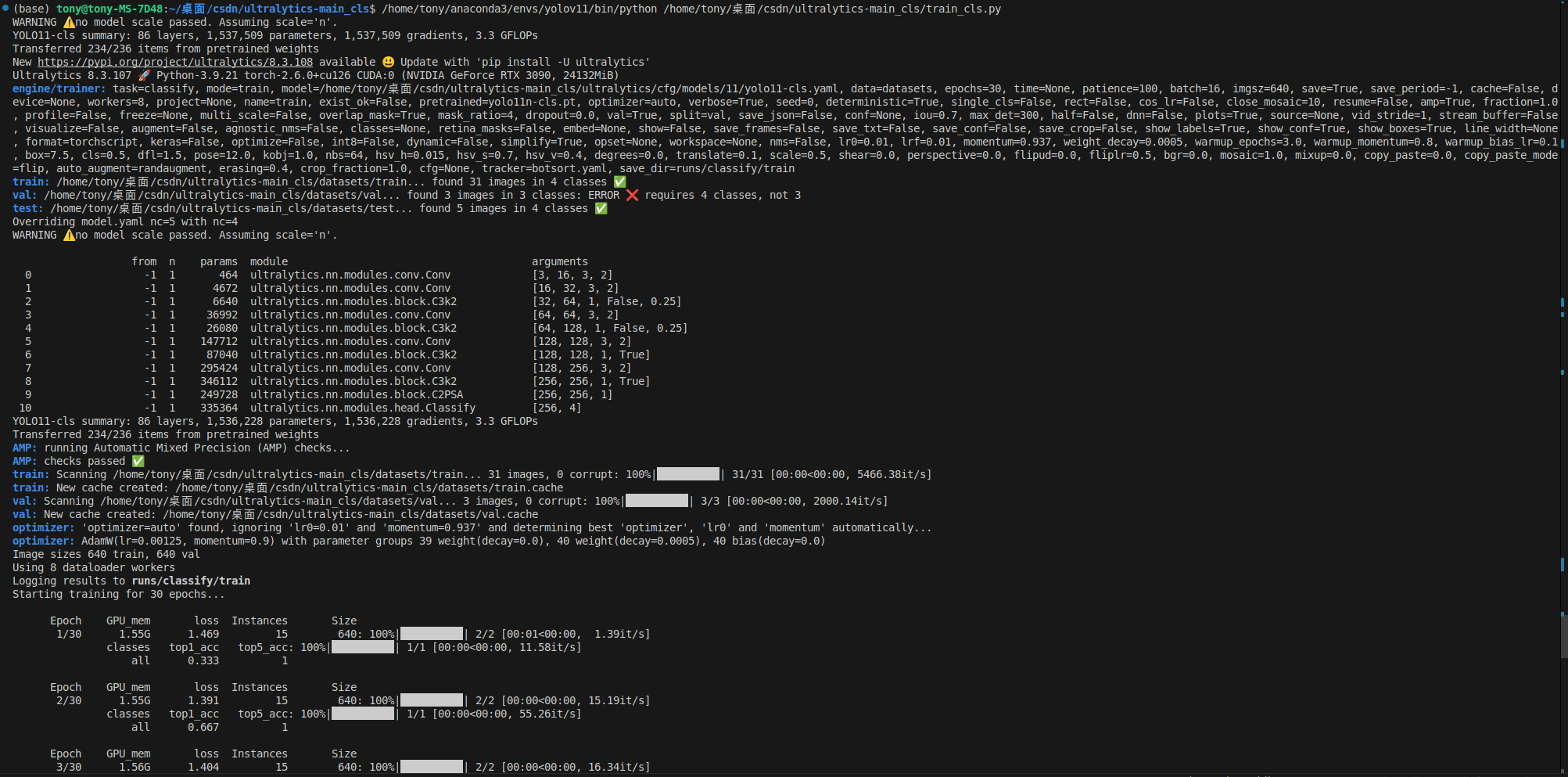
我这里存在一个ERROR,这是因为我的数据集很少,验证集里面其中一个分类没有被分到图片的原因。不必理会。
好了,训练完成之后,会在runs/classify/train/weights/路径中生成best.pt的权重文件。
我们用官方的test_cls.py来调用一下测试。
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.pt") # load an official model
model = YOLO("runs/classify/train/weights/best.pt") # load a custom model
# Predict with the model
results = model("dataset/bi_gangbi/1.jpeg") # predict on an image测试结果很成功,模型基本上识别出来了东西。

现在我们开始细分类。
我们把钢笔和铅笔分为笔类,只需要修改一下测试代码就可以。
test_cls_plus.py
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.pt") # load an official model
model = YOLO("runs/classify/train/weights/best.pt") # load a custom model
# Predict with the model
results = model("dataset/bi_gangbi/1.jpeg") # predict on an image
# Get the most likely class
top_class_index = results[0].probs.top1
class_name = results[0].names[top_class_index]
probability = results[0].probs.data[top_class_index].item()
# Split the class name if it contains an underscore
if '_' in class_name:
parts = class_name.split('_')
attribute1 = parts[0]
attribute2 = parts[1]
print(f" {attribute1}:{attribute2}, Probability: {probability:.2f}")
else:
print(f"Detected Class: {class_name}, Probability: {probability:.2f}")
输出的结果就是:

验证集结果:



















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











