






模版
函数模板
在此之前,我们遇到相同功能但是类型不同的函数可能会很麻烦,即使有了重载,依旧要写很多。祖师爷应该也有这种困扰,所以他整了个模版出来,模版的功能就是可以自动替换类型,只要我们写了一个模版,那么所有类型都能用,只需要写一次就好了。

这就是函数模版的写法,如果咱的参数都是一个类型的,那就只要定义一种就好。之后我们正常调用函数传参,模版就会被触发,他会让编译器去生成这个类型的函数,这个过程叫模版实例化。
需要注意的是,如果我们只写了个一种类型的模版,但是参数传的却是不同类型。
这时候就需要在我们的函数名后面跟一个 <> 这里面提供类型,这样它才能确定你传入的是什么类型,如果类型不匹配它就会强制类型转换而不是报错了。 你也可以在知道类型不匹配的情况下手动的强制类型转换,道理是一样的。
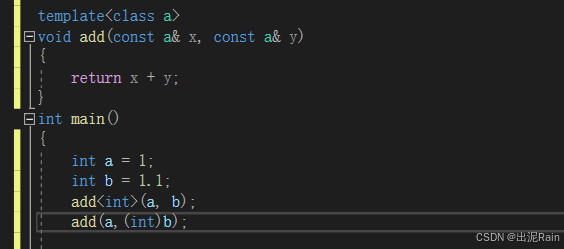
同时,如果说我有一个加法模板,但是我自己又写了加法函数,那么函数执行的时候是优先去使用我写的加法函数的,因为模板是根据你给的类型创建一个函数,而我写的加法函数则是已经存在的,所以它不会舍近求远自己去创建一个新的用。
类模板
既然函数有模板,那么类也有模板。
template<class M>
class stack
{
stack(int n = 4)//构造
: _arr(new M[n])
,_size(0)
,_cap(n)
{
}
~stack()//析构
{
delete[] _arr;
_arr = nullptr;
_cap = _size = 0;
}
void push(const M& a)//用模版完成任意类型插入
{
if (_size == _cap)
{
M* tmp = new M[_cap * 2];
memcpy(tmp, _arry, sizeof(M) * _size);
delete[] _arr;
_arr = tmp;
_cap *= 2;
}
_arr[_size++] = a;
}
private:
M* _arr;
size_t size;
size_t cap;
};
template <class M>//上面的仅限于类里面用,所以我们需要再声明一次
int main()
{
stack<int> x1;
stack<double> x2;
return 0;
}这样我们就不需要因为类型不同而去重新写一个类了,只要我们指定一下类型就可以了。
STL
全名为标准模版库,今天先讲string,实际上string并不属于STL而是属于C++标准库。但是就功能来说,把它们划分到一块是没问题的。
在某些情况下,数据可能不得不使用字符串的形式存储,那么单独划分一个管理字符串的类型出来是很有必要的。我们可以把string看成一个管理字符串的类。
使用它需要包一个string的头文件,注意没有.h,这是为了和C语言的区分开。
而string就像是一个集合了很多常用方法的集合。我们来看看它大概是怎么实现出来的。
string(const char* str = "")//假如我们传字符串
{
_size = strlen(str);//size就会根据我们传入的数据开空间
_cap = _size;//我想cap=size是为了节省空间 以后要用再开
_str = new char[_cap + 1];//字符串需要多给一个\0的空间 所以+1
strcpy(_str, str);//然后把数据拷贝一下就好了
}当然我们既然使用了类,就需要考虑深拷贝的问题,所以还有一种方法。
string(const string& s)//我们用一个string类型初始化另一个string类型
{
_str = new char[s._cap + 1];//先开一个一样大的空间
strcpy(_str, s._str);//再拷贝数据
_size = s._size;//照搬size
_cap = s._cap;//照搬cap
}
string& operator=(const string& s)//通过等于来深拷贝
{
if (this != &s)//如果自己=自己 那下面销毁完就变随机值了 所以先判断!=自己
{
delete[] _str;//销毁空间
_str = new char[s._cap + 1];//开空间 顺便改变指向
strcpy(_str, s._str);//拷贝数据
_size = s._size;
_cap = s._cap;
}
return *this;
}当然必不可少的析构也有
~string()
{
delete[] _str;
_str = nullptr;
_cap = _size = 0;
}String主要功能实现
首先空间如果不够,我们需要扩容。
void string::reserve(size_t n)//扩容
{
if (n > _cap)//这个判断是很有必要的,因为我主动调用它,那么它不能无脑的开
{
//正常开空间逻辑
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_cap = n;
}
}尾插
void string::push_back(char ch)//string没有明确的提供头插 因为头插涉及移动数据效率不高
{
//判断是否需要扩容
if (_size == _cap)
{
reserve(_cap == 0 ? 4 : _cap * 2);
}
//直接在size位置插入字符即可
_str[_size] = ch;
++_size;//基本操作
//因为size位置被更改了 所以\0需要我们手动的加上 同时因为我们开cap+1的空间 所以这里不必再扩容
_str[_size] = '\0';
}+=
string& string::operator+=(char ch)
{
//因为上面实现了尾插 所以+=可以直接复用 爽
push_back(ch);
return *this;
}
string& string::operator+=(const char* str)//少不了const版本的
{
append(str);
return *this;
}append追加
void string::append(const char* str)//尾插是插字符 那追加就追加字符串吧
{
//首先就得判断 我追加的大小 会不会大于我的cap 大于的话就扩容呗
size_t len = strlen(str);
if (_size + len > _cap)
{
reserve(_size + len > 2 * _cap ? _size + len : 2 * _cap);
}
//简简单单的从str+size取到最后一位 然后cpy进内容即可
strcpy(_str + _size, str);
//长度也得+
_size += len;
}insert插入
void string::insert(size_t pos, char ch)//插入字符
{
//断言和判断扩容
assert(pos <= _size);
if (_size == _cap)
{
reserve(_cap == 0 ? 4 : _cap * 2);
}
//先移动数据
size_t end = _size+1;
while (end > pos)
{
_str[end] = _str[end-1];
--end;
}
//然后在指定位置插入字符即可 长度也得++
_str[pos] = ch;
_size++;
}
void string::insert(size_t pos, const char* str)//插入字符串
{
//断言和判断扩容
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _cap)
{
reserve(_size + len > 2 * _cap ? _size + len : 2 * _cap);
}
//先看看插入字符串的尾在哪
size_t end = _size + len;
//循环移动数据 这里需要注意区间 因为pos+len也要移 所以-1或者>=都可以
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
//for循环把要插入的数据填进去即可
for (size_t i = 0; i < len; i++)
{
_str[pos + i] = str[i];
}
//长度++
_size += len;
}erase删除
void string::erase(size_t pos, size_t len)//删除
{
//老规矩先判断
assert(pos < _size);
//考虑两种情况 第一种在指定后的位置删的数据小于len 那就简单了 直接pos位置改成\0 size = pos即可
if (len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
//另一种情况就是够删 那就要移动数据
else
{
for (size_t i = pos + len; i <= _size; i++)
{
_str[i - len] = _str[i];
}
//size-len即可
_size -= len;
}
}find找数据
//这个也分为找字符和字符串
size_t string::find(char ch, size_t pos)
{
//字符就简单了 直接断言完for循环找就好了 找到了返回下标 找不到返回npos
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
size_t string::find(char* str, size_t pos)
{
assert(pos < _size);
//字符有点麻烦 需要用strstr先比较 然后判断一下即可
const char* ptr =strstr(_str + pos, str);
if (ptr == nullptr)
{
return npos;
}
else
{
//ptr-str就可以得到下标 (指针-指针得到下标)
return ptr - _str;
}
}substr
string string::substr(size_t pos, size_t len)
{
assert(pos < _size);
if (len > _size - pos)
{
len = _size - pos;
}
//这其实也算找数据 不过它是以全新的身份返回
string sub;//所以我们要创建一个新的变量
sub.reserve(len);//为了出作用域不销毁 所以我们开一下空间
for (size_t i = 0; i < len; i++)
{
sub += _str[pos + i];//导数据即可
}
//返回sub即可
return sub;
}运算符重载
// 这一块就是无尽的复用 我就不多bb了
bool operator<(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) < 0;
}
bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2;
}
bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator>=(const string& s1, const string& s2)
{
return !(s1 < s2);
}
bool operator==(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}istream 和 ostream
ostream& operator<<(ostream& out,const string& s)//这还好 只要给进去就完了
{
//一个范围for搞定
for (auto a : s)
{
out << a;
}
return out;
}
//这就有点麻烦
istream& operator>>(istream& in, string& s)
{
//clear是为了清理上一次输入的残留
s.clear();
//给多少都行 不一定要256
const int n = 256;
//我们如果要输入超级长一段数据 那不如用数组来存
char X[n];
int i = 0;
char ch;
ch = in.get();
while (ch != ' ' && ch != '\n')
{
//从头开始往数组存 满了咱就从头开始
X[i++] = ch;
//如果某一轮满了 就+=然后i置成1重新开始
if (i == n-1)
{
X[i] = '\0';
s += X;
i = 0;
}
ch = in.get();
}
//如果没满就结束 那咱就直接+=
if (i > 0)
{
X[i] = '\0';
s += X;
}
return in;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









