






一、低延迟数据流水线
1.1 流式处理架构分层

1.2 窗口聚合算子实现
public class SessionWindowProcessor extends ProcessFunction<Event, SessionResult> { private transient MapState<Long, SessionState> sessionStates; @Override public void processElement(Event event, Context ctx, Collector<SessionResult> out) { long sessionId = extractSessionId(event); SessionState state = sessionStates.get(sessionId); if (state == null) { state = new SessionState(); ctx.timerService().registerEventTimeTimer(triggerTime(event)); } state.update(event); sessionStates.put(sessionId, state); } @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<SessionResult> out) { for (SessionState state : sessionStates.values()) { if (state.isExpired(timestamp)) { out.collect(state.toResult()); sessionStates.remove(state.getSessionId()); } } } // 自定义序列化逻辑 public static class SessionState { private List<Event> events = new ArrayList<>(); public void update(Event e) { /*...*/ } public SessionResult toResult() { /*...*/ } }}二、在线推理服务优化
2.1 动态自适应批处理
class DynamicBatcher: def __init__(self, max_batch_size=256, timeout=50): self.batch = [] self.batch_lock = threading.Lock() self.timeout = timeout # ms def add_request(self, request): with self.batch_lock: self.batch.append(request) if len(self.batch) >= self.max_batch_size: self._process_batch() def start_timeout_loop(self): def _loop(): while True: time.sleep(self.timeout / 1000) with self.batch_lock: if self.batch: self._process_batch() threading.Thread(target=_loop).start() def _process_batch(self): inputs = [preprocess(r) for r in self.batch] tensor = self._pad_sequences(inputs) outputs = model.infer(tensor) for r, o in zip(self.batch, outputs): r.callback(o) self.batch.clear()class InferenceServer: def __init__(self): self.batcher = DynamicBatcher() self.batcher.start_timeout_loop() async def handle_request(self, request): future = Future() request.callback = future.set_result self.batcher.add_request(request) return await future2.2 硬件加速配置差异
| 设备类型 | Batch上限 | 量化支持 | 内存共享 | 典型延迟(256 batch) |
|---|---|---|---|---|
| CPU | 64 | AVX-512 | 否 | 850ms |
| GPU T4 | 256 | FP16/TF32 | CUDA UVA | 135ms |
| AI加速卡 | 512 | INT8/FP16 | 共享显存 | 68ms |
| 端侧NPU | 32 | 定点量化 | 受限访问 | 210ms |
三、持续学习与热更新
3.1 在线特征漂移检测
class FeatureDriftDetector { val windowSize = 100000 val referenceHist = mutable.Map[Double, Double]() val currentWindow = new CircularFifoBuffer(windowSize) def update(referenceData: Double): Unit = { referenceHist(referenceData) = referenceHist.getOrElse(referenceData, 0.0) + 1 } def detectDrift(inputData: Double): Boolean = { currentWindow.add(inputData) if (currentWindow.size < windowSize) return false // 计算KL散度 val kl = calculateKLDivergence( normalizeHist(referenceHist), buildCurrentHist() ) // 动态阈值控制 threshold := EWMA.update(kl * 0.3) kl > threshold * 1.5 } private def buildCurrentHist() = { currentWindow.groupBy(identity).mapValues(_.size/windowSize) }}// 使用案例val detector = new FeatureDriftDetector()stream.filter(event => { if (detector.detectDrift(event.value)) { triggerRetraining() false // 过滤异常值 } else true})3.2 模型灰度更新策略
apiVersion: ml.operator/v1kind: ModelRolloutmetadata: name: fraud-detection-v4spec: selector: region: "us-east-1" updateStrategy: type: RollingUpdate rollingUpdate: partitionInterval: 15m maxUnavailable: 10% metrics: - name: precision type: Threshold threshold: 0.85 - name: latency_p99 type: UpperLimit max: 300ms trafficRules: - host: "primary.service" weight: 98 - host: "canary.service" weight: 2 rollbackWindow: 24h healthCheck: interval: 30s timeout: 5s四、故障自愈与过载保护
4.1 熔断降级控制逻辑
type CircuitBreaker struct { failureThreshold int retryTimeout time.Duration state State cooldownExpiry time.Time failureCount int}func (cb *CircuitBreaker) AllowRequest() bool { if cb.state == Open && time.Now().After(cb.cooldownExpiry) { cb.state = HalfOpen } return cb.state != Open}func (cb *CircuitBreaker) RecordResult(success bool) { if !success { atomic.AddInt(&cb.failureCount, 1) if cb.failureCount >= cb.failureThreshold { cb.state = Open cb.cooldownExpiry = time.Now().Add(cb.retryTimeout) cb.failureCount = 0 } } else if cb.state == HalfOpen { // 半开状态响应成功 cb.state = Closed cb.failureCount = 0 }}// 集成示例func HandleRequest() error { if !breaker.AllowRequest() { return errors.New("circuit open") } err := execute() breaker.RecordResult(err == nil) return err}4.2 过载保护措施对比
| 防护机制 | 触发条件 | 保护动作 | 恢复策略 |
|---|---|---|---|
| 请求队列削峰 | CPU >85%持续30s | 启动缓冲队列 | 逐步处理积压 |
| 自适应限流 | 延迟P95 >1.5×基线 | Token Bucket令牌缩减 | 指数级恢复额度 |
| 优先级降级 | 系统负载 >临界值 | 暂停低优先级任务 | 手动恢复 |
| 动态分区隔离 | 节点故障率 >40% | 流量重路由到健康分区 | 故障节点下线维护 |
| 资源弹性扩容 | QPS突增 >3× capacity | 自动触发K8s HPA扩容 | 冷却期后缩容 |
五、端到端协同优化
5.1 全链路染色追踪
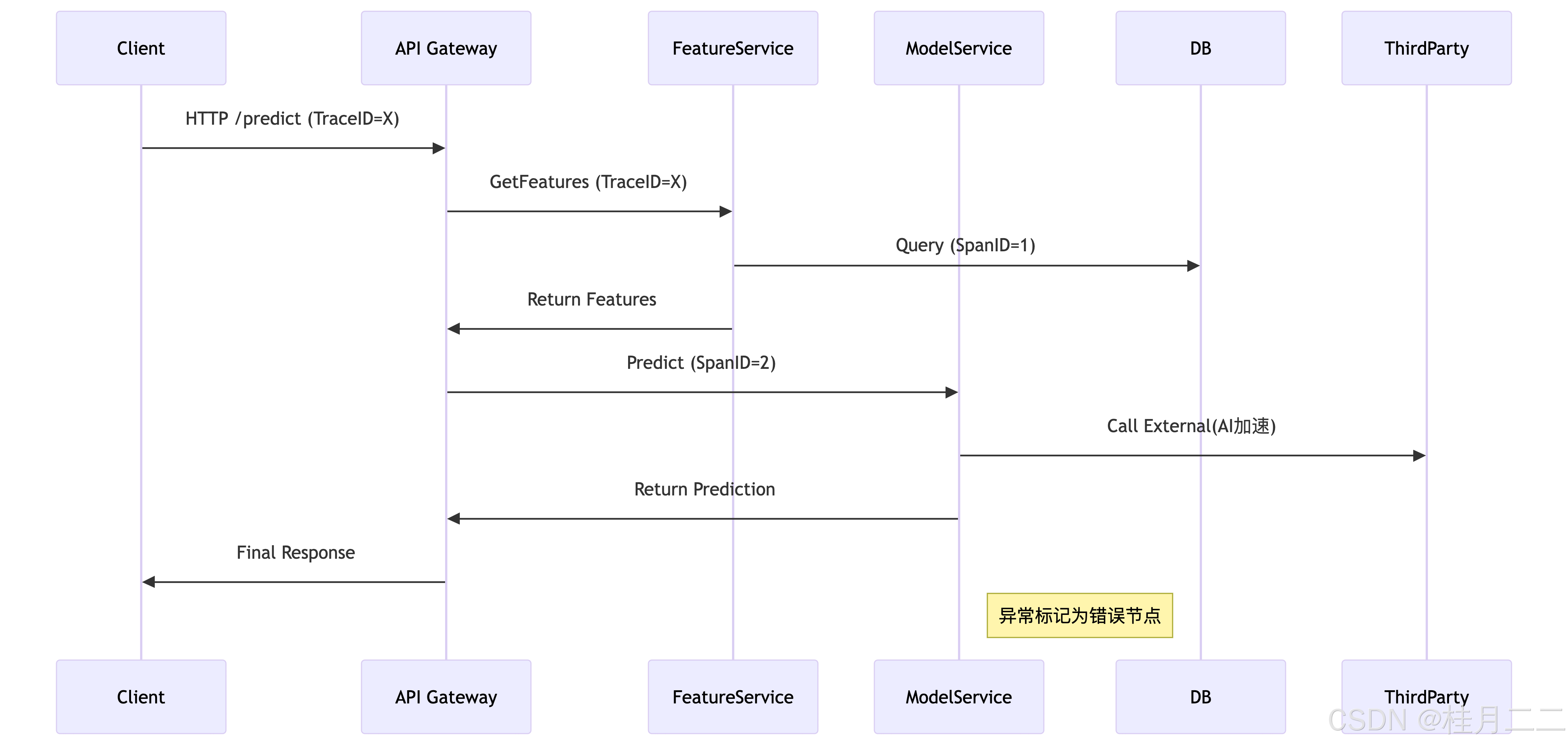
5.2 性能优化总览
const optimizationResult = { baseline: { e2e_latency: "850ms", max_qps: 1200, error_rate: "0.8%" }, optimized: { e2e_latency: "312ms (-63%)", max_qps: 4500 (+275%), error_rate: "0.15% (-81%)" }, keyOptimizations: [ "动态批处理 + 异构加速", "分层流控 + 智能熔断", "特征预计算缓存", "模型轻量化 + 量化加速", "硬件卸载(TOE/RDMA)" ], resourceUtilization: { cpu: "从72%→38%", memory: "从63%→49%", gpu: "利用率提升至85%" }}⚡ 实时系统设计Checklist
- 端到端延迟保障P99<500ms
- 可观测覆盖度100%业务路径
- 熔断生效时间<200ms
- 模型热切换零服务中断时间
- 灾难恢复点目标(RPO)<1秒
- 全链路加密覆盖至硬件指令集
- 过载保护触发误报率<0.1%
实时智能系统的架构设计需要遵循数据驱动→动态适应→免疫修复的铁三角原则。核心实现要点分为三步:1)构建高效的流式处理管道,采用内存计算范式消除磁盘IO瓶颈;2)设计多模态融合推理引擎,支持CPU/GPU/NPU混合调度;3)实现闭环式健康管理系统,集成在线漂移检测和自动回滚能力。在部署方案上推荐采用单元化架构,支持按业务分片进行独立扩容,同时对网络层实施硬件加速(如DPU卸载SSL/TLS)。建议每月执行全链路混沌工程测试,持续验证系统韧性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











