







目录
1、文本嵌入层的作用
- 无论是源文本嵌入层还是目标文本嵌入,都是为了将文本词汇中的数字表示转变为向量表示,希望在这样的高维空间中捕捉词汇之间的关系
2、代码演示
Embedding(10,3)中的第一个参数10代表的是词表的大小,即词表中不同单词的数量
词表中有10个不同的单词,每个单词都被映射成一个长度为3的向量
embedding = nn.Embedding(10,3)
print(embedding)
input = torch.LongTensor([[1,2,3,4],[4,3,2,9]])
embedding(input)
3、构建Embeddings类来实现文本嵌入层
# 构建Embedding类来实现文本嵌入层
class Embeddings(nn.Module):
def __init__(self,vocab,d_model):
"""
:param vocab: 词表的大小
:param d_model: 词嵌入的维度
"""
super(Embeddings,self).__init__()
self.lut = nn.Embedding(vocab,d_model)
self.d_model = d_model
def forward(self,x):
"""
:param x: 因为Embedding层是首层,所以代表输入给模型的文本通过词汇映射后的张量
:return:
"""
return self.lut(x) * math.sqrt(self.d_model)x = Variable(torch.LongTensor([[100,2,42,508],[491,998,1,221]]))
emb = Embeddings(1000,512)
embr = emb(x)
print(embr.shape)
print(embr)
print(embr[0][0].shape)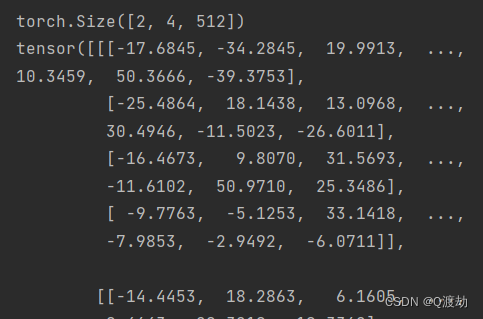
在代码 emb = Embeddings(1000,512) 中,1000是词表的大小,即词表中不同单词的数量。在这个例子中,词表中有1000个不同的单词,每个单词都被映射成一个长度为512的向量。在实际应用中,词表的大小可能会更大或更小,具体大小取决于使用场景和任务需求
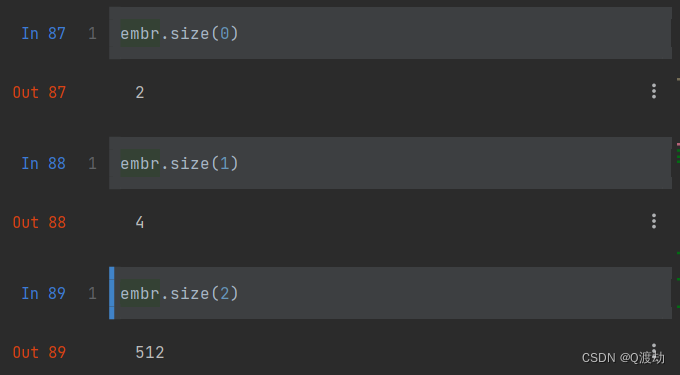
embr.shape为torch.Size([2, 4, 512]),代表有2个句子,每个句子有4个单词,每个单词的embedding维度为512




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











