
爬虫学习
 关注
关注
 分享
分享
文章平均质量分 89
千里桦林
企图用坚持更新博客的方式来进行学习打卡
展开
-
爬虫学习笔记 Day 6 + 记录遇到的小问题
目录一、配置对象二、反爬基于身份识别的反爬基于数据加密进行反爬基于数据加密进行反爬三、验证码图像识别引擎四、遇到的问题一、配置对象(续上昨天的笔记)from selenium import webdriverurl = 'http://www.baidu.com/'#创建配置对象opt = webdriver.ChromeOptions()#添加配置参数# opt.add_argument('--headless')# opt.add_argument('--disable-gpu'原创 2022-01-26 09:25:59 · 210 阅读 · 0 评论 -
爬虫入门学习笔记 Day 5 + 记录遇到的小问题
目录一、标签对象提取文本内容和属性值二、标签切换三、窗口切换四、cookies操作五、执行js代码六、页面等待1.强制分类2.隐式分类(推荐使用)3.显示分类(了解)4.案例:(淘宝翻页)七、配置对象开启无界面模式遇到的小问题1.selenium元素定位方式语法改变了2.配置对象时chrome_options参数报错一、标签对象提取文本内容和属性值1.获取文本:element_text2.获取属性值:element.get_attribute(“属性名”)代码:(在day 4学习的基础上改写for循原创 2022-01-18 00:05:37 · 530 阅读 · 0 评论 -
爬虫入门学习笔记 Day 4
目录一、lxml模块中的etree.tostring函数的使用二、selenium自动化测试框架1.selenium简介(1)工作原理(2)安装selenium以及chromedriver(3)账务标签对象click点击以及send_key输入2.selenium提取数据(1)driver对象的常用属性和方法(2)示例代码示例代码1:如何使用page_source、current_url、title示例代码2:如何使用forward()、back()示例代码3:如何截图(3)元素定位三、补充知识点一、lx原创 2022-01-15 22:47:57 · 1166 阅读 · 0 评论 -
爬虫入门学习笔记 Day 3 + 记录遇到的小问题
文章目录一、常用数据解析方法二、jsonpath简单知识点三、jsonpath的网络联系四、lxml简介1.lxml模块和xpath语法五、谷歌浏览器xpath helper插件1.xpath安装和使用2.xpath语法(1)基础节点选择(2)节点修饰语法(3)选取未知节点的语法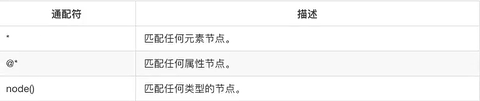六、lmxl使用七、案例:百度贴吧遇到的小问题1.xpath通过子节点的值修原创 2022-01-14 00:25:18 · 634 阅读 · 0 评论 -
爬虫入门学习笔记 Day 2 + 记录遇到的小问题
目录一、requests模块发送post请求二、post数据来源三、request模块——session(利用session进行状态保持)1.session的作用及应用场景2.session使用方法四、数据提取——响应内容的分类五、xml和html1. xml2. html六、遇到的问题/tips一、requests模块发送post请求1.实现方法:requests.post(url, data) data是一个字典2.使用金山词霸网页作为例子。输入“字典”二字,会翻译出dictionary原创 2022-01-11 23:45:04 · 330 阅读 · 0 评论 -
爬虫入门学习笔记 Day 1+ 记录遇到的小问题
安装好pycharm,开始学习。目录一、学习requests模块1.安装requests2.requests模块的简单使用3.requests发送请求的例子二、学习response响应对象1.text和content的区别2.其他属性或方法三、发送带header的请求头dubug :User-Agent四、发送带参数的请求方法一:url中直接带参数方法二:使用params参数五、在headers中设置cookies参数六、使用Cookies保持会话七、CookieJar的对象与Cookie字典的互换八、超原创 2022-01-08 21:58:39 · 821 阅读 · 0 评论