







Abstract
参考图像分割是一项基本的视觉语言任务,旨在从图像中分割出由自然语言表达所引用的对象。 这项任务背后的关键挑战之一是利用引用表达式来突出显示图像中的相关位置。解决这个问题的一个范例是利用一个强大的视觉语言(“跨模态”)解码器来融合从视觉编码器和语言编码器中独立提取的特征。 最近的方法通过利用Transformer作为跨模态解码器在这个范例中取得了显著的进步,同时Transformer在许多其他视觉语言任务中取得了压倒性的成功。在这项工作中,我们采用了一种不同的方法,表明可以通过在视觉变压器编码器网络的中间层中早期融合语言和视觉特征来实现更好的跨模态对齐。 通过在视觉特征编码阶段进行跨模态特征融合,我们可以利用Transformer编码器的相关建模能力来挖掘有用的多模态上下文。 这样,准确的分割结果很容易收获与轻量级掩模预测器。 我们的方法在RefCOCO、RefCOCO+和G-Refby上超越了以前最先进的方法。
Introduction
给定目标物体的图像和文本描述,参考图像分割旨在预测描绘该物体的pixel-wise mask。一种被广泛采用的模式是首先从不同的encoder网络中独立提取视觉和语言特征,然后用跨模态decoder将它们融合在一起进行预测。融合策略包括反复互动、跨模态注意、多模态图推理、语言结构引导的语境结构建模等。
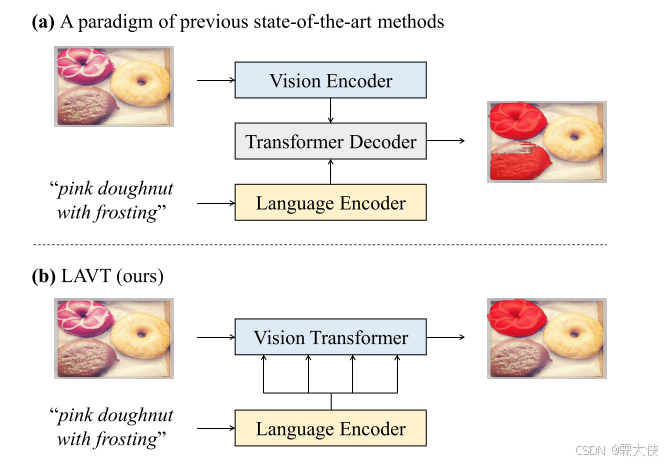
LAVT:接将语言信息整合到视觉Transformer网络的中间层次的视觉特征中,在那里有益的视觉语言线索被共同利用。
传统的方法:跨模态的交互仅在特征编码后进
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









