







 该专栏为热销专栏榜 第81名
该专栏为热销专栏榜 第81名名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(优快云)(一个喜欢古诗词和编程的Coder😊)
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第94天:走近自动化训练平台
欢迎回到Python星球🪐日记!今天是我们旅程的第95天。
在我们的人工智能学习旅程中,随着模型复杂度的增加和数据规模的扩大,单台机器的计算能力常常捉襟见肘。今天,我们将探索分布式训练与推理技术,这是解决大规模AI模型训练和部署挑战的关键方法。通过合理利用多台机器的计算资源,我们可以大幅提升训练速度和推理效率,让AI模型的开发与应用更加高效。
一、分布式训练基础
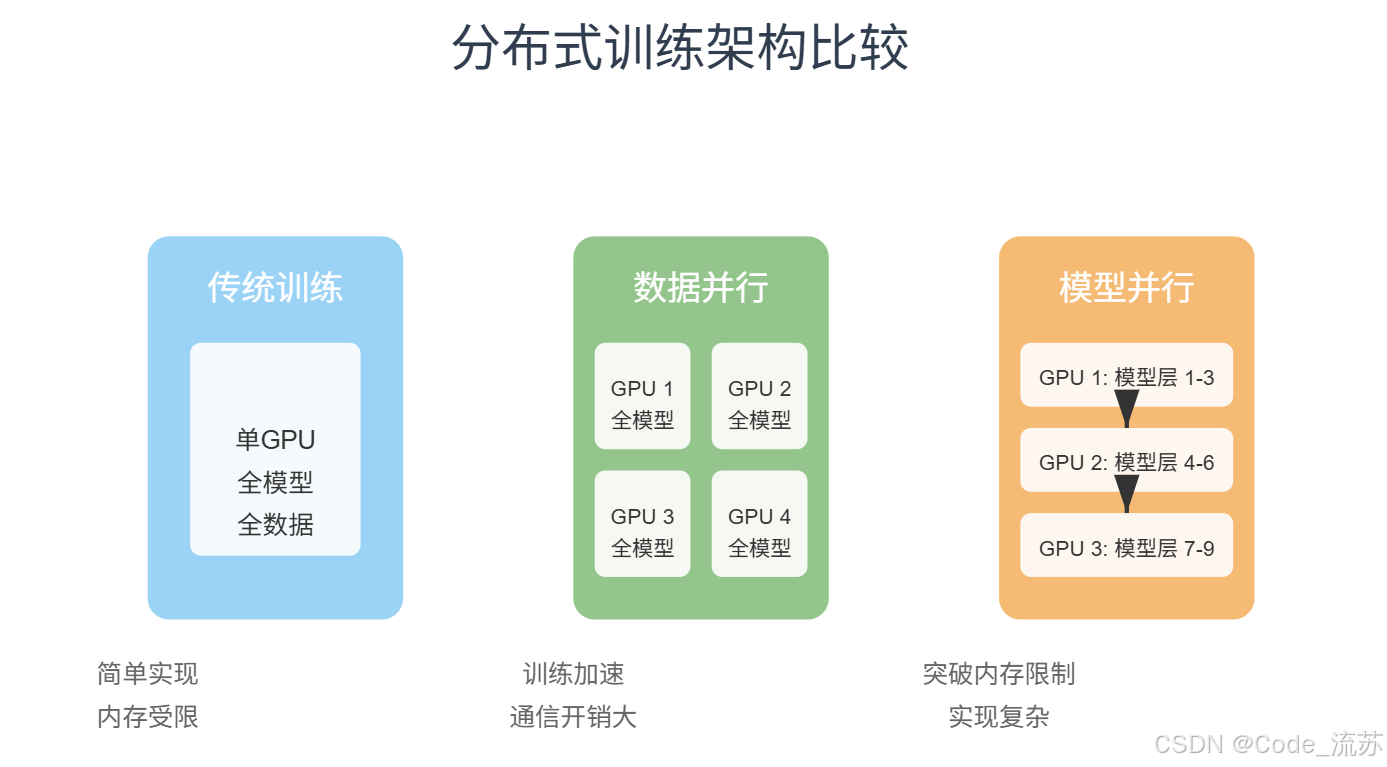
分布式训练是指利用多台计算机(或多个GPU)共同完成模型训练的过程。它能够有效解决两个关键问题:训练速度慢和内存不足。
1. 数据并行与模型并行
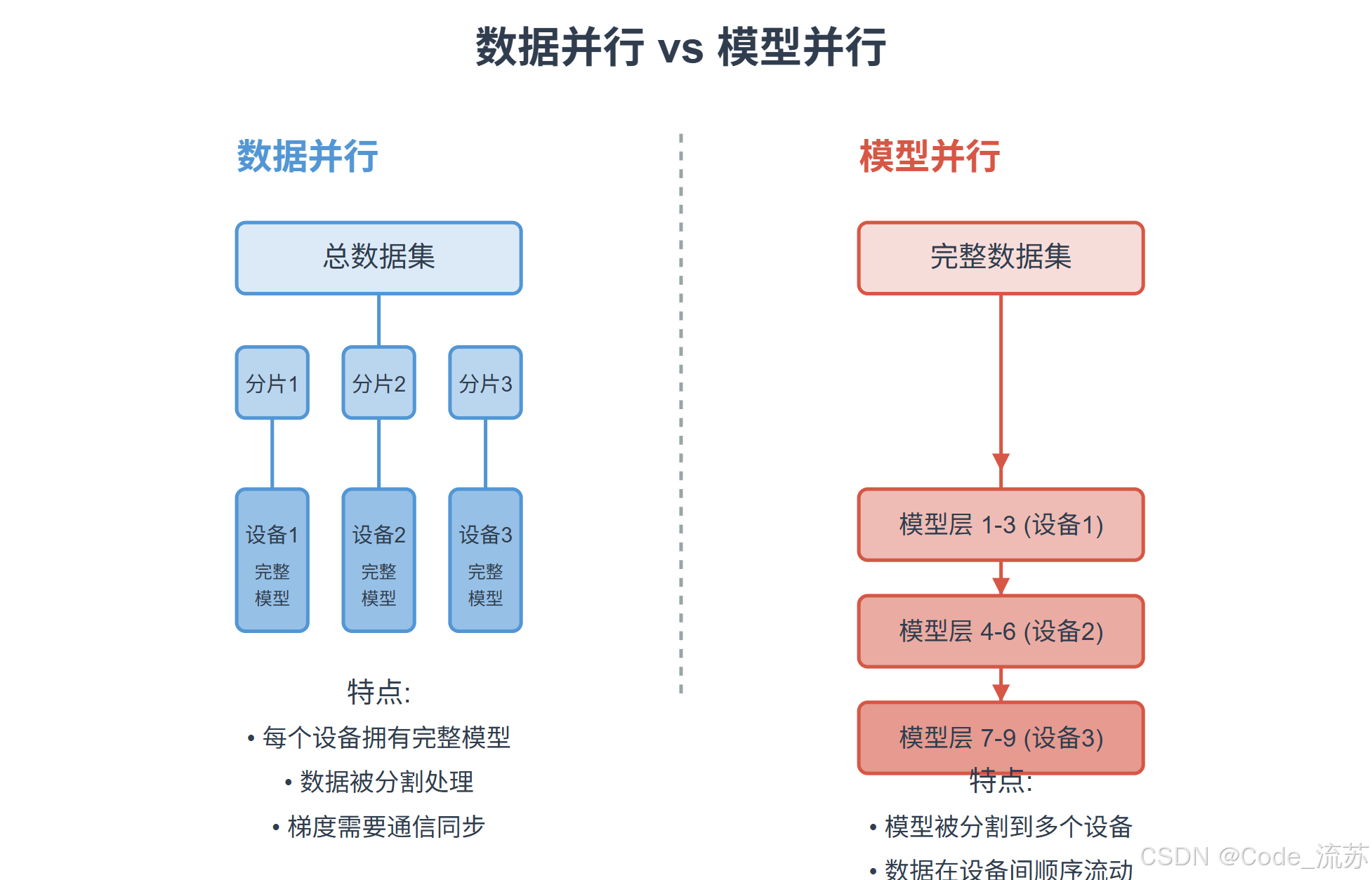
分布式训练主要有两种基本策略:数据并行和模型并行。
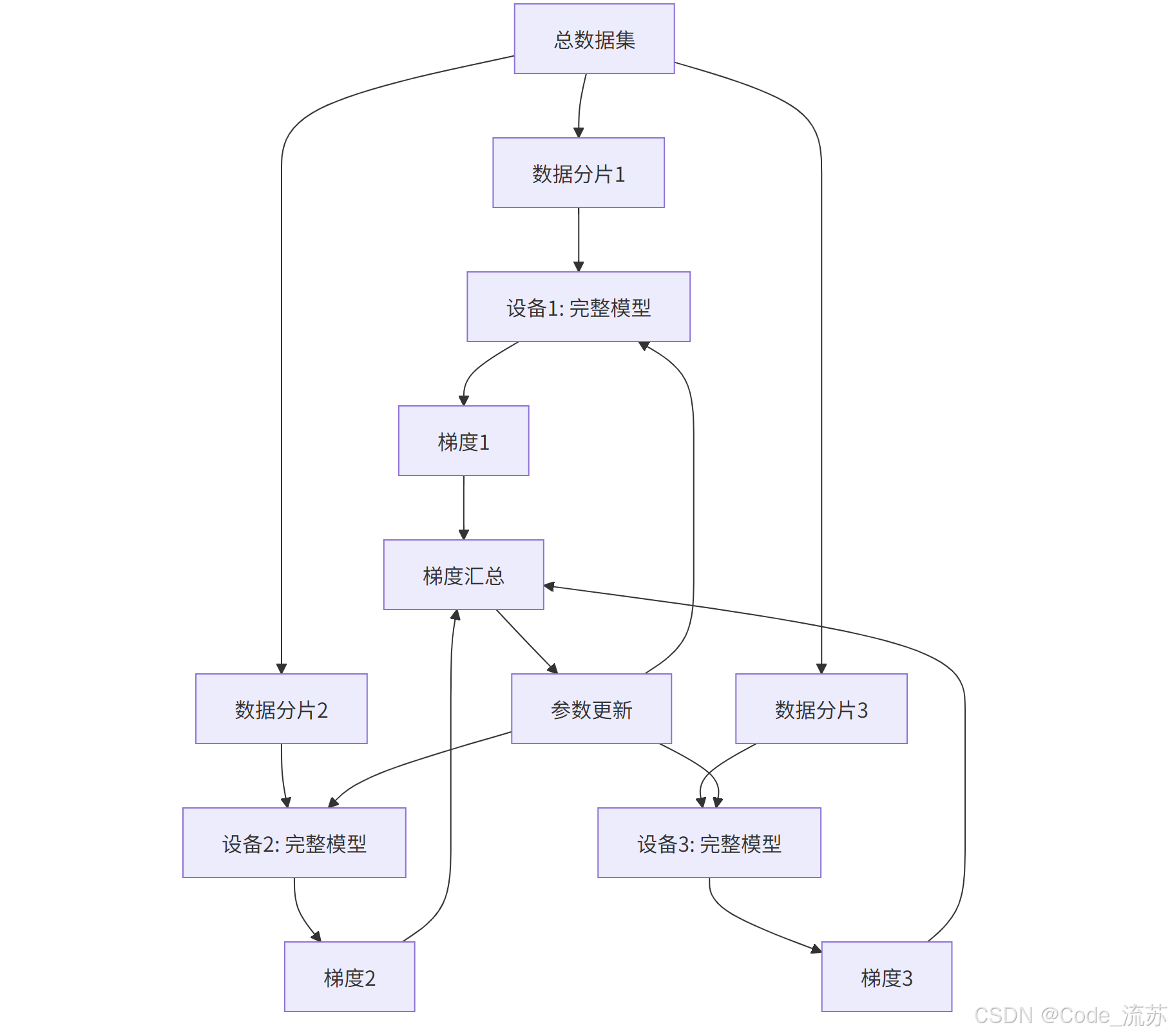
1》数据并行(Data Parallelism)
数据并行是最常用的分布式训练方式,其核心思想是:
- 模型结构在每个设备上完整复制一份
- 训练数据被分成若干批次,分别送入不同设备
- 每个设备使用各自的数据计算梯度
- 梯度汇总后统一更新模型参数
2》模型并行(Model Parallelism)
模型并行适用于模型过大,单个设备内存无法容纳的情况:
- 将神经网络模型分割成多个部分
- 每个部分分配到不同设备上
- 数据在各个部分之间顺序流动完成前向和反向传播

3》数据并行 vs 模型并行
2. 主流分布式训练框架
1》Horovod
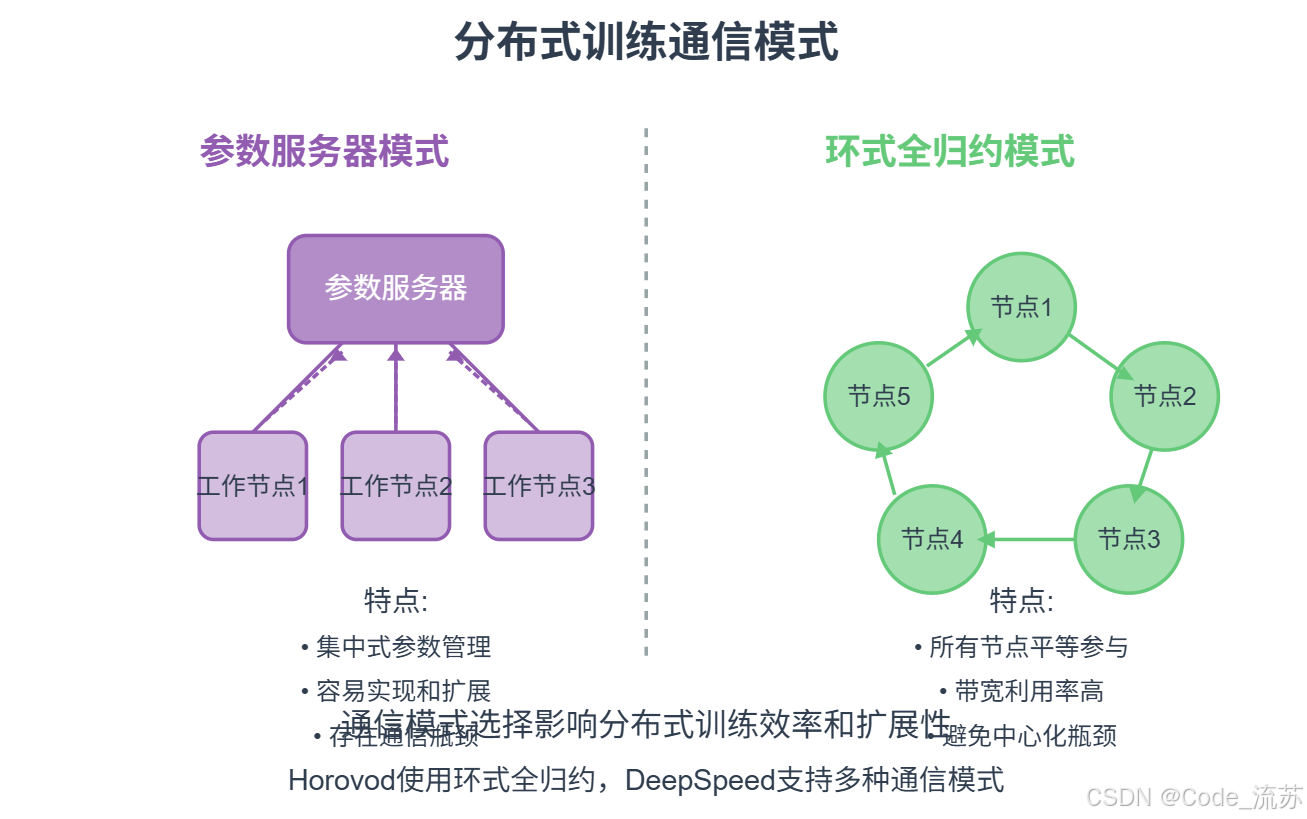
Horovod是由Uber开发的一款易用、高效的分布式深度学习训练框架,它基于环形全归约(Ring-AllReduce)算法,可以无缝集成到TensorFlow、PyTorch和MXNet等框架中。
# Horovod 基本使用示例 (PyTorch)
import torch
import horovod.torch as hvd
# 初始化Horovod
hvd.init()
# 获取当前设备ID和总设备数
rank = hvd.rank() # 当前进程的排名
size = hvd.size() # 总进程数
# 将每个进程绑定到对应的GPU
torch.cuda.set_device(rank)
# 准备模型
model = MyModel().cuda()
# 准备优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 使用Horovod包装优化器
optimizer = hvd.DistributedOptimizer(optimizer,
named_parameters=model.named_parameters())
# 广播参数,确保所有进程从相同状态开始
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)
# 数据分片
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=size, rank=rank)
train_loader = torch.utils.data.DataLoader(
train_dataset, sampler=train_sampler, batch_size=batch_size)
Horovod的主要优势:
- 易于使用,代码改动小
- 通信效率高,扩展性好
- 支持多种深度学习框架
2》DeepSpeed
DeepSpeed是微软开发的分布式训练库,提供了更全面的分布式训练策略,包括ZeRO(Zero Redundancy Optimizer)技术,可以显著降低内存占用,适合训练超大型模型。
# DeepSpeed 基本使用示例
import torch
import deepspeed
# 定义模型
model = MyModel()
# DeepSpeed配置
ds_config = {
"train_batch_size": 16,
"optimizer": {
"type": "Adam",
"params": {
"lr": 1e-5
}
},
"zero_optimization": {
"stage": 2 # ZeRO优化级别
}
}
# 初始化DeepSpeed模型
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config=ds_config
)
# 训练循环
for batch in train_loader:
inputs, labels = batch
# 前向传播
outputs = model_engine(inputs)
loss = loss_fn(outputs, labels)
# 反向传播
model_engine.backward(loss)
# 更新参数
model_engine.step()
DeepSpeed的主要特点:
- ZeRO优化减少内存占用
- 支持3D并行(数据、模型、流水线)
- 提供混合精度训练
- 针对极大模型(如GPT-3)有特殊优化
3》分布式训练架构比较
二、分布式推理技术
分布式推理是在模型部署阶段,利用多设备协同工作,提高推理吞吐量和降低延迟的技术。与训练不同,推理阶段更注重低延迟和高吞吐量。
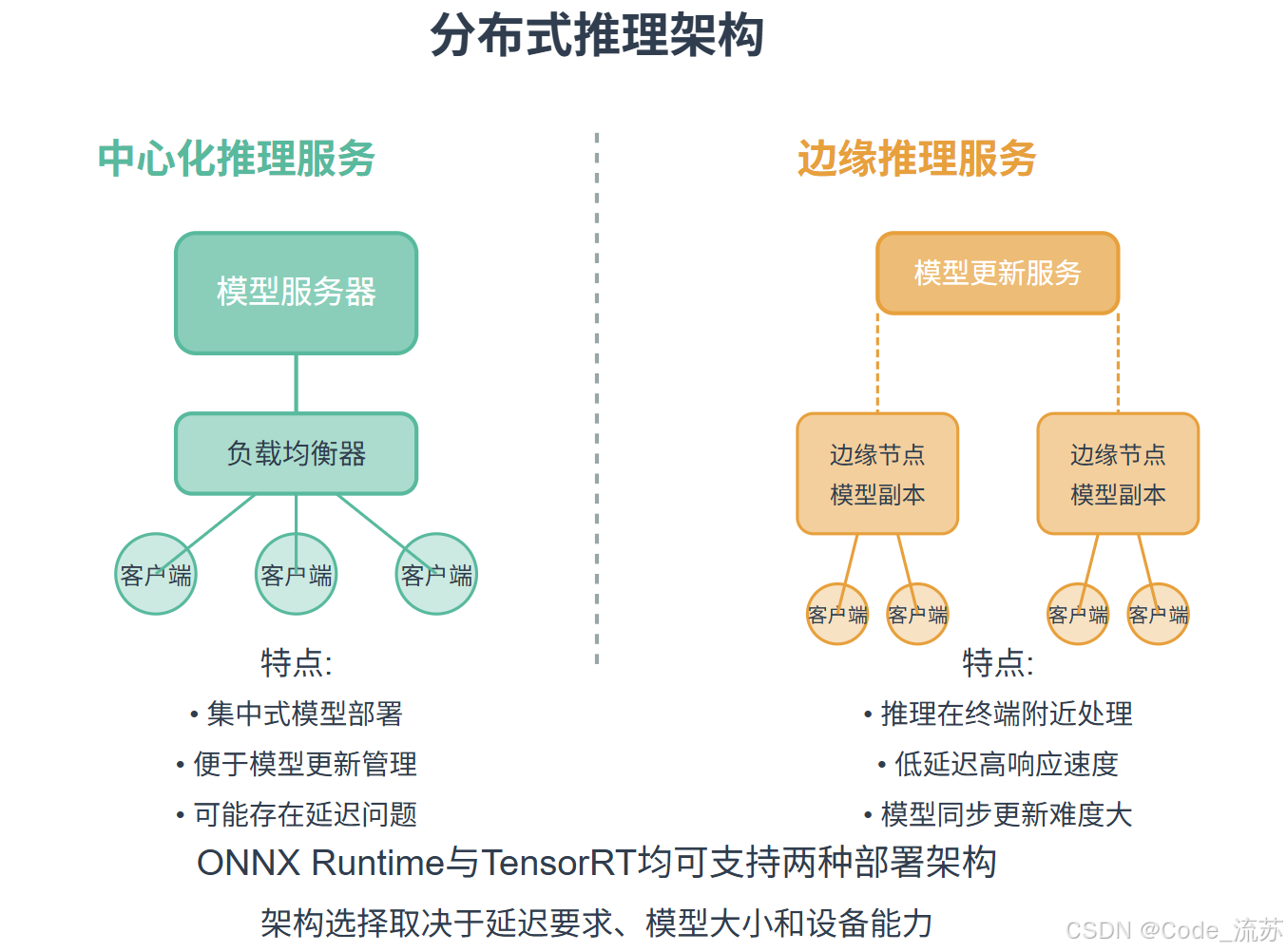
1. ONNX Runtime分布式推理
ONNX (Open Neural Network Exchange) 是一种开放的神经网络模型表示格式,而ONNX Runtime是针对ONNX模型的高性能推理引擎。
ONNX Runtime的分布式特性
- 模型并行化:可以将大模型分割到多个设备上
- 动态负载均衡:根据计算负载动态调整任务分配
- 跨平台优化:在不同硬件平台上都能获得优化的性能
# 使用ONNX Runtime进行分布式推理示例
import onnxruntime as ort
import numpy as np
# 创建分布式推理会话
providers = ['CUDAExecutionProvider']
session_options = ort.SessionOptions()
# 启用并行执行
session_options.execution_mode = ort.ExecutionMode.ORT_PARALLEL
session_options.inter_op_num_threads = 4 # 设置线程数
session_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# 创建推理会话
session = ort.InferenceSession('model.onnx', session_options, providers=providers)
# 准备输入数据
input_name = session.get_inputs()[0].name
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32)
# 执行推理
output = session.run(None, {input_name: input_data})
2. TensorRT分布式推理
NVIDIA TensorRT是专为NVIDIA GPU优化的高性能深度学习推理库,它提供了强大的模型优化和加速能力。
TensorRT的分布式特性
- 引擎级并行:通过创建多个TensorRT引擎实例处理请求
- 批处理优化:智能批处理机制提高GPU利用率
- 多流执行:支持CUDA流并行处理多个请求
# 使用TensorRT进行分布式推理示例
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
# 创建TensorRT运行时和引擎
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
runtime = trt.Runtime(TRT_LOGGER)
# 加载序列化的引擎
with open('model.engine', 'rb') as f:
engine_bytes = f.read()
engine = runtime.deserialize_cuda_engine(engine_bytes)
# 创建执行上下文
context = engine.create_execution_context()
# 分配输入/输出缓冲区
h_input = cuda.pagelocked_empty(trt.volume(engine.get_binding_shape(0)), dtype=np.float32)
h_output = cuda.pagelocked_empty(trt.volume(engine.get_binding_shape(1)), dtype=np.float32)
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
# 创建CUDA流用于并行执行
stream = cuda.Stream()
# 准备输入数据
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32)
np.copyto(h_input, input_data.ravel())
# 复制输入数据到GPU
cuda.memcpy_htod_async(d_input, h_input, stream)
# 执行推理
context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
# 将结果从GPU复制回CPU
cuda.memcpy_dtoh_async(h_output, d_output, stream)
# 同步流
stream.synchronize()
3. 分布式训练与推理框架对比
下表总结了不同分布式框架的特点和适用场景:
| 框架 | 主要特点 | 适用场景 | 优势 | 挑战 |
|---|---|---|---|---|
| Horovod | 环形全归约算法 易于集成 | 中小规模模型训练 横向扩展训练 | 使用简单 通信效率高 | 不适合超大模型 纯数据并行 |
| DeepSpeed | ZeRO优化 3D并行 | 超大规模模型训练 资源受限环境 | 内存效率高 支持混合精度 | 配置复杂 兼容性考虑 |
| ONNX Runtime | 跨平台 动态分配 | 云端推理服务 跨平台部署 | 广泛硬件支持 易于部署 | 优化不如专用库 调优复杂 |
| TensorRT | GPU专用优化 高吞吐量 | 需要极致性能 NVIDIA硬件环境 | 性能最优 延迟最低 | 仅支持NVIDIA 开发难度大 |
三、代码练习:分布式训练实战
让我们通过一个实际例子,使用PyTorch的DistributedDataParallel (DDP)模块来实现分布式训练,加速深度学习模型训练过程。
1. 分布式训练环境准备
首先,我们需要设置分布式训练环境。以下是一个可在多节点、多GPU环境下运行的脚本:
# 文件名: distributed_train.py
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.distributed import DistributedSampler
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
def setup(rank, world_size):
"""
初始化分布式环境
参数:
- rank: 当前进程的序号
- world_size: 总进程数
"""
# 设置环境变量
os.environ['MASTER_ADDR'] = 'localhost' # 主节点地址
os.environ['MASTER_PORT'] = '12355' # 主节点端口
# 初始化进程组
dist.init_process_group(
backend='nccl', # NVIDIA GPU推荐使用nccl后端
init_method='env://',
world_size=world_size,
rank=rank
)
# 设置当前设备
torch.cuda.set_device(rank)
def cleanup():
"""
清理分布式环境
"""
dist.destroy_process_group()
def train(rank, world_size, epochs):
"""
模型训练函数
参数:
- rank: 当前进程的序号
- world_size: 总进程数
- epochs: 训练轮数
"""
# 初始化分布式环境
setup(rank, world_size)
# 创建模型
model = models.resnet50(pretrained=False).cuda(rank)
# 将模型包装为DDP模型
model = DDP(model, device_ids=[rank])
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss().cuda(rank)
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 数据预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载CIFAR-10数据集
dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
# 创建分布式采样器,确保每个进程获取不同的数据
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
# 创建数据加载器
dataloader = DataLoader(
dataset,
batch_size=64,
shuffle=False, # 分布式采样器控制随机性
num_workers=4,
pin_memory=True,
sampler=sampler
)
# 训练循环
for epoch in range(epochs):
# 必须在每个epoch开始时设置sampler的epoch
sampler.set_epoch(epoch)
running_loss = 0.0
for i, (images, labels) in enumerate(dataloader):
# 将数据移至当前设备
images = images.cuda(rank, non_blocking=True)
labels = labels.cuda(rank, non_blocking=True)
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 统计损失
running_loss += loss.item()
# 每100批次打印一次统计信息
if i % 100 == 99 and rank == 0: # 只在主进程(rank=0)打印
print(f'Epoch {epoch+1}, Batch {i+1}, Loss: {running_loss/100:.4f}')
running_loss = 0.0
# 清理分布式环境
cleanup()
def run_demo(demo_fn, world_size):
"""
启动多进程训练的入口函数
参数:
- demo_fn: 训练函数
- world_size: 总进程数
"""
mp.spawn(demo_fn, args=(world_size, 10), nprocs=world_size, join=True)
if __name__ == "__main__":
# 获取可用的GPU数量
n_gpus = torch.cuda.device_count()
if n_gpus < 2:
print(f"需要至少2个GPU进行分布式训练,但只发现了{n_gpus}个。将使用单GPU训练。")
# 这里可以添加单GPU训练的代码
else:
# 使用所有可用的GPU
world_size = n_gpus
run_demo(train, world_size)
2. 运行分布式训练
要运行上述脚本,您只需执行:
python distributed_train.py
脚本将自动检测可用的GPU数量,并据此创建相应数量的进程进行训练。
3. 分布式训练性能分析
让我们分析一下分布式训练与单机训练的性能差异:
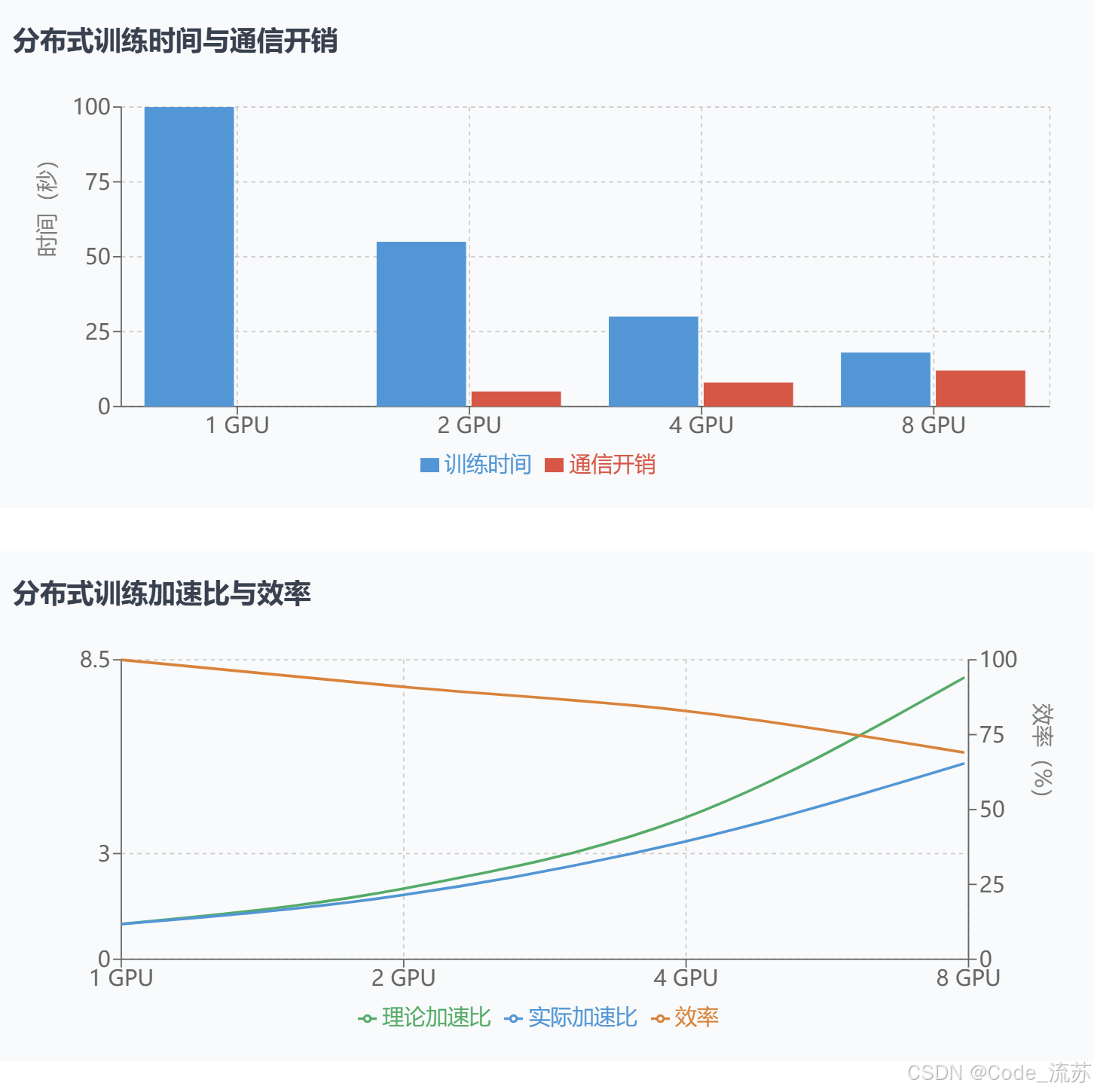
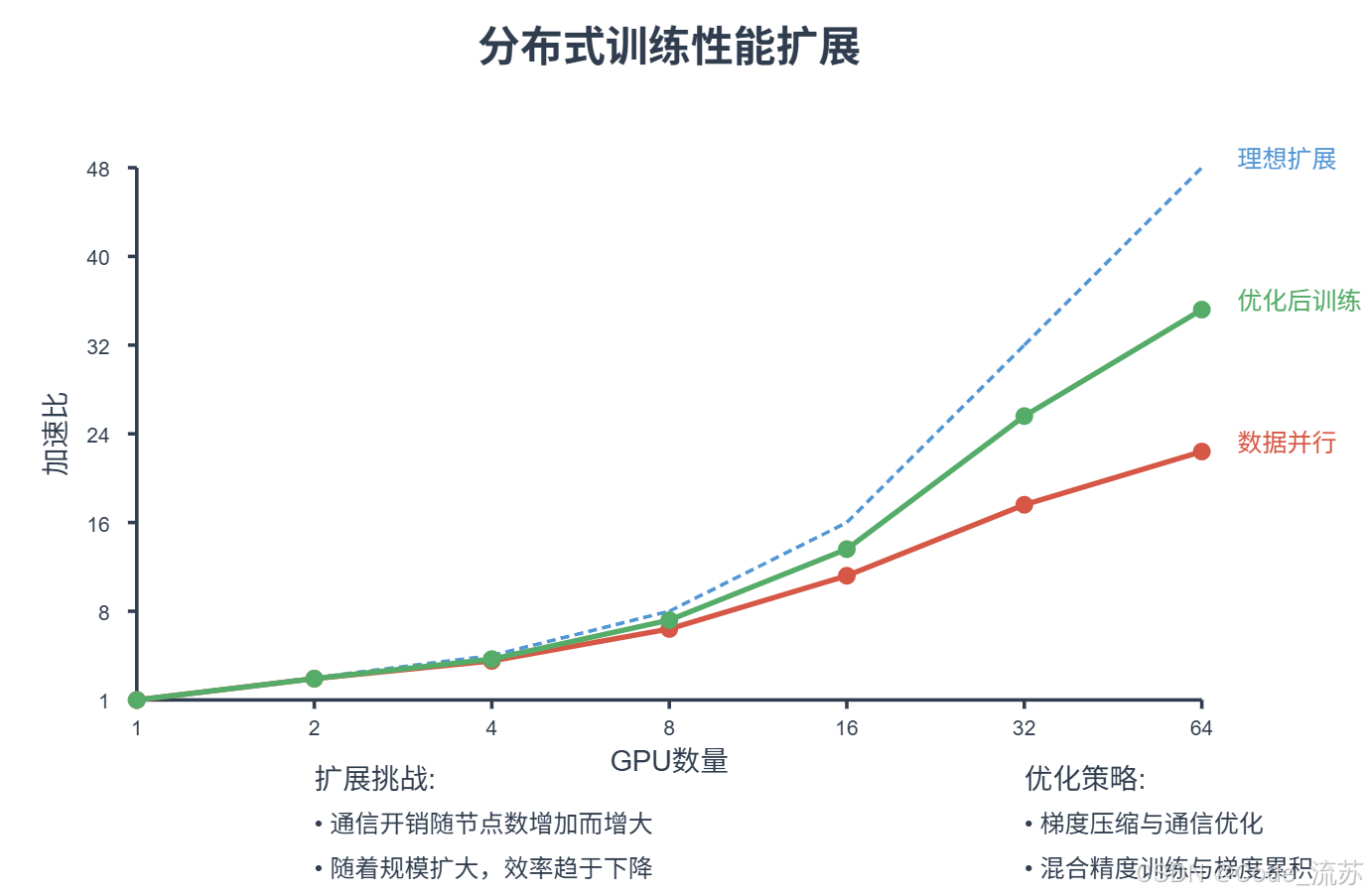
四、分布式训练与推理最佳实践
在实际应用中,如何有效利用分布式训练与推理技术是一个需要经验积累的问题。以下是一些最佳实践建议:
1. 选择合适的并行策略
选择合适的并行策略对性能影响重大,需要根据具体场景做出选择:
- 模型较小,数据量大:优先选择数据并行
- 模型较大,单设备放不下:优先选择模型并行
- 超大模型(百亿参数以上):考虑组合使用多种并行策略
# 综合并行策略示例 (基于DeepSpeed)
ds_config = {
"zero_optimization": { # ZeRO优化 - 数据并行中的参数分片
"stage": 3,
"offload_optimizer": { "device": "cpu" }, # 将优化器状态卸载到CPU
"offload_param": { "device": "cpu" } # 将部分参数卸载到CPU
},
"pipeline": { # 流水线并行配置
"stages": 2,
"partition": "type:transformer|embedding" # 按照模块类型分区
},
"tensor_parallel": { # 张量并行配置
"enabled": True,
"size": 4
}
}
2. 通信优化技巧
在分布式训练中,通信开销常常成为瓶颈,以下技巧可以显著提升性能:
- 梯度累积:减少通信频率,每N个批次更新一次
- 梯度压缩:使用量化或稀疏化技术减少传输数据量
- 重叠通信与计算:在计算下一批次的同时进行通信
# 梯度累积示例
accumulation_steps = 4 # 每4个批次更新一次模型
for i, (images, labels) in enumerate(dataloader):
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 缩放损失值
loss = loss / accumulation_steps
# 反向传播
loss.backward()
# 每accumulation_steps批次更新一次参数
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
3. 内存优化
对于大模型训练,内存优化至关重要:
- 混合精度训练:使用FP16/BF16代替FP32,减少内存消耗
- 梯度检查点:牺牲计算换取内存,反向传播时重新计算中间结果
- 选择性激活缓存:只保存关键层的中间结果
# 混合精度训练示例 (使用PyTorch AMP)
from torch.cuda.amp import autocast, GradScaler
# 创建梯度缩放器
scaler = GradScaler()
for epoch in range(epochs):
for images, labels in dataloader:
images = images.cuda()
labels = labels.cuda()
# 自动使用混合精度
with autocast():
outputs = model(images)
loss = criterion(outputs, labels)
# 缩放梯度并执行反向传播
scaler.scale(loss).backward()
# 更新参数
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
4. 分布式推理的负载均衡
在大规模推理服务中,负载均衡是保证高吞吐量和低延迟的关键:
- 动态批处理:根据请求量动态调整批大小
- 模型分片与副本:热门模型创建多个副本,大模型进行分片
- 请求路由优化:根据硬件负载和模型特性智能分配请求
# 动态批处理示例伪代码
import queue
import threading
import time
request_queue = queue.Queue()
batch_size = 4 # 初始批大小
max_wait_time = 0.1 # 最大等待时间
def batch_processor():
while True:
# 收集批处理请求
batch = []
start_time = time.time()
# 尝试填满一个批次或等待最大时间
while len(batch) < batch_size and time.time() - start_time < max_wait_time:
try:
request = request_queue.get(timeout=max_wait_time)
batch.append(request)
except queue.Empty:
break
if batch:
# 处理批次请求
process_batch(batch)
# 动态调整批大小
if len(batch) == batch_size and request_queue.qsize() > batch_size:
# 请求量大,增加批大小
batch_size = min(batch_size * 2, 32)
elif len(batch) < batch_size // 2:
# 请求量小,减少批大小
batch_size = max(batch_size // 2, 1)
# 启动批处理线程
threading.Thread(target=batch_processor, daemon=True).start()
五、总结与未来展望
通过本文的学习,我们掌握了分布式训练与推理的基本概念、主流技术及实践方法。随着AI模型规模不断增长,分布式技术已成为现代深度学习的必备工具。
1. 关键技术总结
- 分布式训练:通过数据并行、模型并行等策略,将训练任务分布到多台设备上
- 分布式推理:通过模型分割、动态负载均衡等技术,提高推理服务的吞吐量和降低延迟
- 主流框架:Horovod、DeepSpeed用于训练,ONNX Runtime、TensorRT用于推理
2. 未来发展趋势
- 混合云训练:跨越本地集群和云端资源的弹性训练架构
- 确定性训练:保证分布式环境下的训练结果可复现性
- 智能资源调度:基于AI的分布式资源自动调度系统
- 低能耗高效推理:更高效的分布式推理技术,降低能源消耗
3. 实践建议
对于初学者,建议从以下几个方面入手:
- 先掌握单机多卡训练,熟悉基本的分布式概念
- 尝试使用PyTorch DDP或Horovod这类易用的工具
- 在小规模数据集上实验不同的并行策略
- 逐步探索更高级的技术,如DeepSpeed和TensorRT
分布式训练与推理是AI大规模应用的基石,随着模型规模和计算需求不断增长,这些技术将变得越来越重要。希望本文能为您打开分布式AI技术的大门,助力您在未来的AI实践中游刃有余!
思考题:如果有一个10亿参数的模型需要在8台各有4张GPU的机器上训练,您会选择什么样的分布式训练策略?为什么?
祝你学习愉快,勇敢的Python星球探索者!👨🚀🌠
创作者:Code_流苏(优快云)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!


















 4414
4414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











