







前言
随着AI代码生成技术的爆发式发展,国内外顶尖模型在编程领域的竞争愈发激烈。
本文选取了DeepSeek R1(中国)、Qwen QwQ-32B(中国)、Grok3(美国)、Claude 3.7 Sonnet(美国)、GPT o3-mini(美国)五款代表性模型,通过实际案例测试其在生成"令人惊讶的HTML页面"时的表现,一起来看看吧!
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》
创作者:Code_流苏(优快云)(一个喜欢古诗词和编程的Coder😊)目录
很高兴你打开了这篇博客,更多好用的软件工具,请关注我、订阅专栏《AI漫谈》,内容持续更新中…
思维速览:
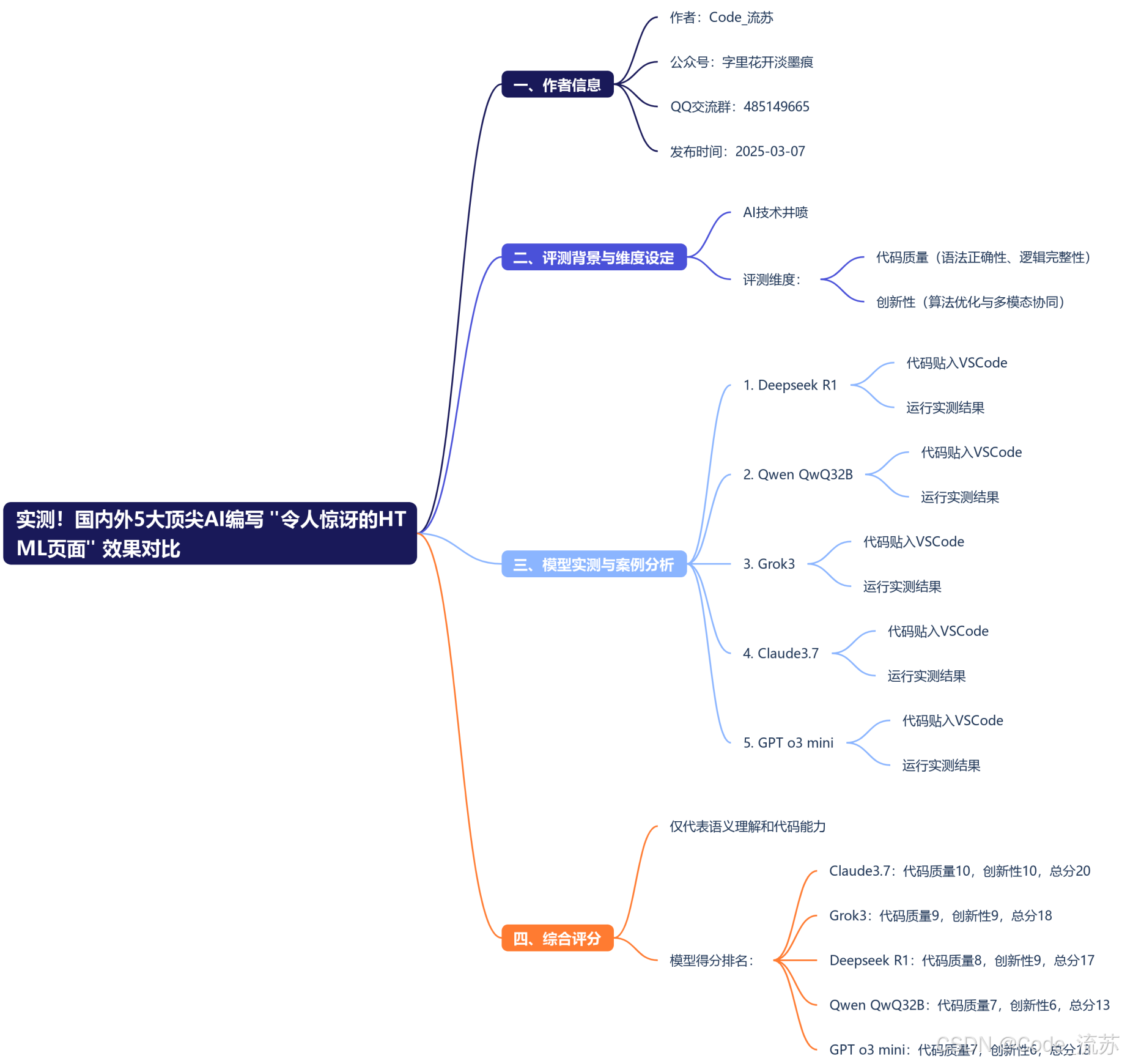
一、评测背景与维度设定
在2025年AI技术井喷的背景下,我们选取了国内外最具代表性的五款大语言模型——Deepseek R1(中国)、Qwen QwQ32B(中国)、

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











