







 本文详细介绍了数据库的模式和数据模型,包括概念层、组织层数据模型以及数据库系统的结构。重点讲解了关系数据库的关系模型,如关系、元组、属性等基本术语,并阐述了数据完整性控制,包括主键、外键约束。此外,还涵盖了关系代数的基础运算,如并、差、交等。最后讨论了数据库中常用的操作函数,如日期时间、字符串函数和类型转换等。
本文详细介绍了数据库的模式和数据模型,包括概念层、组织层数据模型以及数据库系统的结构。重点讲解了关系数据库的关系模型,如关系、元组、属性等基本术语,并阐述了数据完整性控制,包括主键、外键约束。此外,还涵盖了关系代数的基础运算,如并、差、交等。最后讨论了数据库中常用的操作函数,如日期时间、字符串函数和类型转换等。
数据库管理模式和数据模型
数据模型对现实世界客观事物抽象建立数据关系的模型**(数据库中各表,及各表之间联系)**,针对数据库来说,数据模型分为层次型,网状型,关系型三大类。
数据模型三要素:
(1)数据结构:描述数据类型、内容,以及数据之间的联系;
(2)数据操纵:是指对数据库中各种对象允许的操作功能集合,如对数据的增、删、查、改等;
(3)数据的约束:泛指完整性规则集合,尽可能保证数据的正确性,有效性。
概念层数据模型
概念层数据模型是指抽象现实系统中有应用价值的元素和关系,反映现实中有用价值的信息结构。用于对信息世界中的对象建模—属于抽象的第一步。
实体-联系模型 E-R (entity-relationship)
- 实体:是有公共性质并可以相互区分的现实对象的集合。
- 每个实体有多个列,每列就叫属性,也叫字段field ,属性是对象的静态参数的描述。
- 联系 : 指不同实体表的之间的联系。
注:描述概念层模型时,使用E-R图的三个主要素是:实体,属性,联系
组织层数据模型
分为层次数据模型、网状数据模型、关系数据模型
数据库系统的结构
从数据库管理角度看:三级模式是数据库系统的内部结构;从一般用户从外部看数据库系统的角度看,数据库系统结构分为集中式、文件服务器结构、客户/服务器结构。
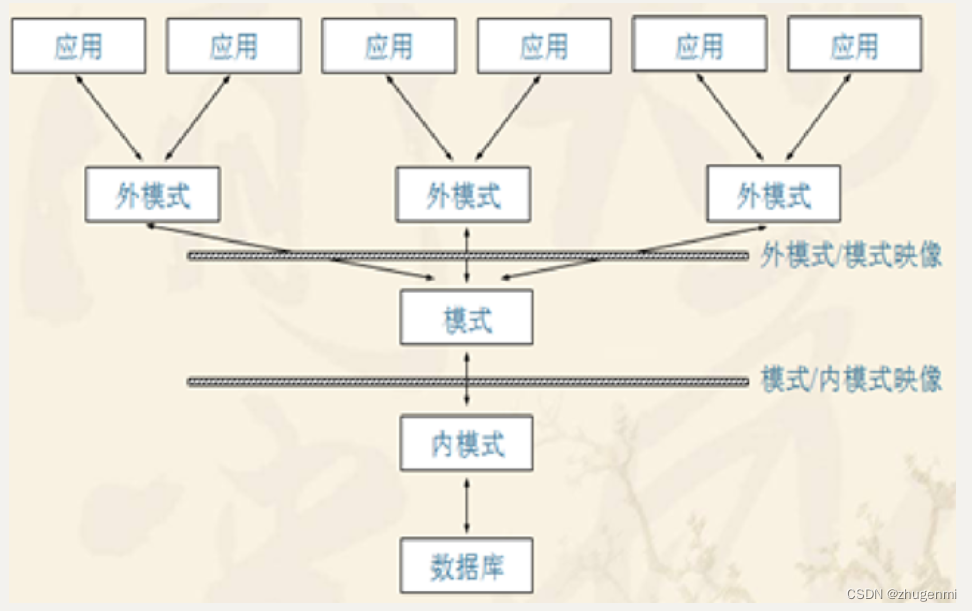
(1)模式:逻辑/概念数据库
模式也称为逻辑模式(Logic Schema),它是由数据库设计者综合所有的数据需求,从全局的角度对数据库中全部数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图,即全局视图.
定义模式时不仅要定义数据的逻辑结构(如数据的型、数据类型、取值范围等),而且要定义与数据有关的安全性、完整性要求,定义这些数据之间的联系。
(2) 外模式(External Schema):用户数据库
外模式也称为子模式(Subschema)或用户模式(User Schema),是程序员和最终用户能看见和使用的局部数据的逻辑结构和特征的描述,是与某一应用有关的数据的逻辑表示。外模式通常是模式的子集。
外模式完全按照用户对数据的需要、站在局部的角度进行设计的。由于一个数据库应用系统有多个应用,因此可以有多个外模式。由于外模式是面向程序员和最终用户的,因此又称为用户数据视图。另一方面,同一外模式也可以为某一用户的多个应用系统所使用,但一个应用程序只能使用一个外模式。
(3)内模式(Internal Schema):物理数据库
内模式也称为存储模式(Storage Schema)或物理模式(Physical Schema),它是数据物理结构和存储方式的底层描述,包括记录的存储方式、索引组织方式、数据是否压缩和加密。
比内模式更接近物理存储和访问的那些软件机制,即文件系统,是操作系统的一部分。例如,从磁盘读数据或写数据到磁盘上。
一个DBMS至少应该支持的主要功能
1 数据定义:建立数据库结构,表头structure,及维护
2 数据操纵:数据的增删查改(查叫query,其它增删改叫noquery)
3 优化和执行: 数据结构严谨,不冗余,执行效率高
4 数据安全和数据完整性控制:存储安全(加密),访问权限安全;数据完整性是数据符合要求,表之间的联系严谨。
5 数据备份和恢复,并发控制: 备份是防止数据丢失;并发控制是防止脏数据。
6 数据字典:开发软件之前制定数据需求分析,需求分析中的对关键字或功能加以说明。
7 性能
关系数据库
关系模型
基本概念
1 实体:就是一个数据表(对象集合),这些对象具有共享的属性如学号,姓名,性别等. 一个实体对应一个关系
2 属性: 关系二维表的一列叫一个属性(有些教材称为字段,field )
一个实体是属性的集合(列的集合),也是记录的集合(行的集合);一个数据行叫一个记录record;一个实体的一个属性针对不同对象的取值范围一样的(数据域),比如({“男”,“女”}是性别属性的域)
3 联系: 实体之间的按关键字的联系(用于以后多表连接查询)
4 参照完整性:一个表的关键属性值发生变化时,要参考另一个表的同属性值。(如工资表中不能出现不在人事表事先存在的人;工资表的数据按工号去参考人事表,证明该人是否是合法员:实体之间的参照完整性;限制表中的性别只能是男或女,身高范围:自定义完整性之一)
注:如果一个表实在无法定义一个主码PK属性列,也要定义一个自增列,相当于记录号–recno)
5 域: 一组有相同类型的值的集合。域可理解为一个关系中某个属性的值的范围界定。如:属性性别的域为{男,女}, 身高的域为[150,180]
6 分量:一个元组的某个属性值就是分量,如上面的“张三”,“男”都是该元组的分量
关系中基本术语(重点)
(1) 元组:表中的一个数据行(不是表头)叫一个记录,也叫一个元组。如学生表的:
0001 张三 男 2003-2-1 ,这就是一个元组
(2) 属性
(3) 候选码:在一个实体表中,某属性的值唯一,用这些值可以在表中唯一代表标识该元组记录,如学生表中的学号列,身份证号列,手机号列。这些列属性可以作为表的候选码,但注意:一个表可以有多个候选码。
(4) 主码:一个表在候选码中选一个最具有代表的属性作为主码primary key(PK), 一个表只能有一个PK码。在学生表中一般选学号为PK
注意:如管理一些数据时,数据无明确的主码,应该人为地给这样的表指定一个ID列,甚至可以让它随着新的记录数据入驻而自动产生一个整数ID,以后在操作这些记录时就有一个明确的唯一的ID。
一个表主码可能是由一列组成,也可以由多个列属性组成:
-
学生表中: pk(学号)
-
成绩表中:pk(学号,课程号)
(5) 主属性:在表中所的属性列中,能作为主码的一个或多个属性构成该表的主属性。
特别注意:如在学生表中,学号是主码,学号是主属性(姓名依赖于学号);在选课成绩表(学号 ,课程号,成绩值)中,学号+课程号 才是主码,此时学号,课程号是成绩表的主属性。即成绩值依赖于学号+课程号(学号和课程号组合起来就是不重复的)。
一个实体表中,除了主属性外的其它属性列叫非主属性列.
注意:一个好的严谨的表,非主属性的值要完全(仅)依赖于主属性值;如果一个表的某属性值只是依赖于主属性(主码)的一部分,叫“部分依赖”,这样的是不优化(冗余数据太多)
(6) 外码:FK
在A表中某属性列c1为主码,在B表同样有属性列c1但c1不是主码。两表可靠C1属性值进行逻辑的关联,如果要让B表的人在逻辑上依赖A1表的值的存在,此时说立足B表,C1列叫针对A表的外码。
如成绩表中学号(代表学生),这些学号值的存在要依赖,要参考学生表的学号值。在成绩表插入一个新学生成选课数据时,我们应该要检测此学号是否已经存在于学生表中,如果存在则可以插入;如果不存在则出现“外键错误”。
以上理论就是表间的关系约束,也是一种数据完整性控制。在大中型APP中,数据表几十上百个,这些表大部分要靠以上理论来实现表间的联系。
关系(表)的类型
(1)基本表 table
是数据库最重要的实体,就是存放各种数据的物理表,是以APP的数据主要来源. 如学生表,课程表等
(2)视图 view
是虚拟表,仅存在于内存,它在使用时功能当基本表来使用,它的数据来源于基本表。虚拟表在使用结束时消失。
如:select * from 学生表 成功后系统以一个视图虚拟表呈现给用户(可这样说:在sqlserver中用户使用查询命令输出的结果都叫视图)
虽然说视图数据来源于基本表,但完成操作后,视图一般与基本表不再有关系。可见:数据库以视图的方式把需要的数据展现出来(即三级模式中的中间模式)。如再利用JAVA把这些视图中的数据以漂亮的表格列表方式呈现给用户(外模式)
数据库最底层提供数据过程:物理磁盘的数据库→视图→展示数据
(3)查询临时表
基本上同(2),临时表还包括在数据操纵过程中系统临时表,触发器用到的.
关系的基本性质
一个表内的数据,属性的特点
(1)列是同质的
同一列的数据有规范范围,不同列是相互独立又相互依赖的。
(2)不同列可以来自同一个域,也可不同
域是属性值的取值范围,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











