






 本文介绍了如何查看及使用GPU设备,包括在单GPU和多GPU环境下通过DataParallel、OS环境变量设置以及命令行参数来指定GPU运行代码。内容涵盖了模型和数据的设备迁移,以及CUDA_VISIBLE_DEVICES环境变量的设置方法。
本文介绍了如何查看及使用GPU设备,包括在单GPU和多GPU环境下通过DataParallel、OS环境变量设置以及命令行参数来指定GPU运行代码。内容涵盖了模型和数据的设备迁移,以及CUDA_VISIBLE_DEVICES环境变量的设置方法。
查看自己的GPU设备:
nvidia-smi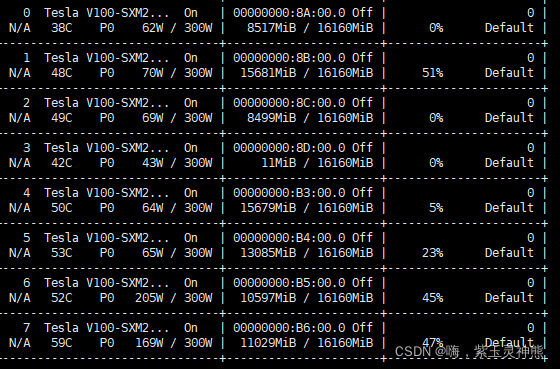
在某一块设备上运行代码的基本条件:1.有这个设备;2.代码所需的数据在这块设备上,代码所需的数据是指网络的模型以及训练数据两部分,只要这两部分在同一块设备上,就可以运行。
1.单GPU设备:
1.1使用DataParallel()函数:
由于使用的是单GPU,所以其设备编号一定是0.所以这样默认的调用GPU0.
impor torch.nn as nn
# 模型加载
# 假设模型初始化如下:
model=VGG16()
# 将其指认到设备上的方法如下:
model=torch.nn.DataParallel(model)
cudnn.benchmark = True
model=model.cuda()
# 数据加载
# 假设已经载入好的数据和标签如下:
images,targets = data
# 指认到设备上的方法如下:
images.cuda()
targets.cuda()1.2使用OS调用设备:
在代码中加入如下语句:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
1.3命令式调用GPU:
即在运行指令前加入设备指认语句。我只在服务器上试过这样的语句,没有在Windows多GPU设备上试过代码,不知道可不可行。
CUDA_VISIBLE_DEVICES=0 python XXX.py
2.多GPU设备:
其实调用多GPU设备的命令与单GPU设备相似。
2.1使用OS调用设备:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3"2.2命令式调用GPU:
CUDA_VISIBLE_DEVICES=0,1,2,3 python XXX.py
我也是初学,如果大家有什么不同的看法,或者需要实践的指令,也可以告诉我,我试试。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









