






今天本想着爬取网易云的飙升榜的歌曲排名和信息的,来练习一下。结果第一步就报错了:
爬取网址是:https://music.163.com/#/discover/toplist?id=19723756
使用requests模块来请求网页,得到响应,并且为了防止网站发现我是爬虫,加了请求头。
headers={
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-encoding':'gzip, deflate, br, zstd',
'accept-language':'zh-CN,zh;q=0.9',
'cache-control':'max-age=0',
'referer':'https://music.163.com',
'sec-ch-ua':'"Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"Windows"',
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'same-origin',
'sec-fetch-user':'?1',
'upgrade-insecure-requests':'1',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36'
}
正当我,准备爬虫第一步:得到响应,准备解析网页,发现报错了:
requests解析网页有两个方法:第一个方法使用response.text
结果报错:出现乱码了:
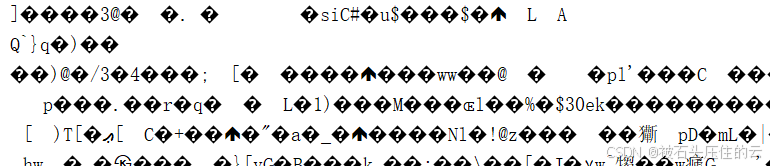 使用第二个方法是:response.content.decode('utf-8')
使用第二个方法是:response.content.decode('utf-8')
结果还是报错了:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa7 in position 6: invalid start byte
。
看了这两个方法的都报错的结果,我开始去分析是否是编码的问题。于是去网上搜索寻找解答
知道了:使用response.encoding可以获取网页的编码格式
于是我print(response.encoding)打印了一下是utf-8.
为了保证我解析网页的编码没有错误,于是我这样写response.encoding='utf-8'
结果使用第一个方法解析网页,还是乱码,
第二个也还是报相同的错。
我大概的了解了一下,response.text的功能是:是读取网页的默认设置的编码来解析的,就是读取到python中会先有一个中转,编码为unicode,然后再读取网页给的编码来解析。我设置为utf-8应该是没有问题的,好奇怪。
然后response.content是将网页转换为二进制。然后再decode设置指定的编码来解析成网页的内容。我也是设置为utf-8的,应该也没问题的。好奇怪。
正当我焦头烂额的时候。
我开始从头开始分析。没错就是分析那个请求头了。我写的参数非常多。
于是我去网上搜索资料,想了解一下这个请求头,是不是不用给这么多参数,只需要给几个必须得参数就可以了。
然后大概了解了一下,好像最少给一个:user-agent的参数就可以了。
于是我抱着试试的想法。把请求头其他的参数注释掉,留一个user-agent。再执行一下。解析网页的代码,竟然成功了,没有报错了。
真的我会哭死。
为了找出,具体是请求头的那个参数导致的报错,我一个个注释,调试,运行,发现罪魁祸首是
'accept-encoding':'gzip, deflate, br, zstd',
这个参数。只要注释这行参数,使用第一个方法解析网页就不会乱码了。使用第二个方法解析网页就不会报错了。
然后,我也不知道这个参数具体是什么作用的,于是就去网上搜索了一下,具体可以参考一下,这位大佬的分析。
然后看了大佬的发现:把这行参数中的 br去掉,也可以解决问题。于是我试了一下,发现也没报错了,太感谢了。我还没有细琢磨,
我后面要好好学习一下,要搞懂原理,后面才能处理起来得心应手,加油。
今天的这个爬虫学习,爬取网页云音乐的就到这个解析网页这里就结束了一天就过去了,本来以为处理完这个问题就可以往下进行,结果发现往下进行不下去了。处理完这个问题,后面还有更大的问题等着我,我发现这个网易云的网址是js加密了。我不会,只能后面慢慢学习了。加油。每天学习一点,生活才能进步一点点。万丈高楼平地起,辉煌只能靠自己。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









