




一、缓存的概念
1.1 概念
缓存就是数据交互的缓冲区(称为Cache),是存储数据的临时地方,一般读写性较高。
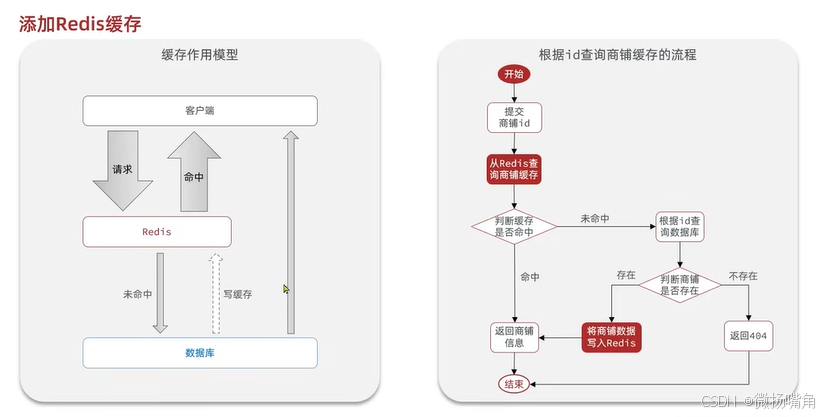
1.2 代码实现
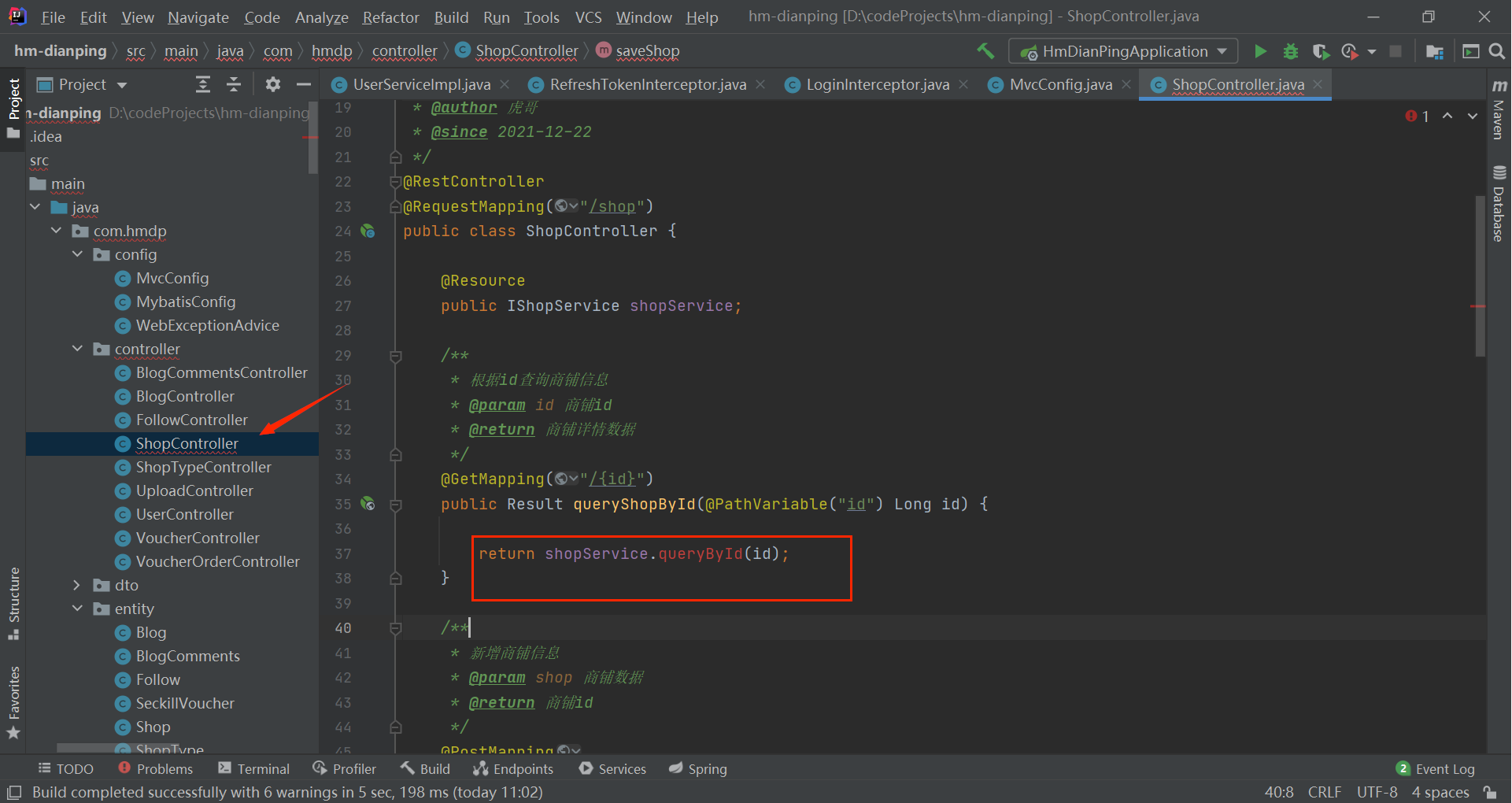
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return shopService.queryById(id);
}
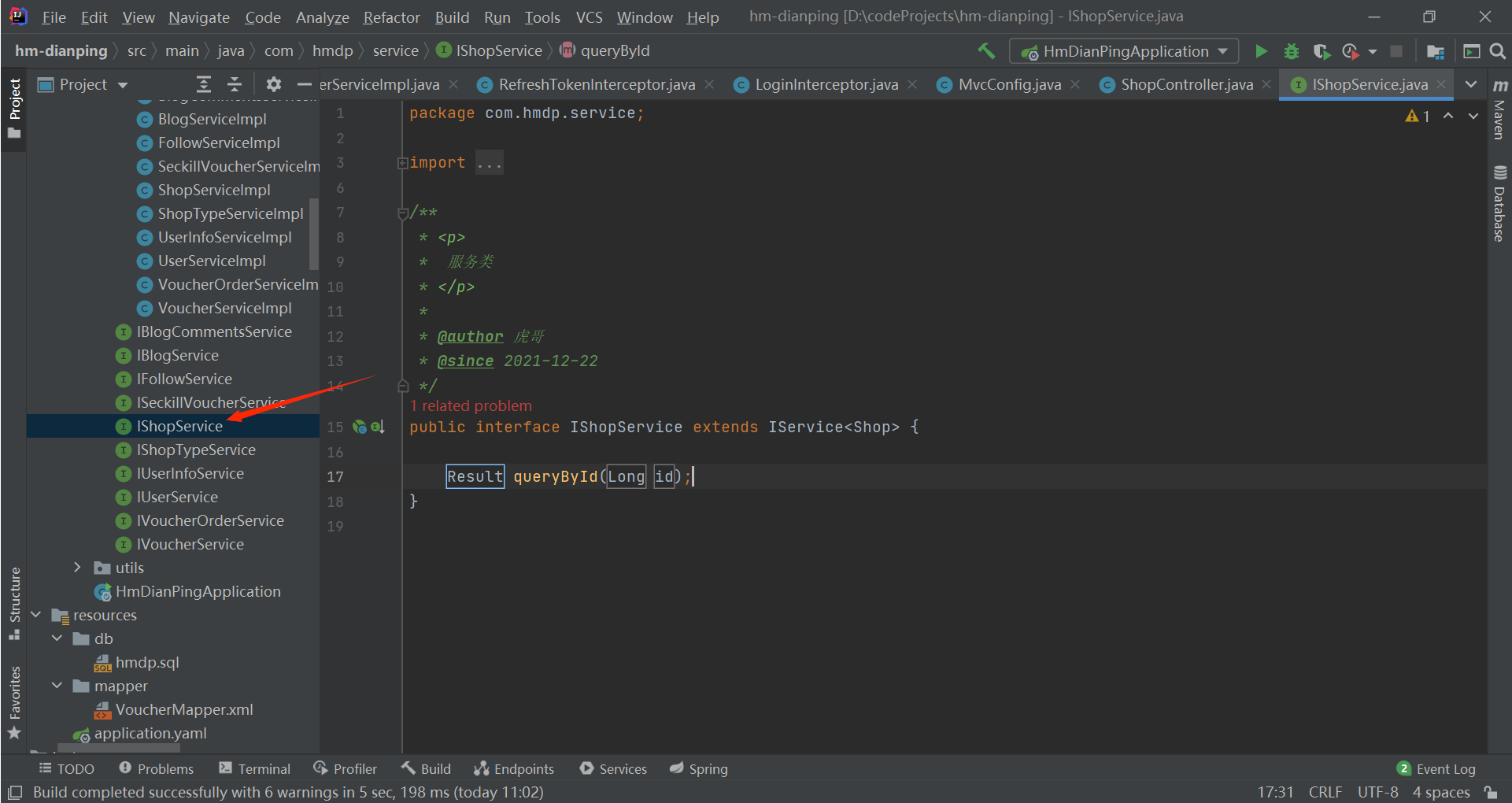
public interface IShopService extends IService<Shop> {
Result queryById(Long id);
}
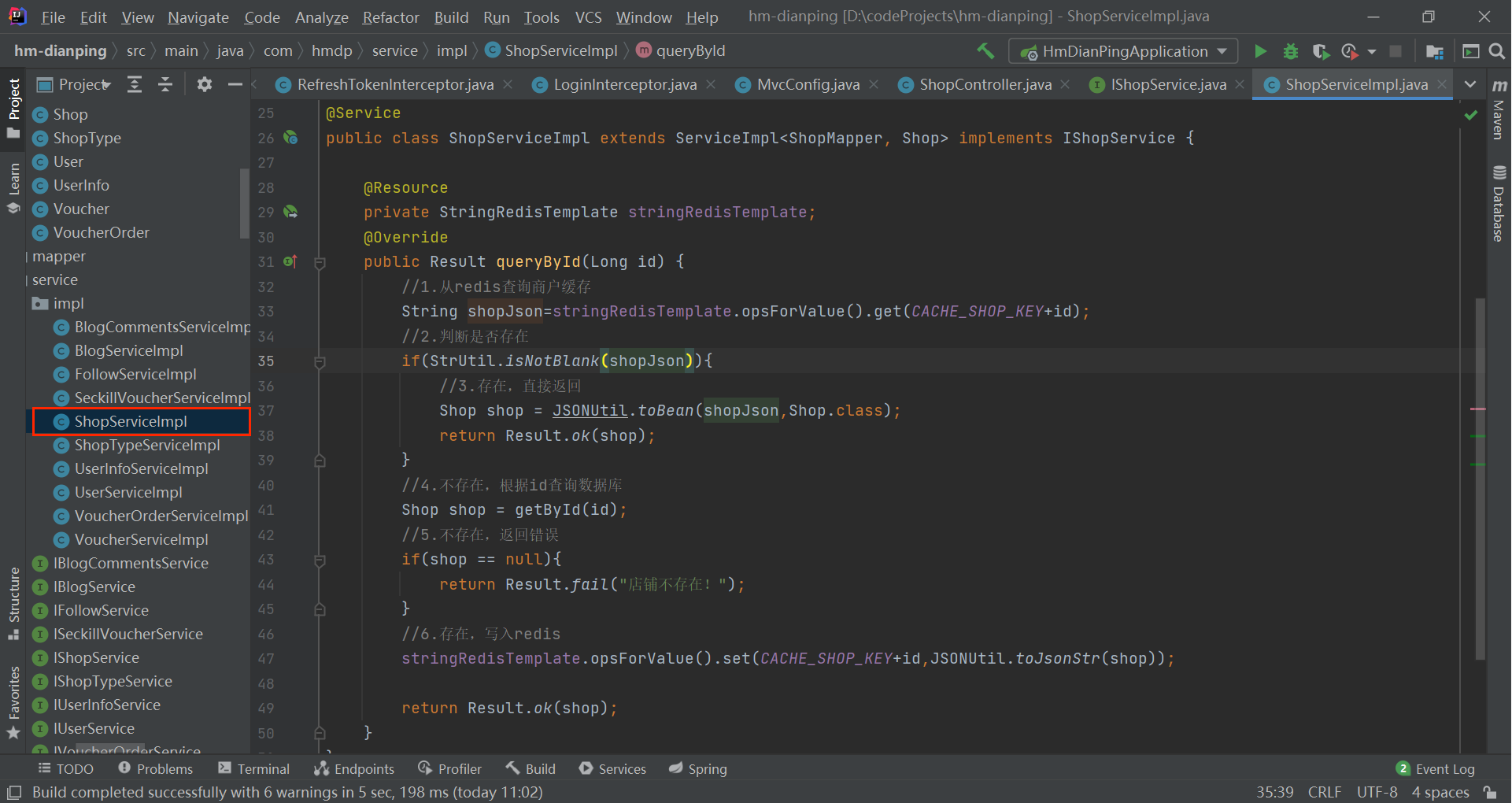
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
//1.从redis查询商户缓存
String shopJson=stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY+id);
//2.判断是否存在
if(StrUtil.isNotBlank(shopJson)){
//3.存在,直接返回
Shop shop = JSONUtil.toBean(shopJson,Shop.class);
return Result.ok(shop);
}
//4.不存在,根据id查询数据库
Shop shop = getById(id);
//5.不存在,返回错误
if(shop == null){
return Result.fail("店铺不存在!");
}
//6.存在,写入redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop));
return Result.ok(shop);
}
}
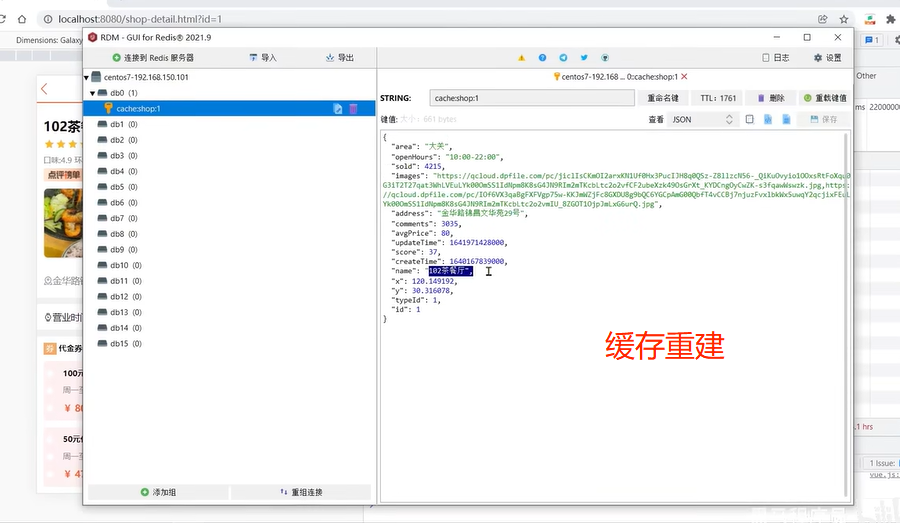
启动服务测试:
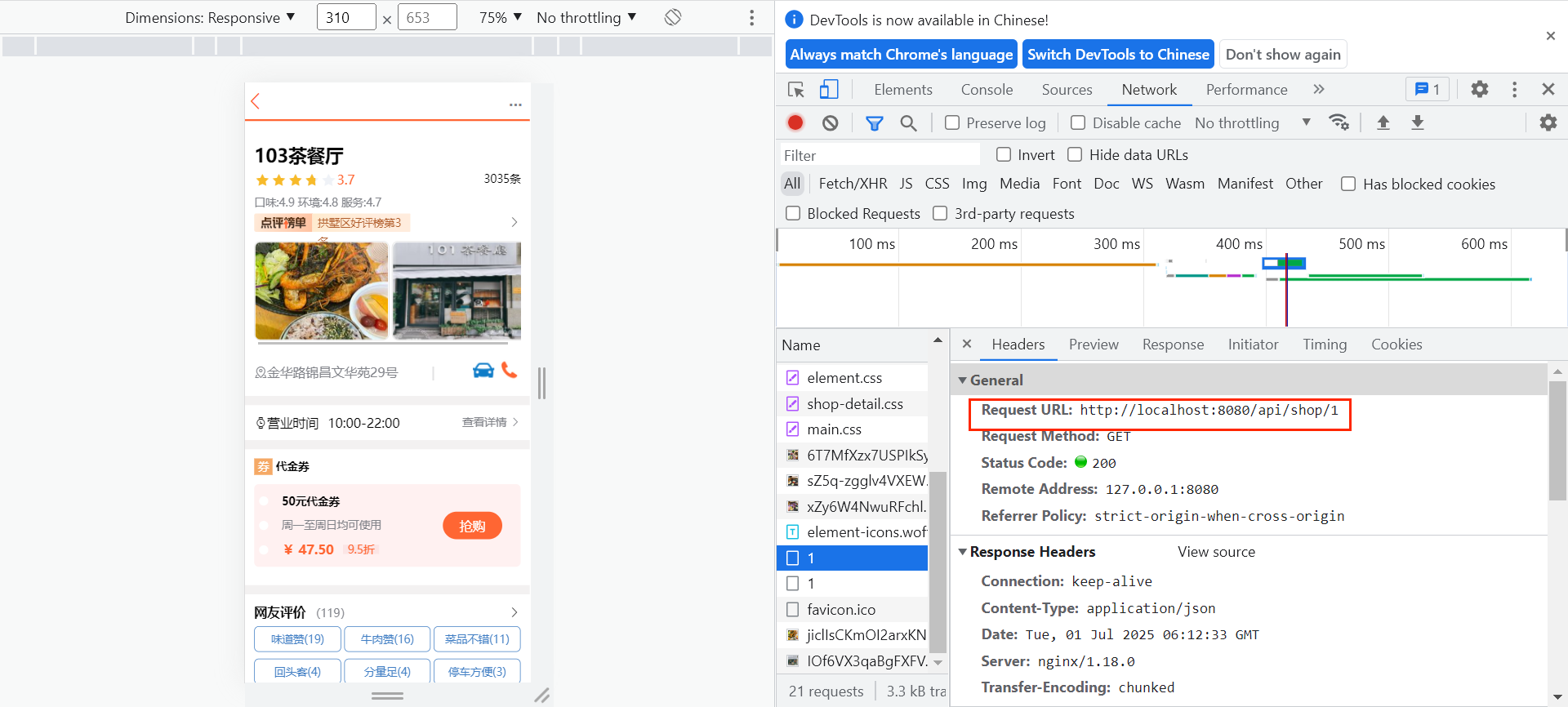
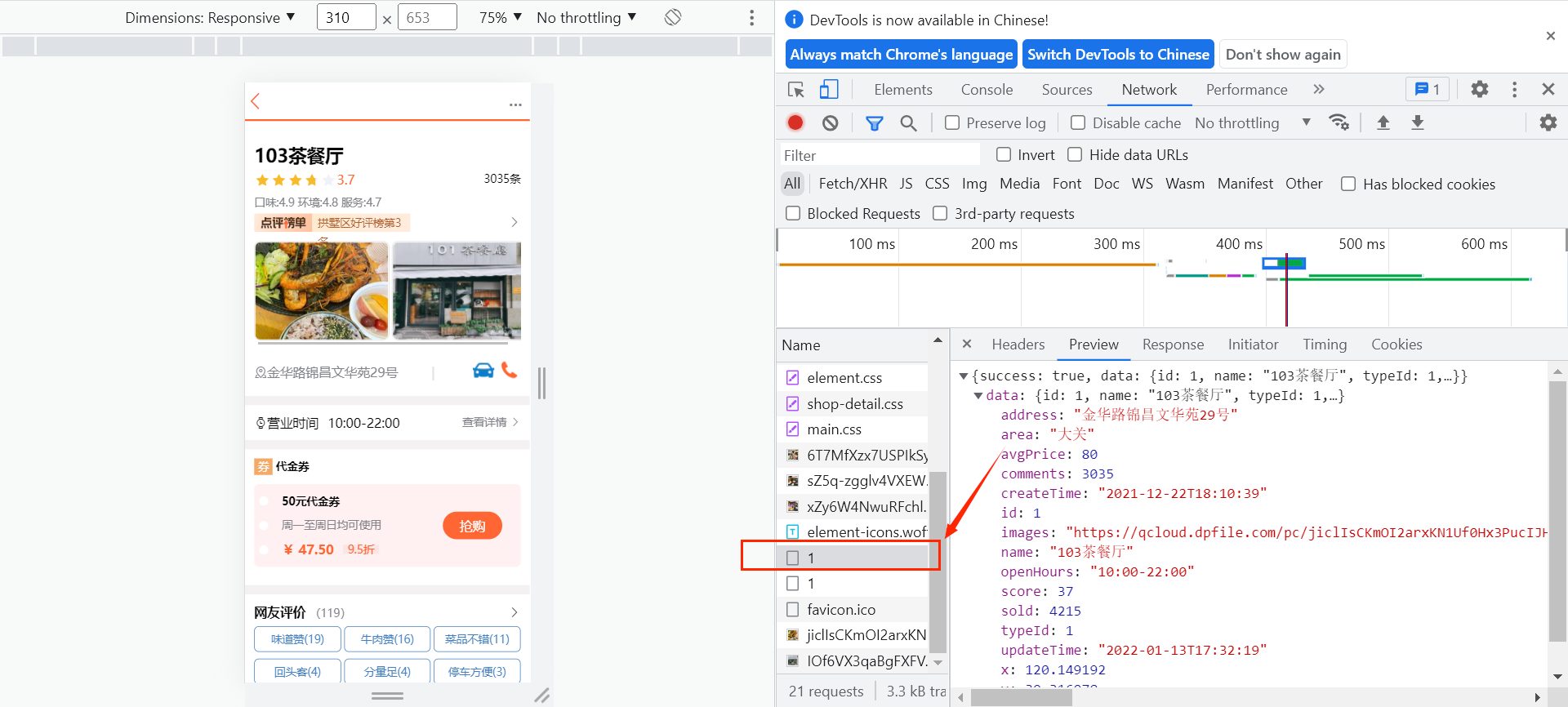
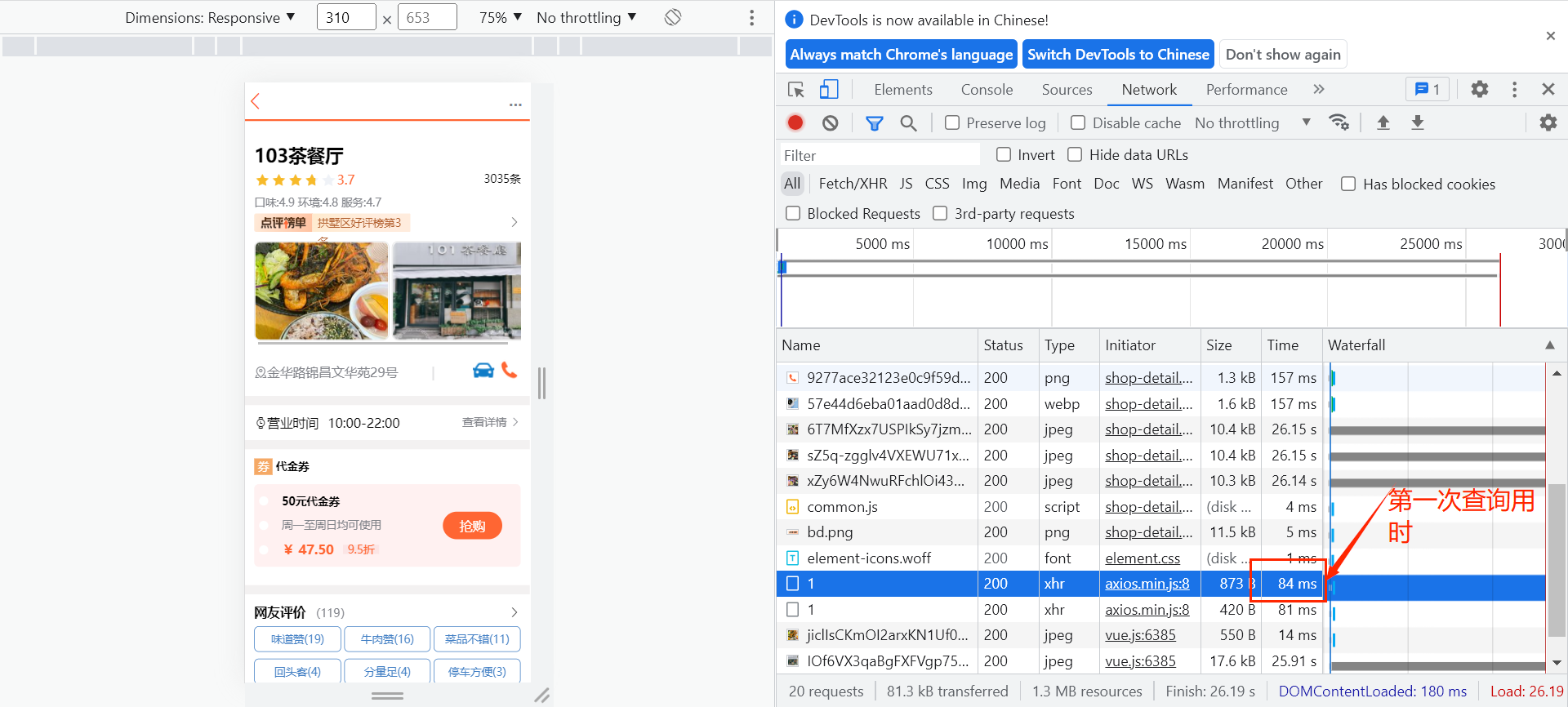
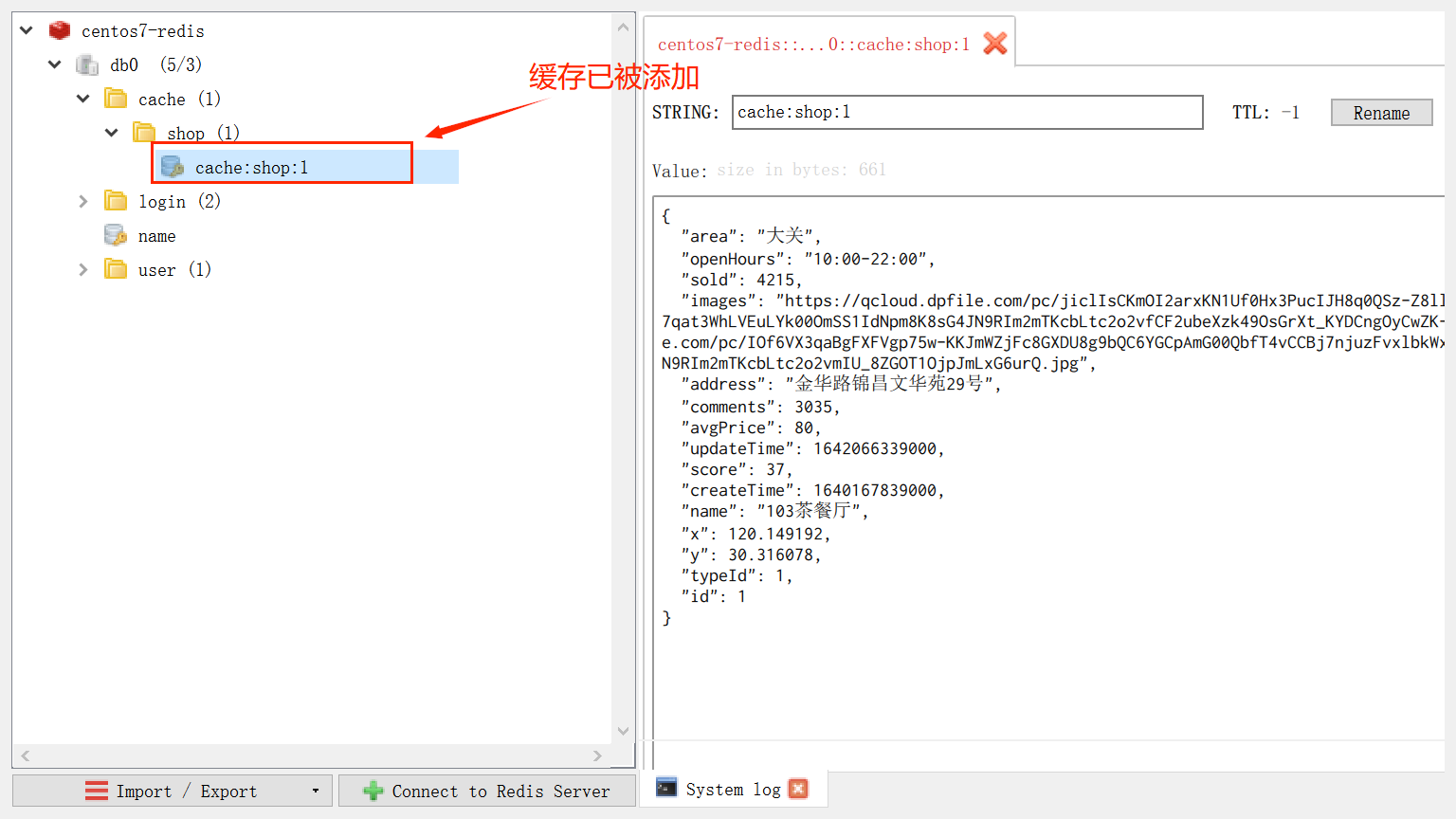
第二次访问:
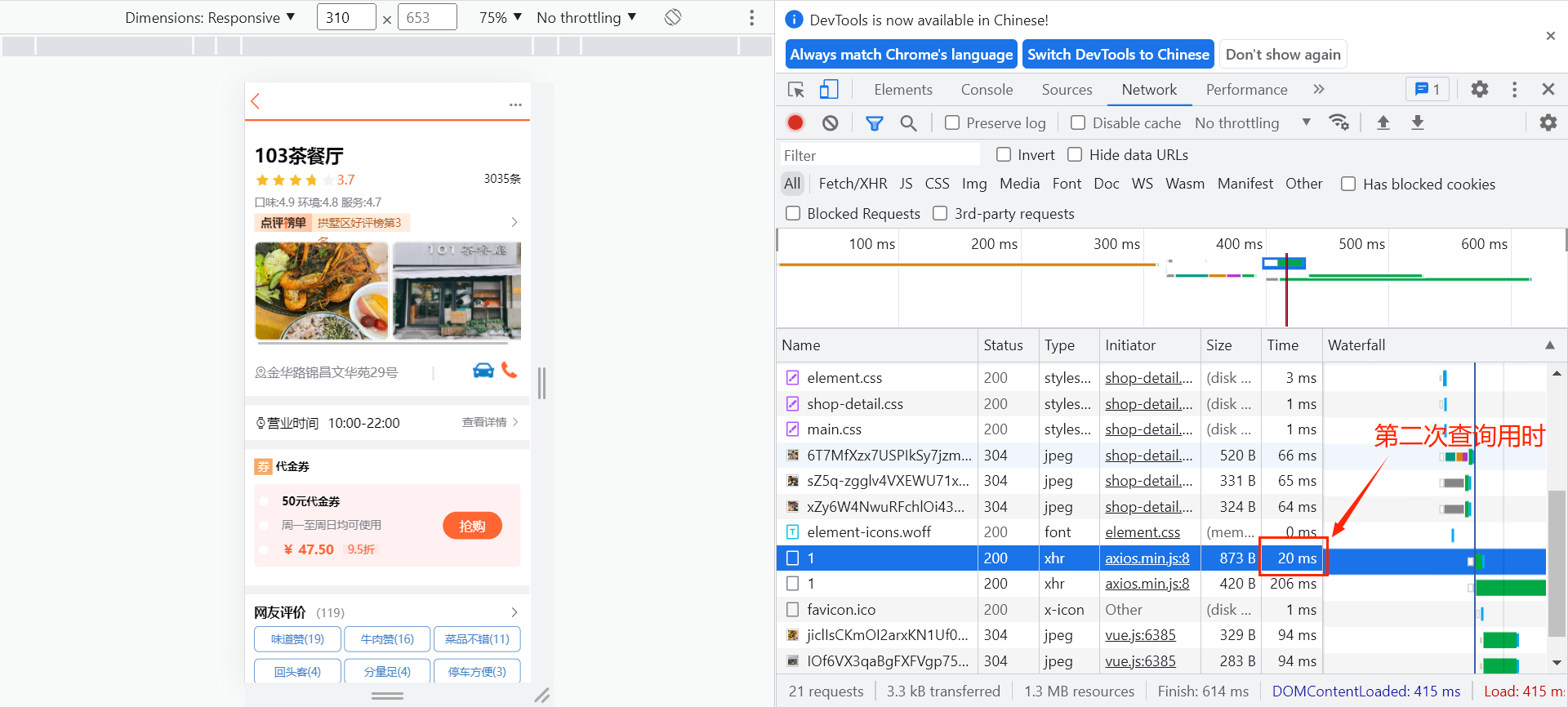
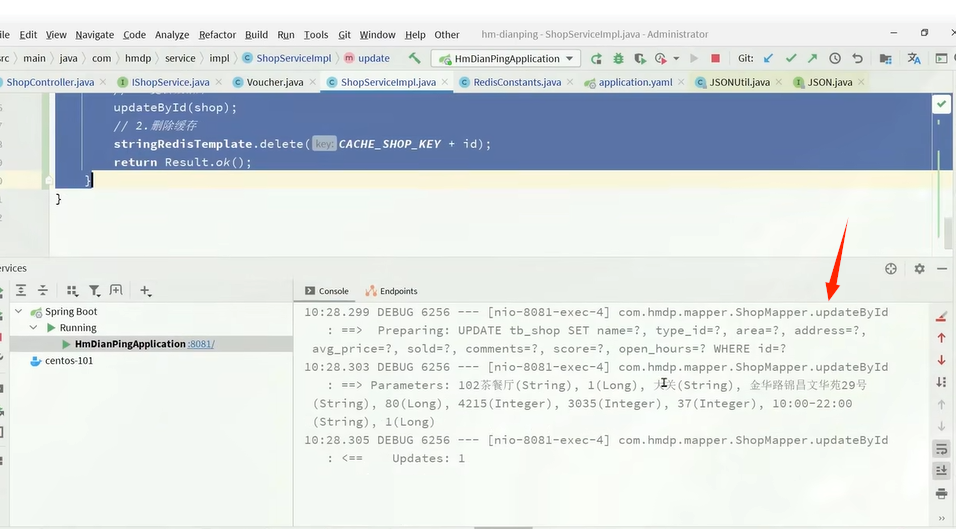
另外,可以通过DEBUG日志来查看是否执行了数据库查询操作。
二、缓存更新策略
2.1 三种缓存更新策略
缓存存在数据一致性问题,如数据库里的数据改变,缓存中的数据未及时更新。这需要在代码中解决该问题。
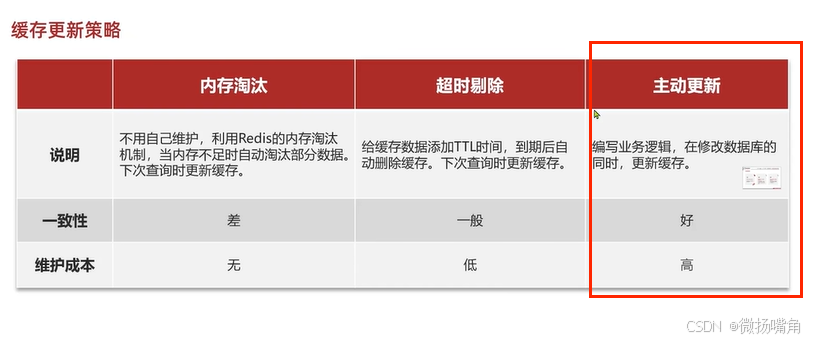
对于低一致性需求的数据可以选择“内存淘汰”和“超时剔除”策略,对于高一致性需求的数据可以选择“主动更新”策略,并以“超时剔除”为兜底方案。
2.2 主动更新策略(主流)
2.2.1 具体内容
主动更新策略又可以有以下三种实现方式:

企业中使用的最多的是01Cache Aside Pattern。

(1)选删除缓存的原因:若是有多次更新操作但是无查询,一直去更新缓存造成无效写操作,此时直接删除缓存,等后面有了查询再添加缓存的机制更佳。
(2)对分布式事务感兴趣可以去了解springcloud等微服务的知识。
(3)先删缓存还是先操作数据库的两种情况分析:
上图中的分布式事务的使用场景是两个业务在不同的机器上执行,如一台服务器更新数据库后利用mq机制让另一台服务器去完成删除缓存的操作,而为了保证操作的完整性,需要利用分布式事务的机制。但会存在一些问题。
2.2.2 问题
2.2.2.1 先删缓存再操作数据库
先删缓存再操作数据库的正常流程:
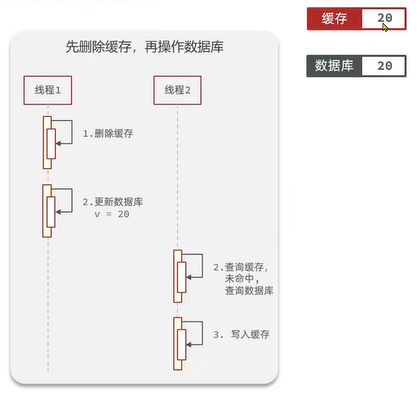
异常情况:
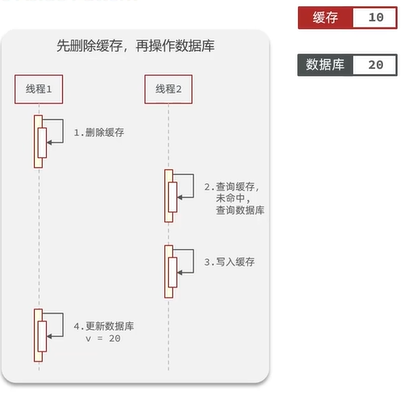
上图会导致缓存中的数据与数据库中的数据不一致。
2.2.2.2 先操作数据库再删除缓存
正常情况:
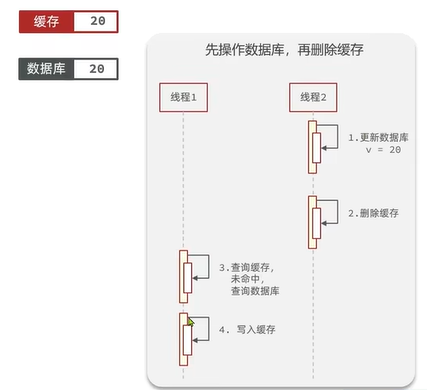
异常情况:
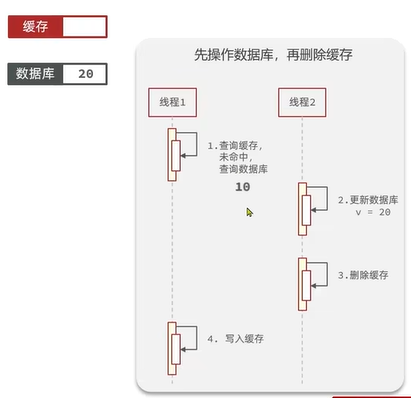
“先操作数据库再删除缓存”的异常发生的概率极低(更新数据库操作比读缓存还快),所以建议先更新数据库再删缓存的方案。
2.2.2.3 最终方案

2.2.3 代码实现
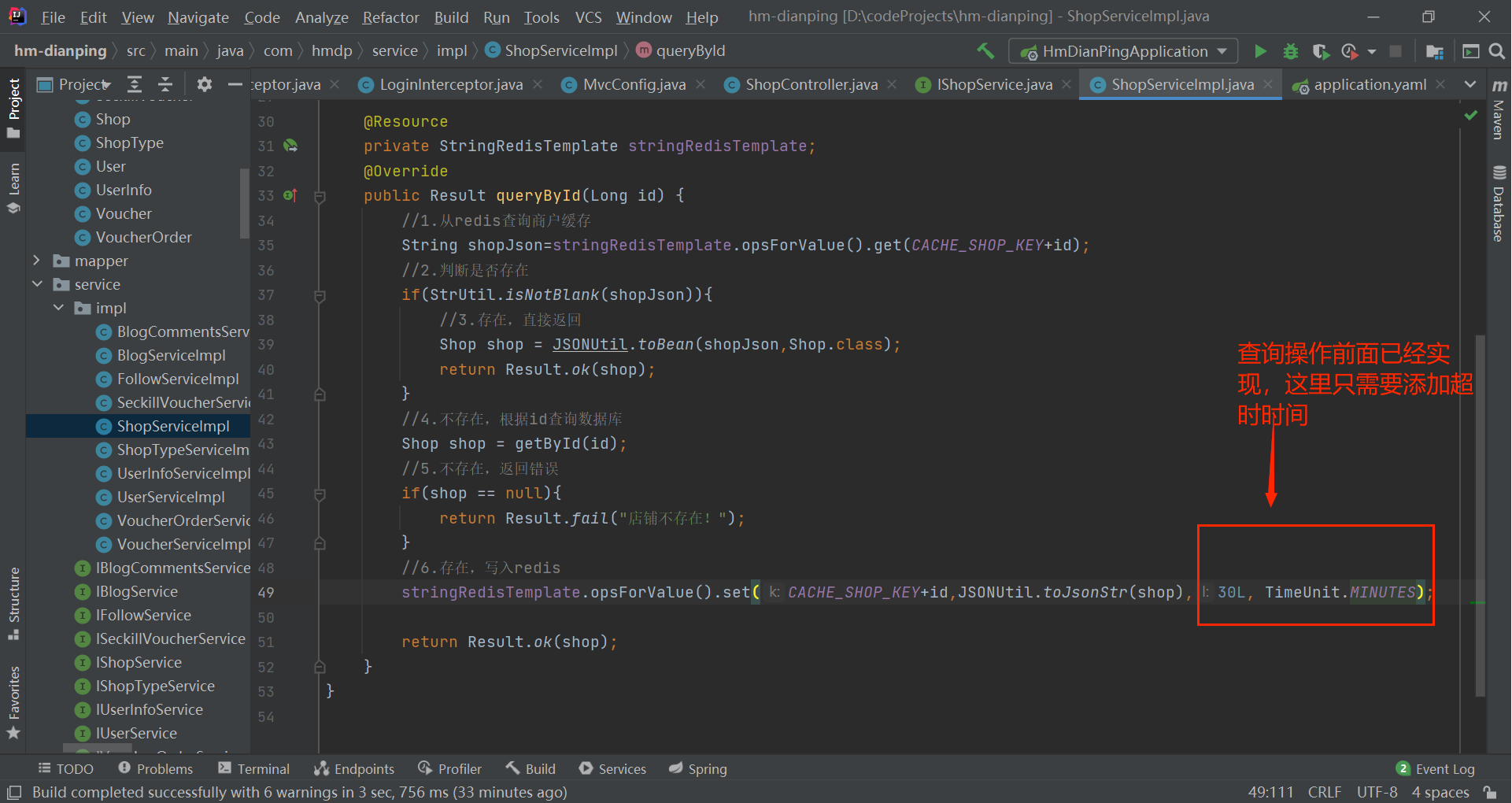
写操作换成主动更新策略:
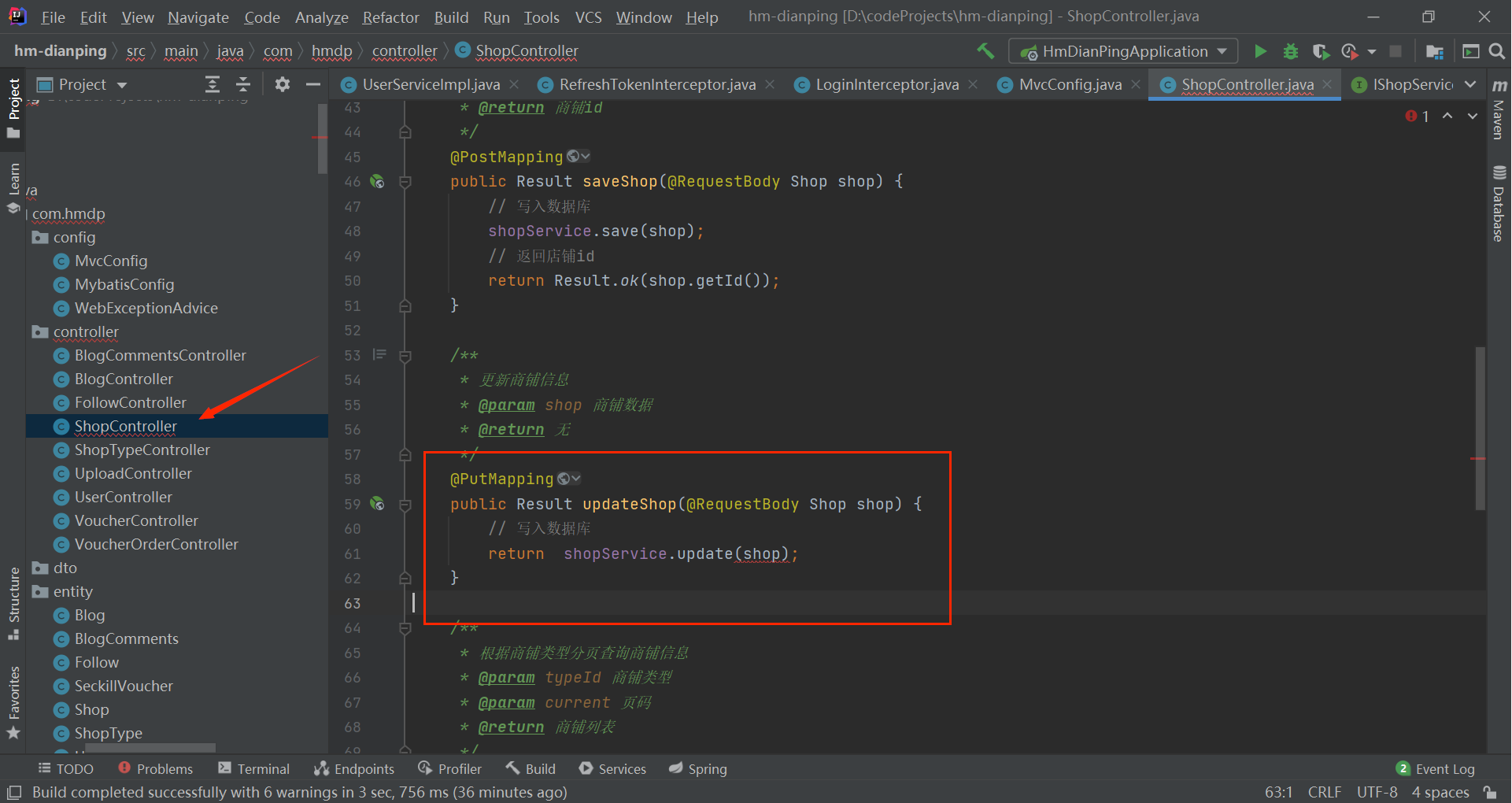
@PutMapping
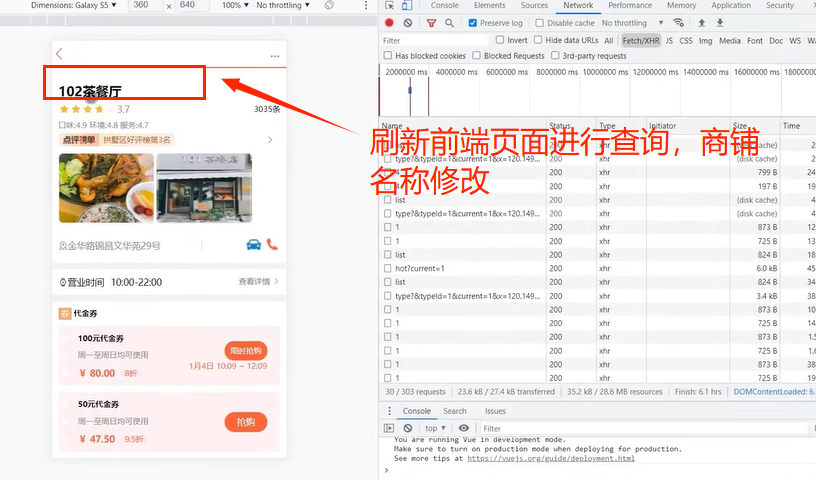
public Result updateShop(@RequestBody Shop shop) {
// 写入数据库
return shopService.update(shop);
}
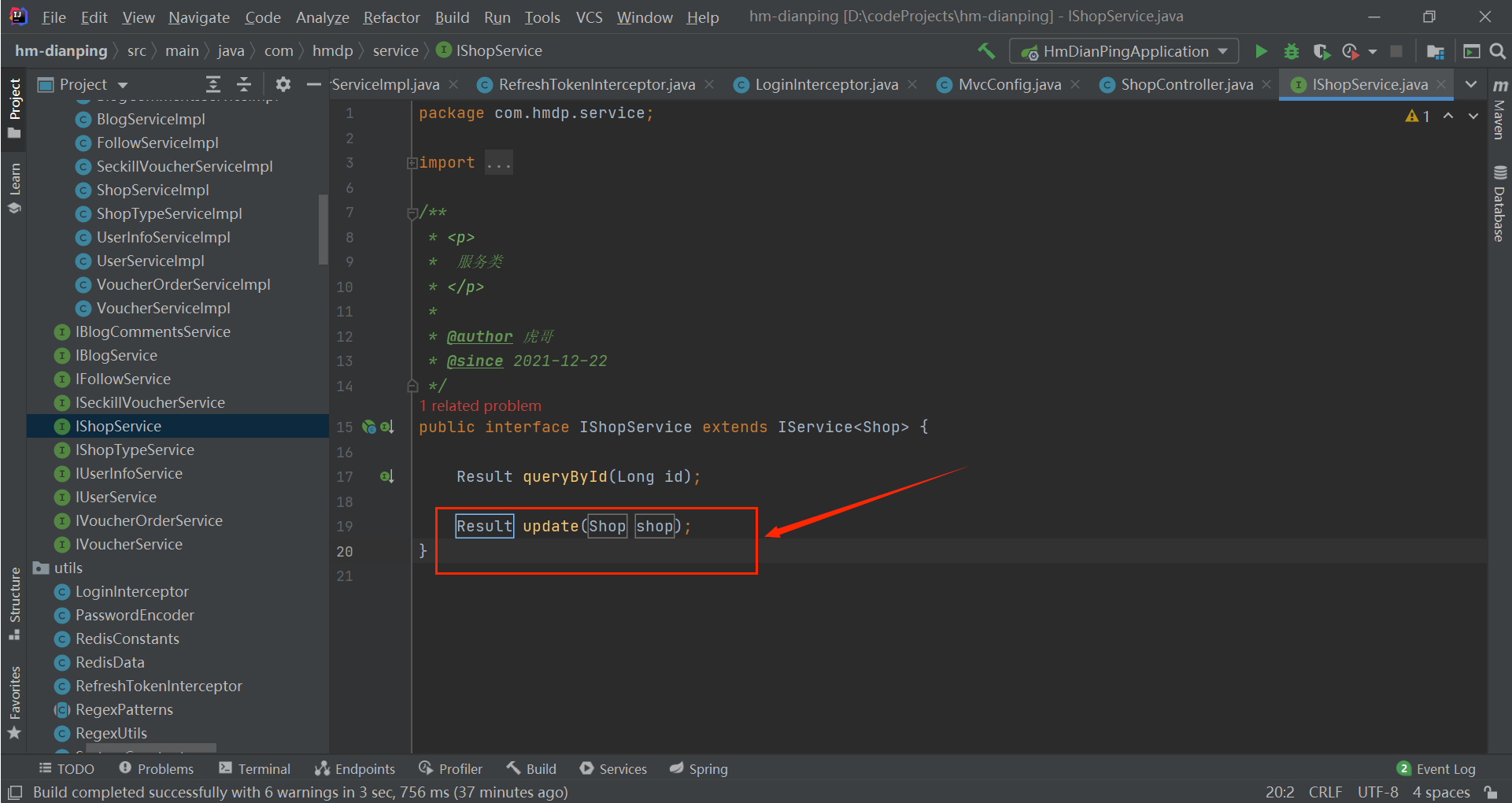
public interface IShopService extends IService<Shop> {
Result queryById(Long id);
Result update(Shop shop);
}
(使用@Transactional保证原子性):
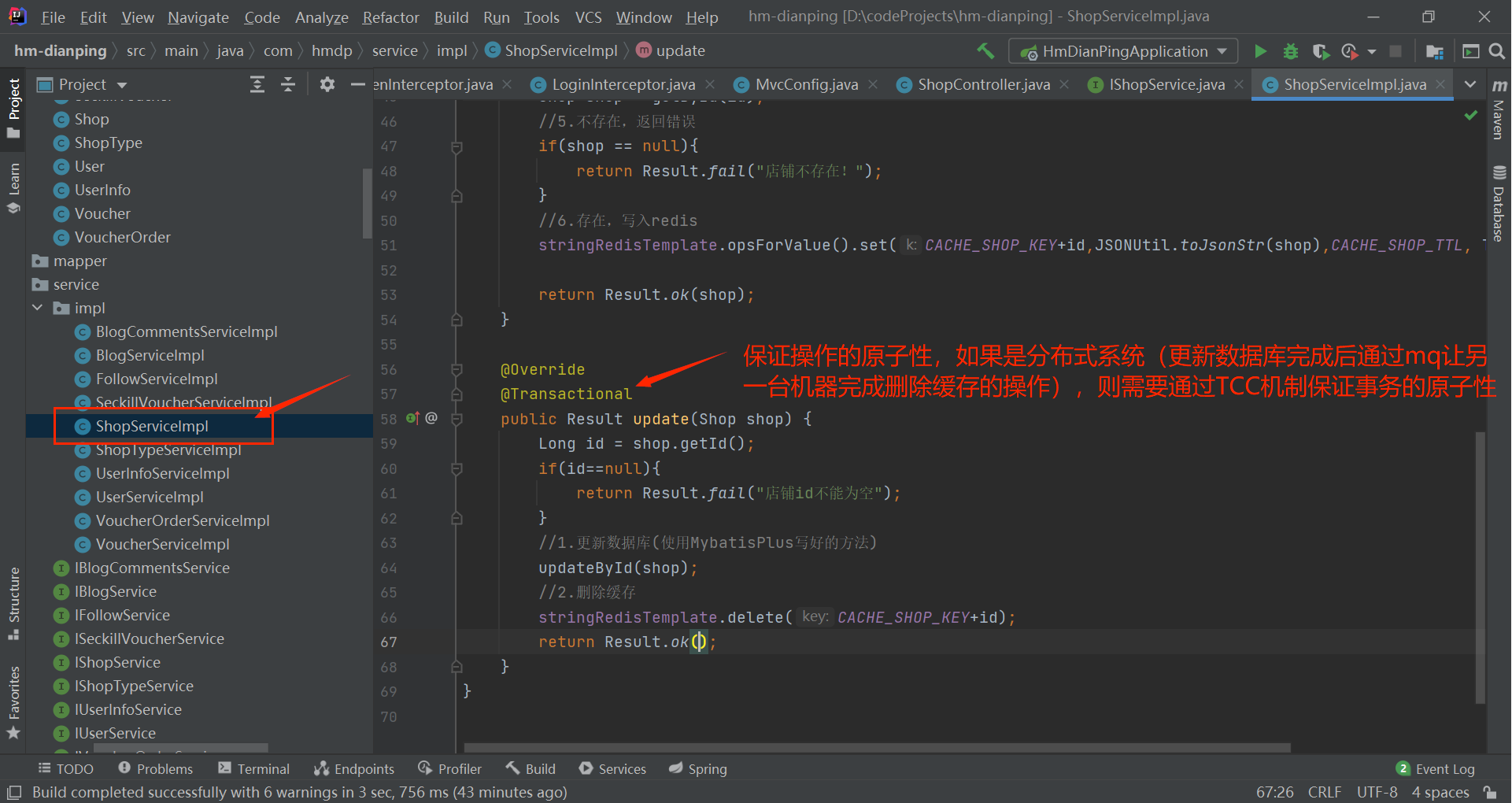
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if(id==null){
return Result.fail("店铺id不能为空");
}
//1.更新数据库(使用MybatisPlus写好的方法)
updateById(shop);
//2.删除缓存
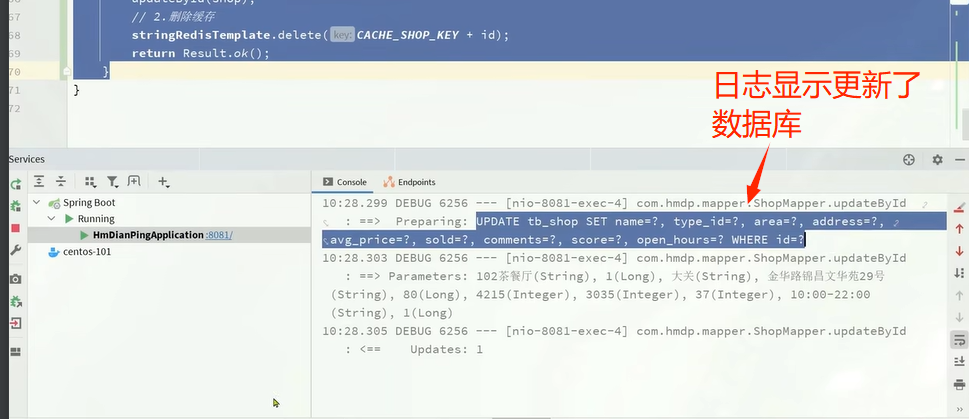
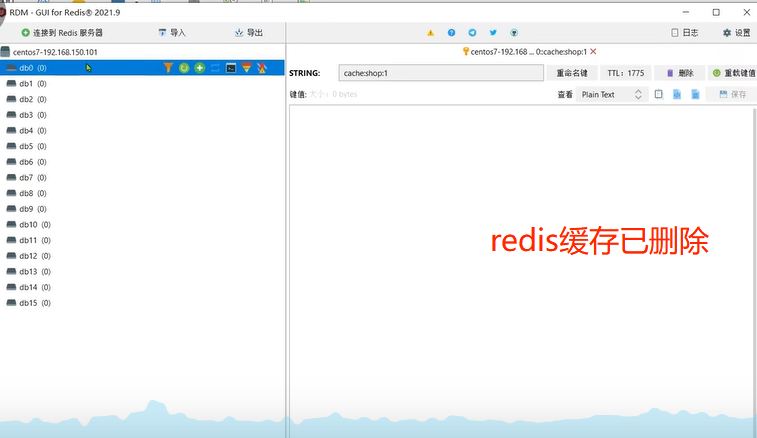
stringRedisTemplate.delete(CACHE_SHOP_KEY+id);
return Result.ok();
}
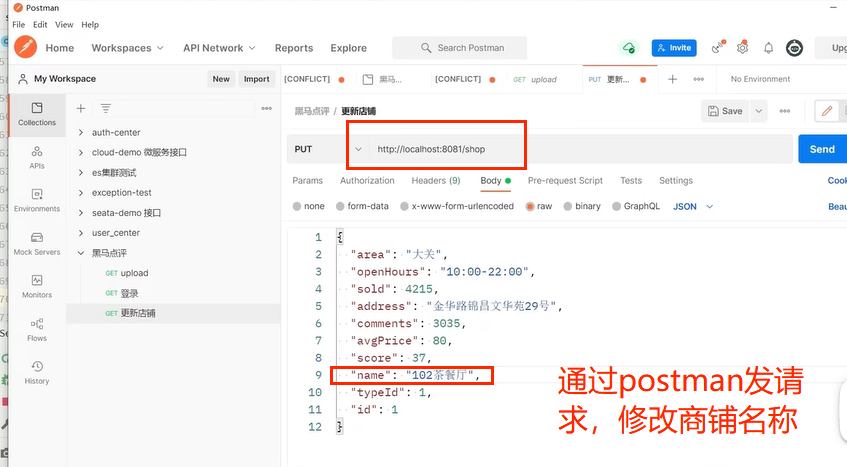
启动服务验证:

三、缓存穿透
3.1 概念
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打倒数据库。
3.2 解决方案
3.2.1 缓存空对象
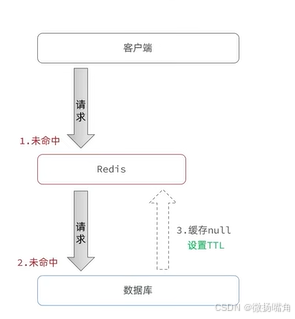

造成短期不一致的原因:没查到却保留了一个null缓存,后续插入一条数据后,在null缓存还未清楚前用户查到的还是null缓存。
3.2.2 布隆过滤
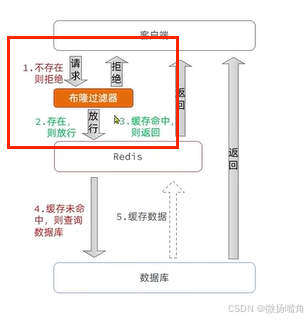
新增一个“布隆过滤器”,其他流程不变。布隆过滤器里并不是存储了数据库中的所有数据,而是有一个map数组,里面存的是二进制位,当要判断数据库中的数据是否存在时,并不是真的把数据存在布隆过滤器,而是把这些数据基于某种哈希算法计算出哈希值,然后将哈希值转换成二进制位保存到布隆过滤器中。注意,布隆过滤器是概率统计。当布隆过滤器返回不存在时那数据库必定不存在;当布隆过滤器返回存在时那数据库中不一定存在,也有一定的穿透风险。

3.3 代码实现
3.3.1 缓存空对象
方案调整如下:
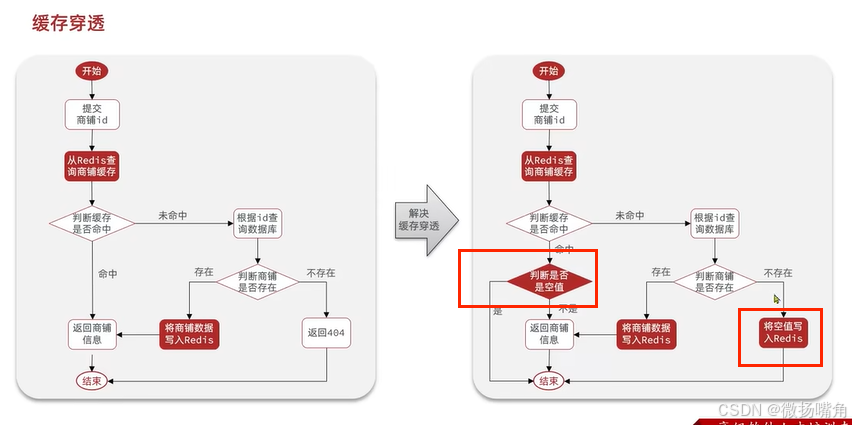
修改查询店铺信息的代码:
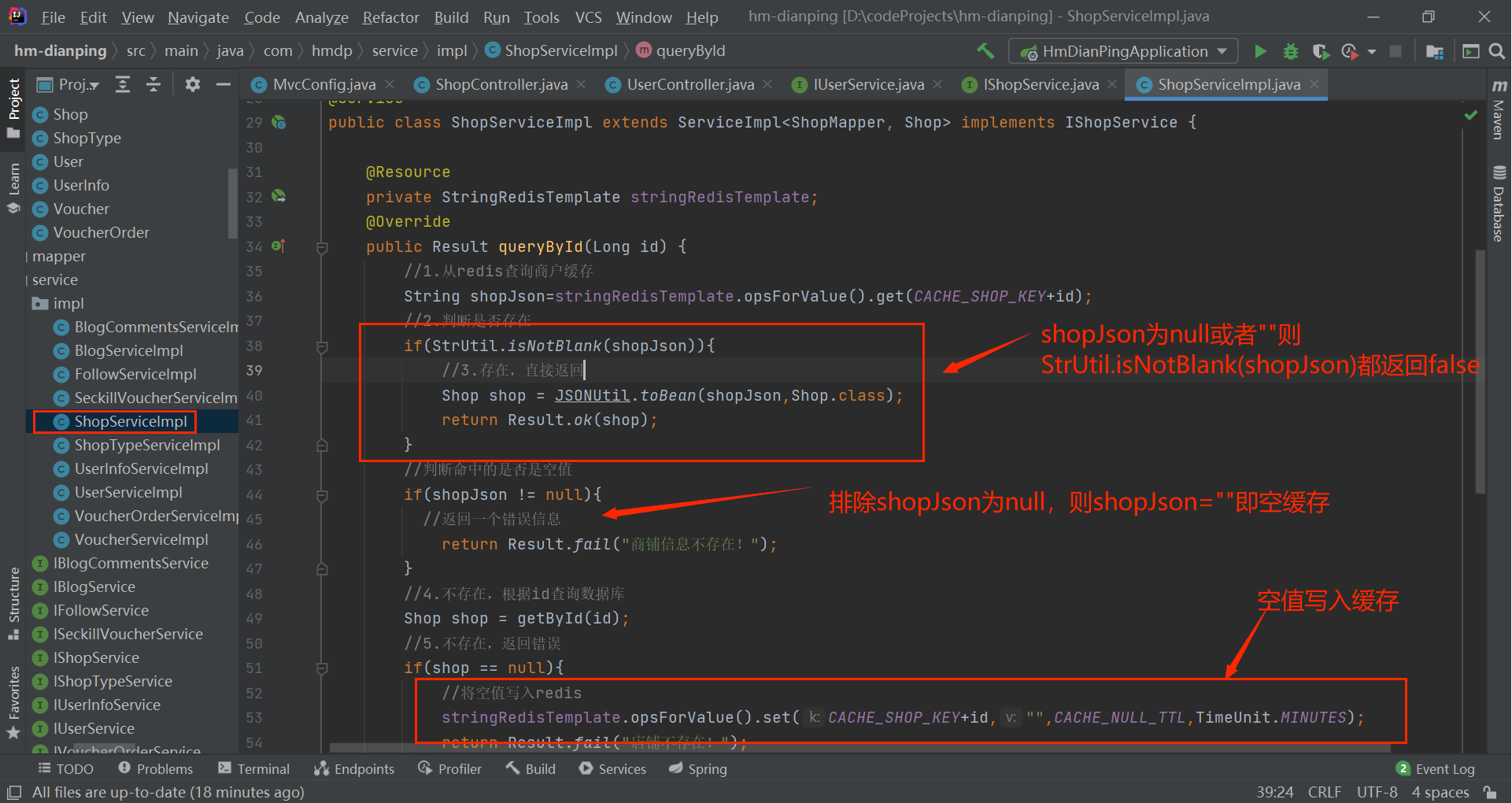
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
//1.从redis查询商户缓存
String shopJson=stringRedisTemplate.opsForValue 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









