






 文章详细解释了Java中创建对象的过程,包括内存分配、对象头的组成和作用,以及对象在内存中的存储布局。通过例子展示了对象头如何记录锁信息和哈希码。还讨论了对象定位的两种方式,并提到了不同垃圾回收器下对象的分配策略。最后,文章探讨了多线程环境下的DCL(Double-CheckedLocking)单例模式,强调了volatile关键字在确保可见性方面的重要性。
文章详细解释了Java中创建对象的过程,包括内存分配、对象头的组成和作用,以及对象在内存中的存储布局。通过例子展示了对象头如何记录锁信息和哈希码。还讨论了对象定位的两种方式,并提到了不同垃圾回收器下对象的分配策略。最后,文章探讨了多线程环境下的DCL(Double-CheckedLocking)单例模式,强调了volatile关键字在确保可见性方面的重要性。
今天的话题我们围绕一行短短的代码说起
Object o=new Object();
1.请解释一下对象的创建过程?
这个问题问的其实就是当我们new一个对象的时候这个对象是怎么创建出来的。当我们new一个Object,这个Object会诞生在内存里面。所以创建一个对象首先要在内存当中创建一块空间用于容纳对象,具体步骤我们来观察一下
public class Demo {
public static void main(String[] args) {
Object o=new Object();
}
}
我们先写一小段代码,然后观察他的class文件,再深入到class文件里面去深入观察这句话背后到底进行了哪些深入的操作。
运行主函数,打开bycode查看字节码文件
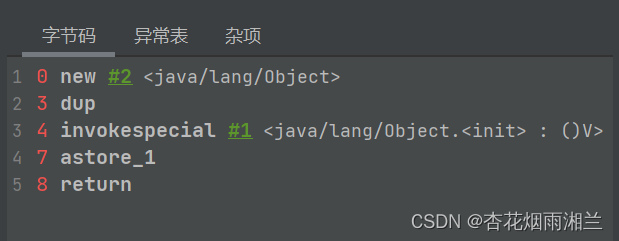
这个相当于 JVM的汇编语言,一共由五条指令构成。
接下来我们来看看整个对象的创建过程:

第一步是new,表示分配一块空间,那这个空间分配多大呢?很简单,T这种class占多大的类型就分配多大。 我们分配了一块空间之后,这个空间内部会有它的成员变量m。此时m值为0,如果是C/C++,我们给对象分配空间时会给m一个随机值,这个值是一个遗留值,可能是上一个程序用过这块内存遗留的值,从某种角度来说C/C++在这方面做的不是很安全。java的做法相当于拿到这块地方之后喊了一头牛把地重新耕一遍,即如果是基础数据类型全设成0,如果是指针或者引用类型,全设为null,相当于java分配对象比C/C++多了一个步骤,从这个角度来讲Java更安全,但同样运行速度也会比C/C++更慢。
第二步是duplicate表示在栈顶复制一个指针(这句先不讲)
第三步表示特殊调用,特殊调用了后面写的T.init方法,也就是构造方法。只有在T类型的构造方法执行完毕之后,m的值才是8。
第四步表示建立关联,将指针t指向建立的对象。指针存放在栈里,new出来的对象放在堆里。
2.对象在内存中的存储布局?
这个问题实际想问的是:我们new出来的对象在内存中实际上的大小是多少?每一位存放的都是什么信息?
2.1普通对象
当我们new一个普通对象,它由这四部分组成:
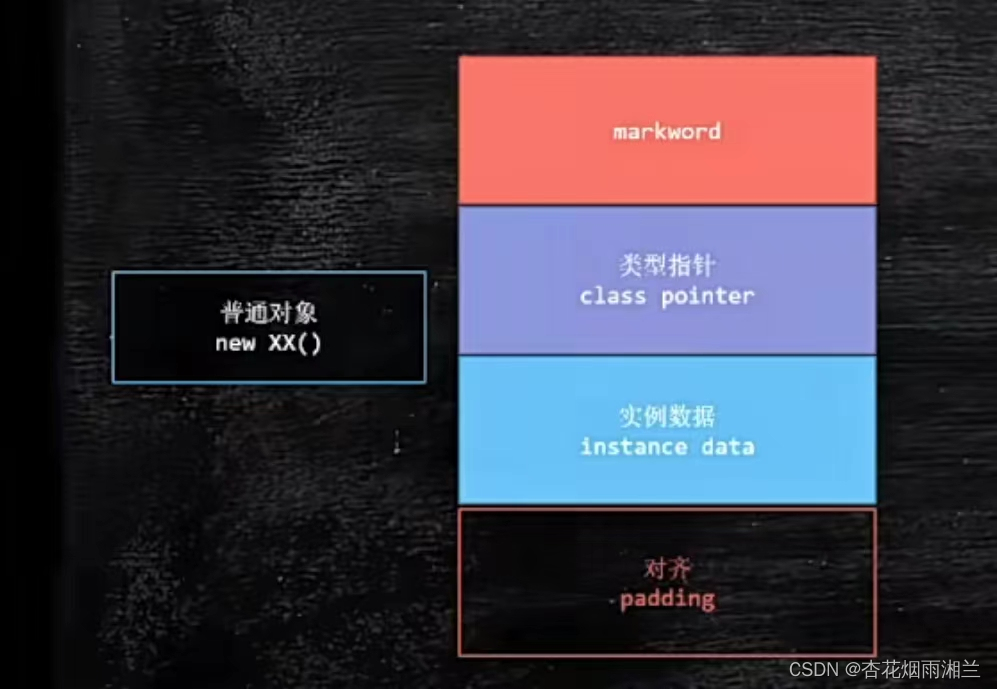
前两个部分称为对象头部 ,记录了对象的关键信息
第一部分叫markword,存放一些关于对象的元信息(解释性的信息)
第二部分叫做类型指针,指向这个对象的class,比如XX对象就指向XX.class。
第三部分叫实例数据,存放了成员变量
最后部分叫填充,如果整个对象所占空间不能被8字节整除,为了便于存取会被补齐到能被8整除为止。
第一部分叫markword,存放一些关于对象的元信息(解释性的信息)
3.Object o=new Object()在内存中占用多少字节?
我们使用JOL来探究一下内部结构:
import org.openjdk.jol.info.ClassLayout;
public class Main {
private static class T{
}
public static void main(String[] args) {
T t=new T();
System.out.println(ClassLayout.parseInstance(t).toPrintable());
}
}
注意要在maven项目的配置文件中引入JOL的依赖
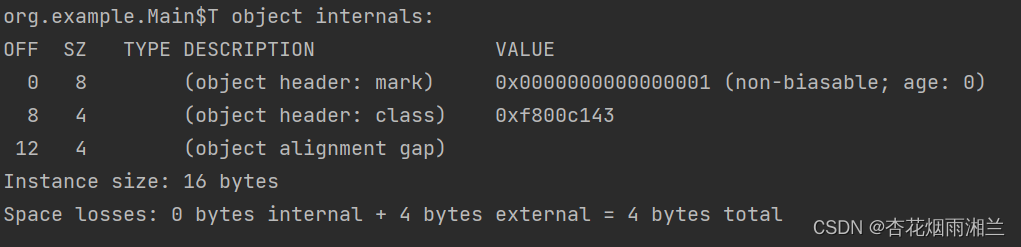
如图所示就是我们整个对象在内存中的一个过程。我们可以看到一个空的对象占了16给字节。前面12个字节是我们的markword,后面4给自己是我们的classpointer,也就是指向T.class的指针。
最后四个字节用于补齐。
对象头部一般装三类信息:第一类是关于锁的信息,第二部分是对象的hashcode,第三类是垃圾回收的信息。
那么问题来了,下面这个类占多少字节呢
private static class T{
int m;
boolean b;
String s="jdhklewjidhfljw";
}
对象头12字节,i那天字节,boolean1字节 不算字符串17字节,如果没有字符串的话应该是补齐7
位24字节,那么加了这么长一段字符串会有多少字节呢?
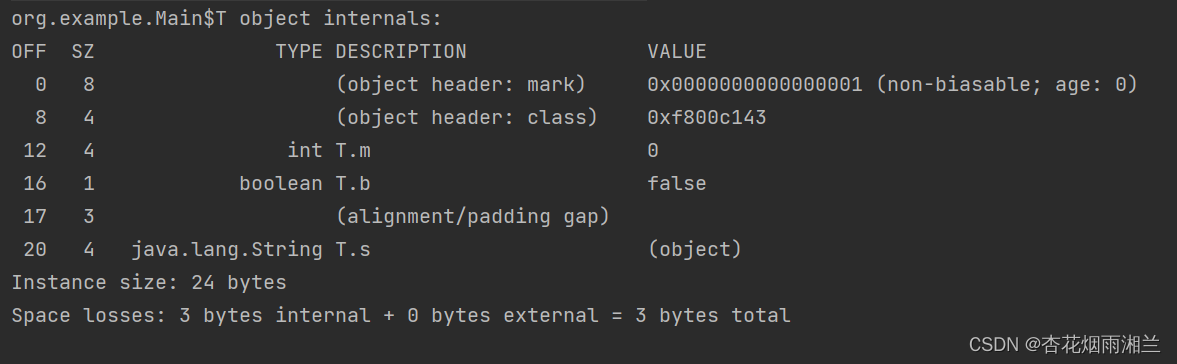
答案仍然是24字节
因为字符串并没有把整个字符串对象放进对象当中,放在对象当中的只有一个指针是,这个s占4字节,所以还是24字节。
当我们在对象中new一个String对象,存储的并不是字符串本身而是字符串的引用。这个引用指向的是常量池当中的字符串(也就是我敲的那一大串)。
我们刚刚说字符串的地址占4字节 ,实际上地址占几个字节是由操作系统的位数来决定的,我们所说的32位,64位操作系统指的就是在系统中指针的长度。
n位的操作系统就可以管理2^n个地址,32位的系统(比如WindowsXP)就可以管理2^32个地址,也就是4G个地址。
那我们JVM的操作系统是多少位呢?我们来打开命令行看一下

可以看到我的JVM是64位操作系统,一个64位操作系统理应可以管理2^64个地址,寻址空间是一个超级大的天文数字,那我们的指针应该是8个字节,可是刚刚我们看到的引用类型只有4个字节。

这是因为我们的JVM默认参数使用了压缩类指针,即UseCompressedClassPointers,以及压缩普通对象指针,即UseCompressedOops,Oops表示Ordinary Object Pointers 。也就是说我们看到的指针都是被压缩了,因为绝大部分的程序4g的空间已经完全够用了,所以在绝大多数情况下JVM使用的都是压缩指针。
如果我们的JVM需要管理大于32G的时候就不会使用压缩指针了,32G而不是4G,这是因为JVM管理内存的时候每一个地址并不是一位,而是一个字节。4字节的指针一共管理4G个地址,每个地址是8位,换算成内存也就是32G的内存。
4.对象头都包括什么?
我们先把刚刚T对象的结构标记在这里:

接下来我给t上一把锁
synchronized (t){
System.out.println(ClassLayout.parseInstance(t).toPrintable());
}
再运行观察对象内部:
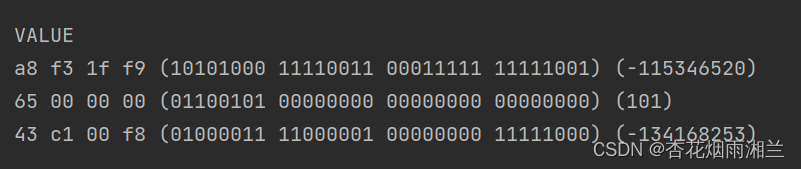
我们可以看到两者markword的区别,这就是记录了相关的锁信息,比如锁的类型,持有锁的线程id等等。
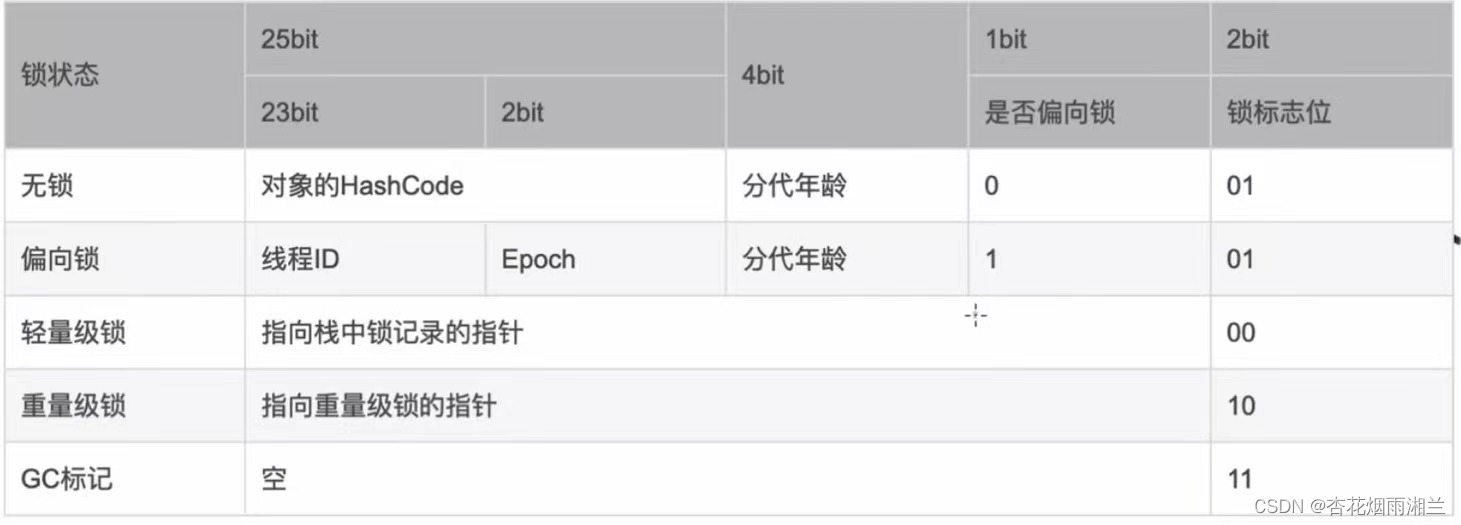
关于记录锁信息的具体情况可见下图:
我们在使用hashcode方法观察一次
T t=new T();
t.hashCode();
System.out.println(ClassLayout.parseInstance(t).toPrintable());
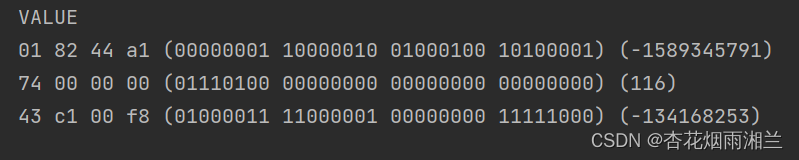
注意此时对象头再度发生变化,这就是对象的hashcode,只记录这一次
5.对象怎么定位?
这个问题问的是,当我定义一个对象,我怎么通过我的引用去找到内存当中的具体位置。
在JVM设计中,对象的定位有两种方式:句柄方式和直接指针
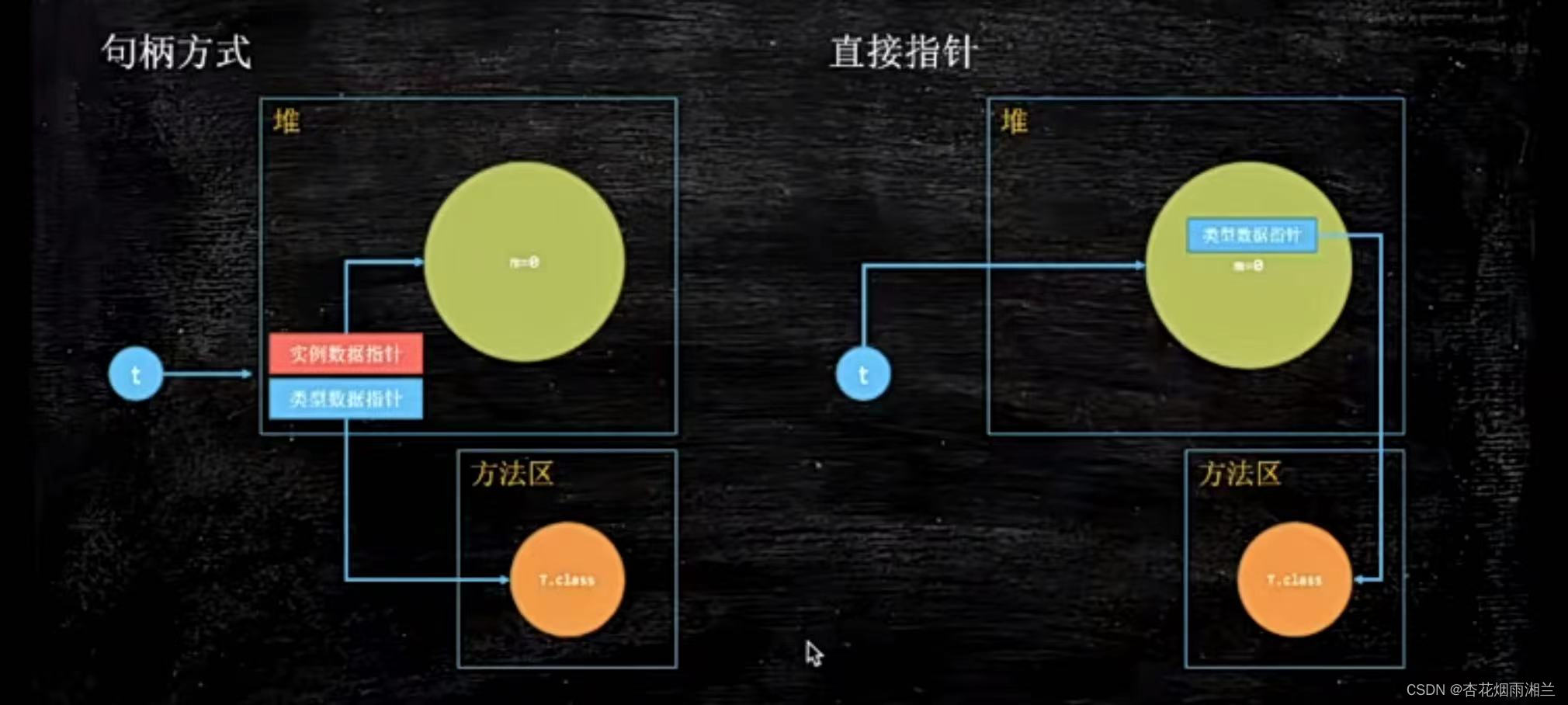
我们常用的HotSport用的就是直接指针的方式。 通过t可以直接定位到对象,对象内部有一个类型指针,指向具体的class
句柄方式的t指向了一个包含示例数据指针和类型指针的结构体,相当于一个过渡状态。
句柄方式的优点是对象比较小,因为对象内部没有class指针。缺点是每次访问对象都需要访问两次来分别找到对象本身和对应的class。
直接指针的优点就是可以直接访问,缺点就是对象比较大。但这不是核心的优缺点,核心的优缺点是和垃圾回收有关系的。因为垃圾回收会频繁的移动整个对象(详见垃圾回收的博客)如果一个对象不断地移动位置,那么t当中的指针就需要不断地进行修改。如果是句柄方式的话我们就不需要频繁的修改t。
6.对象怎么分配?
这个问题问的是,在不同的垃圾回收器下,这些对象分配到堆的哪部分里面。
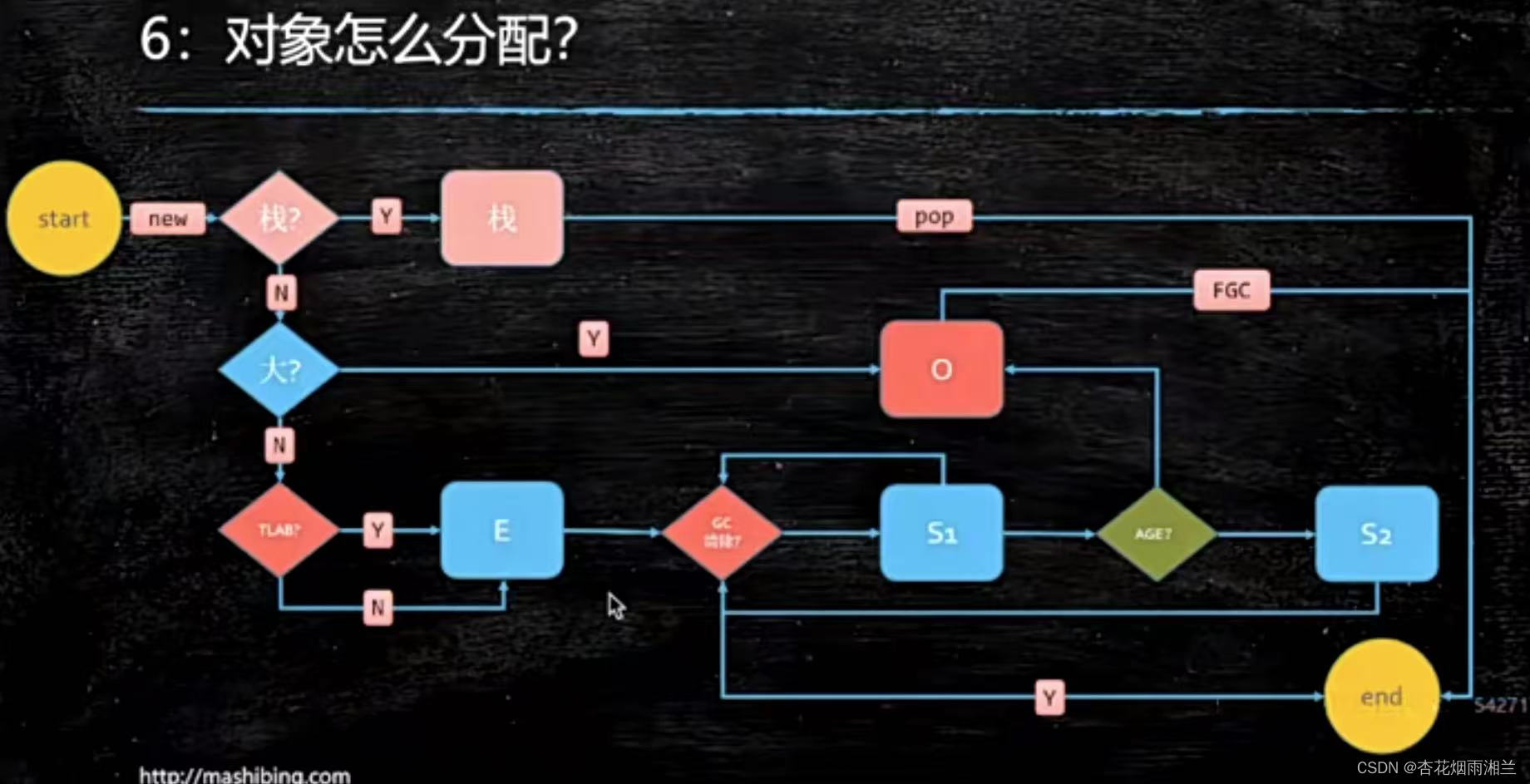
当我们new出来一个对象,JVM会首先将它分配到栈,栈上能够分配的就直接分配,回收的适合直接取出,最高速度非常快。如果栈上分配不了,JVM会观察这个对象占的空间大不大,如果是个头很大,会分配到老年代,需要经过FGC(FullGC)才能被回收掉。如果大小适中,会分配到年轻代之中一个单独的空间TLAB(Threadlocal Allocation Buffer线程本地分配缓冲区),如果线程本地能够分配下就往线程本地分,如果不能就放到年轻代(Eden)
7.DCL要不要加volatile?
DCL是Double-Checked Locking的缩写,是一种在多线程环境下使用的单例模式实现方式。在DCL中,为了保证只有一个实例被创建,需要使用双重检查锁定机制。
我们先来看这样一段代码:
import java.util.concurrent.CountDownLatch;
public class Demo03 {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
for (long i = 0; i < Long.MAX_VALUE; i++) {
x = 0;
y = 0;
a = 0;
b = 0;
CountDownLatch latch = new CountDownLatch(2);
// 用于同步两个线程的执行,确保 one 线程和 other 线程都执行完毕后,才会继续执行下一轮循环。
Thread one = new Thread(new Runnable() {
@Override
public void run() {
a = 1;
x = b;
latch.countDown();
}
});
Thread other = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
y = a;
latch.countDown();
}
});
one.start();
other.start();
latch.await();
String result = "第" + i + "次(" + x + "," + y + ")";
//System.out.println(result);
if (x == 0 && y == 0) {
System.out.println(result);
break;
}
}
}
}
在这段代码中我定义了两个线程,分别执行如下指令:
a=1;x=b;
b=1,x=a;
按照不同的执行顺序,最后的x和y可能有以下几种情况:

我们可以看到无论是哪种顺序x和y都不可能同时为0,只有如果两个线程的第二条指令同时跑到第一条前面才会发生这种情况,按理来说是不可能出现的。但是我们运行一下程序可以发现:
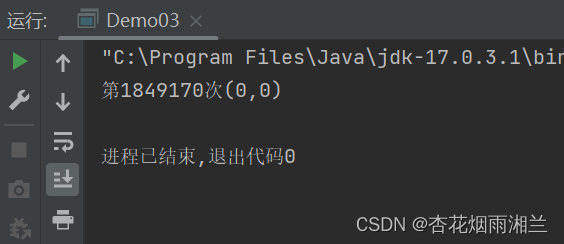
我们最终还是出现了x和y同时为0的情况,线程两句话并没有按照我们想象的顺序执行,这种情况我们称之为指令重排。
这是因为程序其实并不是严格按照我们看到的顺序在执行的,它的顺序是有可能进行替换的。原因是为了提高效率。
假设我们现在执行两个指令,第一个指令是CPU去内存当中拿数据,大概需要100nm,第二句话是CPU在本地的寄存器对变量进行++操作,大概需要2nm。如果这两句话严格按照顺序执行,CPU需要等待第一条指令去内存当中拿数据回来之后再进行++操作,此时我们一共需要102nm。但是为了提升效率,CPU可以在第一句话取回数据之前先执行第二句话,执行完成之后再执行第一句,总共需要100nm。这就是指令重排的最终目的。

当然,CPU并不是在什么情况下都可以进行这种指令的乱序执行,如上图左侧两个指令,如果交换顺序会导致最终x的值不一样,这种情况下就不可以乱序执行,但右侧这种情况完全不影响卒子红结果,所以对CPU而言是可以换序的。两句话能不能换,就看影不影响结果的最终一致性就可以了。但是这种情况在多线程的环境下就会出问题,就像我们刚刚的程序中展示的那样。
我们再回到问题,聊聊什么是DCL。
DCL是Double-Checked Locking的缩写,是一种在多线程环境下使用的单例模式实现方式。
我们先来写一个简单的单例模式:
public class Demo {
private static final Demo INSTANCE=new Demo();
private Demo(){
}
public static Demo getInstance(){
return INSTANCE;
}
public void m(){
System.out.println("m");
}
public static void main(String[] args) {
Demo m1=Demo.getInstance();
Demo m2=Demo.getInstance();
System.out.println(m1==m2);
}
}
这就是一个单例模式的简单实现,确保在程序运行期间只有一个Demo实例被创建。
在这里,Demo类的构造方法是私有的,因此外部无法直接创建Demo实例。而Demo类中定义了一个私有的静态final变量INSTANCE,它是Demo类的唯一实例。getInstance()方法返回了这个实例,确保在程序运行期间只有一个Demo实例被创建。
在main()方法中,通过调用getInstance()方法获取Demo实例,并将其赋值给m1和m2变量。由于Demo类的INSTANCE变量是静态final的,因此它只会被初始化一次,并且在类加载时就已经被创建。因此,m1和m2变量都引用了同一个Demo实例。最后,通过比较m1和m2的引用是否相等,可以验证Demo类确实实现了单例模式。
这种实现方式有一个缺点:这个对象在我们还没有使用的适合就已经被new出来了,那如果这个对象我们一直没用到这个空间就白浪费了。所以有了我们的第二种实现方式:
public class Demo01 {
private static Demo01 INSTANCE;
private Demo01(){}
public static Demo01 getInstance() {
if(INSTANCE==null){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
INSTANCE=new Demo01();
}
return INSTANCE;
}
}
这段代码实现了一种延迟加载的单例模式,即只有在第一次调用getInstance()方法时才会创建Demo01实例。睡1ms主要是为了暴露在多线程环境下的问题。
sleep(10)方法的作用是为了模拟多线程环境下的竞争情况,从而更容易观察到单例模式的效果。
具体来说,如果不加sleep(1)方法,多个线程可能会在同一时间内进入if(INSTANCE==null)语句块中,从而导致多个实例被创建,违反了单例模式的原则。通过让当前线程休眠一段时间,可以增加其他线程获取锁的机会,从而减少多个实例被创建的可能性。
需要注意的是,sleep(1)方法并不能完全消除多线程环境下的问题,因为在多线程环境下,可能会出现多个线程同时判断INSTANCE变量为null的情况,从而导致多个线程同时创建Demo01实例的问题。因此,sleep(10)方法只是为了让问题更容易被观察到,并不能保证线程安全。
这种方式比第一种优化了一些,但是这种优化不够好,因为这种方式在多线程的环境下有问题:
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
new Thread(()->{
System.out.println(Demo01.getInstance().hashCode());
}).start();
}
}
我在主函数中定义了100个线程,每个线程都打印单例的hashcode,运行观察结果:
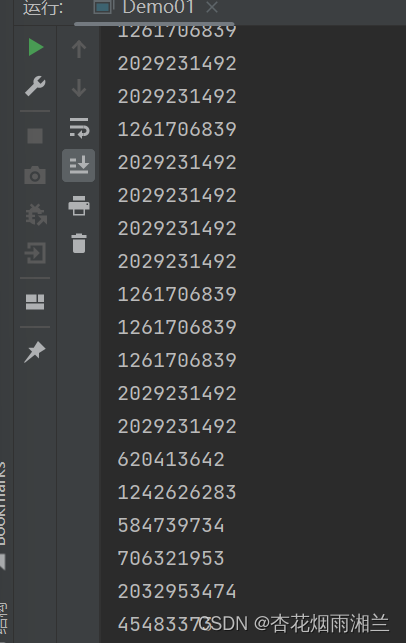
我们可以看到这里面的hashcode五花八门,也就是意味着它一定不是只有一个对象,原因很好理解,一个线程执行到if,发现等于空,进入sleep,第二个线程执行到if,发现依然等于空,继续睡眠,这就导致两个对象生成。
改进的方法有很多,最简单的就是上锁。
public static synchronized Demo01 getInstance()
如果我们把synchronized写在了方法上,这把锁就上在了我们当前的对象上,static的话就上在了class对象上,持有这把锁要执行的语句就是方法下面的所有代码。但在开发中有很多只读性的代码是没必要上锁的,所以这把锁的范围有一些太大了,这样有些影响效率,会导致并发量的降低。
为了解决这个问题我我们可以缩小锁的范围:
public static Demo01 getInstance() {
if(INSTANCE==null){
synchronized (Demo01.class){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
INSTANCE=new Demo01();
}
}
return INSTANCE;
}
这样性能就变强了一点点,但是这种写法依然不能保证在多线程环境下只有一个对象,我们再次运行主函数:
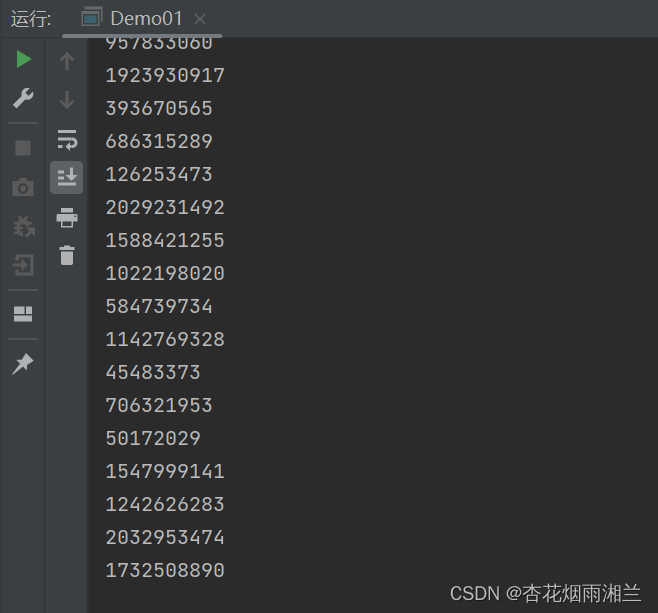
运行之后我们发现依然有好多种hashcode,说明还是生成了不同的对象。这就是多线程编程的麻烦之处,看上去我们上了锁,但这个所运用到不准确,还是去出问题。
当第一个线程获取锁进入睡眠之后,第二个线程经过if判断,等待锁释放,此时第一个线程睡眠结束创建对象,第二个线程进入睡眠,同样也会创造对象,所以还是不安全。
为了解决这个问题,我们可以采用双重验证的方法:
if(INSTANCE==null){
synchronized (Demo01.class){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
if(INSTANCE==null){
INSTANCE=new Demo01();
}
}
}
我们在上锁之后再判断一次是否仍然为空,这样就可以避免上一步的问题。这种方式又叫双重检查锁(Double Checked Lock)简称DCL 。
但是双重检查有一个很隐蔽的bug,理解这个问题需要我们回想一下前面对象创建的过程。
public static Demo01 getInstance() {
if(INSTANCE==null){
synchronized (Demo01.class){
if(INSTANCE==null){
INSTANCE=new Demo01();
}
}
}
return INSTANCE;
}
现在我们有两个线程,一个线程进入if判断,上锁,再判断依然等于空,到这里都没有问题。接下来,线程1开始new对象,我们之前见过new对象由这么几步构成:
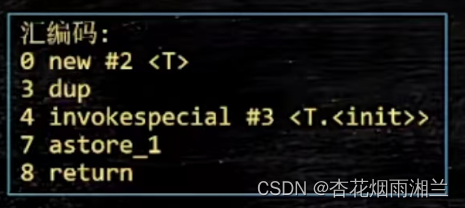
0 new #3 <T> //开辟空间
3 dup
4 invokespecial #4 <T.<init> : ()V>//调用构造方法
7 astore_1 //引用
8 return
想象这么一种情况:如果在执行invoke和astore指令时发生了指令重排,就会发生INSTANCE指向了这个刚被new出来空间但是还没调用构造方法的对象,指向了这个穿衣服穿了一半的对象。此时第二个线程正好执行到第一个if判断,发现此时INSTANCE不为空,直接引用穿了一般衣服的对象拿去用了。虽然这种情况可能程序跑一年都遇不上一次,但是一旦遇到了可能调一年也调试不出来。
这就是DCL内部的问题,我们可以加volatile关键字来解决指令重排的问题,volatile有一个作用叫做禁止重排,用于解决多线程环境下指令乱序执行的问题。(单线程底层也会乱序执行,但是不会影响结果)
我们把CPU比作一个奶茶店,不同的指令就相当于不同的顾客排队买奶茶,但是总有的顾客不守规矩想要插队(指令重排),这种问题如何解决呢?原理很简单,在两个顾客之间插一堵墙,顾客买完奶茶之后再把这堵墙拆掉,放下一个人过来。
这种机制在底层被称为屏障,它是一种特殊指令,称之为屏障指令,当CPU看到这种指令的适合,就一定不会把前后的顺序换掉,一定会把前面的执行完再执行后面的指令。这种指令再不同CPU是不一样的,在JVM中这种虚拟的屏障指令分为这几种:

Load代表读,Store代表写,LoadLoad指的是我的第一条是读指令,第二条也是读指令,如果中间有一条LoadLoad屏障指令 ,那么这两条load就不能换顺序。

当我们使用volatile修饰一个变量,那么所有关于x的写操作,在前面都有一个StoreStoreBarrier(前面的写都给我写完),后面都会有一个StoreLoadBarrier(只有我写完了,其他人才能读)。所有关于x的读操作,后面都会有一个LoadLoadBarrier(等我读完别人再读)和一个LoadStoreBarrier(等我读完别人再写)。
所以,在Java中,DCL的实现通常会使用volatile关键字来确保多线程环境下的可见性。具体来说,将单例对象的引用声明为volatile类型,可以确保在一个线程修改了该引用后,其他线程能够立即看到这个修改。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









