






 本文探讨了Records与OutputFormat在数据处理中的作用及其差异。详细分析了二者在数据分区与输出过程中的执行机制,并通过实验验证了它们之间的优先级关系。
本文探讨了Records与OutputFormat在数据处理中的作用及其差异。详细分析了二者在数据分区与输出过程中的执行机制,并通过实验验证了它们之间的优先级关系。
Partition分区
Partition是用来指定分区规则的,也就是指定shuffle阶段的如何分区,最后按照指定分区会输出和分区个数相同个数的文件
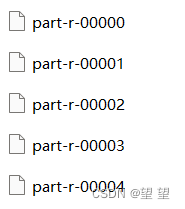
以达到不同数据的归并的效果
OutputFormat输出
OutputFormat可以定义输出路径指定输出文件,及输出规则。
也就是说其实我们也可以使用OutputFormat自定以达到对输出内容的文件自定
问题引出
两者的执行阶段和机制都不同但是对于指定分类数据文件的效果是相同的,都可以完成这种需求 那么我同时执行这两个要求最后是谁优先呢?
于是我带着疑问同时设置分区规则,也定义了输出规则,执行

与只定义输出规则结果相同,那么由此推测出,输出规则是具有较大优先级的
那么既然如此,那为啥还需要有分区规则呢?
个人理解如下
因为分区实现其实是提前与Records的 ,发生在shuffle阶段的,也就是说有部分需求是需要我们在Records之前就分好区的,因为我们知道Records在处理数据的时候是拉取相同分区数据进行处理的,那么这里就出现了两者功能的差异性,所以Records的存在是有必要的
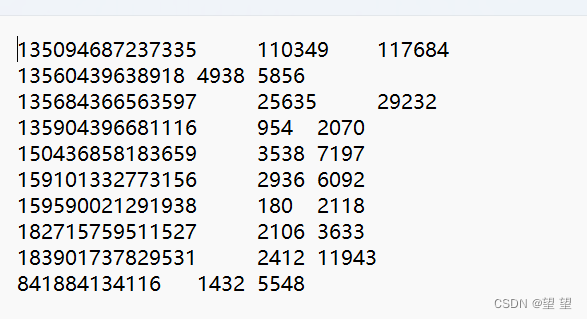
而后我打开数据发现!!!执行同时执行数据最后会缺少数据!!!
使用分区
未分区
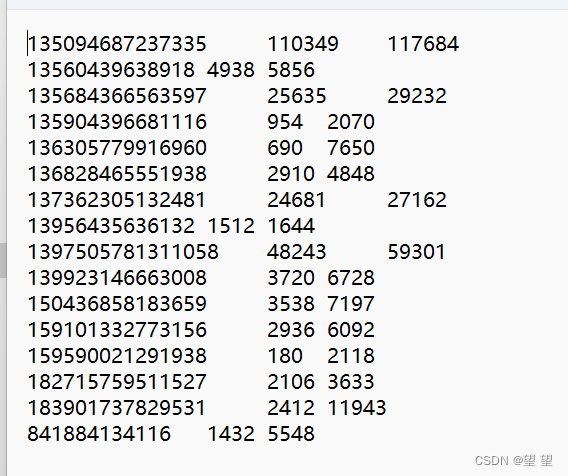
这是为什么呢?
原来每个Records执行完就会调用OutputFormat进行输出,因为我的输出路径是固定的,每次Records调用完之后就会发生覆写,那么我们之前分区内容就全数丢失了。所以才会产生我们看到的数据丢失事件,而后我们对输出路径进行个性化就可以解决了。
以上就是我对Records和OutputFormat理解了
如果有错误欢迎留言纠正

















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









