







以下是数据结构里快速排序的设计思想和代码实现:
算法设计思想
取出序列里某个值为基准值,以基准值为分割点,将待排序序列划分为左右两个子序列。左子序列的所有元素都比基准值小,右子序列都比基准值大;重复此过程,直到整个序列都有序为止。
排序步骤
找基准值的方法:
1、选出待排序序列最左侧元素当基准值;
2、设置两个哨兵left和right,分别位于待排序序列左右两端。
3、右哨兵right先往左走,遇到比基准值小的元素时停止移动;
4、右哨兵right停止移动后,左哨兵left开始向右移动,直到遇到比基准值大的元素时停止移动;
5、交换左右哨兵所指向的元素(注意不是交换左右哨兵);
6、重复3~5过程,直到左右哨兵相遇,此时相遇的点称作“枢轴”,将基准值与枢轴的值交换(此时枢轴的位置的值就是本次排序的基准值,枢轴左侧的元素均比基准值小,枢轴右侧的元素均比基准值大);
7、一分为二,枢轴左右侧的序列便成了两个待排序列,将这两个子序列重复1~6的过程,直到整个序列有序。
4个实例(都以序列最左值为基准值)
实例0(13个元素)
初始状态: 5 8 0 0 5 9 3 7 1 0 0 3 6
此次排序区间:0-12
第1个元素与第11个元素互换 |5 3 0 0 5 9 3 7 1 0 0 8 6 |
第5个元素与第10个元素互换 |5 3 0 0 5 0 3 7 1 0 9 8 6 |
第7个元素与第9个元素互换 |5 3 0 0 5 0 3 0 1 7 9 8 6|
第8个元素与第8个元素互换 |5 3 0 0 5 0 3 0 1 7 9 8 6|
0-12区间排序完毕,枢轴为:8,交换枢轴和基准值。
此时序列: 1 3 0 0 5 0 3 0 5 7 9 8 6此次排序区间:0-7
第1个元素与第7个元素互换 |1 0 0 0 5 0 3 3| 5 7 9 8 6
第4个元素与第5个元素互换 |1 0 0 0 0 5 3 3| 5 7 9 8 6
第4个元素与第4个元素互换 |1 0 0 0 0 5 3 3| 5 7 9 8 6
0-7区间排序完毕,枢轴为:4,交换枢轴和基准值。
此时序列: 0 0 0 0 1 5 3 3 5 7 9 8 6此次排序区间:0-3
第0个元素与第0个元素互换 |0 0 0 0| 1 5 3 3 5 7 9 8 6
0-3区间排序完毕,枢轴为:0,交换枢轴和基准值。
此时序列: 0 0 0 0 1 5 3 3 5 7 9 8 6此次排序区间:1-3
第1个元素与第1个元素互换 0 |0 0 0| 1 5 3 3 5 7 9 8 6
1-3区间排序完毕,枢轴为:1,交换枢轴和基准值。
此时序列: 0 0 0 0 1 5 3 3 5 7 9 8 6此次排序区间:2-3
第2个元素与第2个元素互换 0 0 |0 0| 1 5 3 3 5 7 9 8 6
2-3区间排序完毕,枢轴为:2,交换枢轴和基准值。
此时序列: 0 0 0 0 1 5 3 3 5 7 9 8 6此次排序区间:5-7
第7个元素与第7个元素互换 0 0 0 0 1 |5 3 3| 5 7 9 8 6
5-7区间排序完毕,枢轴为:7,交换枢轴和基准值。
此时序列: 0 0 0 0 1 3 3 5 5 7 9 8 6此次排序区间:5-6
第5个元素与第5个元素互换 0 0 0 0 1 |3 3| 5 5 7 9 8 6
5-6区间排序完毕,枢轴为:5,交换枢轴和基准值。
此时序列: 0 0 0 0 1 3 3 5 5 7 9 8 6此次排序区间:9-12
第10个元素与第12个元素互换 0 0 0 0 1 3 3 5 5 |7 6 8 9|
第10个元素与第10个元素互换 0 0 0 0 1 3 3 5 5 |7 6 8 9|
9-12区间排序完毕,枢轴为:10,交换枢轴和基准值。
此时序列: 0 0 0 0 1 3 3 5 5 6 7 8 9此次排序区间:11-12
第11个元素与第11个元素互换 0 0 0 0 1 3 3 5 5 6 7 |8 9|
11-12区间排序完毕,枢轴为:11,交换枢轴和基准值。
此时序列: 0 0 0 0 1 3 3 5 5 6 7 8 9
排序完毕: 0 0 0 0 1 3 3 5 5 6 7 8 9
实例1(10个元素)
初始状态: 1 8 3 9 9 0 2 3 9 7
此次排序区间:0-9
第1个元素与第5个元素互换 |1 0 3 9 9 8 2 3 9 7 |
第1个元素与第1个元素互换 1 0 3 9 9 8 2 3 9 7
0-9区间排序完毕,枢轴为:1,交换枢轴和基准值。
此时序列: 0 1 3 9 9 8 2 3 9 7此次排序区间:2-9
第3个元素与第6个元素互换 0 1 |3 2 9 8 9 3 9 7 |
第3个元素与第3个元素互换 0 1 |3 2 9 8 9 3 9 7 |
2-9区间排序完毕,枢轴为:3,交换枢轴和基准值。
此时序列: 0 1 2 3 9 8 9 3 9 7此次排序区间:4-9
第9个元素与第9个元素互换 0 1 2 3 |9 8 9 3 9 7 |
4-9区间排序完毕,枢轴为:9,交换枢轴和基准值。
此时序列: 0 1 2 3 7 8 9 3 9 9此次排序区间:4-8
第5个元素与第7个元素互换 0 1 2 3 |7 3 9 8 9| 9
第5个元素与第5个元素互换 0 1 2 3 |7 3 9 8 9| 9
4-8区间排序完毕,枢轴为:5,交换枢轴和基准值。
此时序列: 0 1 2 3 3 7 9 8 9 9此次排序区间:6-8
第7个元素与第7个元素互换 0 1 2 3 3 7 |9 8 9| 9
6-8区间排序完毕,枢轴为:7,交换枢轴和基准值。
此时序列: 0 1 2 3 3 7 8 9 9 9
排序完毕: 0 1 2 3 3 7 8 9 9 9
实例2(7个元素)
初始状态: 3 2 5 0 0 4 1
此次排序区间:0-6
第2个元素与第6个元素互换 |3 2 1 0 0 4 5|
第4个元素与第4个元素互换 |3 2 1 0 0 4 5|
0-6区间排序完毕,枢轴为:4,交换枢轴和基准值。
此时序列: 0 2 1 0 3 4 5此次排序区间:0-3
第0个元素与第0个元素互换 |0 2 1 0| 3 4 5
0-3区间排序完毕,枢轴为:0,交换枢轴和基准值。
此时序列: 0 2 1 0 3 4 5此次排序区间:1-3
第3个元素与第3个元素互换 0 |2 1 0| 3 4 5
1-3区间排序完毕,枢轴为:3,交换枢轴和基准值。
此时序列: 0 0 1 2 3 4 5此次排序区间:1-2
第1个元素与第1个元素互换 0 0 1 2 3 4 5
1-2区间排序完毕,枢轴为:1,交换枢轴和基准值。
此时序列: 0 0 1 2 3 4 5此次排序区间:5-6
第5个元素与第5个元素互换 0 0 1 2 3 4 5
5-6区间排序完毕,枢轴为:5,交换枢轴和基准值。
此时序列: 0 0 1 2 3 4 5
排序完毕: 0 0 1 2 3 4 5
实例3(7个元素)
初始状态: 2 8 6 3 3 5 7
此次排序区间:0-6
第0个元素与第0个元素互换 |2 8 6 3 3 5 7|
0-6区间排序完毕,枢轴为:0
此时序列: 2 8 6 3 3 5 7
(刚好基准值是区间里的最小值,所以此次划分只有右侧序列一个序列,相应的如果基准值刚好是区间里的最大值,划分后只有左侧序列)
此次排序区间:1-6
第6个元素与第6个元素互换 2 |8 6 3 3 5 7|
(这里出现元素换自己,是因为代码里防止两个数相同时两个哨兵都不前进陷入死循环,所以设置两个元素相同时继续进行移动交换操作)
1-6区间排序完毕,枢轴为:6
此时序列: 2 7 6 3 3 5 8此次排序区间:1-5
第5个元素与第5个元素互换 2 |7 6 3 3 5| 8
1-5区间排序完毕,枢轴为:5
此时序列: 2 5 6 3 3 7 8此次排序区间:1-4 第2个元素与第4个元素互换 2 |5 3 3 6| 7 8 第3个元素与第3个元素互换 2 |5 3 3 6| 7 8
1-4区间排序完毕,枢轴为:3
此时序列: 2 3 3 5 6 7 8(记得最后一步是把枢轴的值和基准值交换喔)此次排序区间:1-2
第1个元素与第1个元素互换 2 |3 3| 5 6 7 8
1-2区间排序完毕,枢轴为:1
此时序列: 2 3 3 5 6 7 8
排序完毕: 2 3 3 5 6 7 8
关于稳定杂性
快速排序是不稳定排序,因为在快速排序的随机选择比较子(即pivot)阶段,如果选择一个数作为比较子,而把大于等于比较子的数均放置在大数数组中,则原数组中相等的两个数非原序,这就是“不稳定”。
关于复杂性
快速排序的时间复杂度为O(nlogn)。最好时间复杂度为O(nlogn),最坏时间复杂度为O(n^2),平均时间复杂度为O(nlogn)。
关于复杂性
快速排序的空间复杂度为O(logn)。最优的情况下空间复杂度为O(logn),每一次都平分数组的情况。最差的情况下空间复杂度为O(n),退化为冒泡排序的情况。
源代码(风格参考严蔚敏版数据结构,但过程作了降时间优化,具体过程不同书上):
/*
广西师范大学 计算机科学与工程学院
GuangXi Normal University
College of Computer Science and Engineering
Student STZ
*/
#include<iostream>
#include<stdio.h>
#include <stdlib.h>
#include <time.h>
using namespace std;
#define ElemType int
#define Status int//表示状态
#define OK 1
#define ERROR 0
#define maxnum 13
#define max 10
typedef struct SqList{
ElemType *list;
ElemType lenght;
}SqList,*Sl;
Status initial(Sl sl){
sl->list = new ElemType[maxnum];
sl->lenght = maxnum;
srand((unsigned)time(NULL));//时间种子
for(int i=0;i<sl->lenght;i++){//随机生成10个数
sl->list[i] = rand()%max;
}
return 1;
}
void showList(SqList sl){
for(int i=0;i<maxnum;i++){
cout<<sl.list[i]<<" ";
}
cout<<endl;
}
void swap(SqList &sl,int i,int j){
int t = sl.list[i];
sl.list[i] = sl.list[j];
sl.list[j] = t;
}
int PartSort(SqList &sl,int left,int right){
int L = left,R = right;//纯属用来输出使用,无实际意义
cout<<"\n此次排序区间:"<<L<<"-"<<R<<endl;
//left和right表示左右哨兵,left哨兵从左往右走,right哨兵从右往左走
int pivotindex = left;//取区间最左边元素为key
while(left<right){//两个哨兵未相遇
//right哨兵先走
while(left<right&&sl.list[pivotindex]<=sl.list[right]){
right--;//找到比key小的元素就跳出
}
//找到比key小元素了,此时right哨兵停止移动,left哨兵开始移动
while(left<right&&sl.list[pivotindex]>=sl.list[left]){
left++;//找到比key大的元素就跳出
}
//交换这哨兵所指的元素
swap(sl,left,right);
cout<<"第"<<left<<"个元素与第"<<right<<"个元素互换"<<endl;
showList(sl);
}
int encounter = left;//哨兵相遇(枢轴)时指向的元素,和key交换
swap(sl,pivotindex,encounter);
cout<<L<<"-"<<R<<"区间排序完毕,枢轴为:"<<encounter<<",交换枢轴和基准值。"<<endl;
cout<<"此时序列:\n";showList(sl);
return encounter;//返回枢轴
}
void qSort(SqList &sl,int left,int right){
if(left<right){
int pivot = PartSort(sl,left,right);
qSort(sl,left,pivot-1);//左子序列
qSort(sl,pivot+1,right);//右子序列
}
}
void quickSort(SqList &sl){
qSort(sl,0,sl.lenght-1);
}
int main(){
SqList sl;
if(!initial(&sl)){
cout<<"初始化失败"<<endl;
return 0;
}
cout<<"初始化完毕。初始状态:"<<endl;
showList(sl);
quickSort(sl);
cout<<"排序完毕:"<<endl;
showList(sl);
return 0;
}
再补充两个例子吧:
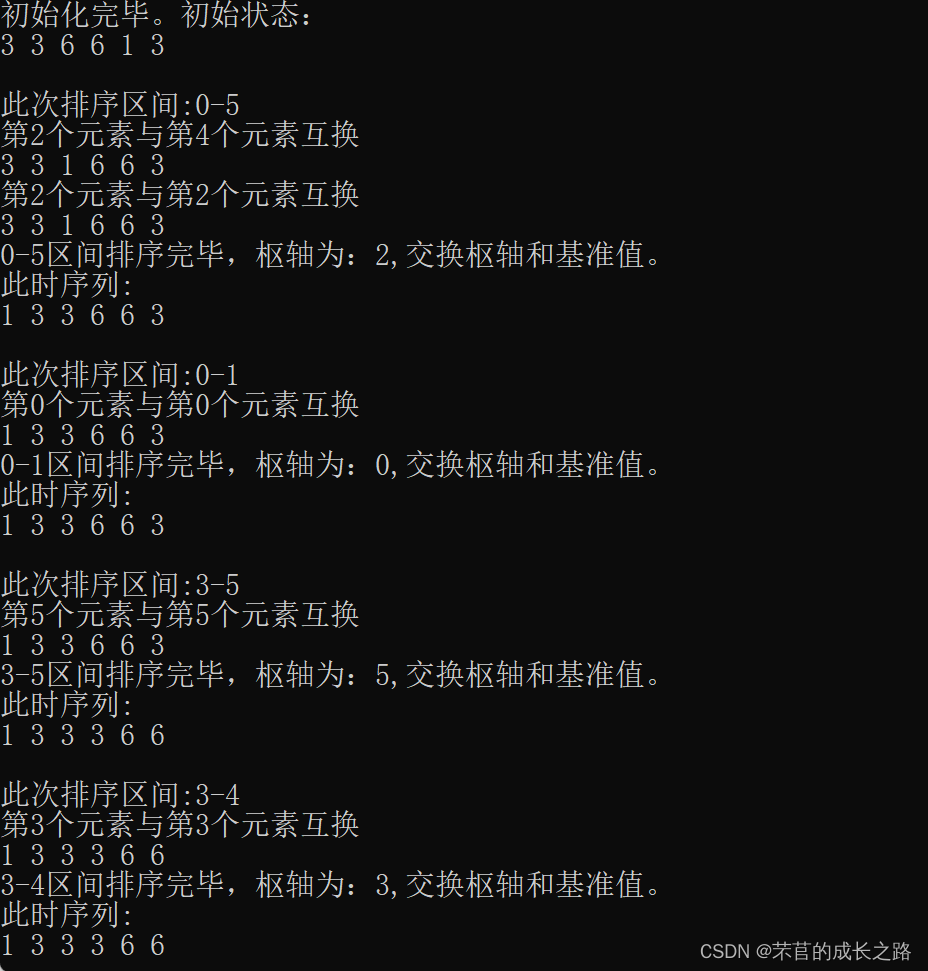
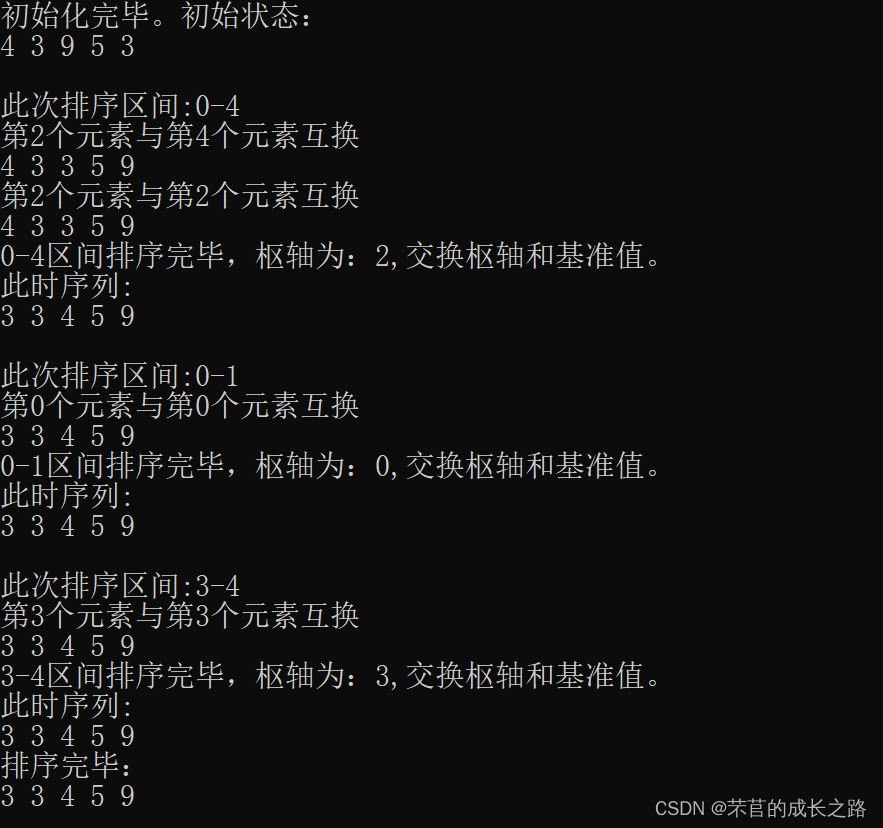
源代码(书上同款过程的代码):
应一些小伙伴的要求,写了一个同书上的过程。书上的过程和优化过后的过程区别在于:书上原版的过程使用的是“不停更新key”的思想,而优化过的代码使用的思想是“找到区间最初的key的最终归宿后再更新key的位置”的思想。优化过后的代码的操作次数比书本原版的操作次数大概减少了一半。
#include<iostream>
#include<stdio.h>
#include <stdlib.h>
#include <time.h>
using namespace std;
#define ElemType int
#define Status int//表示状态
#define OK 1
#define ERROR 0
#define maxnum 13
#define max 10
typedef struct SqList{
ElemType *list;
ElemType lenght;
}SqList,*Sl;
Status initial(Sl sl){
sl->list = new ElemType[maxnum];
sl->lenght = maxnum;
srand((unsigned)time(NULL));//时间种子
for(int i=0;i<sl->lenght;i++){//随机生成10个数
sl->list[i] = rand()%max;
}
return 1;
}
void showList(SqList sl){
for(int i=0;i<maxnum;i++){
cout<<sl.list[i]<<" ";
}
cout<<endl;
}
void swap(SqList &sl,int i,int j){
int t = sl.list[i];
sl.list[i] = sl.list[j];
sl.list[j] = t;
}
int PartSort(SqList &sl,int left,int right){
int L = left,R = right;//纯属用来输出使用,无实际意义
cout<<"\n此次排序区间:"<<L<<"-"<<R<<endl;
//left和right表示左右哨兵,left哨兵从左往右走,right哨兵从右往左走
int pivotindex = left;//取区间最左边元素为key
while(left<right){//两个哨兵未相遇
//right哨兵先走
while(left<right&&sl.list[pivotindex]<=sl.list[right]){
right--;//找到比key小的元素就跳出
}
swap(sl,pivotindex,right);//更改key
//找到比key小元素了,此时right哨兵停止移动,left哨兵开始移动
while(left<right&&sl.list[pivotindex]>=sl.list[left]){
left++;//找到比key大的元素就跳出
}
swap(sl,pivotindex,left);//更改key
cout<<"第"<<left<<"个元素与第"<<right<<"个元素互换"<<endl;
showList(sl);
}
int encounter = left;//哨兵相遇(枢轴)时指向的元素,和key交换
swap(sl,pivotindex,encounter);
cout<<L<<"-"<<R<<"区间排序完毕,枢轴为:"<<encounter<<",交换枢轴和基准值。"<<endl;
cout<<"此时序列:\n";showList(sl);
return encounter;//返回枢轴
}
void qSort(SqList &sl,int left,int right){
if(left<right){
int pivot = PartSort(sl,left,right);
qSort(sl,left,pivot-1);//左子序列
qSort(sl,pivot+1,right);//右子序列
}
}
void quickSort(SqList &sl){
qSort(sl,0,sl.lenght-1);
}
int main(){
SqList sl;
if(!initial(&sl)){
cout<<"初始化失败"<<endl;
return 0;
}
cout<<"初始化完毕。初始状态:"<<endl;
showList(sl);
quickSort(sl);
cout<<"排序完毕:"<<endl;
showList(sl);
return 0;
}
两款代码的区别:
//优化后的代码
while(left<right){//两个哨兵未相遇
//right哨兵先走
while(left<right&&sl.list[pivotindex]<=sl.list[right]){
right--;//找到比key小的元素就跳出
}
//找到比key小元素了,此时right哨兵停止移动,left哨兵开始移动
while(left<right&&sl.list[pivotindex]>=sl.list[left]){
left++;//找到比key大的元素就跳出
}
//交换这哨兵所指的元素
swap(sl,left,right);
}
//书本过程
while(left<right){//两个哨兵未相遇
//right哨兵先走
while(left<right&&sl.list[pivotindex]<=sl.list[right]){
right--;//找到比key小的元素就跳出
}
swap(sl,pivotindex,right);//更改key
//找到比key小元素了,此时right哨兵停止移动,left哨兵开始移动
while(left<right&&sl.list[pivotindex]>=sl.list[left]){
left++;//找到比key大的元素就跳出
}
swap(sl,pivotindex,left);//更改key
}
很明显,一个大的while之下,书本的过程使用了两次swap,而优化过后的代码只使用了一次swap。当然,两个都是快排方法,没有谁对谁错,只有性能谁好点谁差点的区别,仅此而已。
敬请批评指正!


















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











