






概念
对于多分类任务,通常采用柔性最大值(softmax):
其中,z是一个K维的得分向量,每一维取值代表第j类的得分
一些分类任务的评价指标:
精度(accuracy)
真阳性率TPR,查全率,召回率(recall)
假阳性率(false positive rate,FPR)
查准率(precision)
F1分数
F-beta分数
实践中,F2和F0.5较为常用
ROC 曲线:
TPR随FPR的变化曲线,该曲线称为受试者操作特征(receiver operating characteristic,ROC)曲线。
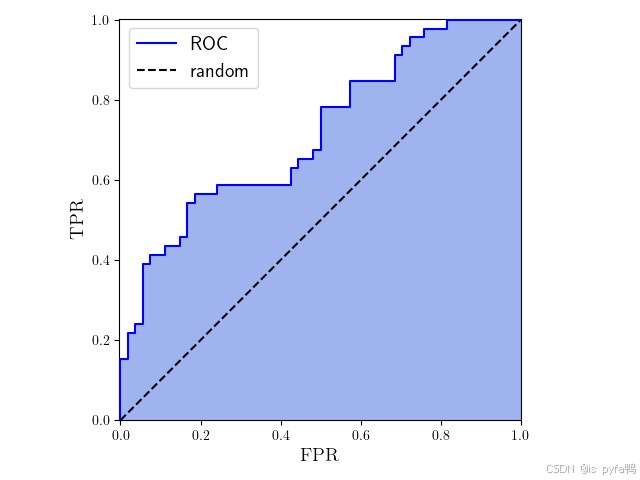
为了定量衡量 ROC 曲线表示的模型好坏,我们通常计算 ROC 曲线与x轴和x=1直线围成的面积,称为曲线下面积(area under the curve,AUC)。模型将真实的正类和负类分得越清楚,就有越多的负类排在正类前面,AUC 就越大。
熵(entropy)
相对熵(relative entropy)来衡量这两个分布的距离。相对熵又称为库尔贝克-莱布勒散度(Kullback-Leibler divergence),简称 KL 散度,其定义为:
交叉熵(cross entropy)
在二分类问题中,令p(x)等于样本x的类别是X的概率;q(x)等于模型预测的样本类别为X的概率,我们期望模型预测的概率尽可能接近真实类别,因此要最小化p与q之间的距离
。而在离散化 KL 散度的定义中,-H(p)只与样本真实类别有关,无法通过模型优化。因此,我们只需要最小化交叉熵H(p,q)
代码
# 划分训练集与测试
np.random.seed(0)
ratio = 0.7
split = int(len(x_total) * ratio)
idx = np.random.permutation(len(x_total))
x_total = x_total[idx]
y_total = y_total[idx]
x_train, y_train = x_total[:split], y_total[:split]
x_test, y_test = x_total[split:], y_total[split:]与线性回归相似,sklearn 同样提供了封装好的逻辑斯谛回归模型LogisticRegression
from sklearn.linear_model import LogisticRegression
# 使用线性模型中的逻辑回归模型在数据集上训练
# 其提供的liblinear优化算法适合在较小数据集上使用
# 默认使用系数为1.0的L2正则化约束
# 其他可选参数请参考官方文档
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(x_train, y_train)
print('回归系数:', lr_clf.coef_[0], lr_clf.intercept_)
# 在数据集上用计算得到的逻辑回归模型进行预测并计算准确度
y_pred = lr_clf.predict(x_test)
print('准确率为:',np.mean(y_pred == y_test))

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









