







摘要
RefineNet是用于语义分割的多路径细化网络,它通过级联架构有效地结合高级特征和低级特征来生成高分辨率的语义分割图。同时模型提出了一种全新的层——链式残差池化单元,该单元通过多个由池化层、卷积层构成的池化单元和残差连接来融合不同层次的特征,使得模型可以从很大的图片区域中捕获到背景的上下文信息。此外,模型中的所有组件都使用了恒等映射的残差链接,使得梯度在模型中能直接传递,以至于可以进行高效地端到端训练。尽管RefineNet能带来高质量的语义分割效果,但是由于级联架构和主干网络模型的复杂性导致该模型的计算复杂度高,要求极高的计算资源。
Abstract
RefineNet is a multi-path refinement network for semantic segmentation, which effectively combines high-level and low-level features through a cascade architecture to generate high-resolution semantic segmentation maps. The model introduces a novel layer—the chained residual pooling unit—which fuses features from different layers through multiple pooling units and residual connections composed of pooling and convolutional layers. This allows the model to capture contextual information from large image regions, including the background. Additionally, all components in the model use identity mapping residual links, enabling the direct propagation of gradients through the network for efficient end-to-end training. Although RefineNet achieves high-quality semantic segmentation results, its cascade architecture and the complexity of the backbone network lead to high computational complexity, requiring substantial computational resources.
1. 引言
尽管卷积神经网络如VGG,ResNet在图片分类任务上效果极佳,但是这些模型在密集预测类型的任务,如语义分割,展现出明显的缺点——多阶段空间池化和卷积的步长会在每个通道上将最终的特征图减少好几倍,从而丢失图像大部分细粒度的信息。
论文认为来自所有层次的特征都有助于进行语义分割。高层次语义特征有助于图像区域中种类的识别,而低层次视觉特征有助于生成清晰、详细的边界以进行高分辨率预测。但是如何高效利用中间层的特征仍然是一个问题。论文提出了一个全新的框架RefineNet以利用多层次的特征进行高分辨率预测。
2. 框架
论文中首先将ResNet模型分为四部分,其中第一部分得到的输出是
1
4
\displaystyle\frac{1}{4}
41倍原图大小的特征图,第二部分得到的输出是
1
8
\displaystyle \frac{1}{8}
81倍原图大小的特征图,第三部分得到的输出是
1
16
\displaystyle \frac{1}{16}
161倍原图大小的特征图,第四部分得到的输出是
1
32
\displaystyle \frac{1}{32}
321倍原图大小的特征图。接着第四部分输出的特征图作为RefineNet-4的输入,RefineNet-4输出后的特征图和第三部分输出的特征图一起作为RefineNet-3的输入,经过RefineNet-3后的特征图和第二部分输出的特征图一起作为RefineNet-1的输入,RefineNet-1输出后的特征图在经过一些层(下文中提到的两层RCU)后再输入密集Softmax层进行逐像素的预测。最后在将预测结果用双线性插值方法进行上采样以得到原图大小的预测结果,用来完成语义分割任务。
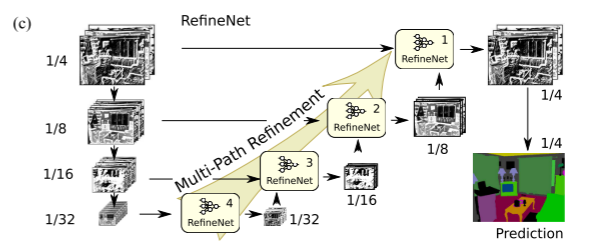
2.1 模型结构
RefineNet块的结构如下,一般由三个部分组成:残差卷积单元、多分辨率融合单元和链式残差池化单元组成。除了RefineNet-4的输入为一个外,其余的RefineNet块的输入均为两个。这两个输入分别经过两个残差卷积单元,再经过多分辨率融合单元,接着经过链式残差池化,最后经过一个残差卷积单元,便可以得到一个RefineNet块的输出特征图。
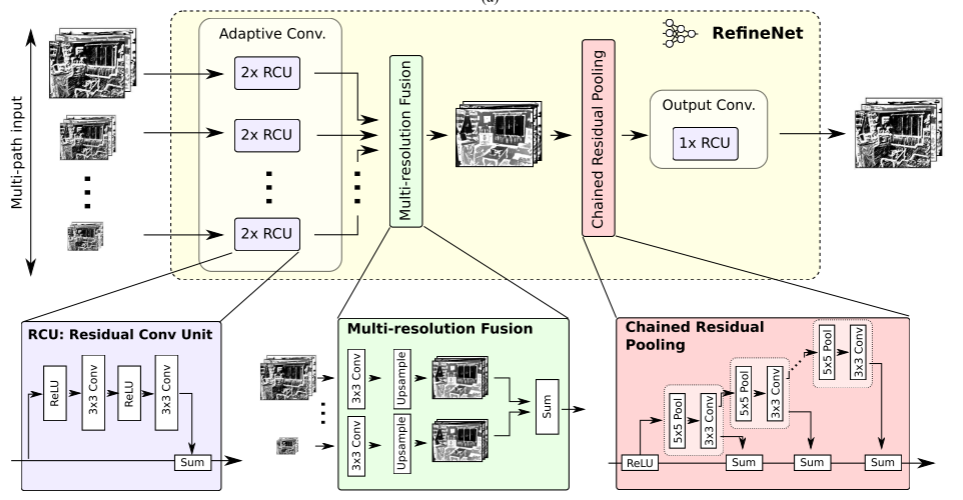
由于RefineNet-4只有一个输入,因此RefineNet-4只由残差卷积单元和链式残差池化单元组成。ResNet第四部分的输出特征图经过两个残差卷积单元,再经过链式残差池化单元,接着经过一个残差卷积单元,最后得到RefineNet-4的输出特征图。
论文提出的残差卷积单元是仿照ResNet中残差块设计的,残差卷积单元的输入分为两路,一路为主路,一路为支路。输入在主路上先经过ReLU激活,再经过
3
×
3
3\times3
3×3的卷积层,然后继续进行ReLU激活和
3
×
3
3\times3
3×3卷积。输入在经过主路一系列层后得到的输出直接与支路的输入相加,便得到残差卷积单元的最终输出。

多分辨率融合单元利用高分辨率的特征图来细化低分辨率的特征图。两个不同尺寸的特征图分别经过一个
3
×
3
3\times3
3×3的卷积层,再分别进行一次上采样以使两者在尺寸上达到一致,最后对两者进行相加,便得到了多分辨率融合单元的输出。

链式残差池化单元的目的是为了在较大的图片区域上捕获背景的上下文信息,该单元由多个池化块组成,每个池化块由一个
5
×
5
5\times5
5×5最大池化层和一个
3
×
3
3\times3
3×3卷积层组成。每个池化块以之前层的输出(ReLU激活后的输出或之前池化块的输出)作为输入,同时每个池化块的输出与支路上的输入相加。此外,链式残差池化单元一开始的ReLU激活层可以减小模型对学习率的敏感性和增强后续池化层的效果。论文中提到链式残差池化单元由两个池化块构成。

2.2 评估结果

3. 创新点和不足
3.1 创新点
RefineNet利用多层次的特征来进行高分辨率的语义分割,以级联的方式用低层次、精细的特征来细化高层次、粗糙的特征。同时模型中的所有组件都使用了恒等映射的残差链接,使得梯度在模型中能直接传递,以至于可以进行高效地端到端训练。此外,模型提出了一种全新的层——链式残差池化单元,该单元通过多个由池化层、卷积层构成的池化单元和残差连接来融合不同层次的特征,使得模型可以从很大的图片区域中捕获到背景的上下文信息。
3.2 不足
RefineNet的多路径细化过程虽然可以逐步提高分割精度,但同时也导致了较高的计算复杂度。这使得模型在实时应用中的性能受到限制,尤其是在资源受限的设备上难以高效运行。
此外,RefineNet 的架构相对复杂,包含多个模块和多级联结构。这种复杂性不仅增加了模型的训练难度,也使得模型的调试和优化变得更加困难。
参考
Guosheng Lin, Anton Milan, Chunhua Shen, Ian Reid. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation.
代码来源:https://github.com/DrSleep/refinenet-pytorch
总结
RefineNet通过主干网络得到不同尺寸的特征图,再通过级联架构有效地结合高级特征和低级特征来生成高分辨率的语义分割图。在论文中主干网络是ResNet,该主干网络会产生四种不同尺寸的特征图,具体过程如下:第四部分输出的特征图作为RefineNet-4的输入,RefineNet-4输出后的特征图和第三部分输出的特征图一起作为RefineNet-3的输入,经过RefineNet-3后的特征图和第二部分输出的特征图一起作为RefineNet-1的输入,RefineNet-1输出后的特征图在两层RCU后再输入密集Softmax层进行逐像素的预测。最后在将预测结果用双线性插值方法进行上采样以得到原图大小的预测结果,用来完成语义分割任务。尽管RefineNet语义分割效果极好,但是计算复杂度极高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









